【Introducción】En la reciente WWDC, la reconstrucción de Siri con IA fue una palabra clave, ¡y los "modelos locales" ya son una tendencia! Un poco antes, Andrej Karpathy abogó por despojar al modelo de su conocimiento y conservar solo el "núcleo cognitivo". Una empresa china afirma haber materializado esta dirección: 4B parámetros, logrando resultados de modelos grandes de cientos de miles de millones en tareas de inteligencia colectiva. ¿Qué puede cambiar realmente un modelo cognitivo local?
Anoche, Siri renació con la ayuda de Gemini de 1.2 billones de parámetros de Google.
Pero por otro lado, Amazon cerró su polémico ranking interno de IA: los empleados usaban masivamente herramientas de IA, elevando los costos de computación hasta niveles que la gerencia no podía tolerar.
El costo por token se ha convertido en el obstáculo más duro para la adopción masiva de la IA.
Andrej Karpathy propuso anteriormente una dirección: despojar al modelo de su vasto conocimiento, conservando solo un "núcleo cognitivo" que sepa pensar, planificar y reconocer sus propias limitaciones. Con 1B parámetros sería suficiente.

https://www.youtube.com/watch?v=lXUZvyajciY
Esta dirección se está verificando.
Un modelo de 4B parámetros ha logrado resultados equivalentes a modelos grandes de cientos de miles de millones como GPT-5.4 en tareas de inteligencia colectiva, y admite despliegue local.
Proviene de un equipo fundador que anteriormente, con un modelo de 3.6B parámetros, venció a Llama de 65B y alcanzó el primer lugar en el ranking japonés de Hugging Face.
Esta vez, han creado el primer modelo cognitivo local de la industria.
La profecía de Karpathy y la factura de la computación
La presión del costo de la computación ha pasado de ser un tema técnico a uno financiero; el caso de Amazon es solo un ejemplo.
Los empleados de Amazon, mediante herramientas internas de IA, invocaban frecuentemente la capacidad de inferencia de modelos grandes, incrementando el gasto general en computación, lo que obligó a la gerencia a suspender urgentemente el mecanismo de ranking para contener el uso.

