【Nota introductoria】¡Es una locura! Los datos de evolución de IA medidos recientemente por Meta y METR coinciden perfectamente con la «Ley de Densidad» propuesta por un equipo chino hace dos años. Silicon Valley se dio cuenta de repente de que los investigadores chinos llevan dos años de ventaja en este camino.
¡Tres de las instituciones de investigación de IA más serias del mundo chocaron colectivamente la semana pasada!
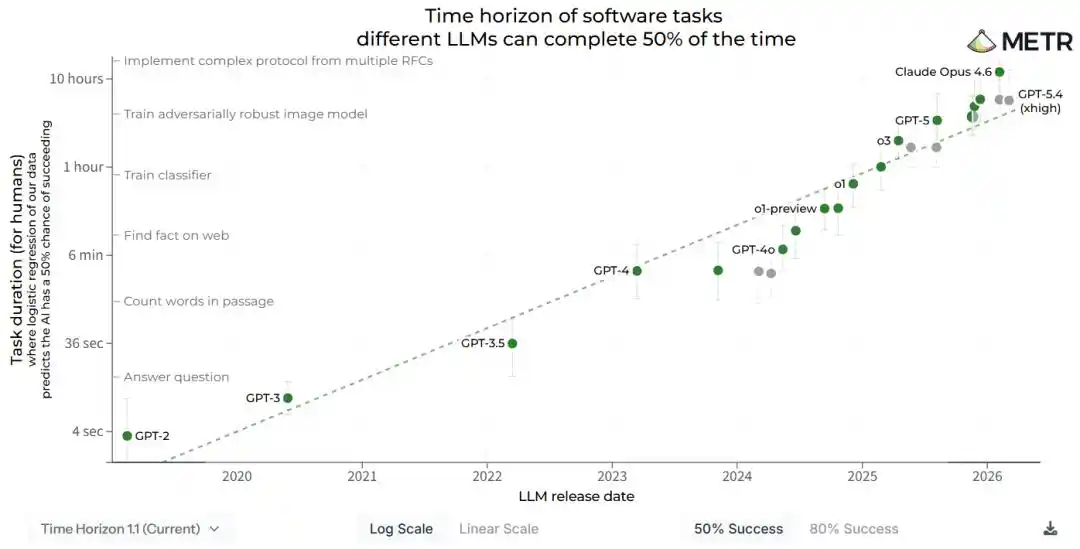
El 3 de abril, la institución de investigación estadounidense METR actualizó silenciosamente un informe técnico, resumiendo su conclusión central en una frase.
La capacidad de la IA se duplica cada 88.6 días.
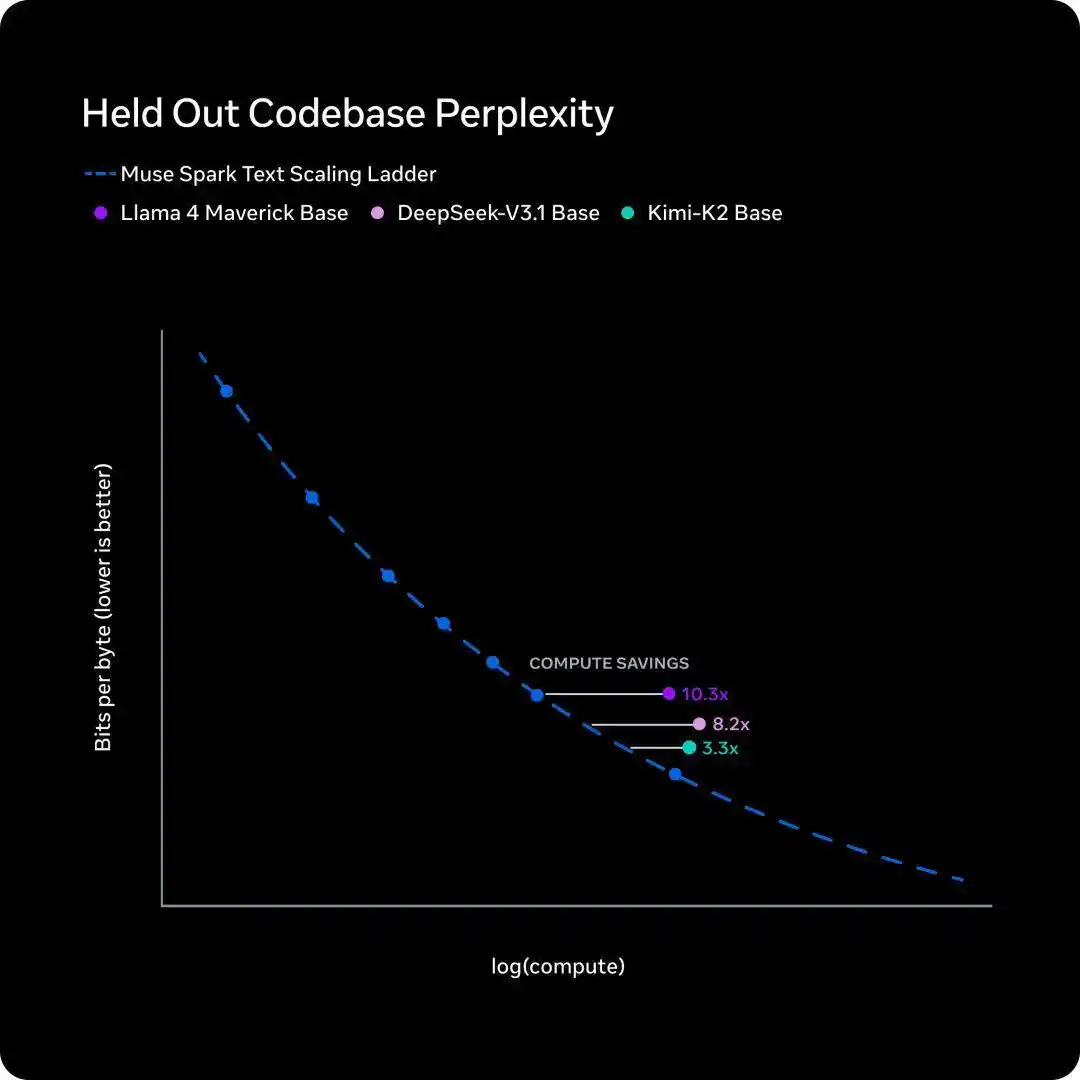
Cinco días después, el 8 de abril, el Laboratorio de Superinteligencia de Meta lanzó el nuevo modelo Muse Spark, revelando una curva de eficiencia de entrenamiento llamada internamente «escalera de escalado» (scaling ladder), cuya conclusión también es una frase.
