Autor: Fei-Fei Li
Compilación: Jiayang
"Modelo del mundo" es probablemente el concepto más caliente y confuso en el campo de la IA desde 2025. Cuando salió Sora, OpenAI lo llamó simulador del mundo; Genie te deja caminar por las imágenes generadas y también se llama modelo del mundo; las empresas de robótica dicen que están haciendo modelos del mundo, NVIDIA dice que Omniverse es la infraestructura para los modelos del mundo, e incluso los motores de juego han sido arrastrados a esta narrativa. Todo el mundo usa la misma palabra, pero cada uno se refiere a algo completamente diferente.
Hoy, Fei-Fei Li publicó un nuevo artículo en su Substack, aclarando este concepto. Primero vuelve al gráfico clásico de los libros de texto de aprendizaje por refuerzo (el bucle cerrado POMDP: agente → acción → estado → observación → agente), y luego señala: las cosas que ahora se llaman "modelos del mundo" son en realidad tres proyecciones diferentes de este bucle cerrado. Lo que produce píxeles (observación) es el renderizador, lo que produce el estado es el simulador, y lo que produce la acción es el planificador. El criterio de clasificación es muy simple: depende de qué parte del bucle cerrado se produce.

(Fuente: MIT Technology Review)
Ella juzga que, entre los tres, el renderizador es el más maduro comercialmente pero tiene un techo (que se vea bien no significa que sea físicamente correcto), el planificador es el más emocionante pero está más lejos del despliegue real (la brecha entre demostraciones de laboratorio y usabilidad práctica sigue siendo enorme), y el simulador es un eje clave gravemente subestimado. Porque el simulador trabaja a nivel de geometría, física y dinámica, puede proyectar hacia arriba para crear píxeles para consumo humano, y también derivar hacia abajo las consecuencias de las acciones para uso robótico. Dominar la simulación proporciona simultáneamente la base para el renderizado y la planificación; lo contrario no es cierto.
Este artículo también es un manifiesto de producto para World Labs. Su Marble ya está produciendo simultáneamente Gaussian splats y mallas de colisión, intentando unificar el renderizador y el simulador en un solo modelo. La visión al final del artículo es un modelo base unificado del mundo, capaz de cambiar libremente entre renderizado, simulación y planificación según las necesidades posteriores. Si esta visión se puede lograr o no es otra cuestión, pero como marco de análisis, la tricotomía renderizador/simulador/planificador quizás sí ayude a penetrar parte del ruido del concepto actual de "modelo del mundo".
Se traduce el texto completo a continuación.
"El mundo es todo lo que ocurre." — Wittgenstein, Tractatus Logico-Philosophicus, 1921
El mundo no está hecho de palabras.
En un artículo anterior, propusimos que la inteligencia espacial es la próxima frontera de la IA, y los modelos del mundo son el camino hacia ella. Aquí, el equipo de World Labs y yo queremos profundizar un nivel más: entre las muchas cosas que hoy llevan el nombre de "modelo del mundo", ¿qué módulos funcionales constituyen realmente esta capacidad? ¿Y para qué sirve cada uno?
Los modelos de lenguaje han otorgado a las máquinas un poderoso dominio sobre conceptos, vocabulario y razonamiento, pero el mundo físico, ya sea virtual o real, opera en un sustrato completamente diferente. Los modelos de lenguaje aprenden la estructura estadística del texto, los modelos del mundo aprenden la estructura estadística del espacio y el tiempo: cómo cae la luz sobre una superficie, cómo se ve un jardín desde un ángulo nunca captado por una cámara, cómo los objetos responden a las fuerzas y siguen las leyes físicas.
Esto hace de "modelo del mundo" uno de los términos más importantes y, al mismo tiempo, más abusados en el campo actual de la IA. La visión por computadora, la robótica, el aprendizaje por refuerzo y la IA generativa afirman estar construyendo modelos del mundo, pero cada una se refiere a cosas radicalmente diferentes. Un modelo de video que genera llamas espléndidas pero físicamente imposibles, un modelo de lenguaje que improvisa un juego jugable, un motor de física que simula fielmente el proceso de combustión, todos reciben el mismo nombre.
Los antiguos griegos nunca pudieron ponerse de acuerdo sobre de qué estaba hecho el mundo, ya fuera fuego, agua o átomos indivisibles, porque "mundo" nunca fue una sola cosa. Siempre fue un sustituto que un pensador usaba para razonar sobre algún tipo de totalidad. La IA heredó el mismo problema, y justo en el momento en que este campo más necesita precisión.
