Finalmente, Lilian Weng publicó en su blog tras un retraso de tres años.
Recién, un extenso artículo de la exvicepresidenta de OpenAI, Lilian Weng, retrasado por más de tres años, se volvió viral.
En este blog titulado "Scaling Laws, Carefully", desglosa las Leyes de Escalado desde el principio hasta el final —
Esta ley en la que la industria de la IA ha invertido decenas de miles de millones de dólares es mucho más frágil de lo que cualquiera imaginaba.
Resumen en un minuto: ¿De qué trata este artículo de más de diez mil palabras?
Una fórmula ha gobernado toda la industria durante cinco años. Las Leyes de Escalado afirman que "al hacer el modelo más grande, alimentar más datos y aumentar la potencia de cálculo, el rendimiento mejorará a un ritmo fijo". Convirtió la IA de una ciencia esotérica en un negocio calculable, dirigiendo indirectamente el flujo de cientos de miles de millones de dólares.
OpenAI y DeepMind dieron respuestas opuestas. Para la misma pregunta "¿cómo distribuir el presupuesto de cómputo?", en 2020 OpenAI dijo que el modelo debería crecer más rápido que los datos; en 2022 DeepMind dijo que ambos deberían crecer juntos. Más tarde se descubrió que la raíz de la divergencia era una diferencia en el método de conteo de parámetros y que la escala experimental no era lo suficientemente grande.
Incluso la fórmula del ganador tiene errores. La proporción óptima de DeepMind, copiada por toda la industria durante dos años, en 2024 fue replicada línea por línea y se descubrió: la función de pérdida usó el promedio en lugar de la suma, lo que provocó que el optimizador se detuviera prematuramente y los parámetros de salida no fueran la solución óptima.
Hay que tener mucho cuidado al usar patrones de modelos pequeños para predecir modelos grandes. Esta curva se ajustó en modelos relativamente pequeños; al extrapolarla al nivel de billones de parámetros, una diferencia por redondeo puede hacer que las conclusiones varíen enormemente. El blog incluye un simulador interactivo; puedes verlo deslizando un control.
Hay un problema más fundamental: los datos se están acabando. La fórmula asume que los datos son infinitos, pero el texto de alta calidad es finito. Por eso toda la industria se está volcando colectivamente hacia el aprendizaje por refuerzo, el cálculo en tiempo de prueba y los datos sintéticos.
