¿Cuánto se puede comprimir una imagen?
En febrero de 2025, el Joint Photographic Experts Group (JPEG) anunció algo que fue celebrado discretamente por la industria: JPEG AI, el primer estándar internacional de codificación de imágenes basado en aprendizaje de extremo a extremo, largamente esperado y desarrollado durante años, fue lanzado oficialmente.

La noticia se difundió, y muchos investigadores compartieron en redes sociales, con comentarios como "la IA finalmente entra en los estándares".
El estándar JPEG nació en 1992 y, durante más de tres décadas, ha sido un lenguaje fundamental para las imágenes digitales humanas. Y ahora, la inteligencia artificial está empezando a reescribir la gramática de ese lenguaje.
Sin embargo, tras la celebración hay una realidad sutil: incluso JPEG AI está aún bastante lejos de la verdadera compresión perceptiva.
Los ingenieros saben que el pico de relación señal-ruido (PSNR), una métrica tradicional de calidad de compresión, no está muy relacionada con lo "atractivo" que el ojo humano percibe. Una imagen puede obtener una puntuación alta en PSNR, pero una persona puede encontrarla mediocre; mientras que otra imagen con PSNR más bajo puede parecer rica en detalles y con textura realista. Optimizar métricas matemáticas y optimizar la percepción humana son dos cosas completamente diferentes.
Durante décadas, desde JPEG hasta VVC y ahora JPEG AI, la lógica de diseño de casi todos los códecs ha girado en torno al marco de las métricas matemáticas. La compresión perceptiva (optimizada directamente para la experiencia visual humana) siempre ha parecido un objetivo lejano en artículos académicos, no una realidad de ingeniería que pueda integrarse en un teléfono móvil.
Precisamente en este momento, un equipo de ingenieros de Apple publicó discretamente un artículo de investigación con su respuesta, bajo el nombre en clave: PICO.

Título del artículo: What Matters in Practical Learned Image Compression
Dirección del artículo: https://arxiv.org/pdf/2605.05148
¿Por qué es mucho más difícil que algo "se vea mejor" que que un "número sea más alto"?
Para entender PICO, primero hay que entender qué hace realmente la compresión de imágenes.
Guardar una fotografía en un archivo es esencialmente una cuestión de decidir "qué olvidar y qué recordar". El espacio de almacenamiento es limitado, por lo que hay que descartar parte de la información, intentando al mismo tiempo que quien la vea apenas lo note. Diferentes códecs siguen diferentes "métodos de descarte".
Los códecs tradicionales como JPEG, AV1, VVC son sistemas de reglas diseñados manualmente por ingenieros. Dividen la imagen en bloques, transforman, cuantifican, codifican la entropía; cada paso es experiencia humana acumulada durante décadas. Estos sistemas pueden funcionar extremadamente bien en métricas matemáticas como el PSNR, pero su diseño está orientado esencialmente a "reducir el error de píxeles", no a "reducir la incomodidad visual".
El problema es que el ojo humano no es un medidor de error de píxeles. La sensibilidad del ojo humano a las texturas, al texto, a los detalles es mucho más compleja que una fórmula matemática. Cuando se comprime mucho una foto de una calle, el PSNR puede seguir siendo decente, pero se verán bordes de edificios borrosos, letreros de calles distorsionados, precisamente las cosas que el ojo humano detecta primero.
La aparición de códecs basados en aprendizaje abrió teóricamente una nueva puerta: las redes neuronales podrían entrenarse de extremo a extremo directamente para la percepción humana, no para fórmulas matemáticas. Pero antes de PICO, los códecs de aprendizaje perceptivo existentes o eran demasiado lentos para ser prácticos, o carecían de compatibilidad multiplataforma, o no podían controlar flexiblemente la tasa de bits, y simplemente no cabían en un producto de consumo.
Tres problemas centrales, tres soluciones
PICO son las siglas de Perceptual Image Codec (Códec de Imágenes Perceptual). Este nombre define directamente su objetivo: satisfacer al ojo humano.
