Algunos celebran que esta es la vez que OpenAI ha sido "más abierto". Añadir a Codex un enchufe que permite cambiar de modelo a voluntad equivale a allanar con sus propias manos la fosa que protegía sus modelos. ¿Qué persigue con esto?
De la noche a la mañana, el agente de programación inteligente Codex de OpenAI ya no solo reconoce sus propios modelos GPT, sino que se ha abierto a todos los modelos de código abierto.
La comunidad de desarrolladores fue la primera en detectar esta señal.
Un desarrollador descubrió en la configuración de la interfaz de línea de comandos (CLI) y el kit de desarrollo de software (SDK) de Codex un modo desconocido de código abierto (OSS mode), también llamado oficialmente "proveedores locales" (local providers).
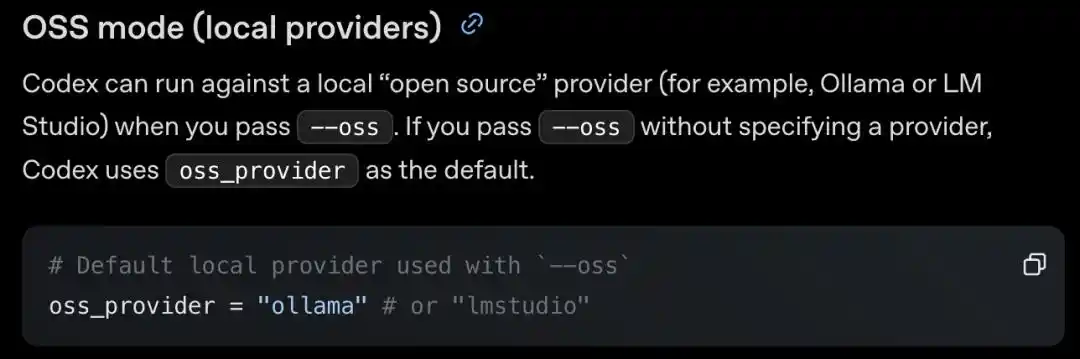
Añadiendo un simple --oss en la línea de comandos, puede ejecutar modelos de código abierto localmente; si se quiere conectar otro, basta con cambiar un campo.
Hay que recordar que en el pasado, OpenAI era casi sinónimo de "código cerrado", y Codex solo reconocía los GPT propios de OpenAI.
Pero ahora es diferente. Con solo una línea de configuración, se puede cambiar a servicios de modelos locales como Ollama, LM Studio, etc.
Esto pronto causó revuelo en los círculos de desarrolladores.
Tibo, responsable del equipo de OpenAI Codex, no olvidó recordarlo personalmente en X:
Las aplicaciones, CLI y SDK de Codex pueden usarse con cualquier modelo de código abierto, no solo con los propios de OpenAI.
Este recordatorio fue rápidamente retransmitido por Thomas Wolf, cofundador de Hugging Face, quien añadió una exclamación: Hoy me entero de que ya se pueden usar modelos de código abierto en Codex.

Algunos internautas exclamaron que esta podría ser la vez más "abierta" en la historia de OpenAI, un asunto verdaderamente importante.

La comunidad actuó aún más rápido.
Tan pronto como salió la documentación oficial, los desarrolladores probaron a conectar algunos modelos de código abierto y comenzaron a discutir sobre esquemas de combinación que ahorren más tokens.
Pero también hubo quienes pronto encontraron obstáculos.