Una línea recta, cientos de miles de millones de dólares
Como es sabido, el núcleo de las Leyes de Escalado puede resumirse en una frase simple—
Cuanto mayor sea el modelo, más datos y más potencia de cálculo, mejor será el rendimiento. Y este "mejor" no es aleatorio, tiene una ley matemática precisa.
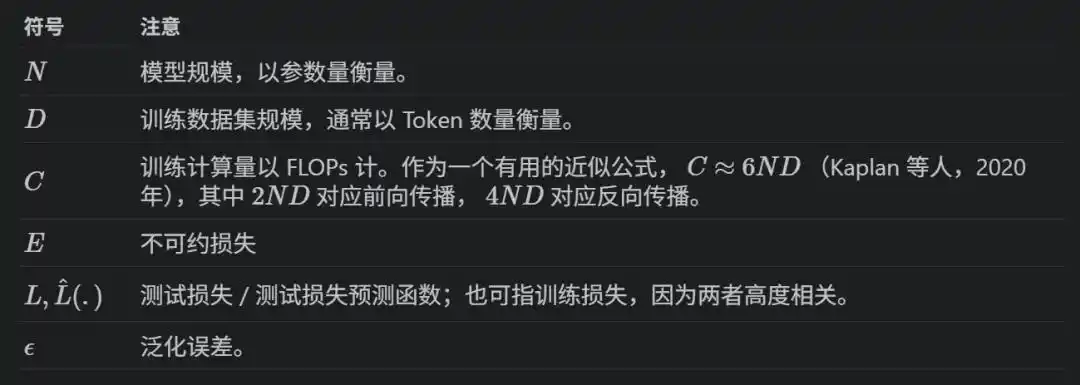
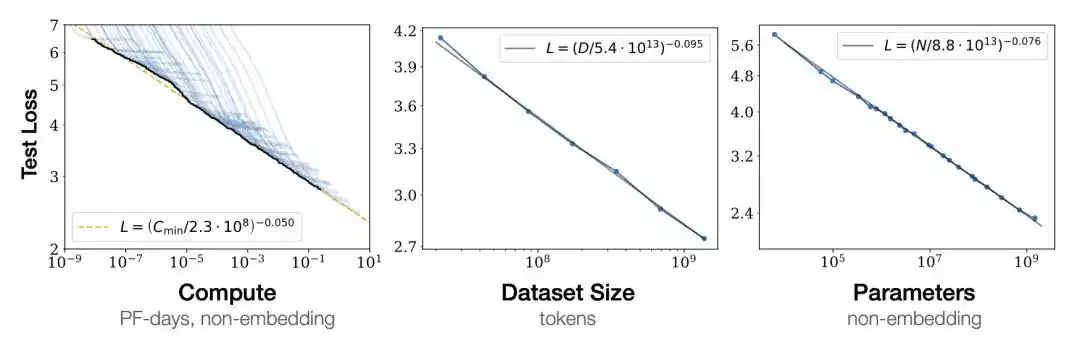
Graficando la pérdida del entrenamiento del modelo en coordenadas logarítmicas, desciende en línea recta a medida que aumentan los parámetros del modelo N, la cantidad de datos D y la potencia de cálculo C.
Escribiendo la fórmula es L(x) = E + A/x^α, donde x puede ser N, D o C, E es la pérdida óptima teórica (la entropía de los datos mismos), A y α son constantes ajustadas.
Entrenar un modelo con N parámetros con D tokens, potencia total de cálculo C ≈ 6ND—propagación hacia adelante 2ND, propagación hacia atrás 4ND.
Esta línea recta significa que la mejora del rendimiento es predecible.
Primero ejecuta algunos modelos pequeños, ajusta esa línea recta, extrapola hacia la derecha y puedes estimar el rendimiento del modelo grande entrenado. No es necesario gastar cientos de millones de dólares entrenando el modelo grande para saber si funcionará.
Antes de esto, el aprendizaje profundo siempre fue ridiculizado como "alquimia", sabiendo qué funciona pero no por qué.
En 2020, Kaplan de OpenAI publicó esta ley de potencia, llevando por primera vez la ciencia esotérica al ámbito de lo "predecible".
Esta es la confianza que tienen todas las empresas de modelos grandes para invertir a lo grande.
Pero la recomendación más crítica de la fórmula, dado el presupuesto de cómputo, cómo asignar recursos entre modelo y datos, OpenAI y DeepMind dieron respuestas opuestas.
El mismo problema
OpenAI y DeepMind llegaron a respuestas opuestas
La conclusión del equipo de Kaplan de OpenAI en 2020 fue: El tamaño óptimo del modelo N_opt ∝ C^0.73.
Traduciéndolo: si la potencia de cálculo se multiplica por 10, asigna 5.5 veces al modelo y 1.8 veces a los datos—el modelo debe crecer mucho más rápido que los datos.
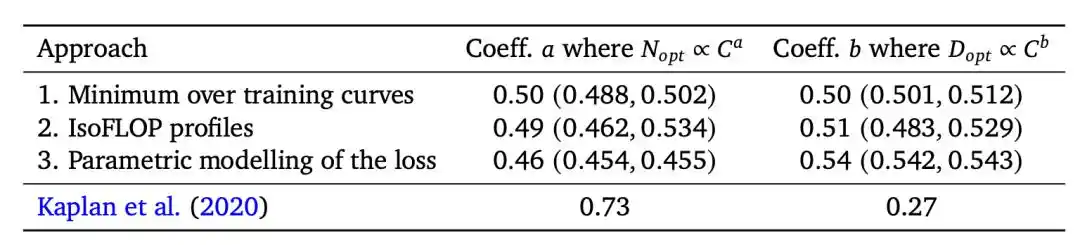
Esto guió directamente el plan de entrenamiento de GPT-3.
