¡Una factura de 500 millones de dólares quemados en 1 mes!
Recientemente, el círculo tecnológico destapó un monumental error. Según Axios, ¡una empresa acumuló una factura de 500 millones de dólares en Claude en apenas un mes!
La razón es para reír y llorar: la gerencia, al dar permisos de cuenta de Claude a los empleados, olvidó establecer un límite máximo de uso.

En realidad, no es la única con una factura de IA descontrolada.
En abril de este año, un usuario de Google Cloud, cuya clave API en un servicio público fue mal utilizada, recibió de la noche a la mañana una factura de 18.000 dólares para un presupuesto original de solo 7 dólares.

Este desafortunado usuario se llama Jesse Davies, un consultor de IA australiano y fundador de Agentic Labs. Había puesto dos seguros en su cuenta de Google Cloud: una alerta de presupuesto de 10 AUD (unos 7 USD) y un límite de gasto fijo de 1.400 dólares.
Según Tom's Hardware, el atacante descubrió un servicio Cloud Run que había publicado meses antes desde AI Studio, envió más de 60.000 solicitudes y ninguno de los dos seguros lo detuvo: el cálculo de la factura tenía retraso, y cuando el sistema reaccionó, el monto ya se había disparado a 18.000 dólares.
A mediados de mayo, Peter Steinberger, fundador del proyecto de código abierto OpenClaw, publicó en X una captura de pantalla: 1,3 millones de dólares en factura de API de OpenAI en 30 días.
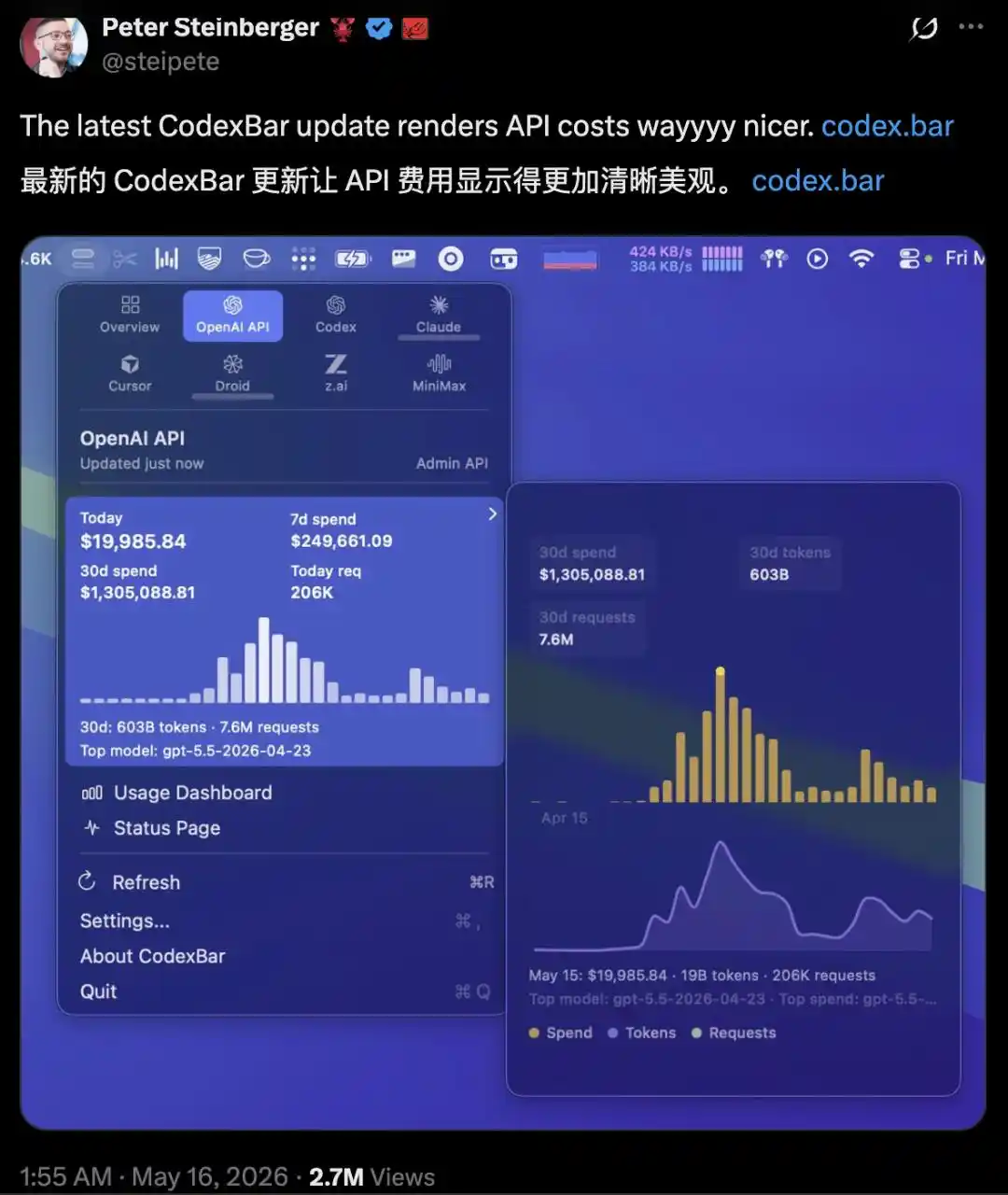
Su equipo solo tiene tres personas, pero los 100 agentes inteligentes Codex que dirigían funcionaban en paralelo: en 30 días consumieron 603.000 millones de Tokens, realizando 7,6 millones de solicitudes. Por suerte, esos 1,3 millones de dólares no salieron de su bolsillo.
Steinberger se unió a OpenAI en febrero de este año, y estos 1,3 millones de dólares se consideraron un experimento interno:
Para probar hasta qué límite puede llegar la programación con IA si no se considera el coste de los Tokens. Añadió que este fue el resultado del modo «Fast Mode» (facturación en marcha rápida) de Codex, y que al apagarlo el coste sería de unos 300.000 dólares.
Un poco antes, Praveen Neppalli Naga, CTO de Uber, también admitió a The Information que la empresa había agotado en abril el presupuesto anual para Claude Code, y su COO declaró públicamente que el coste de la IA es cada vez más «difícil de justificar».
500 millones, 1,3 millones, 18.000, aunque las cantidades difieren en varios órdenes de magnitud, apuntan al mismo hecho:
En la era de los agentes inteligentes, una clave descontrolada, un ejército de agentes trabajando día y noche, una cuenta sin límite establecido: cualquiera de ellos puede hacer que tu factura de Tokens se dispare de la noche a la mañana.
¿Por qué explotan las facturas de IA?
La respuesta está principalmente en los cambios en la forma de facturación.
A partir de abril de este año, OpenAI empezó a cambiar la facturación mensual por un modelo basado en el consumo de Tokens.
El 2 de abril, la facturación de Codex pasó de estimarse por mensaje a alinearse por consumo de Tokens: calculando por separado los Tokens de entrada, entrada en caché y salida. El 23 de abril, estas reglas se extendieron a todos los planes Enterprise, Edu, Health y Gov: se eliminó el descuento invisible incluido en la tarifa mensual.
GitHub también siguió sus pasos, anunciando recientemente: todos los planes de Copilot cambiarán a facturación por uso a partir del 1 de junio de 2026. La antigua lógica de solicitudes avanzadas queda anulada, reemplazada por créditos de IA, que se liquidan según el consumo real de Tokens de entrada, salida y caché, aplicando la tarifa API de cada modelo.

GitHub explicó oficialmente la razón:
Actualmente, una pregunta rápida en el chat y una tarea de codificación autónoma que se ejecute durante horas cuestan lo mismo al usuario. GitHub ha estado subsidiando a los usuarios con tareas intensivas, pero este modelo ya no es sostenible.
