¡Acaba de llegar DeepSeek-V4!
La versión preliminar ya está disponible y se ha lanzado como código abierto simultáneamente.
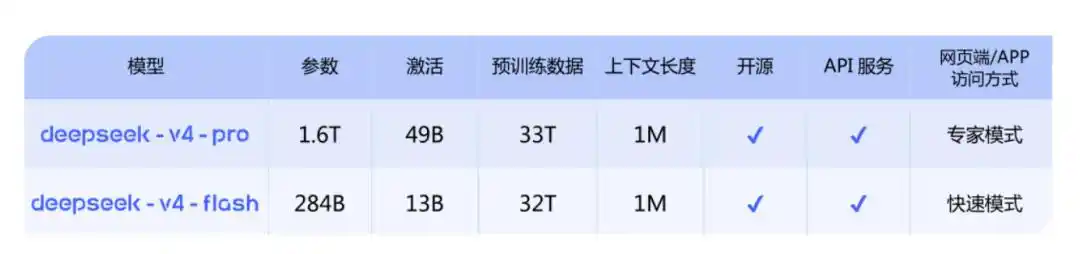
Hay dos versiones:
DeepSeek-V4-Pro: comparable con los mejores modelos cerrados, 1.6T, 49B de activación, longitud de contexto de 1M;
DeepSeek-V4-Flash: una versión económica más pequeña y rápida, 284B, 13B de activación, longitud de contexto de 1M.
Las palabras oficiales son: En capacidades de agente, conocimiento del mundo y rendimiento de razonamiento, logra un liderazgo tanto a nivel nacional como en el campo del código abierto.
Y además:
Actualmente, DeepSeek-V4 se ha convertido en el modelo de Agentic Coding utilizado por los empleados internos de la empresa. Según las evaluaciones, la experiencia de uso es superior a Sonnet 4.5, y la calidad de entrega se acerca al modo no reflexivo de Opus 4.6. Sin embargo, aún existe una brecha con el modo reflexivo de Opus 4.6.
Actualmente, tanto el sitio web oficial como la aplicación están actualizados, y el servicio API también se ha actualizado simultáneamente.
En cuanto a la capacidad de computación nacional que a todos preocupa, punto clave: en la segunda mitad del año, se admitirá la capacidad de computación de Huawei.

Opción de gama alta y relación calidad-precio, dos versiones lanzadas juntas
Esta vez, V4 lanza dos versiones de una vez.
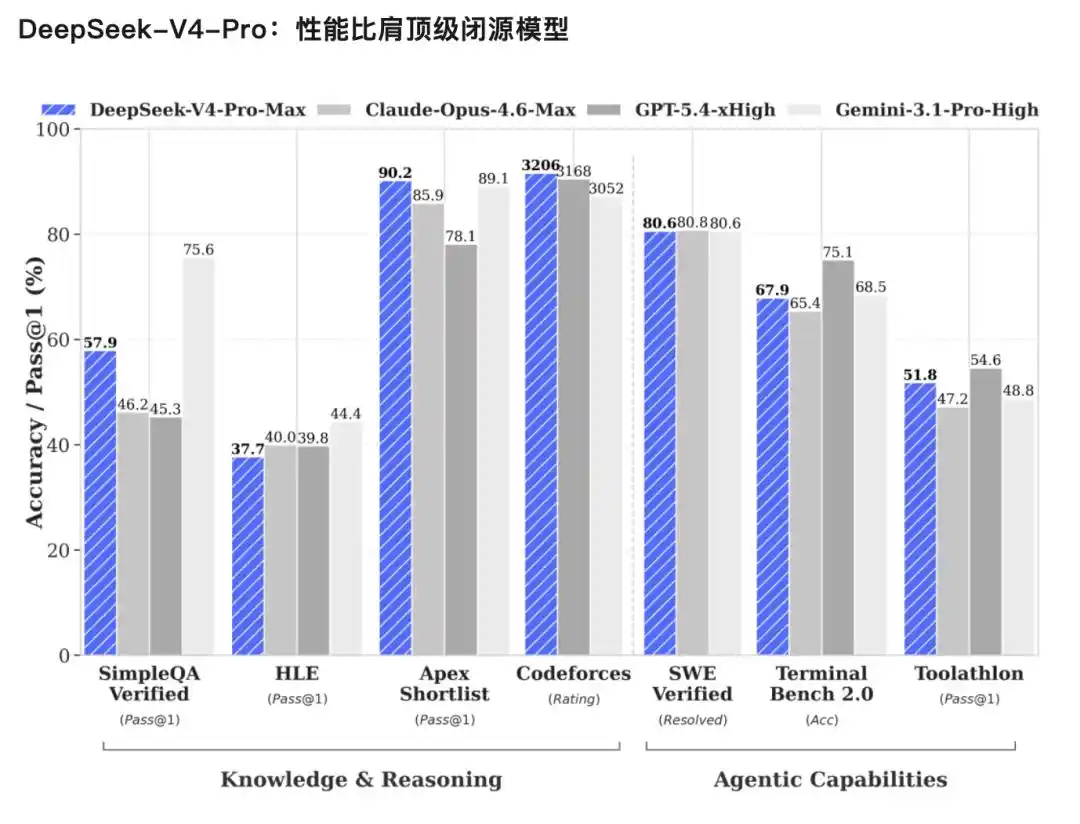
V4-Pro, rendimiento comparable con los mejores modelos cerrados.