Un modelo de 175 mil millones de parámetros, solo fue alimentado con 300 mil millones de tokens (el token es la unidad mínima que el modelo procesa del texto, aproximadamente una palabra corresponde a 1-2 tokens).
Según estándares posteriores, esto es un entrenamiento severamente insuficiente.
En 2022, el equipo Chinchilla de DeepMind llegó a la conclusión opuesta: N_opt ∝ C^0.50, el modelo y los datos deben crecer proporcionalmente.

Los ingenieros luego lo resumieron en un número fácil de recordar: La proporción óptima de tokens por parámetro es aproximadamente 20:1.
Entonces DeepMind hizo una confrontación directa.
Su propio Gopher, 280 mil millones de parámetros con 300 mil millones de tokens. Chinchilla, 70 mil millones de parámetros con 1.4 billones de tokens. Ambos modelos usaron la misma potencia de cálculo.
Chinchilla aplastó por completo.
Un modelo más pequeño y "bien alimentado" derrotó a un oponente más grande y "hambriento".
El consenso de toda la industria se invirtió: pasó de "hacer modelos más grandes" a "la mayoría de los modelos están insuficientemente entrenados".
0.73 vs 0.50, el mismo problema, respuestas opuestas, harían que asignaras el presupuesto de cómputo en dos direcciones completamente diferentes.
La razón resultó ser un "problema de contabilidad"
En 2024, dos investigadores publicaron un artículo de conciliación en la revista TMLR, llevando esta divergencia hasta sus raíces.
La conclusión es irónica.
Primera razón: las formas de contar parámetros eran diferentes.
En los modelos hay una capa de parámetros llamada embedding, responsable de convertir texto en vectores numéricos que el modelo entienda. En modelos pequeños, esta capa representa una gran proporción del total de parámetros; un modelo de decenas de millones de parámetros podría tener un tercio aquí.
Kaplan excluyó los embeddings al contar parámetros, Chinchilla los incluyó.
Solo esta diferencia en el método de conteo de parámetros es suficiente para distorsionar el exponente final de la ley de potencia ajustada.
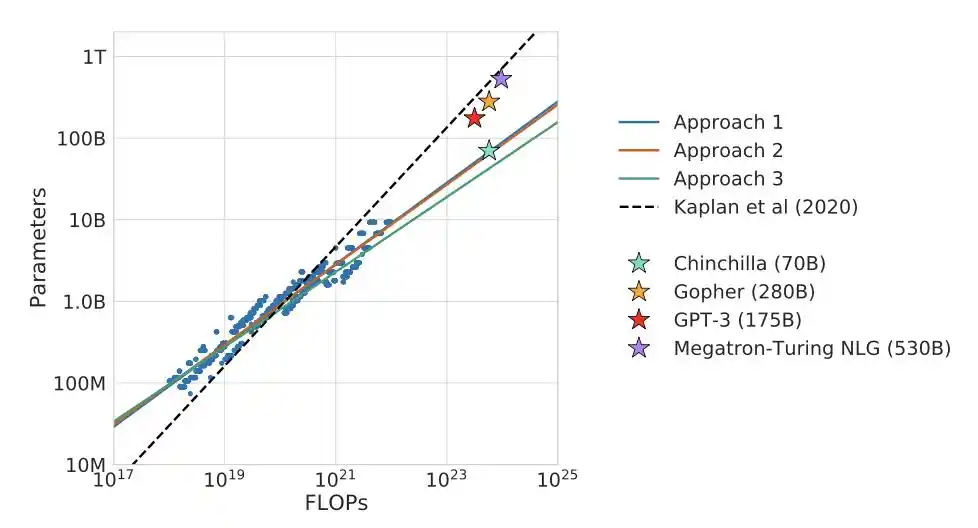
Ellos dieron una fórmula de corrección concisa: N = N_\E + ω·N_\E^(1/3), donde N_\E es el número de parámetros sin embedding, ω es una constante. Para modelos pequeños, el segundo término representa una gran proporción, el efecto del embedding es significativo; cuanto más grande es el modelo, el segundo término se acerca a cero, ambos métodos de conteo convergen.
