En febrero de 2026, Xiaohongshu anunció que todo el contenido generado o sintetizado por IA debía ser identificado activamente, y el contenido no identificado sería restringido en su distribución. Más de tres meses después, apareció en GitHub un proyecto de código abierto llamado guizang-social-card-skill, especializado en generar gráficos 3:4 para Xiaohongshu y portadas para WeChat Official Accounts. Su enfoque técnico tiene una elección inusual: no utiliza ningún modelo de IA para generar píxeles de imagen; toda la composición se renderiza mediante HTML+CSS, y las imágenes de apoyo provienen de la búsqueda en bancos de fotos reales como Unsplash. Su salida no es una "imagen generada por IA", sino una captura de pantalla rasterizada por el motor de un navegador.
Esta elección responde a un cambio concreto. Desde 2026, Xiaohongshu ha implementado un modelo de reconocimiento audiovisual que analiza los patrones de distribución de píxeles en las imágenes y las características del audio para detectar contenido generado por IA. En el mismo periodo, se gestionaron más de 800.000 cuentas alojando IA y casi 150.000 notas falsificadas por IA. Para los creadores de contenido que necesitan producir imágenes y texto con alta frecuencia, la probabilidad de que las imágenes generadas por Midjourney o Canva AI sean detectadas y marcadas está en constante aumento. La Skill del Maestro Zang eligió otro camino: dejar que la IA tome las decisiones de maquetación y confiar los píxeles finales al motor de renderizado y a los bancos de fotos reales.
Esta es una desviación técnica deliberada. Pero hasta dónde pueda llegar este esquema depende de la elasticidad de la definición de "contenido generado/sintetizado por IA" por parte de la plataforma.
28 esqueletos de maquetación, la IA se encarga de la lógica del diseño, no de la pintura
El Maestro Zang, cuyo nombre real es Gui Zang, había lanzado anteriormente guizang-ppt-skill, otra herramienta de IA orientada al diseño de gráficos y texto. Esta social-card-skill está más enfocada: genera gráficos 3:4 para Xiaohongshu, y portadas 1:1 y 21:9 para WeChat Official Accounts, con resoluciones de salida de 1080×1440, 1080×1080 y 2100×900 respectivamente.
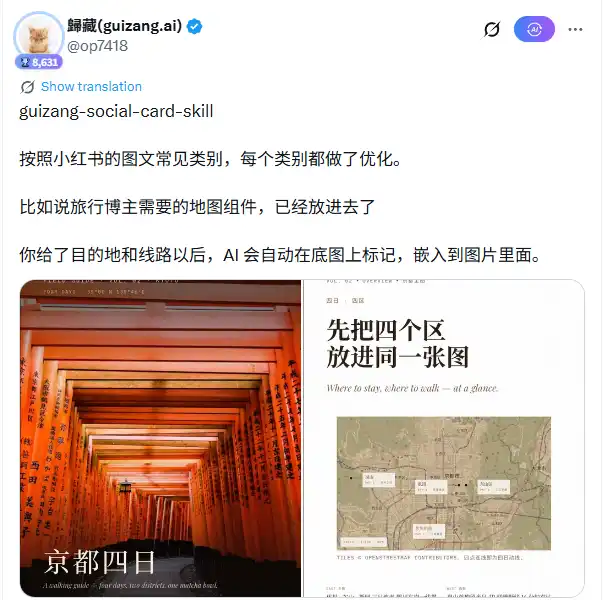
En cuanto a la arquitectura técnica, esta Skill incorpora 28 esqueletos de maquetación, divididos en dos sistemas visuales: Editorial (estilo revista, 16 plantillas) y Swiss (estilo Internacional Suizo, 12 plantillas), con 10 preajustes de paleta de colores temáticos. Después de que el usuario introduce un destino, itinerario o tema de la nota, la IA se encarga de seleccionar el esqueleto de maquetación adecuado, decidir la posición del texto, procesar los parámetros de anotación del mapa y luego escribir todas las decisiones de diseño en HTML+CSS. El motor de renderizado Playwright se hace cargo de los siguientes pasos, capturando pantalla página por página para generar PNG.
Un componente especialmente útil para los bloggers de viajes es el módulo de mapas. Utiliza MapLibre para cargar teselas reales de OpenStreetMap, admitiendo múltiples marcadores de ubicación y líneas de conexión. El usuario solo necesita proporcionar el nombre de la ciudad o el lugar de interés, y la IA genera automáticamente un mapa base con anotaciones y lo integra en el diseño. El flujo de trabajo para las fuentes de imágenes tiene una prioridad clara: las fotos reales proporcionadas por el usuario tienen la máxima prioridad; si no hay imágenes del usuario, se buscan automáticamente imágenes de apoyo en este orden: Unsplash → Pexels → Flickr CC → Wallhaven.