Antes del auge de los agentes de IA, el coste del chat y la finalización era similar, y la tarifa mensual podía cubrirlo.
Después del auge de los agentes, una tarea puede ejecutarse de forma continua durante horas, modificando todo el repositorio de código, y la diferencia de coste entre usuarios intensivos y ligeros puede alcanzar varios órdenes de magnitud. Frente a esta brecha, el modelo de tarifa plana mensual colapsa directamente.
La noticia causó un gran revuelo en Reddit y X.
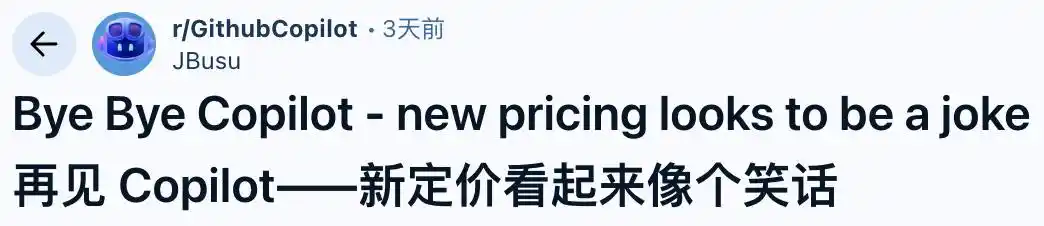
Un desarrollador con el ID JBusu compartió una captura de su factura, afirmando que el nuevo precio «es una broma». De un gasto mensual de 28,12 dólares, con el nuevo sistema pagaría 746,01 dólares. Ya decidió darse de baja: «A este precio, incluso alquilar mi propio servidor en la nube sería más barato».
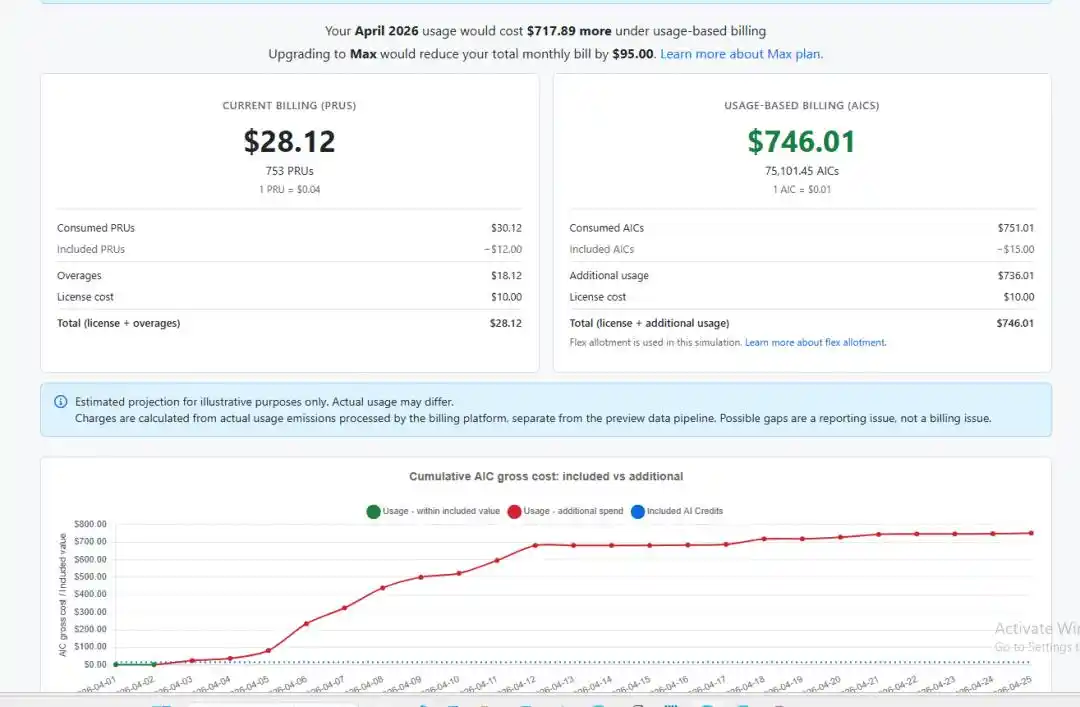
Otro usuario mostró una captura aún más exagerada, donde el coste pasó de 50 dólares a dispararse hasta 3.000 dólares. Dijo que no esperaba que el precio fuera tan desorbitado, «¿alguien seguirá suscrito?»