Segunda razón: el experimento de Kaplan era demasiado pequeño.
El modelo más grande que probó Kaplan fue de solo 1.5 mil millones de parámetros, mientras que el experimento de Chinchilla abarcó más de 16 mil millones. En coordenadas logarítmicas, pequeñas desviaciones en el ajuste se amplifican drásticamente al extrapolar.
Re-derivaron la fórmula de Chinchilla con un método unificado de conteo de parámetros y descubrieron una ley clave—
El exponente de la ley de potencia cambia con el tamaño del cómputo. En el rango de experimentos pequeños de Kaplan, el exponente realmente se acerca a 0.73; pero al aumentar la escala, el exponente converge a 0.50.
Kaplan no estaba "equivocado", tenía razón dentro de su propio rango experimental.
Pero extrapoló una ley localmente válida a una conclusión global.
Un problema de cómo contar un parámetro, sumado a una escala experimental insuficiente, hizo que dos equipos de élite dieran recomendaciones opuestas para la asignación de recursos.
Toda la industria ajustó su receta de entrenamiento siguiendo esta conclusión durante dos años.
Incluso el ganador tiene errores
Kaplan fue corregido por Chinchilla, esta es la narrativa estándar que todos conocen.
Pero Weng fue un paso más allá—La metodología de Chinchilla misma también tiene problemas.
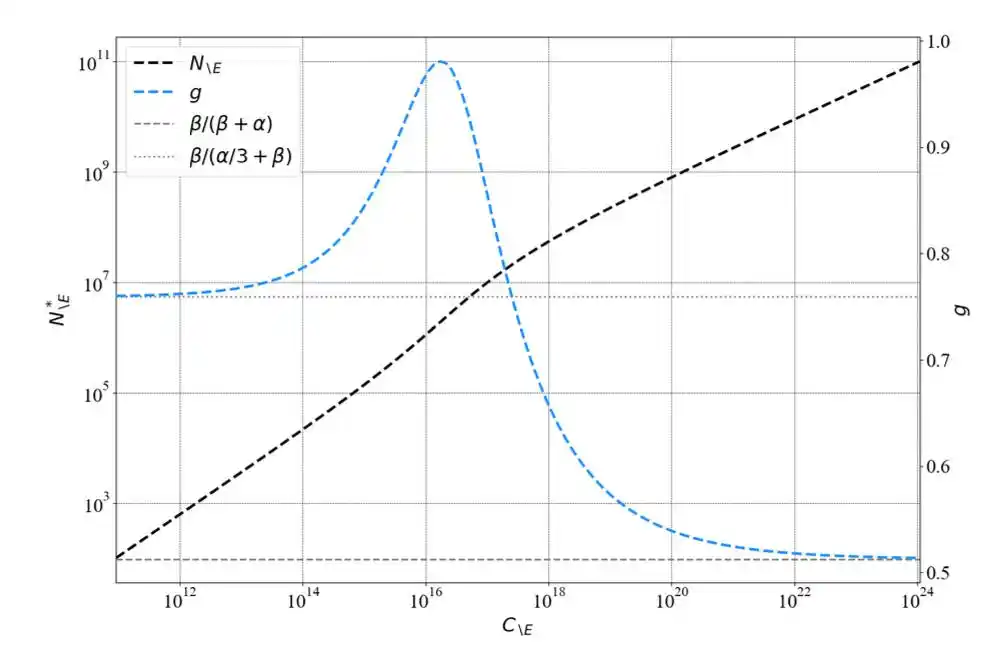
El artículo de Chinchilla usó tres métodos independientes para validar cruzadamente su conclusión:
Método 1 tamaño del modelo fijo variando la cantidad de datos
Método 2 dibujando curvas de cómputo igual (IsoFLOP profiles)
Método 3 ajustando directamente los parámetros de la fórmula de pérdida L(N,D) = E + A/N^α + B/D^β
Tres caminos apuntando a la misma conclusión, parecía muy sólido.
La derivación matemática del método 3 es especialmente elegante: optimizando L(N,D) bajo la restricción C ≈ 6ND, se puede obtener una solución cerrada N_opt ∝ (C/6)^(β/(α+β)). Cuando α ≈ β, el exponente es aproximadamente 0.5, es decir, el modelo y los datos crecen proporcionalmente. Este es el origen matemático de 0.50.