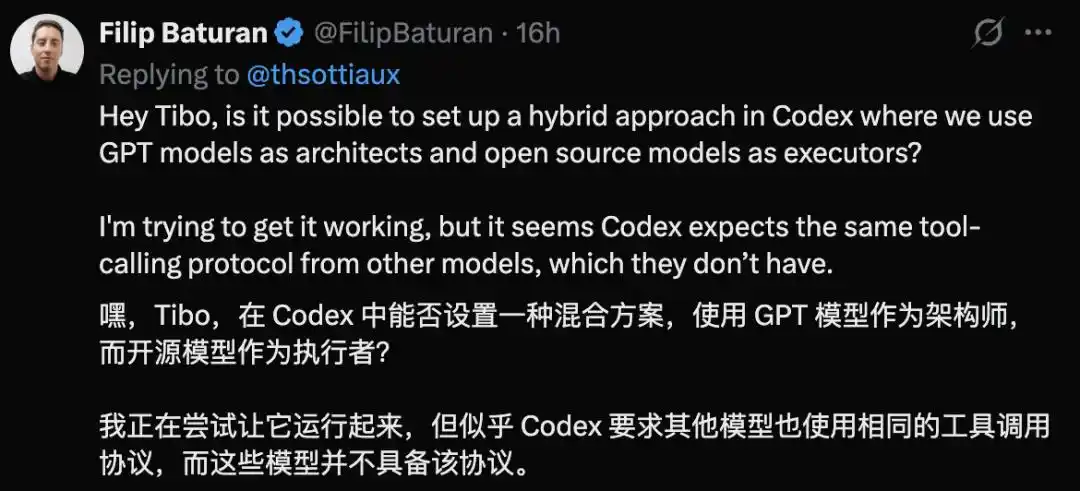
El desarrollador Filip Baturan quiso implementar un esquema híbrido en Codex: que GPT hiciera la planificación y luego un modelo de código abierto actuara como ejecutor.
Sin embargo, al probarlo descubrió que Codex requiere que los modelos conectados también usen el mismo protocolo de llamada a herramientas, lo cual los modelos de código abierto no necesariamente tienen.
Por un lado, el júbilo por la "apertura histórica"; por otro, el protocolo que no se puede conectar.
Esta vez, ¿hasta qué punto ha llegado la apertura de OpenAI?
¿Cómo se conectan los modelos de código abierto a Codex?
La apertura de OpenAI hacia Codex esta vez, en esencia, no es abrir el modelo en sí, sino abrir la "capa de acceso al modelo".
En otras palabras, no ha abierto el modelo GPT, sino que ha añadido a Codex una "capa de interfaz de modelo intercambiable".
Esta capacidad se logra mediante una configuración llamada proveedores de modelos (model_providers).
Los desarrolladores pueden registrar múltiples "proveedores de modelos" en el archivo de configuración. Cada proveedor contiene cuatro tipos de información:
Dirección de acceso (base_url), protocolo de comunicación (wire_api), método de autenticación (env_key) y relación de mapeo de modelos (model).
Al iniciarse, Codex selecciona el proveedor de modelos correspondiente según la configuración, enrutando así las solicitudes a diferentes servicios de modelos, incluidos los propios modelos de OpenAI, modelos locales de Ollama o APIs de terceros como DeepSeek.
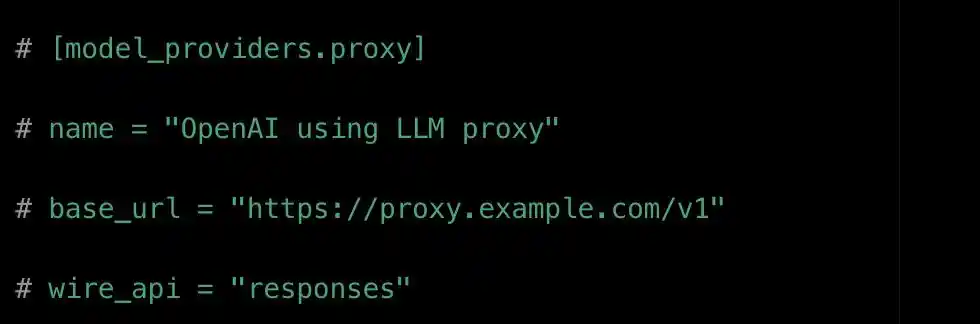
Ejemplo de configuración model_providers en Codex. base_url es la dirección del modelo, y el campo de protocolo wire_api solo acepta un valor: responses.
Mistral, proxies empresariales autogestionados, estaciones de transferencia de terceros, todos pueden conectarse a Codex de esta manera.