Para igualar el rendimiento de Llama 4 Maverick de hace un año, el nuevo modelo necesita menos de una décima parte de la potencia de cálculo de entrenamiento.
Uno mide la duración de la tarea, el otro mide la potencia de cálculo del entrenamiento. Las dos instituciones no tenían ninguna relación y sus métodos de investigación no se superponían en absoluto.
Pero cuando las dos curvas se convirtieron al mismo sistema de coordenadas, sus pendientes coincidían casi por completo.
Hasta aquí, las cosas ya eran bastante descabelladas.
Lo que es aún más descabellado es que esta curva fue dibujada completa hace dos años por un equipo chino, e incluso se publicó en una subrevista de Nature.
Se llama Ley de Densidad.

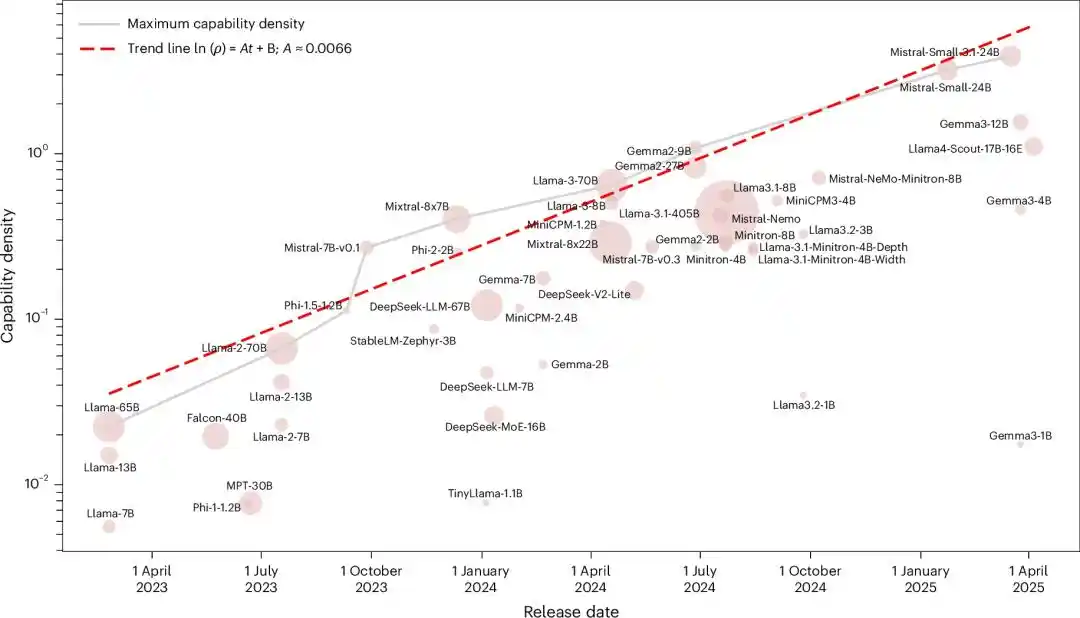
Hace dos años, alguien dibujó esta línea de antemano
Este concepto apareció por primera vez en un artículo titulado «Densing Law of LLMs».