En 2024, el equipo de Epoch AI extrajo manualmente puntos de datos originales de los gráficos del artículo de Chinchilla y volvió a ejecutar el ajuste del método 3.
Dos errores, cada uno más absurdo que el otro.
Error 1: La función de pérdida usó el promedio en lugar de la suma.
Chinchilla, al ajustar estos cinco parámetros, necesitaba minimizar la diferencia entre la pérdida predicha y la real.
El objetivo de optimización completo es: min Σ Huber_δ(log L̂(Nᵢ,Dᵢ) − log Lᵢ), donde Huber Loss es una función de pérdida menos sensible a valores atípicos (δ = 10⁻³), usando el optimizador L-BFGS-B para buscar la solución óptima.
El problema está en un detalle: usaron el promedio (mean) en lugar de la suma (sum) para el Huber Loss de cada muestra. Al promediar cientos de muestras, el valor de pérdida se comprimió a una magnitud extremadamente pequeña.
El optimizador L-BFGS-B tiene un criterio de convergencia incorporado. Cuando el valor de pérdida es suficientemente pequeño se detiene automáticamente. Al ver valores tan pequeños, asumió erróneamente que había convergido y se detuvo.
El optimizador ni siquiera terminó de ejecutarse. Los parámetros de salida no eran el valor verdaderamente óptimo.
Error 2: Los parámetros clave solo conservaron dos decimales.
En el artículo de Chinchilla hay dos exponentes centrales que controlan la forma de la ley de potencia, que solo conservaron dos decimales.
Parece un redondeo inofensivo.
Pero al derivar otras constantes desde estos números aproximados, el error se amplificó exponencialmente. El intervalo de confianza final era irrazonablemente estrecho, tan estrecho que se necesitarían más de 600,000 experimentos para alcanzar esa precisión, mientras que en realidad solo ejecutaron menos de 500.
Una fórmula venerada como un canon por toda la industria, detrás escondía un error de función de pérdida no ejecutada completamente, y este error permaneció oculto durante dos años completos.
Weng incluyó en el blog un simulador interactivo, tres controles deslizantes ajustan respectivamente la precisión de la pérdida, el ruido de la pérdida y el rango de ajuste.
Cada vez que se mueve uno, la Ley de Escalado ajustada cambia de forma.
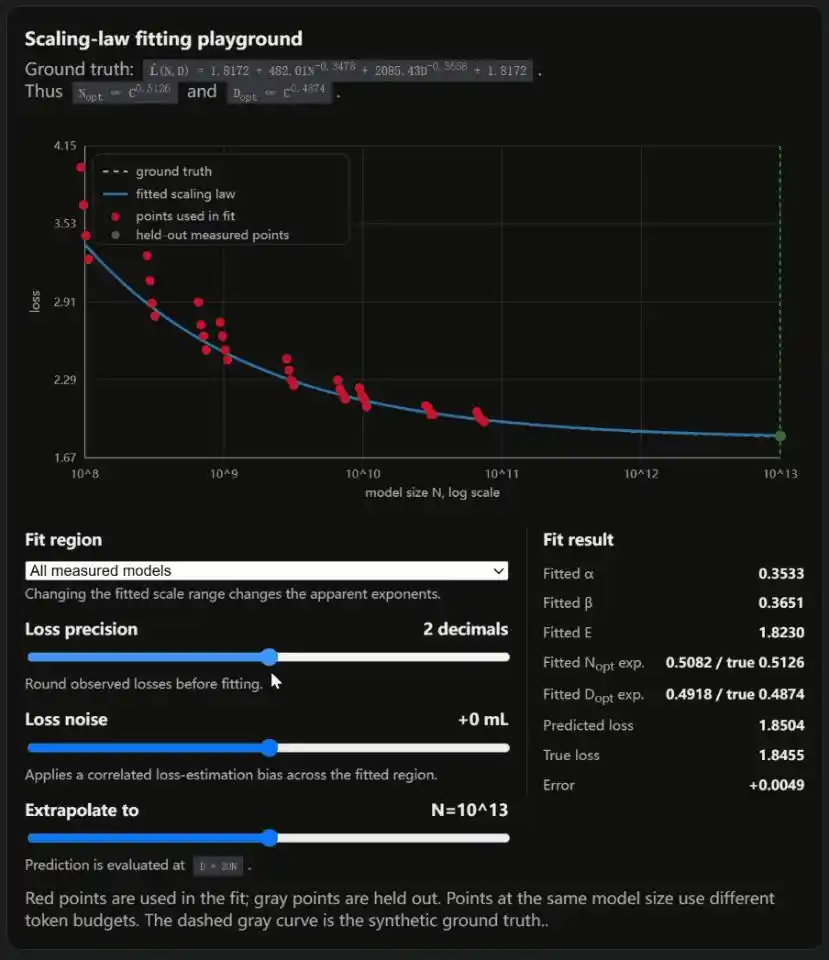
La conclusión de OpenAI tenía sesgo de localidad, la conclusión de DeepMind tenía imperfecciones metodológicas. El debate académico más importante en la industria de la IA, ambos lados tienen grietas.