Sin embargo, también salieron a refutar algunos usuarios veteranos de Copilot: es probable que estas facturas extremas sean resultado de los «vibe-coders» (programadores por sensación) que no dan importancia a quemar Tokens, y no necesariamente representan un uso normal.
Un usuario veterano comentó: «Lo uso todo el día, y al final del mes apenas me paso del límite, me cuesta creer que sea solo por la complejidad del trabajo.» Otro fue más directo: «Simplemente hay gente que quiere desarrollar en modo YOLO totalmente automático, dejando que la IA ejecute lo que sea. Que se elimine este desperdicio es bueno para los demás.»
Hay que dejar claro una cosa: GitHub no ha abolido la tarifa mensual, el precio de la suscripción básica no ha cambiado. Lo que realmente cambia es que el uso adicional, las tareas de agentes y las llamadas a modelos más caros pasan ahora a facturación por consumo.
Los más afectados son aquellos usuarios intensivos de agentes que dependen de Copilot para ejecutar largas cadenas de tareas.
La tabla de clasificación arruinada por los propios empleados
La caída de la tarifa plana mensual es, por un lado, debido al cambio en las reglas de facturación de las plataformas, y por otro, porque los propios usuarios de IA también están quemando recursos sin control.
En mayo, Business Insider informó de que Amazon retiró una tabla de clasificación interna sobre el uso de IA llamada KiroRank.
El informe, citando a fuentes conocedoras, afirmaba que esta lista fomentó silenciosamente una extraña forma de trabajar: algunos empleados, para escalar posiciones en la clasificación, realizaban consumos de Tokens que no resolvían problemas reales, solo para mejorar su ranking.

Tras salir a la luz, Dave Treadwell, vicepresidente senior de Amazon, se dirigió directamente a todos los empleados: «No uséis la IA por usarla. Usadla para resolver problemas de los clientes, problemas de negocio, para innovar.»
Aunque el asunto es algo absurdo, no es sorprendente. Cuando «quemar Tokens» da puntos para una clasificación, los empleados naturalmente quemarán Tokens.
En Silicon Valley le han puesto un nombre específico a este fenómeno: Token maxxing (maximización de Tokens), equiparando el volumen de consumo con la productividad.
El informe de Axios también menciona que algunos CTO descubrieron que empleados usaban modelos de IA para consultar el tiempo o escribir correos rutinarios, tareas extremadamente simples, pero aplicando los modelos más caros y avanzados, haciendo que la factura se disparara silenciosamente.
KiroRank no era parte del sistema de evaluación oficial de Amazon, sino una herramienta no oficial creada espontáneamente por empleados. Pero dejó al descubierto una clásica regla de gestión: cuando el KPI está mal establecido, la gente usará la forma más inteligente de aprovecharse.
Equiparar «cuánto se ha usado» con «lo bien que se ha trabajado» es precisamente la raíz institucional del desperdicio actual de IA.
Quienes calculan la cuenta de Tokens ya están ganando dinero
Al otro lado de la ansiedad por las facturas de Tokens, algunos han convertido silenciosamente esto en un negocio.
Primer camino: alimentar a la IA con contexto.
Glean es precisamente la propia empresa de Arvind. Su función es ser un asistente de trabajo de IA empresarial: unificar el conocimiento disperso en toda la empresa, permitiendo que la IA de los empleados acceda directamente al contexto, sin tener que rebuscar por todas partes. Si la IA da menos vueltas, naturalmente quema menos Tokens.