El juicio oficial se basa en tres puntos:
Capacidad de agente mejorada significativamente: en las evaluaciones de Agentic Coding, V4-Pro ha alcanzado el mejor nivel actual entre los modelos de código abierto, y también ha tenido un rendimiento excelente en otras evaluaciones relacionadas con agentes. En las evaluaciones internas, en el modo Agent Coding, la experiencia de V4 es superior a Sonnet 4.5, y la calidad de entrega se acerca al modo no reflexivo de Opus 4.6, pero aún existe una brecha con el modo reflexivo de Opus 4.6.
Amplio conocimiento del mundo: en las evaluaciones de conocimiento del mundo, DeepSeek-V4-Pro supera significativamente a otros modelos de código abierto, solo ligeramente por detrás del modelo cerrado líder Gemini-Pro-3.1.
Rendimiento de razonamiento de clase mundial: en evaluaciones de matemáticas, STEM y código competitivo, DeepSeek-V4-Pro supera a todos los modelos de código abierto cuyas evaluaciones se han hecho públicas, logrando un excelente rendimiento comparable con los mejores modelos cerrados del mundo.
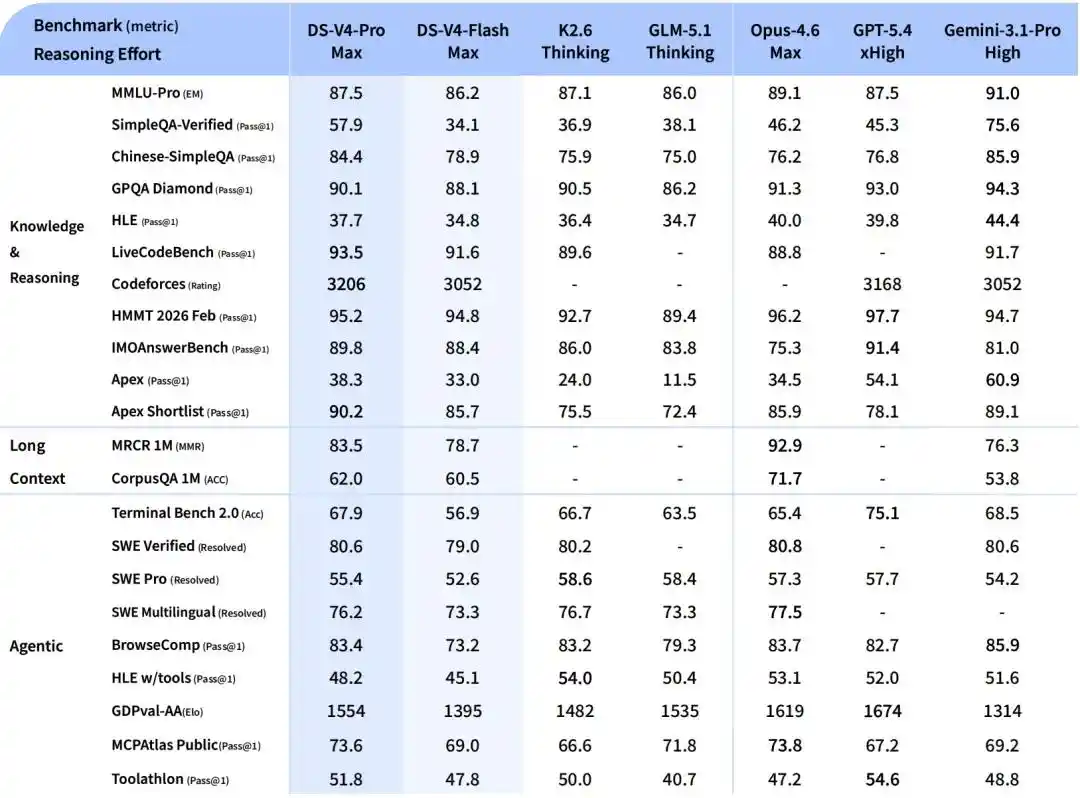
V4-Flash, una versión económica más pequeña y rápida. Su capacidad de razonamiento se acerca a la Pro, aunque su conocimiento del mundo es un poco inferior, pero tiene menos parámetros y activación, y su API es más económica.