Algunos internautas han resumido las ventajas de esta capacidad como: no estar atado a un solo proveedor, cambiar según las necesidades, con la privacidad y el costo bajo control propio.
Lo más conveniente es que también puedes guardar esta configuración como "perfiles", y al depurar, con solo hacer clic en su nombre desde la línea de comandos, puedes cambiar a ella.
Además de la configuración manual anterior, hay un interruptor más directo: --oss. Al añadir este parámetro, Codex se conecta directamente a servicios de modelos de código abierto locales.
Por defecto, solo hay estos dos: Ollama y LM Studio. El primero es la herramienta más popular para ejecutar modelos grandes localmente, el segundo es una alternativa de escritorio con interfaz gráfica.
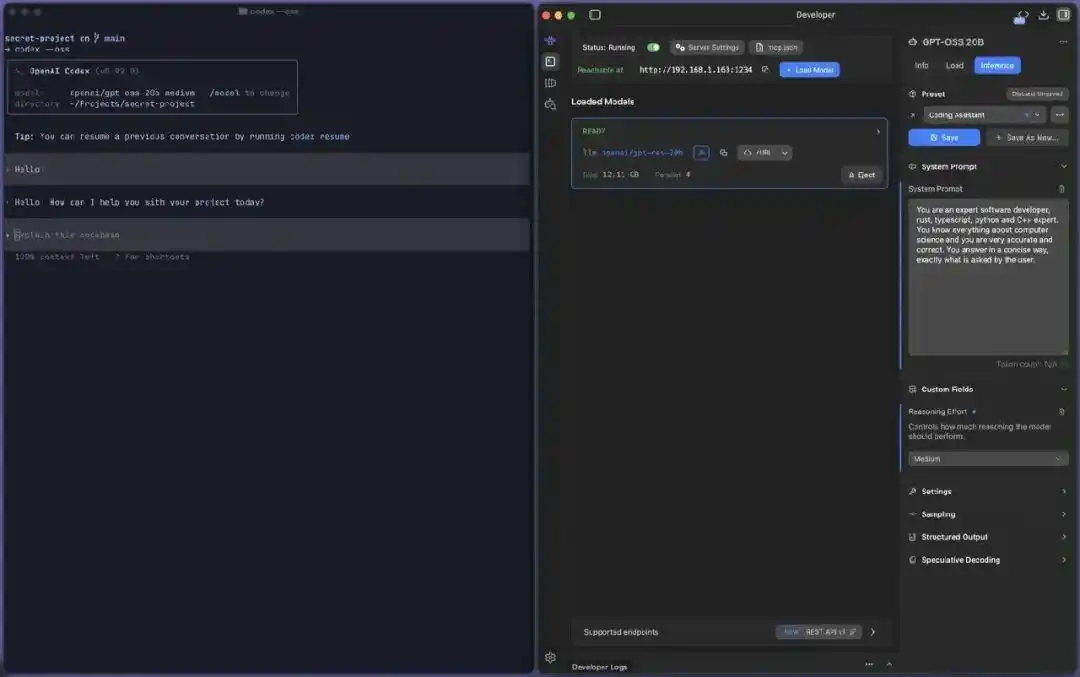
Captura de pantalla práctica de Codex --oss conectándose a un modelo local: a la izquierda, Codex CLI (v0.92.0) usando --oss para llamar al modelo local; a la derecha, LM Studio cargando openai/gpt-oss-20b (12.11GB) en el puerto local 1234 para ofrecer servicio, todo el proceso local y offline.
Es decir, a través de servicios de modelos locales y configuración de permisos de red, puedes hacer que Codex complete la generación de código y el razonamiento en tu máquina, logrando en cierta medida ejecución offline y procesamiento localizado.