Todo el proceso se ejecuta en siete pasos: Intake (recepción de entrada) → Style & Theme (determinación de estilo y tema) → Layout Selection (selección de maquetación) → Asset Prep (preparación de activos) → Compose & Render (diseño y renderizado) → Deliver & Review (entrega y revisión) → Iterate (modificaciones iterativas). Cada paso se registra en archivos .poster dentro del directorio task. Para generar imágenes por lotes se ejecuta
node render.mjs, y Playwright renderiza cada una. Hay otro script de validación, validate-social-deck.mjs, que mide los elementos DOM en un entorno de navegador real, detectando problemas de maquetación como desbordamiento de texto, tamaño de fuente excesivo o colisión de elementos en el pie de página.
El objetivo de diseño de este mecanismo es claro: ser preciso y controlable como un software de maquetación para impresión, no libre pero impredecible como un modelo de difusión. El costo es que la libertad creativa se limita a 28 plantillas. Para creadores que dependen de un estilo fotográfico personal, elementos dibujados a mano o collages irregulares, estos esqueletos de maquetación no ofrecen una mejora de eficiencia, sino una restricción de diseño.
En cuanto a la barrera de entrada, la versión CLI requiere instalar Playwright, entorno Node, y obtener permisos de API para Claude Code o Codex. También hay una entrada web en xiaohongshu.guizang.ai para usuarios no desarrolladores, pero no hay información pública que compare si su integridad funcional es consistente con la versión CLI. Los tweets de X y las README actualizadas del desarrollador indican que este proyecto aún está en rápida iteración.
Los píxeles no provienen de modelos generativos, pero el cumplimiento no equivale a seguridad a largo plazo
La lógica de detección de contenido de IA de Xiaohongshu, según el análisis de información pública y documentación técnica, depende principalmente de un modelo de reconocimiento audiovisual. Este modelo analiza los patrones de distribución de píxeles en las imágenes para determinar si el contenido proviene de modelos generativos de IA. Los modelos de difusión y GAN dejan huellas estadísticas específicas a nivel de píxel al generar imágenes, que difieren de los patrones naturales de luz y sombra, distorsión de lente o ruido capturados por sensores de cámara. El objetivo de entrenamiento del modelo de reconocimiento audiovisual es precisamente capturar esta inconsistencia estadística.
La lógica de elusión de la Skill del Maestro Zang se basa en una distinción clave: los píxeles de sus imágenes de salida no provienen de ningún modelo generativo. El motor de renderizado HTML rasteriza los estilos CSS, y la distribución de píxeles resultante se parece más a una captura de pantalla de la interfaz del navegador o a la salida de software de autoedición. Las partes fotográficas provienen de material fotográfico real de bancos como Unsplash, imágenes capturadas por cámaras y procesadas manualmente, que no llevan las huellas de modelos de difusión.

Pero este distingo es válido solo bajo la premisa de que la definición de "contenido generado/sintetizado por IA" por parte de la plataforma se limite precisamente a la línea de "generación de píxeles por modelos de IA". El anuncio oficial de Xiaohongshu utiliza la expresión "contenido generado/sintetizado por IA", cuyo alcance no es estrecho. Si la plataforma amplía la definición a "salida renderizada por programa con diseño asistido por IA", o si incluye las características de renderizado de navegador de las imágenes rasterizadas HTML en el conjunto de entrenamiento del modelo de reconocimiento, la ventaja técnica actual de este esquema desaparecería.
La plataforma tiene la base técnica y la motivación de gobernanza para ampliar la definición. El propio modelo de reconocimiento audiovisual está en iteración continua. Si en los datos de entrenamiento se incluyen muchas muestras comparativas de imágenes renderizadas HTML frente a imágenes generadas por IA, el modelo puede aprender a distinguir entre las "características de suavizado subpixel del renderizado de fuentes en navegador" y los "bloques de píxeles irregulares generados por GAN al crear texto". Actualmente no hay información pública que indique que Xiaohongshu haya iniciado entrenamiento en esta dirección, pero desde el límite de capacidad del modelo, esta expansión es técnicamente factible.
Un elemento de cumplimiento más relevante tiene que ver con la gestión de mini programas. Actualmente no se ve documentación oficial que indique que esta Skill esté registrada con un número de registro de modelo o haya completado los trámites de cumplimiento pertinentes. Si la plataforma añade requisitos de trazabilidad de la cadena de herramientas en el flujo de revisión de contenido, la falta de información de registro podría convertirse en un nuevo punto de bloqueo.