En tareas de agente, DeepSeek-V4-Flash está a la par con DeepSeek-V4-Pro en tareas simples, pero aún hay una brecha en tareas de alta dificultad.
En la prueba de lavado de autos, V4 también la pasó rápidamente.

Y en el clásico escenario biológico del "padre desesperado", DeepSeek-V4 no captó de inmediato el punto clave del daltonismo rojo-verde (según las leyes genéticas, si una mujer es daltónica rojo-verde, su padre biológico necesariamente también lo es).

Contexto de un millón de tokens como estándar
Vale la pena mencionar que, a partir de hoy, un contexto de 1M es estándar en todos los servicios oficiales de DeepSeek.
Hace un año, el contexto de 1M era la carta exclusiva de Gemini; todos los demás modelos cerrados tenían 128K o 200K; en el lado del código abierto, casi nadie podía permitirse jugar a ese nivel.
DeepSeek ha convertido directamente el contexto de un millón de tokens de una "función premium" en "servicios básicos".
Y es de código abierto. ¿Cómo lo lograron? La respuesta está directamente en el comunicado de lanzamiento:
V4 introduce un nuevo mecanismo de atención que comprime en la dimensión de token, combinado con la atención dispersa DSA. En comparación con los métodos tradicionales, reduce significativamente la necesidad de computación y memoria.
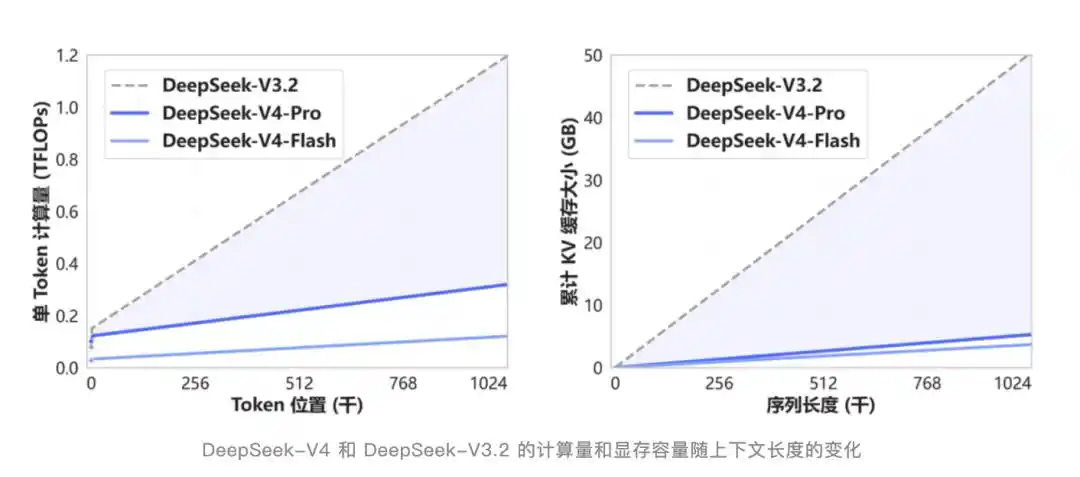
DSA no es un término nuevo. Se introdujo por primera vez hace medio año en la actualización V3.2-Exp, que en su momento tuvo poca atención externa porque las puntuaciones eran casi iguales a las de V3.1-Terminus, pareciendo una versión intermedia sin mucho contenido.
Ahora, mirando hacia atrás, esa fue la base de V4.
Optimización específica para capacidades de agente
En el lado del agente, V4 se ha adaptado y optimizado para productos principales de agente como Claude Code, OpenClaw, OpenCode, CodeBuddy, mejorando tanto las tareas de código como las de generación de documentos.