Los autores eran un equipo conjunto de FaceWall AI y la Universidad de Tsinghua, liderado por los profesores Sun Maosong y Liu Zhiyuan, con el doctorando Xiao Chaojun como primer autor.
El artículo se subió a arXiv en diciembre de 2024 y fue aceptado por Nature Machine Intelligence en noviembre de 2025.

Dirección del artículo: https://arxiv.org/abs/2412.04315

Dirección del artículo: https://www.nature.com/articles/s42256-025-01137-0
El juicio central del artículo es solo una frase.
La densidad de inteligencia del modelo aumenta exponencialmente con el tiempo, y la cantidad de parámetros necesarios para alcanzar un nivel específico de inteligencia se reduce a la mitad cada 3.5 meses.
A finales de 2024, esto sonaba un poco radical.
En aquel entonces, toda la industria adoraba la ley de escalado (scaling law). OpenAI acumulaba modelos, Anthropic acumulaba modelos, Meta también acumulaba modelos.
Todo el mundo pensaba que a más parámetros, más inteligencia, y que el camino correcto era llevar las GPU al límite.
Pero el equipo de investigación no lo veía así.
Colocaron todos los modelos base de código abierto influyentes de la época, desde Llama-1 hasta Gemma-2 y MiniCPM-3, un total de 51 modelos, en la misma escala para medirlos.
Después de ejecutar cinco benchmarks, el resultado fue una relación exponencial casi perfecta, con un R2 de 0.934.
Teniendo en cuenta que la evaluación de modelos grandes es fácilmente contaminada por datos, volvieron a probar con un nuevo conjunto de datos de filtrado de contaminación, MMLU-CF. R2=0.953.
Ambos ajustes obtuvieron un R2 cercano a 1. Estadísticamente, esto casi no podría ser una coincidencia.
En otras palabras, cada modelo de código abierto principal lanzado en esos dos años, sin importar de qué equipo provenía o qué arquitectura usaba, cayó en la misma línea exponencial de «duplicación cada 3.5 meses».
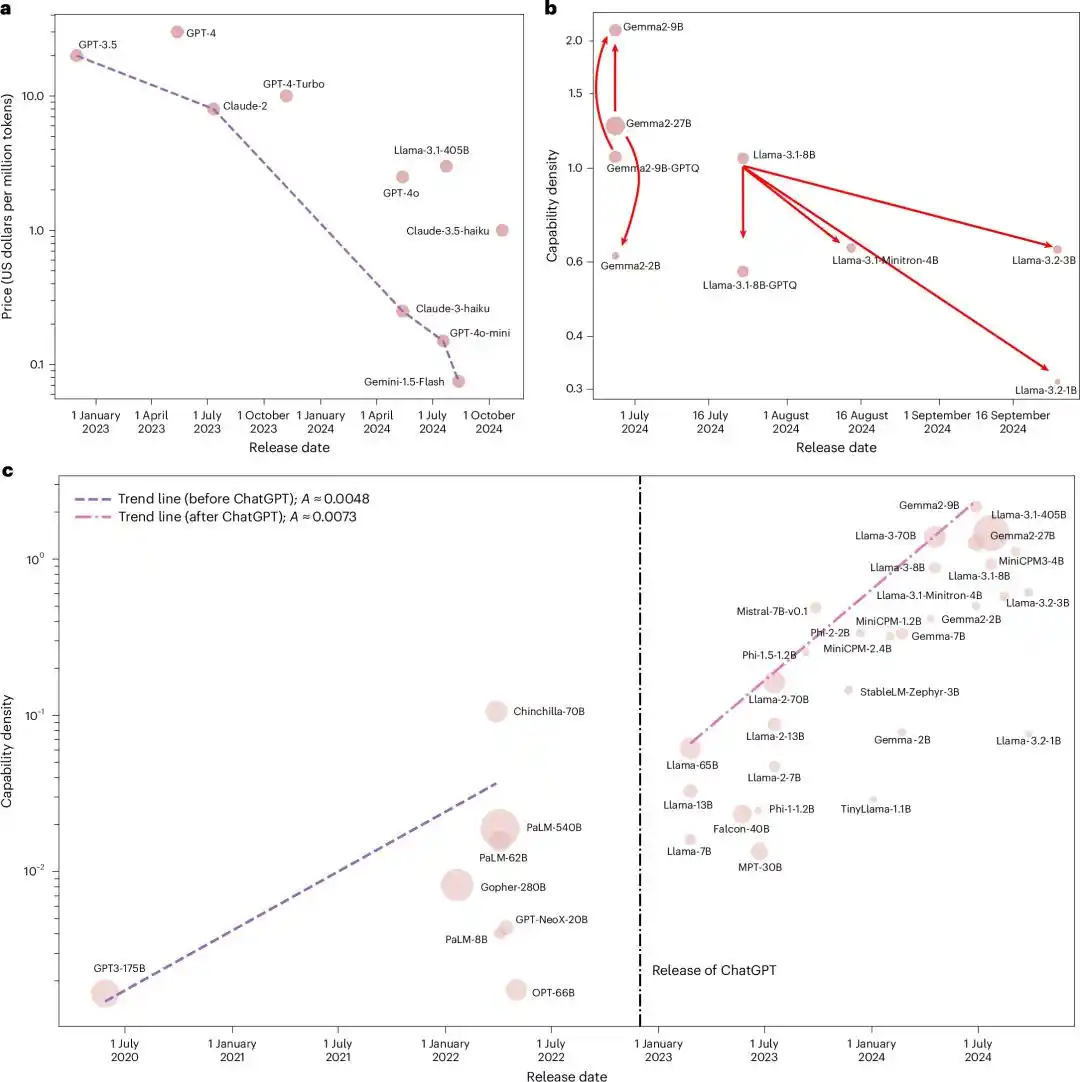
Hasta aquí, la historia era solo «un equipo chino propuso una ley empírica que parecía muy radical».