https://www.ft.com/content/b1a62a7f-6df5-4c90-94ce-64ce9c9961b6?syn-25a6b1a6=1
La industria está experimentando su primera "gran retirada de tokens"; el consumo diario de computación de algunas empresas ya alcanza niveles de cientos de millones.
El modelo de negocio de los modelos grandes choca contra un muro estructural: a mayor capacidad y profundidad de la cadena de razonamiento, mayor es el costo por invocación.
La relación costo de GPU / ingresos (GPU Cost / Revenue) es un indicador crucial para todas las empresas de IA, y la tendencia de inflación continua de los parámetros del modelo solo empeorará esta métrica.
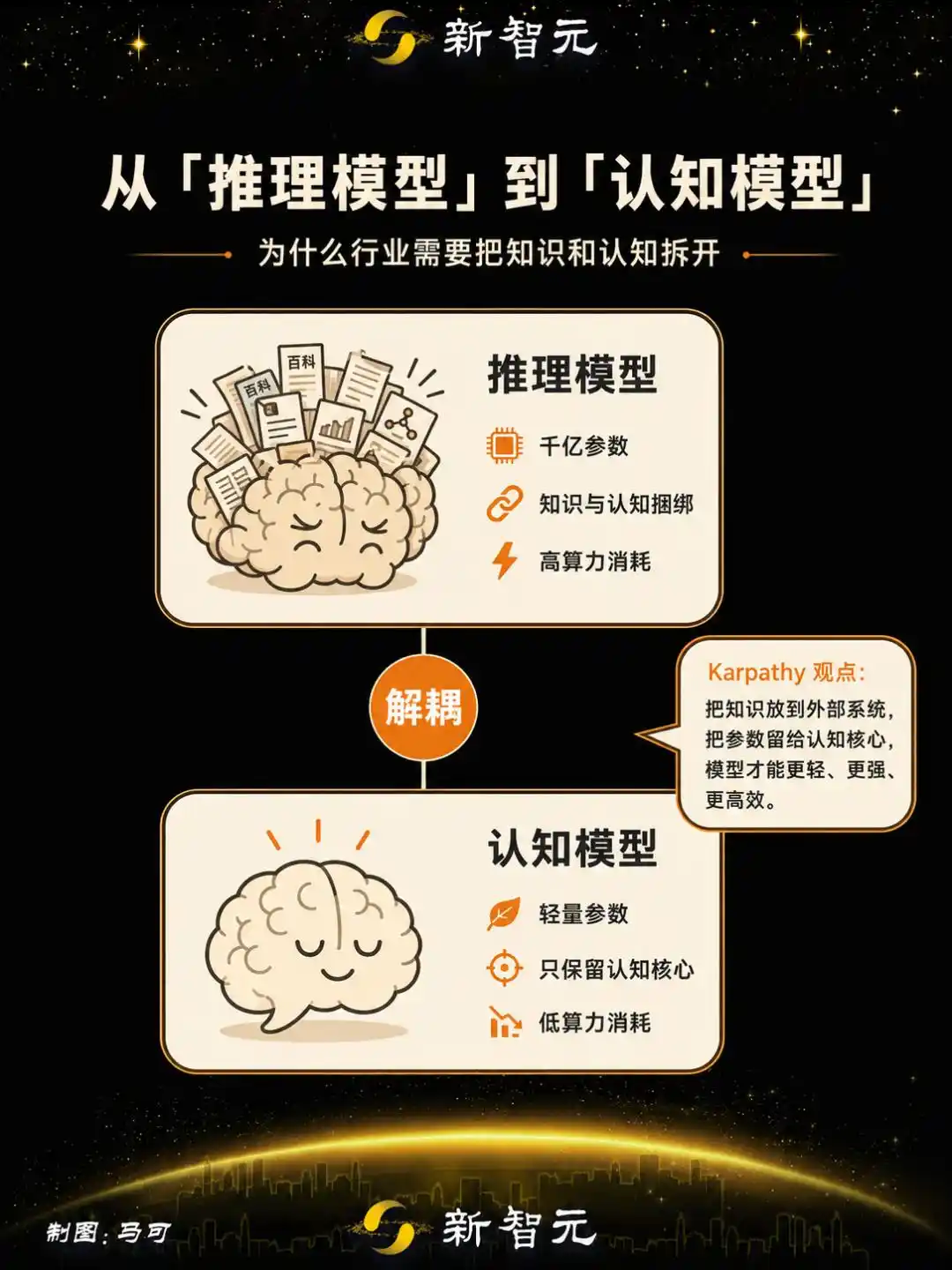
El enfoque de Karpathy apunta a otro camino: propone la necesidad de desacoplar la "memoria / conocimiento" del modelo, conservando lo que él llama el "núcleo cognitivo"—
una entidad despojada de una vasta cantidad de hechos y conocimiento, pero que conserva el algoritmo de pensamiento, la magia de la inteligencia y las estrategias de resolución de problemas.
Él estima que incluso a una escala de mil millones de parámetros, se podría lograr un pensamiento eficiente similar al humano:
Pensaría como un humano... Si le preguntas algo fáctico, podría necesitar consultar—sabe que no lo sabe y buscaría la información.
Estas declaraciones han generado un amplio debate en la comunidad técnica.
Se está formando un consenso sobre la dirección, pero los equipos que puedan llevar el "núcleo cognitivo" del concepto a un producto desplegable son la verdadera variable.
4B iguala a modelos de cientos de miles de millones: ¿Qué ha hecho Nextie Alpha?
Quien ha llevado el "núcleo cognitivo" descrito por Karpathy del concepto al producto es Nextie.
Esta empresa entrena modelos de razonamiento de código abierto con aprendizaje por refuerzo, desacoplando el conocimiento de la cognición—elimina la reserva de conocimiento memorístico del modelo y refuerza la capacidad de generalización y pensamiento abstracto.
