Nota del editor: Cuando "la IA escribe código" se convierte gradualmente en un consenso de la industria, lo que realmente cambia la productividad no es el modelo en sí, sino cómo defines las reglas para el modelo, organizas el flujo de trabajo y lo integras en un sistema que puede funcionar de manera sostenible.
Partiendo de un simple archivo CLAUDE.md, pasando por la colaboración de múltiples agentes, hasta un ciclo de desarrollo automatizado, este método transforma el proceso de desarrollo de un "diálogo entre el humano y la IA" a la "gestión de un equipo de ingeniería de IA". En este proceso, los errores se previenen de forma anticipada, los flujos se estructuran, y la generación de código, las pruebas y las revisiones dejan de ser ejecutadas manualmente para ser gestionadas por el sistema.
Es más, el artículo también revela un detalle que a menudo se pasa por alto: en contextos largos y sistemas complejos, el comportamiento del modelo no es completamente controlable. Tanto el consumo oculto de tokens como la dilución de las instrucciones afectan invisiblemente la calidad de la salida. Esto hace que "cómo gestionar la IA", y no solo "cómo usar la IA", se convierta en la nueva capacidad central.
En este punto, los desarrolladores ya no se centran en codificar, sino que su trabajo gira en torno al diseño de reglas, la planificación de flujos y la verificación de resultados. Aquellos que dan este paso primero ya han comenzado a pasar de "hacer las cosas personalmente" a "dejar que el sistema lo haga por ellos".
A continuación, el texto original:
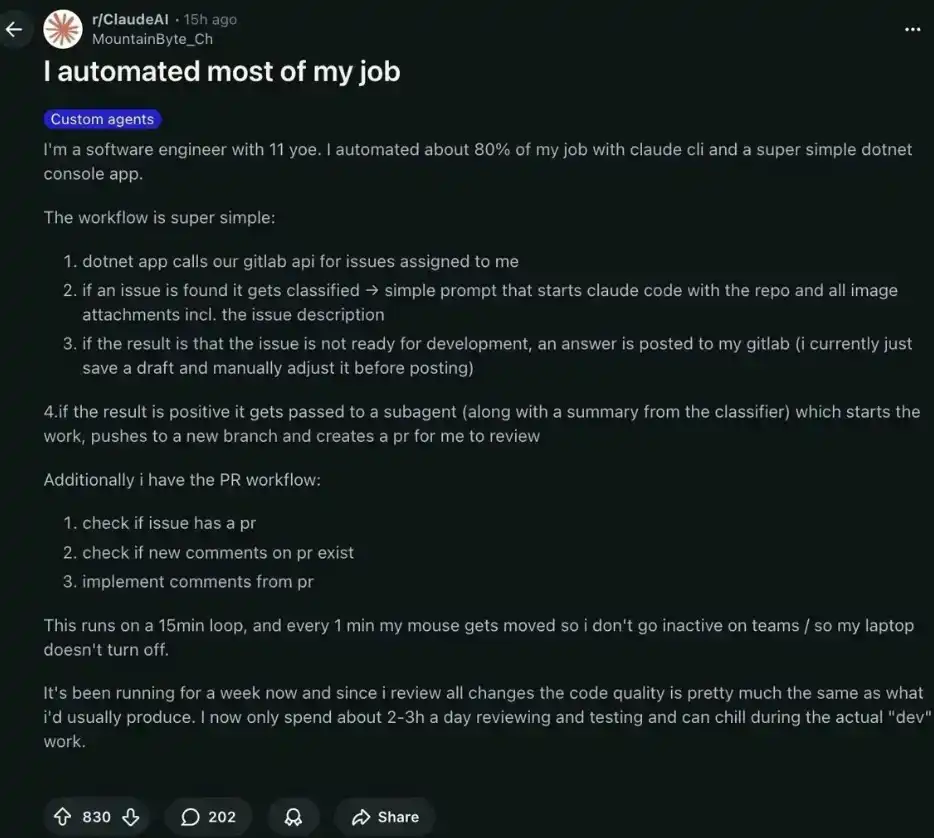
Un ingeniero de Google con 11 años de experiencia ha automatizado el 80% de su trabajo con la ayuda de Claude Code y una simple aplicación .NET.