Lo que realmente convirtió esto en un «momento» fueron los eventos de los siguientes seis meses.
Tres instituciones, tres métodos, la misma pendiente
Al desglosar las conclusiones de FaceWall, Meta y METR:
- La Ley de Densidad de FaceWall mide «cuántos parámetros se necesitan para el mismo nivel de inteligencia». Concluye que la necesidad de parámetros se reduce a la mitad cada 3.5 meses.
- La scaling ladder de Meta mide «cuánta potencia de cálculo de entrenamiento se necesita para el mismo nivel de inteligencia». Concluye que Muse Spark ahorra un orden de magnitud en comparación con Llama 4 Maverick de hace un año.
- El informe de horizonte temporal de METR mide «qué tan larga puede ser la tarea que un modelo puede manejar». Concluye que la duración de la tarea se duplica cada 88.6 días.
Tres métricas. Tres instituciones académicas. Tres caminos de investigación sin superposición alguna.
Pero cuando todos los números se convierten al mismo sistema de coordenadas, las pendientes de sus curvas coinciden casi por completo.
Lo que más fácilmente se pasa por alto es que la Ley de Densidad fue la primera de las tres en proponerse. Casi dos años antes que la scaling ladder de Meta, y más de un año antes que el modelado completo de METR.
Y cuando Meta dibujó esa scaling ladder en su blog a principios de abril, probablemente ni siquiera se dieron cuenta. La forma de este gráfico era casi la misma línea que la curva en una presentación PPT de una conferencia académica en Beijing en 2024.
Qué tipo de observación merece ser llamada «ley»
En la comunidad científica, existe un estándar no escrito para juzgar si una observación empírica merece ser llamada «ley».
No se trata de cuán bonitos sean los datos, sino de si puede sostenerse simultáneamente en múltiples sistemas de medición independientes.
La Ley de Moore es una ley porque la industria de los semiconductores la ha verificado docenas de veces a lo largo de décadas desde tres dimensiones completamente diferentes: precisión de litografía, densidad de transistores, costo por unidad de potencia de cálculo.