Este mecanismo hizo que los ingresos anuales de Glean se triplicaran en 15 meses, superando los 300 millones de dólares, con clientes como Databricks, Reddit y Samsung.
Segundo camino: asignar el trabajo al modelo adecuado.
La startup de enrutamiento de modelos Factory AI se dedica precisamente a esto: enviar automáticamente cada tarea al modelo más apropiado, tareas simples a modelos baratos, tareas complejas a modelos de gama alta. Arvind también ha dicho: «Si el enrutamiento se hace bien, puede ahorrar 10 veces.»
Ambos caminos convergen: que la IA trabaje, pero sin que queme recursos sin control.
La investigación académica también está sentando las bases para este cambio.

https://arxiv.org/pdf/2604.22750
Un artículo de arXiv de abril de 2026 desglosó por primera vez de forma sistemática cómo las tareas de codificación con agentes queman dinero.
Conclusión uno: El consumo de Tokens en tareas con agentes puede ser miles de veces mayor que en el razonamiento de código normal o en diálogos sobre código. La principal causa del aumento de costes son los Tokens de entrada.
Conclusión dos: Ejecutar la misma tarea múltiples veces puede resultar en un consumo de Tokens 30 veces diferente.
Conclusión tres: Un mayor consumo de Tokens no necesariamente conlleva una mayor precisión. La precisión suele alcanzar su punto máximo en un coste medio: seguir quemando por encima supone gastar dinero sin mejorar el resultado, que se satura.
El artículo también descubrió que incluso los modelos más avanzados son incapaces de predecir cuántos Tokens van a consumir, subestimando generalmente el coste real.
Crees que gastando más dinero conseguirás más resultados. En realidad, se gasta dinero, el trabajo no necesariamente es mejor, y además el presupuesto es impredecible.
Cuando la factura de IA empieza a rivalizar con el coste laboral
«Esta es la primera vez que recuerdo que el coste tecnológico empieza a igualarse al coste laboral.»