El bucle cerrado detrás de la taxonomía
Para aclarar este caos, podemos empezar con un gráfico más antiguo que todas las tecnologías mencionadas. Todos los libros de texto de aprendizaje por refuerzo, incluidos los clásicos de Sutton y Barto, han utilizado durante décadas variantes del mismo gráfico para describir cómo un agente interactúa con el mundo. El nombre formal de este gráfico es Proceso de Decisión de Markov Parcialmente Observable (POMDP), y la definición original del término "modelo del mundo" pertenece a esta tradición.
Un agente (puede ser una persona, un robot o un sistema de software) ejecuta una acción. Esa acción cambia el estado del mundo. Pero el agente nunca ve directamente el estado en sí; lo que recibe es una observación: fotones que golpean la retina, lecturas de sensores, píxeles en un fotograma de video. La nueva observación guía una nueva acción, y el ciclo se repite.
La palabra "estado" necesita desglosarse, porque su significado cambia en diferentes campos. No es el estado del químico, la distinción entre sólido, líquido y gaseoso. Es el estado del físico y el roboticista: una descripción completa de todo lo que ocurre en el mundo en un momento dado, incluyendo cada objeto, cada posición, cada velocidad, cada atributo. El estado es la realidad subyacente del mundo, en principio completa, pero para cualquier agente que esté en él, nunca es directamente observable. La observación es la perspectiva local del agente sobre esa realidad. La acción es la respuesta del agente basada en ella.
Este bucle cerrado (agente → acción → estado → observación → agente) es precisamente la estructura que da al término "modelo del mundo" su significado técnico. La frase en sí es aún más antigua, se remonta a la propuesta de Kenneth Craik en 1943 de que la mente razona ejecutando "modelos a pequeña escala" de la realidad, y a finales de los 80 y principios de los 90 este concepto se introdujo en el campo de las redes neuronales. Este bucle también explica lo que la gente quiere decir hoy cuando usa el término. Las diversas cosas que ahora se llaman modelos del mundo son en realidad proyecciones diferentes del mismo bucle cerrado, cada una produciendo una parte diferente del bucle.
Las tres funciones de los modelos del mundo
El primer tipo de modelo del mundo es el renderizador. El renderizador produce observaciones, específicamente píxeles orientados al ojo humano, y la métrica de calidad más importante es la fidelidad visual. Un modelo de video que convierte un mensaje de texto en planos aéreos de calidad cinematográfica es un renderizador; sistemas interactivos como Genie 3 de Google o el propio RTFM de World Labs también son renderizadores, generan imágenes en tiempo real según la entrada del usuario. Este tipo de modelo no posee una comprensión explícita de la estructura tridimensional. Genera lo que un espectador vería, no cómo son las cosas en sí mismas. Los edificios en un plano aéreo pueden parecer perfectos desde el cielo, pero intenta navegar por la ciudad debajo y se derrumbarán.
El segundo es el simulador. El simulador produce el estado: una representación del mundo fiel en términos de geometría, física o dinámica, sobre la que tanto humanos como programas de computadora pueden calcular e interactuar. El contrato del renderizador es puramente visual, mientras que el contrato del simulador es estructural; requiere geometría que aguante el escrutinio, física que siga las leyes de Newton, dinámica que se comporte como dictan las leyes físicas. El simulador sirve a dos tipos de usuarios. Profesionales como arquitectos, diseñadores, cineastas, desarrolladores de videojuegos necesitan una precisión que vaya más allá de la credibilidad visual. Programas de computadora como agentes de aprendizaje por refuerzo, controladores robóticos, vehículos autónomos usan el simulador como campo de entrenamiento, interactuando con el mundo a gran escala, probando escenarios que en la realidad serían peligrosos, caros o simplemente imposibles de ejecutar.
El tercero es el planificador. El planificador produce acciones. Dada una observación y un objetivo, el planificador responde a la pregunta: ¿qué debe hacer el agente a continuación? En muchos sentidos, el planificador es el proceso inverso del renderizador. El renderizador toma acciones como entrada y produce observaciones; el planificador toma observaciones como entrada y produce acciones, cerrando así el bucle percepción-acción. Los modelos de visión-lenguaje-acción (VLA), los sistemas basados en modelos, y la nueva ola de Modelos de Acción del Mundo (World Action Models), son todos intentos de planificación: hacer que un sistema pueda decidir qué debe hacer un robot en un mundo no estructurado.