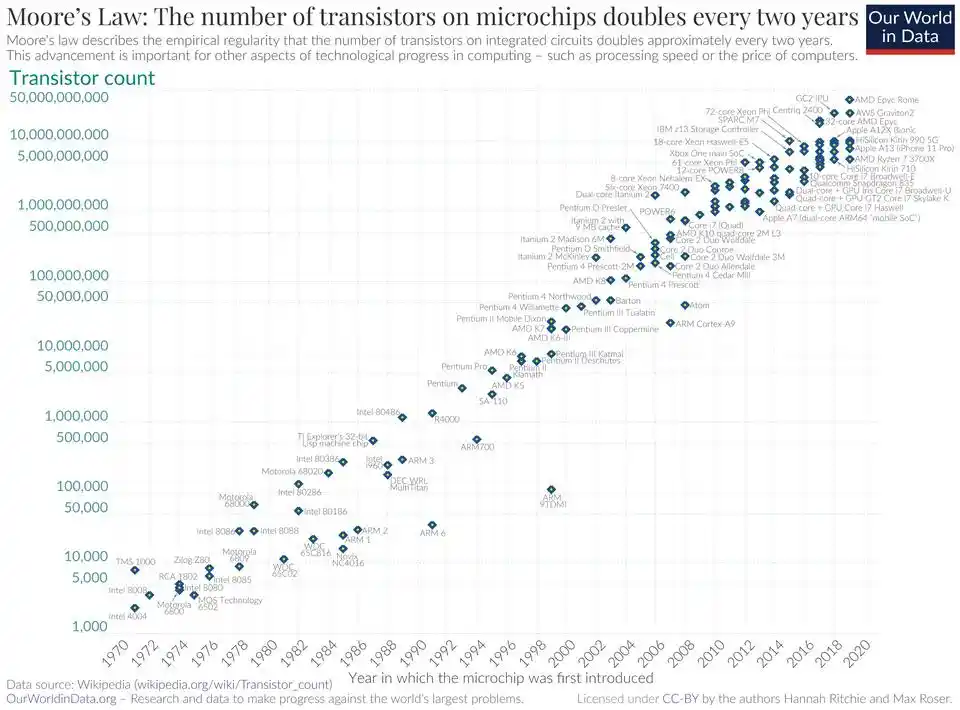
La Ley de Densidad sigue el mismo camino.
Inicialmente era solo una curva de ajuste de un solo equipo. Cuando fue aceptada por la subrevista de Nature, ya podía reproducirse en conjuntos de datos filtrados de contaminación. Y este mes, fue verificada de forma independiente dos veces más en los datos de entrenamiento de Meta y en la evaluación de tareas de METR.
Visto en un sistema de coordenadas más grande, este momento se parece mucho a cuando la electricidad llegó por primera vez a Nueva York en la década de 1880.
En aquel entonces, también eran inventores diferentes, ingenieros diferentes, ciudades diferentes, cada uno trabajando en su propia red eléctrica. Hasta que alguien dibujó las curvas de desarrollo de todos los proyectos en un mismo papel, la gente la que se dio cuenta. Esto no eran unos pocos avances de ingeniería dispersos, era una nueva era que se estaba desplegando en silencio.
Solo que esta vez, desde la publicación del artículo hasta su verificación por pares globales, tomó menos de un año.
Tres inferencias, cada una reescribiendo supuestos de la industria
Si la Ley de Densidad se sostiene, cambiaría muchas cosas a la vez.
Primero, el costo de inferencia colapsará más rápido de lo que nadie esperaba.
Una inferencia de la Ley de Densidad es que el costo de inferencia para LLMs del mismo rendimiento se reduce aproximadamente a la mitad cada 2.6 meses.
Hoy, esta caída ya ha sido superada por la realidad.
Los últimos datos de seguimiento de Epoch AI muestran que para LLMs con un rendimiento similar a Claude 3.5 Sonnet, el precio por token ha caído 400 veces en el último año. La caída más rápida para el mismo nivel de rendimiento alcanzó 900 veces/año.
El nivel por el que GPT-3.5 pedía 20 dólares por millón de tokens a finales de 2022, hoy Mistral Nemo lo ofrece por 0.02 dólares, 1000 veces más barato, y el modelo es aún más potente.
En retrospectiva, la predicción del artículo era conservadora.
Segundo, el punto de explosión de la inteligencia en el dispositivo (edge) está más cerca de lo que nadie pensaba.