Hoy en día, solo necesita trabajar 2 a 3 horas al día, en lugar de las 8 originales. El resto del tiempo básicamente está "relajado", mientras el sistema funciona por sí solo, generándole unos ingresos pasivos de 28,000 dólares mensuales.
Lo que él domina es precisamente ese método que tú aún desconoces.
Parte 1—Escribir un CLAUDE.md según los principios de Karpathy
Andrej Karpathy—uno de los investigadores de IA más influyentes del mundo—resumió sistemáticamente los errores más comunes de los grandes modelos de lenguaje al escribir código: sobreingeniería, ignorar patrones existentes e introducir dependencias adicionales que nadie pidió.
Alguien resumió estas observaciones y las organizó en un archivo unificado llamado CLAUDE.md.
El resultado: este proyecto obtuvo 15,000 estrellas en GitHub en una semana. En cierto modo, se puede decir que 15,000 personas cambiaron su forma de trabajar gracias a esto.
La idea central es muy simple: si los errores son predecibles, se pueden evitar por adelantado con instrucciones claras. Basta con colocar un archivo markdown en el repositorio del proyecto para proporcionar a Claude Code un conjunto completo de reglas de comportamiento estructuradas, unificando así la toma de decisiones y la ejecución en todo el proyecto.
Este archivo contiene principalmente cuatro principios centrales:
· Pensar antes de codificar → Evitar suposiciones erróneas y compensaciones ignoradas.
· La simplicidad primero → Evitar la sobreingeniería y las abstracciones hinchadas.
· Modificaciones quirúrgicas → Evitar modificar código que nadie ha pedido cambiar.
· Ejecución orientada a objetivos → Primero probar, luego verificar según criterios de éxito claros.
No depende de ningún framework ni de herramientas complejas: con un solo archivo, puedes cambiar el comportamiento de Claude a nivel de proyecto.
La verdadera diferencia radica en:
· Sin usar CLAUDE.md: Claude viola las especificaciones aproximadamente en el 40% de los casos.
· Usando el CLAUDE.md de Karpathy: La tasa de violaciones se reduce a aproximadamente un 3%.
· Tiempo de configuración: Solo 5 minutos.
Comando para generar automáticamente tu propio archivo CLAUDE.md:
claude -p "Lee todo el proyecto y crea un CLAUDE.md basado en:
Pensar Antes de Codificar, La Simplicidad Primero, Cambios Quirúrgicos, Ejecución Orientada a Objetivos.
Adáptate a la arquitectura real que veas." --allowedTools Bash,Write,Read
Esto reemplaza a un Claude que, ante tareas simples, hace sobreingeniería, introduce dependencias no solicitadas e incluso modifica archivos que no debería tocar.
Parte 2 - Everything Claude Code: Un equipo de ingeniería completo en un repositorio
Everything Claude Code (más de 153,000 estrellas en GitHub)
Esto no es solo un conjunto de prompts, sino más bien un sistema operativo de IA completo para construir productos.