El comunicado de lanzamiento incluye un ejemplo de una página interna de PPT generada por V4-Pro en un framework de agente.

Precios de la API
En el lado de la API, V4-Pro y V4-Flash se lanzan simultáneamente, admitiendo dos interfaces: OpenAI ChatCompletions y Anthropic.
El base_url no cambia, solo modifica el parámetro model a deepseek-v4-pro o deepseek-v4-flash para llamarlo.
Ambas versiones tienen un contexto máximo de 1M y admiten tanto el modo no reflexivo como el modo reflexivo. En el modo reflexivo, puedes ajustar la intensidad con el parámetro reasoning_effort, dos niveles: high y max. La recomendación oficial para escenarios complejos de agente es usar max directamente.
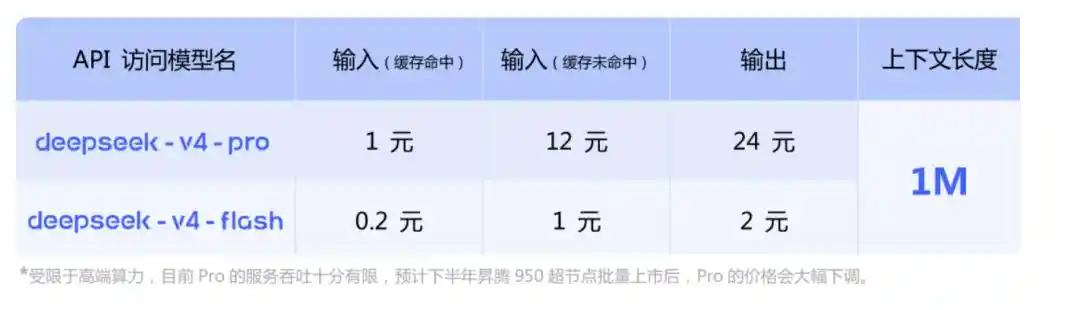
Aquí hay un punto clave: en la segunda mitad del año, se admitirá la capacidad de computación de Huawei.
Además, se eliminarán los nombres de modelos antiguos.
deepseek-chat y deepseek-reasoner se desactivarán en tres meses (24 de julio de 2026). En esta etapa, estos nombres apuntan respectivamente a los modos no reflexivo y reflexivo de V4-Flash.
Para desarrolladores individuales, el impacto es mínimo, solo cambiar un parámetro de modelo. Las empresas con entornos de producción necesitan migrar durante estos tres meses.
One more thing
Al final del comunicado de lanzamiento, DeepSeek cita una frase.
"No seducido por la alabanza, no asustado por la calumnia, procede según el camino, enderézate y corrígete."
Esta es una cita de Xunzi en "Contra los Doce Maestros". Literalmente significa: no dejarse seducir por los elogios, no temer a la difamación, avanzar por el camino que uno cree y corregirse a sí mismo.
En el contexto de hoy, es interesante.
En los últimos seis meses, los rumores sobre cuándo se lanzaría V4, si se había retrasado, si ya había sido superado por otros, si los datos de Claude lo habían destilado, etc., han circulado varias veces en los círculos de IA en chino e inglés. A principios de año, incluso había quien afirmaba con seguridad que V4 se lanzaría antes del Año Nuevo Chino, pero finalmente llegó a finales de abril.
No respondieron ni una vez.
Y luego, en una tarde de viernes, lanzaron V4, simultáneamente en código abierto, actualizaron el sitio web y la App, actualizaron la API, y de paso incluyeron en el comunicado el hecho de que sus empleados internos ya habían dejado de usar Claude.
Sin hoja de ruta, sin transmisión en vivo, sin entrevistas.
Estas cuatro palabras, "proceder según el camino", suenan como un eslogan. Pero si miras la ruta de los últimos seis meses: la versión Exp de V3.2 "sin muchos puntos destacados", la atención dispersa DSA que allanó el camino para V4 durante medio año, el contexto de 1M pasando de ser un as bajo la manga a un estándar.
DeepSeek ya lo ha logrado.
Enlaces de código abierto del modelo DeepSeek-V4:
[1]https://huggingface.co/collections/deepseek-ai/deepseek-v4
[2]https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
Informe técnico de DeepSeek-V4: https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
Este artículo proviene del WeChat público "Quantum Bit", autor: Quantum Bit