Multiplicando la Ley de Densidad por la Ley de Moore, se obtiene un número aún más estimulante.
Según las estimaciones actuales, el tamaño máximo efectivo del modelo que se puede ejecutar en chips del mismo precio se duplica aproximadamente cada 88 días.
Este número coincide casi exactamente con los 88.6 días calculados por METR. Dos caminos de cálculo completamente diferentes chocaron más allá del punto decimal.
En los próximos tres a cinco años, ejecutar modelos de nivel GPT actual de primer nivel en un portátil común o incluso en un teléfono móvil podría dejar de ser ciencia ficción.
Tercero, la estrategia óptima de la industria de los modelos grandes está revirtiéndose en silencio.
En los últimos tres años, la comprensión de la industria sobre la ley de escalado se había estancado en «apilar parámetros, apilar datos».
Pero la Ley de Densidad ofrece un juicio contraintuitivo. Bajo la premisa de un crecimiento exponencial continuo de la densidad, cualquier modelo más potente en un estado dado solo tiene una ventana de optimalidad de unos pocos meses.
Invertir todos los recursos en entrenar un modelo más grande y luego esperar tres meses a que un nuevo modelo con la mitad del tamaño lo supere, no es rentable en términos económicos.
El camino sostenible real es invertir recursos en la mejora de la densidad misma. Mejor arquitectura, datos de mayor calidad, algoritmos de entrenamiento más inteligentes.
FaceWall, siempre avanzando según la regla que ellos mismos dibujaron
Vale la pena mencionar que la Ley de Densidad no es un artículo que terminó después de publicarse.
FaceWall AI, que propuso esta teoría, ha estado verificándola durante los últimos dos años con su serie de modelos «Small Cannon» (Pequeño Cañón) MiniCPM.
Cuando se lanzó MiniCPM-1-2.4B en febrero de 2024, sus puntuaciones podían igualar o superar a Mistral-7B de septiembre de 2023. Es decir, en cuatro meses, con un 35% de los parámetros, alcanzó el mismo rendimiento.
Este número se incluyó directamente en el artículo de la subrevista de Nature, como el primer caso empírico de la Ley de Densidad.
Desde entonces, la serie Small Cannon se ha publicado como código abierto, cubriendo cuatro direcciones principales: texto, multimodal, voz y modalidad completa, todos por debajo de los 10B de parámetros. Este nivel de integridad en código abierto, dentro de China, solo lo ha logrado FaceWall además de Alibaba.
Hasta ahora, la serie Small Cannon ha superado los 24 millones de descargas en todo el mundo.
No es el modelo más grande de la industria. Pero es el primer equipo de la industria en ejecutar la «prioridad de densidad» como metodología de empresa.
Y cuando Meta y METR verificaron la Ley de Densidad en abril de 2026 con sus respectivos métodos, esta empresa china que comenzó a entrenar modelos con esta metodología en 2024, en realidad ya tenía dos años de ventaja en experiencia de ingeniería.
Esta vez, los investigadores chinos están en el punto de partida de la curva
Un marco teórico propuesto hace dos años por un equipo de investigación chino está siendo redescubierto, cada vez, por instituciones extranjeras tan serias como Meta y METR, usando sus propios métodos.
El peso de esto puede necesitar un poco de tiempo para ser completamente comprendido.
No es una historia de «nosotros también podemos». Es una historia de «nosotros lo vimos un poco antes».
No hay muchos momentos así en la historia de la ciencia. Un juicio cuestionado en 2024 se convirtió en 2026 en la misma curva señalada por múltiples evidencias independientes.
Este tipo de «coincidencia» transregional, transmetodológica, transinstitucional, ha ocurrido unas pocas veces en la física, y cada vez ha marcado el final de un paradigma antiguo y el inicio de uno nuevo.
Los investigadores de IA chinos están esta vez en ese punto de partida.
Y esa curva continúa ascendiendo a un ritmo que se duplica cada 88 días.
Referencias:
La «Ley de Densidad» creada por FaceWall AI, reconocida por instituciones top extranjeras como Meta
https://arxiv.org/abs/2412.04315
https://www.nature.com/articles/s42256-025-01137-0
https://metr.org/blog/2026-1-29-time-horizon-1-1/
https://ai.meta.com/blog/introducing-muse-spark-msl/
Este artículo proviene del WeChat público «新智元» (Nueva Era de la Inteligencia), editores: Hao Kun, Tao Zi