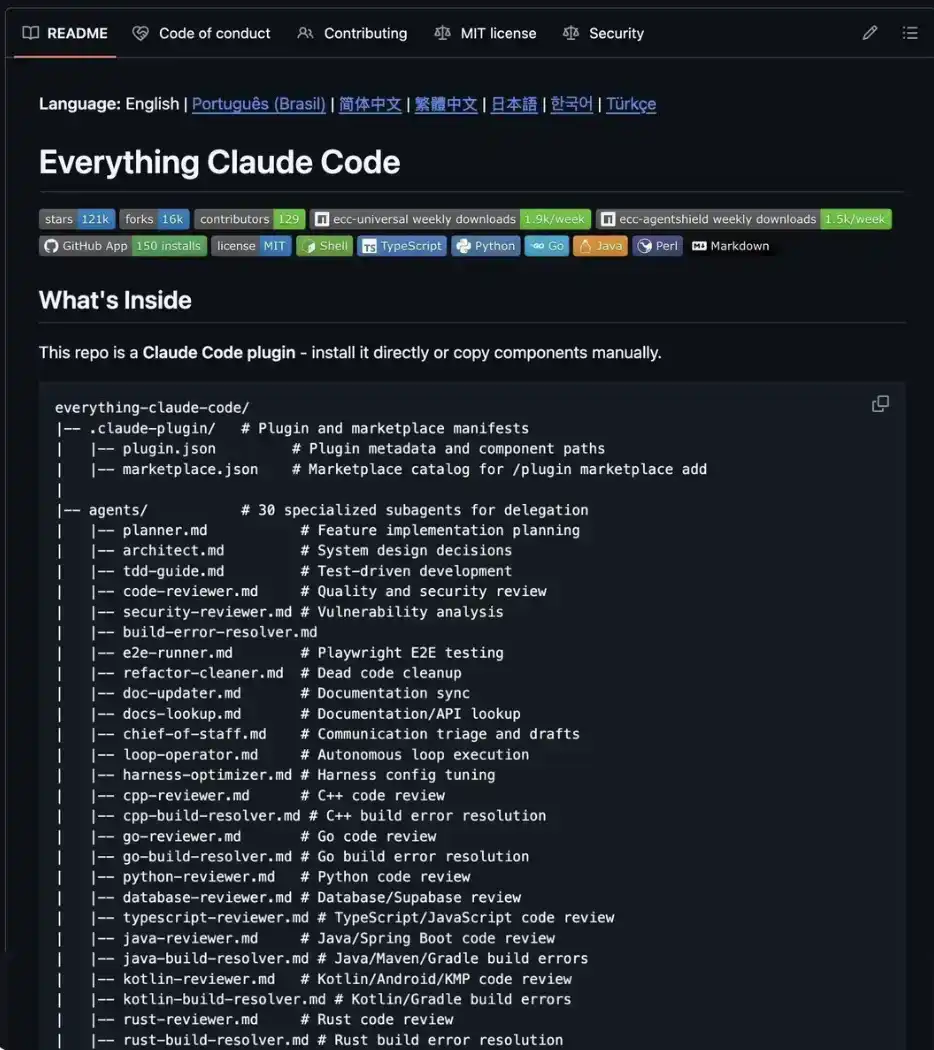

Funciona en Claude, Codex, Cursor, OpenCode, Gemini y muchas otras herramientas: un sistema único, usable en todas partes.
Forma de instalación:
/plugin marketplace add affaan-m/everything-claude-code
O instalación manual: simplemente copia los componentes que necesites al directorio .claude/ de tu proyecto. No cargues todo de una vez: cargar 27 agentes y 64 habilidades simultáneamente probablemente agotará tu límite de contexto incluso antes de que ingreses tu primer prompt. Mantén solo lo que realmente necesites.
La verdadera diferencia está en:
· Antes: Estabas con una IA.
· Después: Gestionas un equipo de ingeniería de IA que funciona automáticamente.
Reemplaza: Tener que pasar semanas construyendo tu propio sistema de agentes, configurando por separado herramientas de planificación/revisión/seguridad, y pagar costos mensuales de 200 a 500 dólares por varios servicios de IA.