El modelo resultante se llama Nextie Alpha, tiene una escala de 4B parámetros, ha completado el entrenamiento y está desplegado, siendo el primer producto definido como "modelo cognitivo" en la industria.
En cuanto a su método de entrenamiento, es un punto de partida poco común.
El equipo de Nextie recopiló artículos académicos humanos desde 1800 hasta 2020, abarcando 220 años, intentando trazar la evolución de la inteligencia colectiva para proporcionar un marco de referencia a la ruta tecnológica.
Sobre la base de esta investigación, aplicaron aprendizaje por refuerzo a modelos de razonamiento de código abierto, centrándose en mejorar las capacidades de generalización y abstracción.
Un ejemplo intuitivo: el modelo entrenado puede transferir los patrones de decisión de un jugador de Go a escenarios de la vida diaria—lo que Karpathy llamaba "conservar el algoritmo de pensamiento" tiene aquí una implementación técnica concreta.
En cuanto a la efectividad, Nextie Alpha en tareas de inteligencia colectiva (debate, reflexión, desafío, votación, etc.) con 4B parámetros alcanzó una calidad de salida equivalente a la de modelos grandes como GPT-5.4, con ventajas significativas en consumo de computación y velocidad de inferencia.
Lo que merece más atención es el espacio de escenarios que desbloquea este modelo, con tres niveles de significado progresivo.
Primer nivel: mejora de la calidad de decisión multiagente.
En el marco de decisión Harness, el uso del modelo cognitivo produce mejores resultados que el modelo de razonamiento.
La actualización del modelo subyacente de "razonamiento" a "cognitivo" conlleva un salto en la calidad general de la cadena de decisiones dentro de los sistemas de colaboración multiagente.
Segundo nivel: reducción a gran escala del costo de computación.
4B comparado con modelos de cientos de miles de millones de parámetros reduce drásticamente el costo de computación en despliegue en la nube.
Nextie Alpha también admite despliegue local—puede ejecutarse directamente en MacBook, dispositivos de inteligencia corpórea, etc. El costo de computación se transforma así en costo eléctrico.
Esto es particularmente significativo para el campo de la inteligencia corpórea: impulsar un robot doméstico con un modelo grande de cientos de miles de millones, donde cada "pensamiento" consume muchos tokens, podría ser más costoso que contratar a una persona.
El despliegue local de 4B reescribe fundamentalmente esta ecuación.
Tercer nivel: desbloqueo de escenarios proactivos (Proactive).
La gran mayoría de los productos de IA actuales funcionan en modo reactivo (Reactive)—el usuario da una orden, el modelo responde.
El modo Proactive significa que el agente inteligente decide y ejecuta tareas de forma autónoma, sin esperar órdenes. Su escala comercial supera con creces la del modo Reactive, pero hasta ahora estaba bloqueada por los costos de computación.
Nextie Alpha admite ejecución ininterrumpida las 24 horas con costos controlables, haciendo posible los agentes proactivos que antes se descartaban por ser demasiado caros.

Las cartas del equipo y la posición en el sector
Nextie fue fundado por el equipo fundador original de Microsoft Xiaoice.
La etiqueta de este equipo es "ganar a modelos grandes con pocos parámetros"—anteriormente, su modelo de código abierto rinna (Xiaoice Japón) con 3.6B parámetros alcanzó el primer lugar en el ranking japonés de Hugging Face, derrotando a Llama de 65B parámetros.
Que Nextie Alpha con 4B iguale el efecto de modelos de cientos de miles de millones continúa la misma genética tecnológica.
El sector en el que Nextie está apostando fuertemente es—los sistemas multiagente colectivos Harness.
Este sector está recibiendo confirmación de capital de primer nivel—en marzo de 2026, OpenAI invirtió en la startup Isara, llevando directamente su valoración a 650 millones de dólares. La dirección de investigación de Isara es precisamente la colaboración multiagente y la inteligencia colectiva.