Estas tres categorías cubren la mayor parte del trabajo que se está implementando actualmente, y su distinción es útil en la práctica. Pero estas tres categorías no están fundamentalmente separadas. Comparten el mismo conocimiento subyacente sobre cómo funciona el mundo: geometría, física, dinámica. Un modelo que pueda renderizar una taza desde cualquier ángulo, en principio también debería poder simular qué pasa si se empuja la taza y planificar que una mano la recoja. Investigaciones cada vez más interesantes están borrando deliberadamente los límites entre los tres.
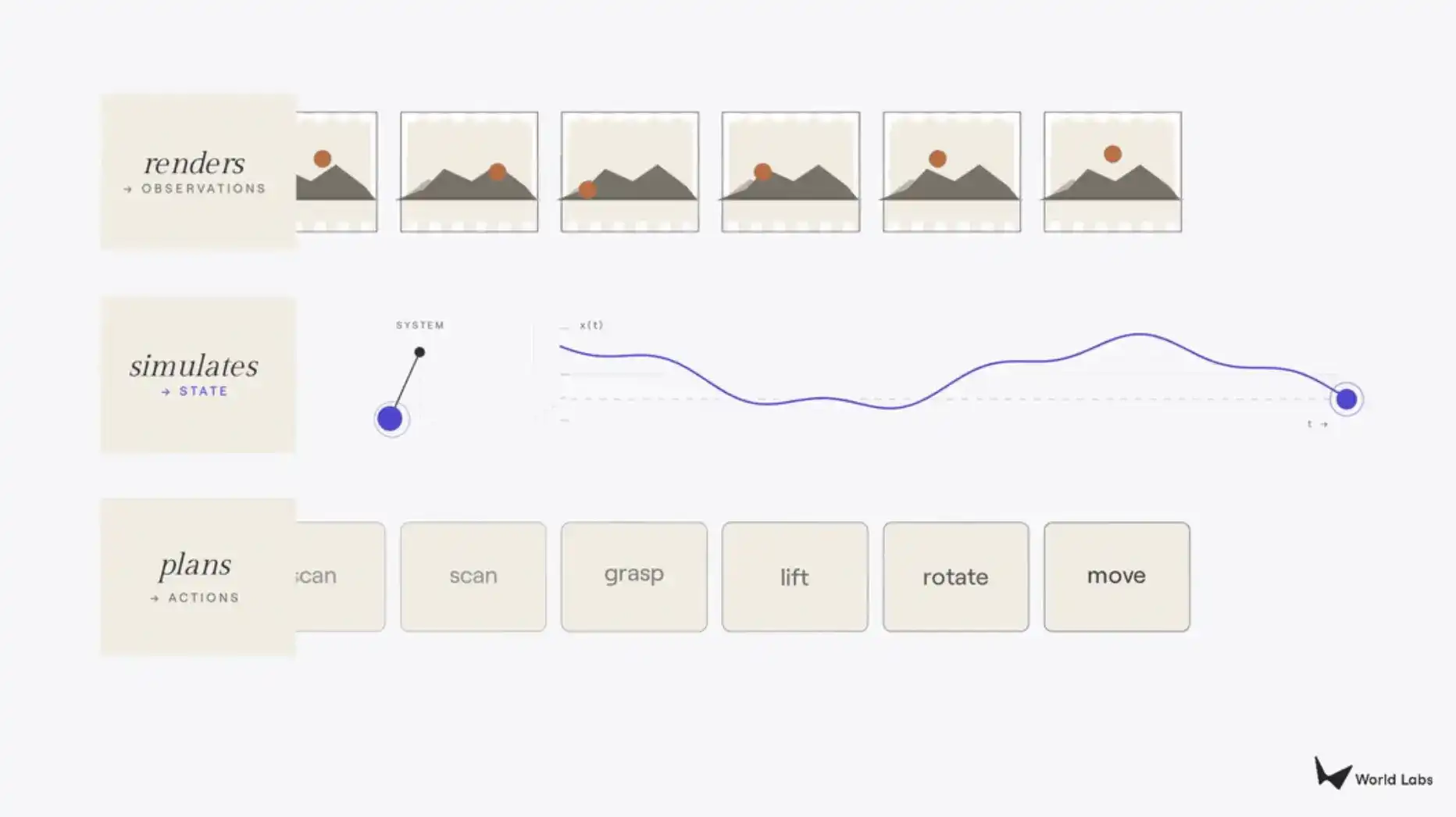
Figura丨Tres tipos de modelos del mundo (Fuente: Substack)
Por qué la simulación es el eje clave
Entre las tres categorías, el simulador recibe la menor atención pública, pero es el más importante de los tres. Este artículo quiere corregir esa asimetría.