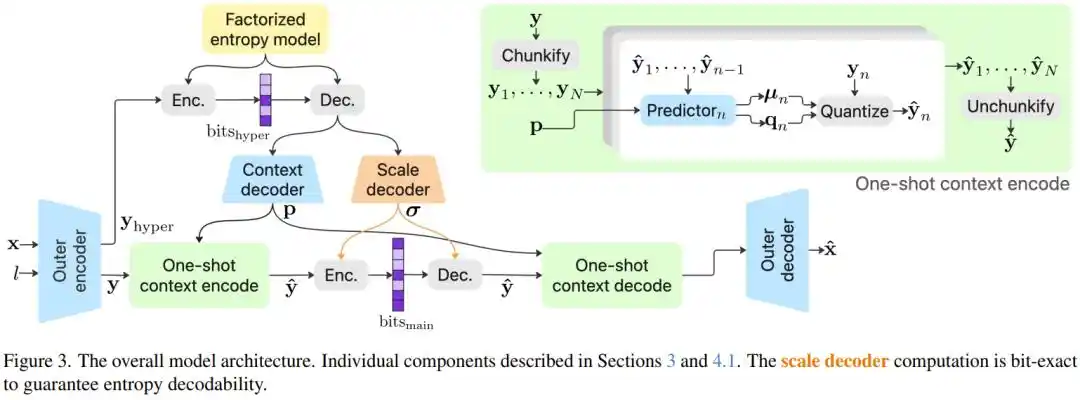
El equipo de investigación exploró sistemáticamente millones de configuraciones de modelos e introdujo varias innovaciones tecnológicas clave.
Primer problema: La codificación de entropía es lenta, ¿qué hacer?
En la compresión de imágenes hay un problema difícil: para comprimir más, el códec necesita un "modelo de entropía" para estimar con precisión la cantidad de información de cada píxel. El método más preciso se llama codificación autorregresiva: para comprimir cada píxel, primero hay que mirar los píxeles ya comprimidos a su alrededor y predecir secuencialmente. Es como si un chef, al añadir cada ingrediente, tuviera que mirar el estado de la olla antes de decidir el siguiente paso. Preciso, pero extremadamente lento.
La solución de PICO es el "Modelo de Contexto de Una Sola Vez" (One-shot Context Model): separar el parámetro de "escala", más crucial en la codificación de entropía, y calcularlo todo en una sola pasada hacia adelante, sin necesidad de esperas sucesivas; mientras que los demás parámetros se pueden calcular en paralelo, manteniendo la precisión autorregresiva pero evitando su cuello de botella de velocidad. El resultado: sin este módulo, el rendimiento del modelo cae un 10.28%; con él, la velocidad apenas se ve afectada.
Segundo problema: El entrenamiento perceptivo produce alucinaciones, ¿qué hacer?
Las imágenes entrenadas con GAN (Redes Generativas Antagónicas) a menudo "se ven realistas", pero pueden ser un realismo inventado: cabellos que se convierten en patrones inexistentes, superficies lisas que adquieren texturas falsas. Lo más problemático es que el ojo humano es extremadamente sensible al texto; incluso la más mínima deformación de una letra se detecta al instante.