https://www.wsj.com/tech/ai/openai-backs-new-ai-startup-seeking-bot-army-breakthroughs-a0b1fedc
En la evaluación de profundidad de inteligencia (IDI) de este campo, el desempeño integral de Nextie es significativamente superior al de cualquier modelo grande individual.
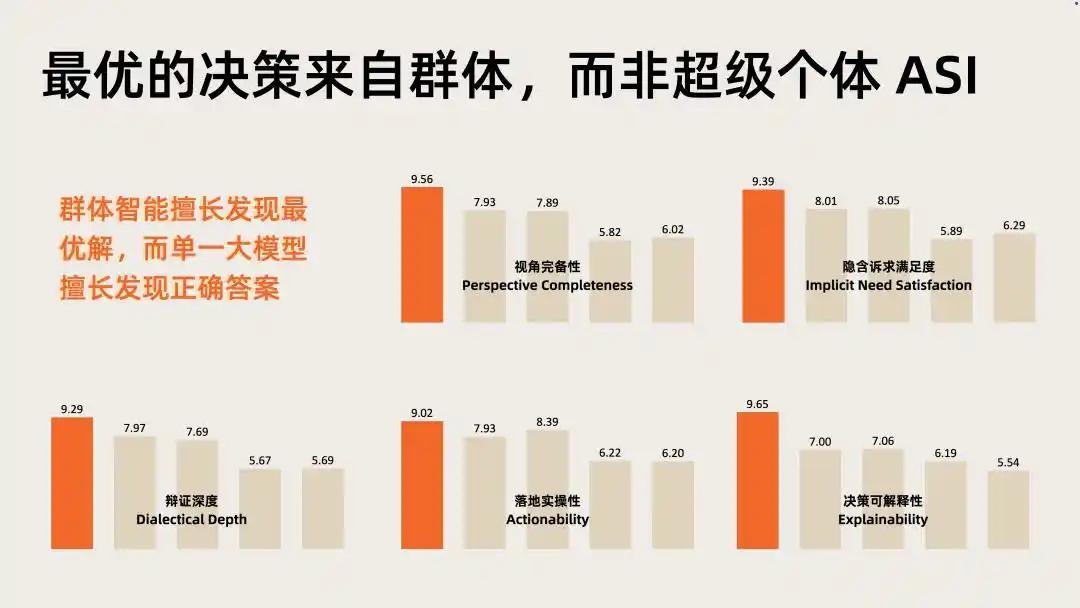
El capital ha validado el valor del sector, y los datos de evaluación han posicionado a Nextie dentro del mismo.
Dos señales superpuestas apuntan al mismo juicio: los sistemas multiagente colectivos son la siguiente dirección de alto valor en la capa de aplicación de la IA, y los modelos cognitivos son la infraestructura clave para impulsarlos.
Lo que el modelo cognitivo cambia no son solo los parámetros, sino el libro de cuentas
La relación costo de GPU / ingresos (GPU Cost / Revenue) es la espada de Damocles que pende sobre todas las empresas de IA.
La solución que proporcionan los modelos cognitivos apunta centralmente a la reestructuración del modelo económico—alcanzar con 4B el efecto que antes requería cientos de miles de millones significa que la misma calidad de salida corresponde a una estructura de costos completamente diferente.
Nextie reveló en una entrevista que el equipo está entrenando un modelo cognitivo de 8B con mayor capacidad de generalización.
Si 4B ya puede igualar a GPT-5.4 en tareas de inteligencia colectiva, los límites de capacidad de 8B son dignos de expectación.
Una pregunta más profunda queda para toda la industria: Cuando el costo de ejecutar un modelo cognitivo local las 24 horas se reduce a un nivel insignificante, es posible que todos los productos de IA diseñados hoy en día basados en el modo reactivo (Reactive) de "orden del usuario, respuesta del modelo" necesiten reevaluar su forma de producto.
El espacio de imaginación comercial para los agentes proactivos (Proactive) supera con creces todo lo que existe actualmente bajo los agentes reactivos (Reactive).
Este artículo proviene del WeChat oficial account "新智元" (Nueva Era de la Inteligencia), autor: ASI启示录