Parte 3 - Un "escándalo" oculto: Claude Code v2.1.100 está consumiendo tus tokens en secreto
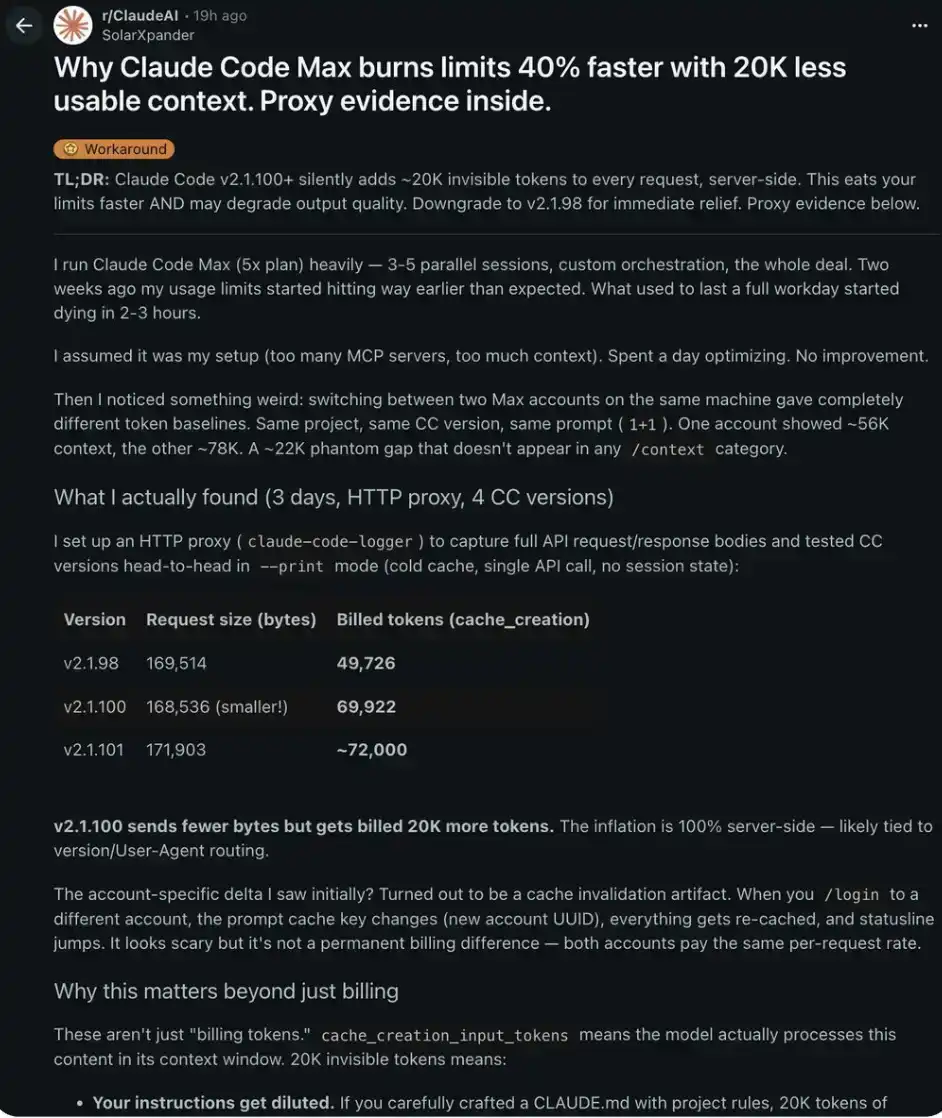
Alguien configuró un proxy HTTP e interceptó y analizó las solicitudes API completas de 4 versiones diferentes de Claude Code.
Descubrieron:
v2.1.98: 169,514 bytes solicitados → 49,726 tokens facturados
v2.1.100: 168,536 bytes solicitados → 69,922 tokens facturados
diferencia: -978 bytes pero +20,196 tokens
v2.1.100 envió menos bytes de datos, pero cobró 20,000 tokens adicionales. Esta "inflación" ocurre completamente en el lado del servidor: no puedes verla ni verificarla a través de la interfaz /context.
Por qué esto es importante más allá de la facturación: estos 20,000 tokens adicionales se incorporan a la ventana de contexto real de Claude.
Esto significa:
→ Tus instrucciones CLAUDE.md se diluirán con estos 20,000 "contenidos ocultos".
→ En conversaciones largas, la calidad de la salida se degradará más rápido.
→ Cuando Claude ignore tus reglas, te resultará difícil encontrar la causa.
→ El límite de uso de Claude Max se consumirá aproximadamente un 40% más rápido de lo normal.
La solución toma solo 30 segundos: npx [email protected]
Esta es una solución temporal hasta que Anthropic solucione el problema oficialmente, pero en la práctica, puedes notar inmediatamente el cambio en la efectividad de la sesión.
Reemplaza: Ya no necesitas adivinar por qué Claude de repente dejó de seguir tus instrucciones.