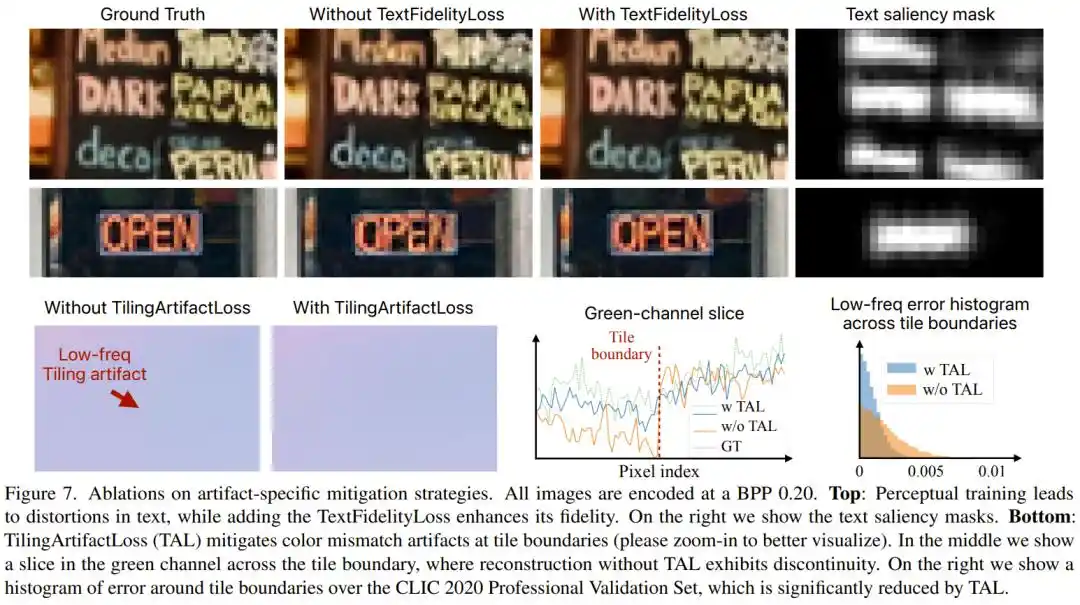
PICO diseñó específicamente para el texto la TextFidelityLoss: utilizando un detector de texto preexistente para identificar automáticamente las áreas de texto en la imagen, aplica restricciones estrictas de fidelidad de píxeles en esas áreas, al tiempo que reprime el "espacio de actuación" de la GAN en las regiones de texto. Los experimentos mostraron que, tras añadir esta función de pérdida, el error absoluto en las áreas de texto se redujo a la mitad.
Tercer problema: El procesamiento por bloques deja bordes de color, ¿qué hacer?
Para ejecutarse rápidamente en chips de teléfonos móviles, PICO divide la imagen en mosaicos de 504×504 píxeles, los procesa por separado y luego los reensambla. Pero las GAN, durante el entrenamiento, tienden a ignorar los colores de baja frecuencia, lo que provoca diferencias de color visibles entre mosaicos adyacentes, similar a la sensación de "no encajar bien" al retocar una foto. El equipo de investigación introdujo específicamente la TilingArtifactLoss, una pérdida L1 multirresolución, que obliga al modelo a mantener la coherencia de color en múltiples frecuencias espaciales. Esta medida redujo también a más de la mitad el error en los bordes de los mosaicos.
Resultados experimentales
El equipo de Apple no se basó solo en métricas de referencia. Encargaron a la plataforma de terceros Mabyduck la organización de una evaluación subjetiva humana a gran escala.
La evaluación utilizó una comparación por pares a ciegas: 610 evaluadores seleccionados (que debían pasar pruebas de daltonismo y de detección de artefactos de compresión) compararon los resultados de reconstrucción de la misma imagen mediante diferentes códecs. Los resultados se resumieron en una puntuación Bayesian ELO. Se recogieron un total de 74,925 comparaciones por pares.

Las cifras finales lo dicen todo: con la misma calidad visual, el tamaño de archivo de PICO es solo de un tercio a la mitad del de AV1, AV2, VVC, ECM y JPEG AI. En otras palabras, para almacenar la misma imagen, necesita solo entre el 30% y el 43% de los bits que requieren estos estándares. Comparado con los códecs de aprendizaje perceptivo más potentes actualmente (HiFiC, MRIC, etc.), PICO también ahorra entre un 20% y un 40% del tamaño de archivo.