El renderizador es actualmente el más maduro comercialmente. Una gran cantidad de productos de imagen-a-video o texto-a-video se están expandiendo rápidamente en mercados de consumo y empresariales. El modelo Nano Banana de Google ha llevado capacidades de generación de imágenes a nivel de renderizador a potencialmente cientos de millones de usuarios. La tecnología es real, el mercado es real. Sin embargo, el objetivo de optimización del renderizador es la credibilidad visual, no la precisión física, y este techo es importante. Su salida es hermosa, pero no puedes usarla para diseñar un edificio o entrenar un robot.
El planificador es el más emocionante y el menos maduro, estrechamente relacionado con el campo de rápido desarrollo del aprendizaje robótico. En los últimos dos años, este campo ha producido muchas demostraciones robóticas impresionantes en video, pero debemos ser honestos sobre lo que realmente muestran estas demostraciones. Casi todas se limitan a entornos de laboratorio altamente restringidos, con tipos de objetos limitados y duraciones de tarea cortas. Ninguna ha sido validada con la complejidad, diversidad y duración continua que exige un despliegue en el mundo real. La brecha entre un video de demostración impresionante y un robot que funcione de manera confiable en una cocina, un almacén o un quirófano sigue siendo enorme.
Aun así, el tamaño de las apuestas comerciales sigue siendo considerable. Una ola de nuevos actores con fondos importantes compite por lanzar sistemas de planificación general, mientras que los grandes jugadores de infraestructura están construyendo capacidades de planificación sobre pilas de simulación más amplias.
La simulación es el puente que conecta ambos. Si el lenguaje es una abstracción del mundo y los píxeles son una proyección del mundo, entonces la geometría, la física y la dinámica son el mundo mismo. El simulador debe operar a este nivel: es el esqueleto estructural a partir del cual pueden derivarse tanto la representación visual (para el renderizador) como las consecuencias de las acciones (para el planificador).
Un modelo que domina la simulación puede proyectar su comprensión en píxeles para consumo humano, y también en predicciones de acciones para agentes corporizados. Un modelo que solo domina el renderizado o solo la planificación no puede hacer ninguna de las dos cosas. El espacio comercial aquí es extremadamente amplio. Solo el Omniverse de NVIDIA, se estima que su mercado objetivo supera el billón de dólares, abarcando fábricas, almacenes, cadenas de suministro y gemelos digitales. El entrenamiento de robots, las pruebas de conducción autónoma, la visualización arquitectónica, la ingeniería de diseño, el descubrimiento de fármacos, todos dependen de alguna forma de simulación.
Las cuestiones abiertas más difíciles en este campo también se concentran aquí. Los datos 3D con geometría explícita, propiedades de materiales y anotaciones físicas son varios órdenes de magnitud más escasos que los videos de Internet utilizados para entrenar renderizadores. La brecha simulación-realidad (la diferencia entre el comportamiento de los objetos en la simulación y en el mundo real) persiste. Los simuladores generativos introducen además nuevos riesgos: la geometría generada por IA puede parecer correcta, pero de hecho contener intersecciones o proporciones erróneas, lo que lleva a resultados absurdos en la simulación física. El costo computacional de la simulación multifísica a gran escala (cuerpos rígidos, objetos deformables, fluidos, tela interactuando todos simultáneamente) sigue siendo varios órdenes de magnitud mayor que la simulación de un solo dominio.
En World Labs, Marble es nuestro primer paso en esta dirección. Acepta entradas multimodales (texto, imágenes, video o bocetos espaciales), genera entornos 3D explorables, y produce simultáneamente Gaussian splats para exploración visual y mallas de colisión para que los motores físicos las operen. Pero Marble es solo el primer capítulo de un largo arco. A medida que los límites entre renderizado, simulación y planificación comienzan a desdibujarse, todo el campo está escribiendo esta historia.