Los datos casi se agotan
Las tres secciones anteriores hablan sobre problemas de métodos de ajuste, cómo contar parámetros, cómo calcular pérdidas, cuántos decimales tomar.
Pero incluso si todos estos problemas se corrigieran, las Leyes de Escalado clásicas tienen un riesgo aún más fundamental—
Asumen que cada dato de entrenamiento es único, no repetido, sin múltiples épocas, suponiendo que tienes datos infinitos.
La realidad es que se estima que los datos de texto de alta calidad se agotarán entre 2026 y 2028 debido a la exploración exhaustiva de los principales laboratorios.
El entrenamiento repetido con datos es inevitable, la premisa de la fórmula clásica se está derrumbando.
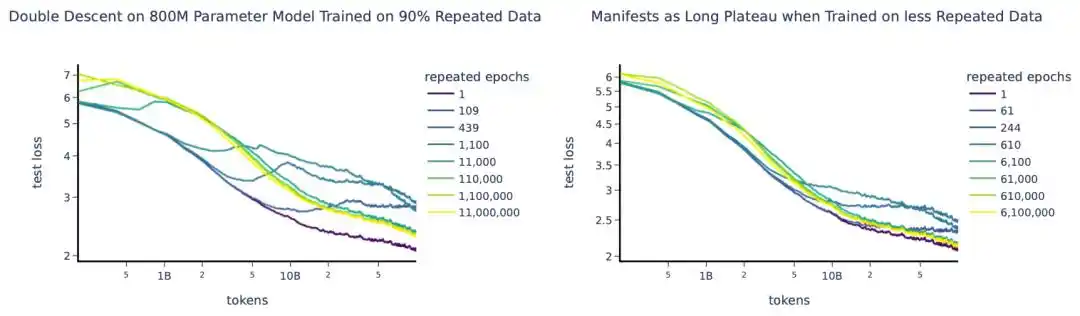
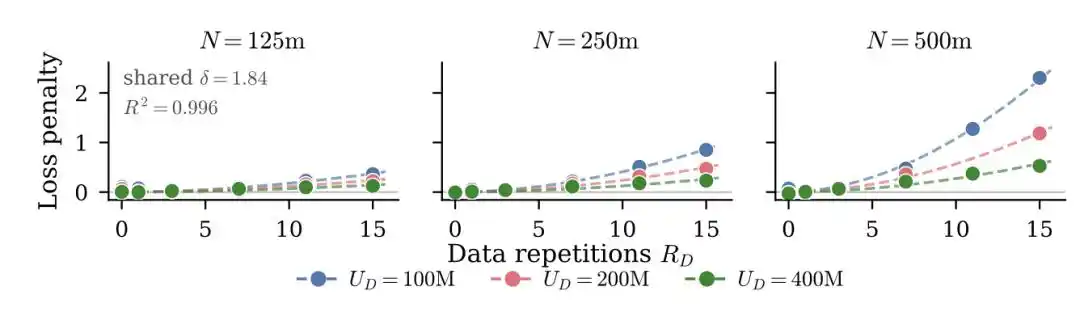
Un experimento a gran escala en 2023 entrenó alrededor de 400 modelos, desde decenas de millones hasta 9 mil millones de parámetros, con hasta 1500 repeticiones de entrenamiento.