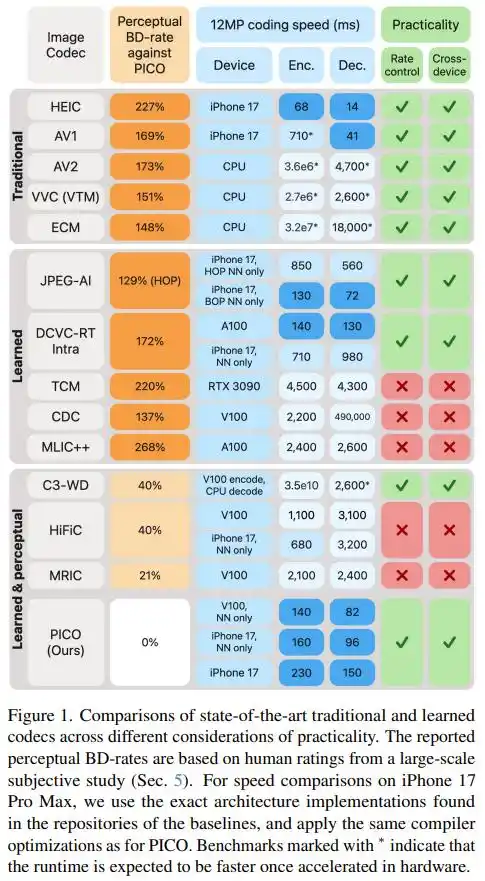
En cuanto a velocidad, en un iPhone 17 Pro Max, PICO codifica una foto de 12MP en solo 230 milisegundos, y la decodificación toma solo 150 ms. La mayoría de los códecs ML de última generación en tarjetas gráficas de servidor NVIDIA V100 son más lentos que esto.
Vale la pena señalar que el artículo también registra un "contraejemplo" específico: en la métrica tradicional del PSNR, PICO tiene un rendimiento mediocre, incluso inferior a DCVC-RT y VVC. Esto corrobora el juicio fundamental del equipo: optimizar la calidad perceptiva y optimizar las métricas matemáticas son esencialmente dos direcciones diferentes, no se puede tener todo.
Un hito de época, no un punto final
PICO, por supuesto, también tiene limitaciones. El artículo reconoce que, para imágenes sintéticas altamente regulares como dibujos animados o diagramas esquemáticos, la eficiencia de compresión de PICO no es tan buena como la de los códecs tradicionales, ya que este tipo de contenido se adapta naturalmente a un modelado autorregresivo basado en reglas, no a la generación perceptiva.
Pero estas limitaciones no opacan el significado de este trabajo.
En los últimos treinta años, los avances técnicos en compresión de imágenes han ocurrido casi por completo en la pista de "hacer que los números se vean mejor". Desde JPEG hasta HEVC y VVC, los ingenieros han optimizado generación tras generación métricas como PSNR y SSIM. Y la percepción del ojo humano siempre ha sido un "problema difícil" evitado.
PICO es la primera vez que alguien descompone sistemáticamente este problema difícil de frente: desde la búsqueda de arquitecturas y el diseño de funciones de pérdida, hasta evaluaciones subjetivas humanas a gran escala, y finalmente integrado en un códec que puede ejecutarse en tiempo real en un teléfono móvil.
La próxima vez que compartas una foto desde un dispositivo Apple, tal vez no notes ninguna diferencia. Pero quizás, en ese silencioso proceso de compresión, un algoritmo diseñado a medida para la percepción del ojo humano esté decidiendo qué información merece quedarse y cuál puede olvidarse discretamente.
El equipo: De WaveOne a Apple
El autor de correspondencia de este artículo es Oren Rippel, investigador de Apple y una cara conocida en el campo de la compresión.
Su nombre apareció por primera vez a gran escala en 2017. Por entonces estaba en la startup WaveOne, donde publicó un artículo titulado "Compresión de imágenes adaptativa en tiempo real", utilizando redes neuronales para superar a todos los códecs principales de la época, manteniendo al mismo tiempo velocidad de ejecución en tiempo real. Ese artículo causó un gran revuelo en la academia y consolidó la posición de Rippel en el campo de la compresión basada en aprendizaje.

Posteriormente, el mismo núcleo de personas continuó profundizando en WaveOne, lanzando ELF-VC para compresión de video, logrando un ahorro de tasa de bits del 44% en comparación con H.264 en el conjunto de pruebas de video UVG, y una velocidad de ejecución cinco veces mayor que otros códecs ML similares.
Este equipo de WaveOne se incorporó posteriormente en su totalidad a Apple. Y este PICO es la primera respuesta sistemática que presentan, con los recursos computacionales y de plataforma de Apple, en el campo de la compresión de imágenes perceptiva.
Este artículo proviene de la cuenta oficial de WeChat "机器之心" (ID:almosthuman2014), autor: Compresión es Inteligencia.