Los límites se desdibujan, y qué pasará después
La tendencia más importante en este campo actualmente es que las tres categorías están empezando a fusionarse. El consenso subyacente es: el conocimiento necesario para renderizar un mundo, simularlo y actuar en él es en gran medida el mismo. Siguiendo el ejemplo anterior, un modelo que realmente entiende cómo se coloca una taza sobre una mesa (su forma geométrica, propiedades materiales, respuesta a fuerzas, etc.) debería poder renderizar esa taza desde cualquier ángulo, simular qué pasa si se empuja, y planificar que una mano la recoja. Las tres categorías son tres proyecciones de la misma comprensión subyacente.
Por ejemplo, trabajos recientes, aunque pocos pero en crecimiento, de diferentes laboratorios de robótica han demostrado una posibilidad al menos conceptualmente viable: un renderizador de video preentrenado puede servir como red troncal para la predicción conjunta del mundo y las acciones, permitiendo que un solo modelo imagine simultáneamente "qué pasará" y "qué hacer", tendiendo así un puente entre renderizador y planificador. Marble de World Labs ya puede producir simultáneamente Gaussian splats y mallas de colisión desde un solo modelo, disolviendo el límite entre renderizador y simulador. Cada nivel está pasando de la producción pasiva a sistemas interactivos: los renderizadores se vuelven sensibles a las condiciones de acción, los mundos generados por simuladores se vuelven más controlables y editables, los planificadores comienzan a razonar deliberativamente en lugar de solo reaccionar.
El punto final lógico es un modelo del mundo unificado: un modelo base capaz de renderizar vistas fotorrealistas, generar estructuras físicamente precisas, planificar secuencias de acciones, y cambiar entre diferentes modalidades de salida según las necesidades del usuario final. Aún enfrentaremos una serie de desafíos severos. El panorama de datos está extremadamente desequilibrado, con los renderizadores teniendo acceso a vastos videos de Internet, mientras que los simuladores y planificadores enfrentan una grave escasez de activos 3D y datos de demostración robótica. La optimización para el atractivo visual puede sacrificar la precisión requerida por la robótica o la simulación de alta fidelidad. Conciliar estas tensiones dentro de una única arquitectura es el problema central abierto en la investigación actual de modelos del mundo, y lo que World Labs se esfuerza por resolver a medida que Marble evoluciona.
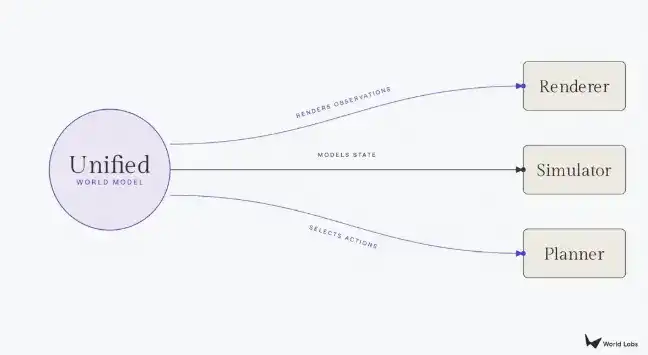
(Fuente: Substack)
Pero la dirección general ya es clara. Desde finales de los años 80 hasta hoy, la apuesta de este campo siempre ha sido la misma: si el modelo del mundo es lo suficientemente rico, contendrá todo lo necesario para que un agente vea el mundo, lo construya y actúe en él. Esta apuesta está impulsando ahora la investigación de toda una generación. Y lo que realmente le da peso es la fusión que ya está ocurriendo: las tres líneas de renderizado, simulación y planificación, cada una ya sosteniendo industrias de miles de millones de dólares, comenzaron como direcciones de investigación independientes y ahora comienzan a converger. Cuando los límites desaparezcan, la confluencia de los tres redefinirá algo más grande: la relación entre la inteligencia de las máquinas y el mundo físico que habita, es decir, la dirección a largo plazo de la inteligencia espacial.
El lenguaje le dio a las máquinas una forma de hablar sobre este mundo. Los modelos del mundo son la vía por la que las máquinas finalmente llegan a comprender, imaginar, razonar e interactuar con él.
Referencias: 1.https://drfeifei.substack.com/p/a-functional-taxonomy-of-world-models