La idea central fue introducir el concepto de "cantidad efectiva de datos" para reemplazar la cantidad real—
Si tienes U datos únicos repetidos R veces, la cantidad efectiva de datos no es U×R, sino que se convierte según la curva de decaimiento exponencial D_eff = U·(1 - e^(-R)). La primera repetición aún puede aprender mucho nuevo, pero en la quinta, décima repetición, el beneficio de aprendizaje marginal se acerca a cero.
También encontraron una conclusión contraria a la intuición: Los parámetros excesivos "se devalúan" más rápido que los datos repetidos. Es decir, con presupuesto limitado, en lugar de aumentar el modelo, es más rentable ejecutar algunas repeticiones más de entrenamiento.
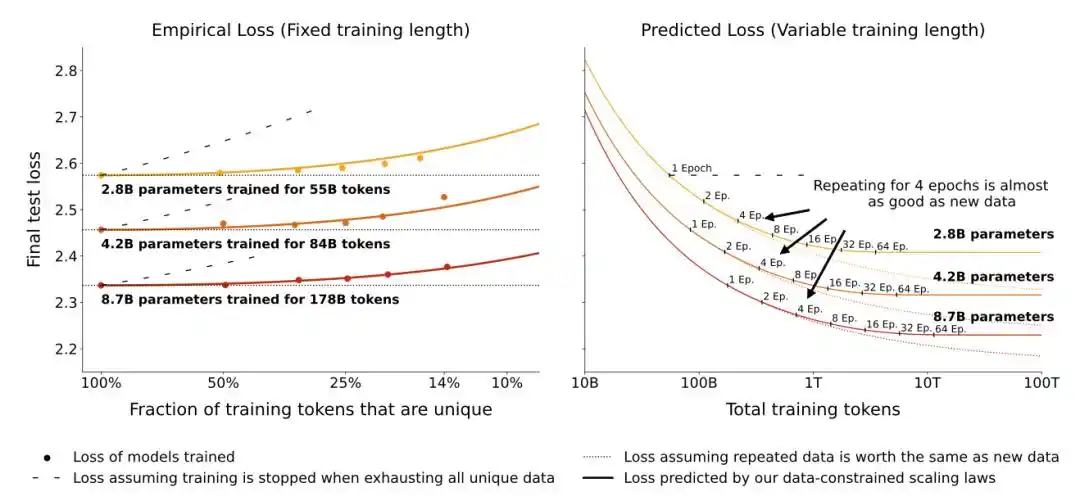
Un nuevo artículo en mayo de 2026 tomó un enfoque diferente.
No convirtieron la cantidad efectiva de datos, sino que agregaron directamente un término de penalización por sobreajuste explícito a la fórmula clásica de pérdida—cuanto más veces el modelo ve los mismos datos, mayor es la penalización, y esta penalización está ligada al tamaño del modelo.
Su fórmula completa es así:
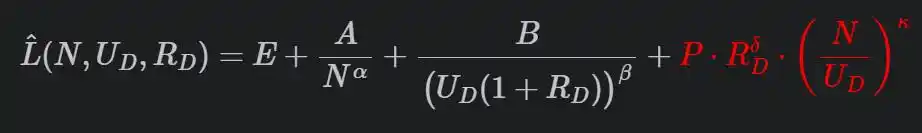
El último término rojo de penalización es clave.
R es el número de repeticiones, N/U es la relación entre los parámetros del modelo y la cantidad de datos únicos (cuán "sobredimensionado" está el modelo respecto a los datos), P, δ, κ son parámetros ajustados a partir de experimentos. Más repeticiones, modelo más grande, mayor penalización.
El hallazgo central de este artículo es: Los modelos grandes son más sensibles a la repetición de datos. Repetir el mismo dato 10 veces, un modelo de 500 millones de parámetros podría resistir, pero un modelo de 5 mil millones sufriría una caída de rendimiento mucho más severa.