Motores de plantillas por API, herramientas personalizadas para plataformas y renderizado HTML están trazando tres caminos divergentes
Al observar las herramientas del mercado que generan imágenes para redes sociales, se ve que se están dividiendo en tres rutas técnicas diferentes. Cada una enfrenta una estructura de riesgo de revisión distinta.
Generación directa de imágenes por modelos de IA. El representante de esta ruta es la función Magic Design lanzada por Canva AI en abril de 2026, que genera diseños que incluyen elementos visuales de IA directamente a partir de prompts de texto. Las imágenes generadas por Midjourney, DALL·E y otros modelos también pertenecen a esta categoría. El problema es claro: estas imágenes son el objetivo principal del modelo de reconocimiento audiovisual. La respuesta de Canva es fomentar el etiquetado transparente, no eludir la detección. En Xiaohongshu, no hay datos públicos que confirmen si las publicaciones con imágenes generadas por IA pierden peso en las recomendaciones tras ser etiquetadas, pero la política de "restricción de distribución de contenido de IA no identificado" ya está establecida. Cada actualización de versión del modelo de difusión puede cambiar las características estadísticas de los píxeles, y el modelo de detección correspondiente también se iterará, lo que enfrenta a los creadores con un blanco en constante movimiento.
Renderizado por motor de plantillas a través de API. Bannerbear es típico de esta ruta. El usuario crea una plantilla en un diseñador, modifica las variables de las capas enviando datos JSON a través de una API REST, y el servidor renderiza y devuelve PNG o JPG. Su núcleo también es "renderizado por programa" y no "generación de píxeles por modelo", por lo que la salida no contiene huellas de modelos de difusión. La diferencia con la Skill del Maestro Zang es que las plantillas de Bannerbear dependen del diseño manual; la IA no participa en las decisiones de maquetación; la Skill del Maestro Zang hace que Claude lea y escriba HTML directamente, delegando la elección de maquetación a la IA. El riesgo de la solución Bannerbear está en otra dimensión: cuando muchas cuentas utilizan la misma plantilla, la misma paleta de colores y la misma fuente para producir gráficos, incluso si cada imagen no es generada por IA, puede activar el reconocimiento de "producción masiva programática" por parte de la plataforma. Las condiciones para activar las reglas antispam no son idénticas a la detección de IA, pero para los creadores que gestionan cuentas en masa, el resultado sigue siendo una distribución restringida.
Generación personalizada para la plataforma. Pin Generator está diseñado específicamente para Pinterest, generando automáticamente imágenes de Pin que se ajustan a las preferencias del algoritmo de la plataforma. El núcleo de esta ruta no es eludir, sino adaptarse por completo: dimensiones, estilo visual, ritmo de publicación, todo se alinea con las normas de la plataforma. La ventaja es el riesgo de revisión más bajo; la desventaja es obvia: la capacidad de la herramienta está atada a las reglas de la plataforma; si Pinterest ajusta su algoritmo o restringe el uso de API de terceros, la herramienta deja de funcionar directamente. Comparada con la Skill del Maestro Zang, la primera es una herramienta exclusiva para una plataforma, la segunda es una solución genérica multiplataforma. La exclusiva es más segura pero más frágil; la genérica multiplataforma es más flexible pero más compleja, una compensación que aparece repetidamente en el campo de las herramientas de IA.
Las tres rutas tienen estructuras de riesgo diferentes. La generación por IA es la más libre, pero cada actualización responde a nuevos modelos de detección. El motor de plantillas es el más estable, pero puede ser afectado por reglas antispam. El renderizado HTML está entre ambos: la maquetación es controlada flexiblemente por la IA, los píxeles se dejan al navegador y a material fotográfico real, eludiendo la detección en el nivel de "generación de píxeles por IA", pero no puede hacer frente a una expansión semántica de las reglas por parte de la plataforma.
El límite superior del sistema de maquetación no está en el código, sino en el tipo de contenido
Los 28 esqueletos de maquetación cubren dos sistemas visuales principales: estilo revista y estilo suizo. Para los bloggers de viajes que necesitan mostrar rutas en mapas, líneas de tiempo o itinerarios de varios días, este sistema tiene una alta compatibilidad. La anotación de mapas y la conexión de itinerarios son la información central de estas notas, y los esqueletos de maquetación estructuran esa información manteniendo un aspecto profesional.