Así lo expresó el CEO de Glean, Arvind Jain, el 29 de mayo en una entrevista con la periodista de CNBC Deirdre Bosa.
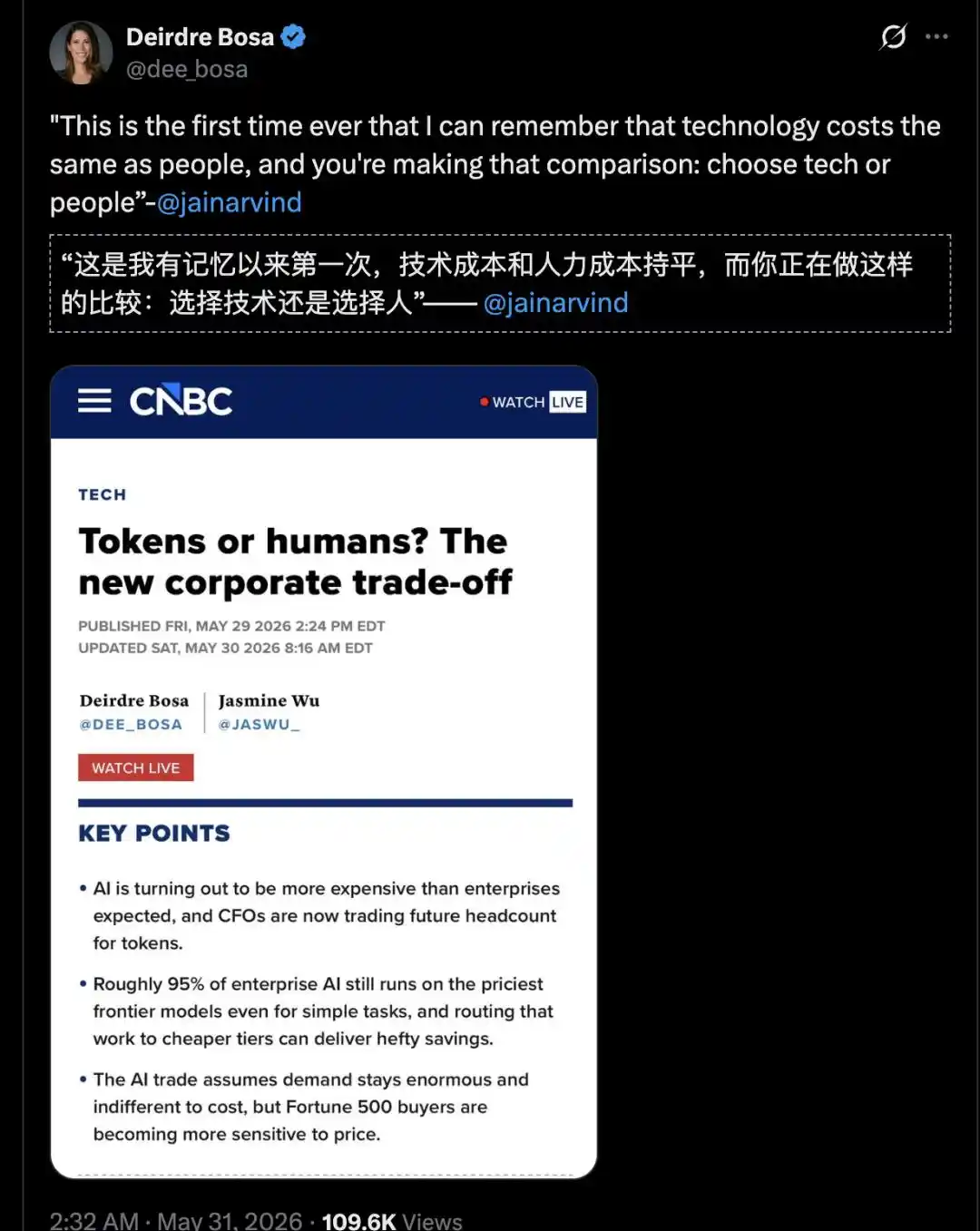
La observación de Bryan Catanzaro, vicepresidente de Aprendizaje Profundo Aplicado de Nvidia, también respalda este punto.
Mencionó en una entrevista con Axios: para su equipo, el coste de la capacidad de cálculo ya supera con creces los salarios de los empleados.
Fenómenos similares están apareciendo en varias empresas: desde Glean, que desarrolla IA empresarial, hasta Nvidia, que vende capacidad de cálculo de IA, y Uber, que usa IA, todos están reevaluando estas cuentas.
Según Arvind, históricamente la tecnología era solo una pequeña parte del coste total de una empresa, pero ahora el coste de la IA puede igualar la nómina salarial. Muchas empresas suelen agotar su presupuesto anual de IA en uno o dos meses.

En el último año, la tasa de uso de la IA era un indicador venerado: usarla mucho era ser avanzado, quemar Tokens era abrazar el futuro. Ahora, muchas empresas están reflexionando sobre esa frase simple: ¿a cambio de qué sirven todos esos Tokens quemados?
Precisamente ahora se está cerrando la ventana de uso ilimitado y gratuito con tarifa plana mensual.
A partir de ahora, todos los desarrolladores se enfrentan a esta pregunta: cómo administrar con cuidado cada recurso, para que cada Token aporte el máximo valor.
Los verdaderos ganadores del futuro, sin duda, serán aquellos que primero aprendan a calcular la cuenta de los Tokens.
Referencias:
https://x.com/dee_bosa/status/2060791500049613306%20
https://www.cnbc.com/2026/05/29/-tokens-or-humans-the-new-corporate-trade-off.html%20
https://www.axios.com/2026/05/28/ai-spending-roi-enterprise-costs%20
https://www.businessinsider.com/amazon-ai-leaderboard-tokenmaxxing-2026-5
Este artículo procede del cuenta oficial de WeChat «新智元» (Nueva Era de la Inteligencia), autor: ASI启示录