Otro hallazgo directamente útil en ingeniería es: Fortalecer el decaimiento de pesos (weight decay) puede aliviar significativamente el sobreajuste causado por el entrenamiento repetido.
Por eso, entre 2025 y 2026, la atención de toda la industria se centró colectivamente en tres caminos para sortear el muro de datos—
Aprendizaje por refuerzo, DeepSeek R1, OpenAI o-series, haciendo que los modelos compitan consigo mismos en tareas verificables como matemáticas y programación, generando señales de entrenamiento.
Cálculo en tiempo de prueba, sin aumentar el costo de entrenamiento, permitiendo que el modelo "piense" algunos pasos más al responder para obtener un mejor rendimiento.
Datos sintéticos, usando modelos fuertes existentes para generar nuevos datos para entrenar la siguiente generación de modelos.
Los tres caminos tienen el mismo mensaje subyacente: La ley de potencia que solo depende de "apilar escala" ya no es suficiente.
De la Universidad de Pekín a OpenAI a su propia empresa
Lilian Weng, licenciada de la Universidad de Pekín, doctorada de la Universidad de Indiana en Bloomington.
Curiosamente, su dirección doctoral no fue aprendizaje profundo, sino ciencia de redes y sistemas complejos, estudiando cómo se propaga la información en redes sociales.
Después de graduarse, primero trabajó en ciencia de datos en Dropbox, luego en la empresa de tecnología financiera Affirm, y se unió a OpenAI en 2018.
Al llegar a OpenAI, el primer proyecto de Weng fue en robótica. La mano robótica Dactyl que aprendió a resolver un cubo de Rubik en dos años, ella fue una de las contribuyentes principales.
Luego se transfirió a construir el equipo de investigación aplicada, después del lanzamiento de GPT-4 fue nombrada para formar el equipo Safety Systems; cuando se fue, este equipo ya tenía más de 80 científicos, ingenieros y expertos en políticas.
En agosto de 2024 ascendió al cargo de VP of Research and Safety, y tres meses después anunció su salida.

En 2017, Weng, recién comenzando en aprendizaje profundo, abrió un blog personal llamado Lil'Log, originalmente solo para organizar sus notas de aprendizaje.
Ella dijo alguna vez, "Explicar un concepto con claridad es la mejor manera de comprobar si realmente lo entiendes".
El resultado fue que escribió durante nueve años, aprendizaje por refuerzo, modelos de difusión, agentes de modelos grandes, cada artículo desde los principios básicos, docenas de páginas largas con diagramas que ella misma dibujaba.
Este blog luego se convirtió en uno de los blogs técnicos personales más citados en el campo de la IA, muchas universidades lo usan directamente como material de enseñanza.
En febrero de 2025, ella y la exCTO de OpenAI Mira Murati fundaron Thinking Machines Lab, los cofundadores también incluyen al cofundador de OpenAI John Schulman, los ex VP de investigación Barret Zoph y Luke Metz. a16z lideró una ronda semilla de 20 mil millones de dólares, valoración de 120 mil millones.
Y mientras la empresa avanzaba a alta velocidad, ella se tomó el tiempo para escribir este extenso artículo sobre Leyes de Escalado que tenía tres años de retraso.
El ChatGPT, Claude, Gemini que usas todos los días, detrás están estas fórmulas decidiendo cómo entrenar la próxima generación.
La próxima generación de IA será útil o no, no depende de quién tenga más GPU, sino de quién maneje estos detalles con más precisión.
Referencias:
https://x.com/lilianweng/status/2070237256070389897?s=20
https://lilianweng.github.io/posts/2026-06-24-scaling-laws/
Este artículo proviene del WeChat público "New Zhiyuan", autor: ASI Apocalipsis, editor: Moisés


![Evaluando la caída del 12% del precio de Sonic [S] y por qué podría venir más venta](https://d1x7dwosqaosdj.cloudfront.net/images/2026-06/161e3d66eea4402796d2e6a66d93d453.jpg)