Pero el ecosistema de contenido de Xiaohongshu es mucho más rico que las guías de viaje. Las notas sobre moda dependen del estilo fotográfico personal y la paleta de colores, las reseñas de maquillaje requieren fotos macro en alta definición y comparaciones de productos, y el contenido de estilo de vida hace un uso intensivo de collages de varias imágenes y anotaciones manuscritas. El "diseño" de estos tipos de contenido no es una presentación estructurada de información, sino una expresión de estética y emoción personal. Los 28 esqueletos de maquetación no son una herramienta en este contexto, son una restricción.

Las limitaciones técnicas también son reales. Actualmente admite tres dimensiones: 1080×1440 (Xiaohongshu 3:4), 2100×900 (WeChat Official Account 21:9) y 1080×1080 (WeChat Official Account 1:1). No admite portadas verticales 9:16 para Douyin ni portadas horizontales 16:9 para Bilibili. Los bancos de imágenes dependen de Unsplash y Pexels, cuyo material tiende a fotografía de alta calidad, adecuada para viajes, paisajes y arquitectura urbana. Pero la cobertura de material frecuente para contenido vertical como primeros planos de comida, fotos de productos cosméticos o artículos de moda es limitada en estos bancos. La estrategia de priorizar imágenes del usuario puede aliviar parcialmente este problema, siempre que el creador tenga suficiente material fotográfico real acumulado.
El mecanismo de validación es un arma de doble filo. validate-social-deck.mjs puede interceptar problemas de maquetación antes de generar la imagen, garantizando que 100 renderizaciones por lotes salgan sin errores. Esto es una garantía de eficiencia en escenarios operativos que requieren docenas de imágenes diarias. Pero también significa que cualquier diseño que no cumpla las reglas predefinidas de las plantillas será rechazado por el script. Los creadores que quieran añadir un adorno de texto inclinado o un margen personalizado a una plantilla estándar no pueden simplemente arrastrar y ajustar como en Canva; necesitan editar directamente el código fuente HTML y CSS.
La barrera de despliegue local es otro punto de diferenciación. Los creadores que puedan ejecutar scripts Playwright y Node pueden personalizar profundizando en los esqueletos de maquetación y scripts de renderizado. Pero para la mayoría de los bloggers de Xiaohongshu, lo que encuentran es un subconjunto de funcionalidades en la interfaz web. Estas dos clases de usuarios obtienen un valor práctico muy diferente de esta Skill. Los usuarios centrales de los proyectos de código abierto son creadores y desarrolladores con conocimientos técnicos dispuestos a experimentar, no la demanda de "generar imágenes con un clic" del productor de contenido promedio.
No hay una respuesta universal, pero la divergencia de rutas técnicas en sí misma ya dice mucho
Un blogger de viajes de Xiaohongshu se enfrenta a tres opciones: usar Midjourney para generar imágenes de itinerario con estilo ilustrado, asumiendo el riesgo de ser etiquetado y penalizado; usar Bannerbear configurando una plantilla e inyectando datos masivamente cada día, asumiendo el riesgo de homogeneidad que conllevan las reglas antispam; o usar la Skill del Maestro Zang, dejar que la IA elija la maquetación y renderizar la imagen con HTML, asumiendo el riesgo de que la plataforma amplíe la definición de "contenido sintetizado". No hay una carta segura, solo combinaciones de diferentes estructuras de riesgo.
Este panorama transmite por sí mismo un mensaje: la iteración de confrontación entre la plataforma y las herramientas de IA ya ha comenzado. Cada vez que la plataforma actualiza su modelo de detección, termina el período de ventaja técnica de un conjunto de herramientas. Cada vez que una nueva herramienta encuentra una ruta de elusión, la plataforma ajusta su estrategia. Este no es un proceso que converja en un estado estable. La validez de la solución de renderizado HTML depende de si la dirección de entrenamiento del modelo de reconocimiento audiovisual de Xiaohongshu sigue centrándose en las "características de píxeles de modelos de difusión" o se expande a "todos los píxeles que no sean de fotografía nativa".
Para los creadores de contenido, distinguir entre "IA asistencial" y "IA sustitutiva" adquiere un significado práctico. La postura de la plataforma es clara: fomenta la IA como amplificador creativo, se opone al uso de la IA para sustituir la producción masiva de baja calidad. En la Skill del Maestro Zang, la IA toma decisiones de maquetación, no genera contenido; las fotos son reales, las maquetaciones son esqueletos prediseñados por humanos. Esto cae precisamente en el ámbito de la "IA asistencial". Aquellas publicaciones en las que tanto el texto como las imágenes están generados completamente por modelos generativos son las que la plataforma quiere combatir claramente.
Aún no está claro si esta distinción se convertirá en un criterio operativo para la revisión de la plataforma. Pero los desarrolladores de herramientas ya están respondiendo a esta definición con sus elecciones técnicas.