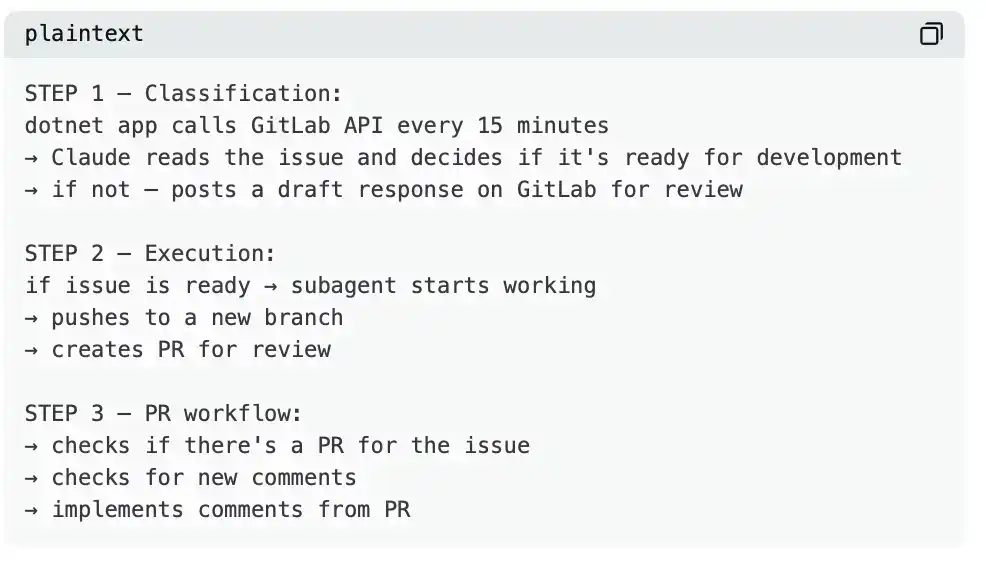
Caso de estudio: Cómo es un sistema de automatización completo
Un ingeniero con 11 años de experiencia construyó un sistema compuesto por tres partes:
Resultado después de una semana:
· Antes: 8 horas al día escribiendo código.
· Después: Solo 2–3 horas al día haciendo revisiones de código y pruebas.
· Calidad del código: Básicamente sin cambios, porque las revisaba una por una.
· Estado en Teams: Siempre en línea: el mouse se movía automáticamente cada minuto.
· Tiempo restante: Libre todo el día.
Esto no es "magia", sino el resultado combinado de CLAUDE.md + los agentes adecuados + un mecanismo de ciclo cada 15 minutos.
Lista completa:

Qué obtienes después de leer esto:
· Antes: Claude violaba las especificaciones existentes en el 40% de los casos.
· Después: Usando el CLAUDE.md de Karpathy, la tasa de violaciones bajó al 3%.
· Antes: Necesitabas semanas para configurar agentes.
· Después: 27 agentes listos para usar.
· Antes: El límite de Claude Max se agotaba en 2–3 horas.
· Después: Revertir a v2.1.98 recupera aproximadamente un 40% del límite de uso.
· Antes: 8 horas al día escribiendo código.
· Después: Solo 2–3 horas haciendo revisiones, el resto lo ejecuta el sistema automáticamente.
· Tiempo de configuración: 15–20 minutos.
· Ahorro diario: 5–6 horas.
· Ahorro mensual: 100–120 horas.
Si el valor de tu tiempo es de 30 dólares por hora, en realidad estás "perdiendo invisiblemente" 3000–3600 dólares al mes.
Si es de 100 dólares por hora, son 10,000–12,000 dólares mensuales que se esfuman, solo porque todavía escribes manualmente el código que Claude podría haber hecho por sí mismo.
La mayoría de los desarrolladores nunca alcanzarán este nivel, no porque no puedan, sino porque piensan que es complicado. En realidad, entre tú y la "automatización total" solo hay tres comandos y un archivo de diferencia.
El ingeniero que mencioné al principio no es un genio, ni un ingeniero senior de Google. Simplemente dedicó una noche a configurar el sistema. Desde entonces, el trabajo lo hace el sistema, y él solo se encarga de vivir.
Tú puedes hacer lo mismo esta noche. Mientras otros todavía discuten si la IA reemplazará a los desarrolladores, aquellos que ya tienen el sistema funcionando solo están relajándose y ganando dinero.
La elección es clara. Estás construyendo tu propia vida: elige el camino correcto.