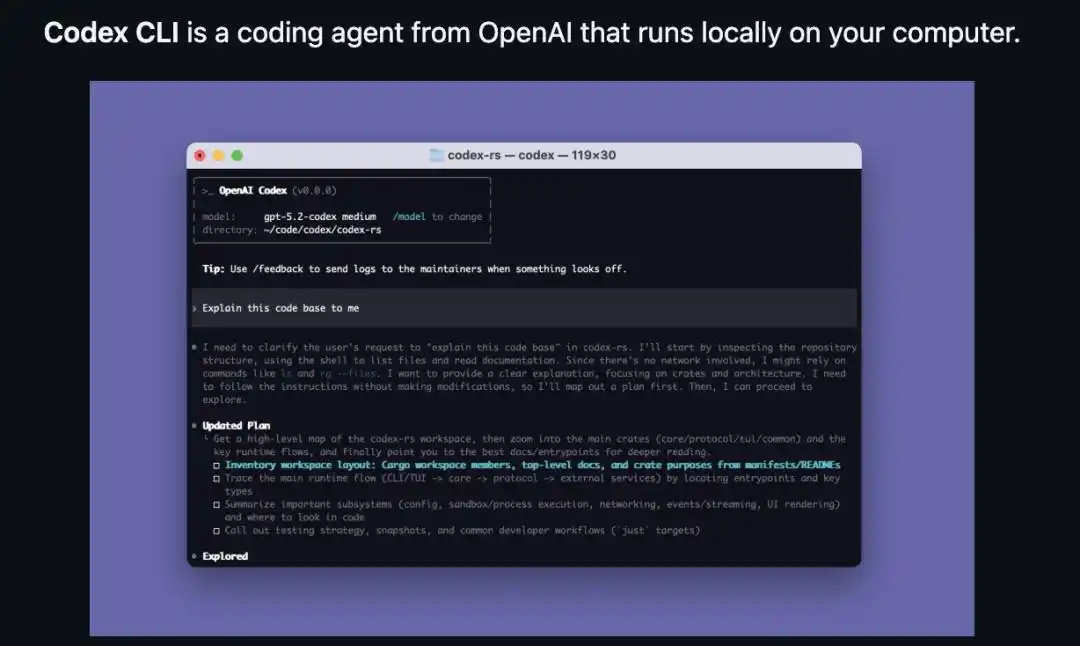
Interfaz de Codex CLI: En la información de inicio, la línea del modelo (model) indica el modelo actual (gpt-5.2-codex), seguido de "/model to change". Con un solo comando se puede cambiar el modelo, y todo el agente inteligente se ejecuta en la máquina local.
Sin embargo, tener el enchufe instalado no significa que cualquier aparato conectado funcione.
Los modelos conectados generalmente deben ser compatibles con el formato de interfaz de finalización de chat (Chat Completions); en cuanto a capacidades más complejas como la llamada a herramientas (function calling), la oficialidad no garantiza que funcionen completamente, hay que probarlos uno por uno.
Precisamente porque los protocolos a menudo no coinciden, la comunidad todavía tiene que escribir herramientas de enrutamiento para traducir en el medio. Y estas son soluciones exploradas actualmente por la comunidad, OpenAI oficialmente aún no las ha respaldado.
Cuando GPT y modelos de código abierto se combinan
Trabajando juntos en Codex
Mientras OpenAI oficialmente acababa de abrir una brecha, la comunidad ya se estaba divirtiendo con ello.
La razón es simple: Codex es bueno, pero usar los modelos de OpenAI con tarificación por token es demasiado caro.
Por lo tanto, muchos desarrolladores volvieron su mirada hacia los modelos de código abierto.
DeepSeek es uno de los modelos de código abierto más familiares para muchos desarrolladores chinos. Una pregunta natural es: ¿Puede Codex usar directamente DeepSeek?
La respuesta de CC Switch es: Sí, pero no se puede conectar directamente, necesita una capa extra de "intermediación".
Tutorial de la comunidad CC Switch: «Ejecutando DeepSeek en Codex con enrutamiento local»
Su tutorial comunitario «Ejecutando DeepSeek en Codex con enrutamiento local» señala que la razón es que la nueva versión de Codex se basa principalmente en la API de Respuestas (Responses API) de OpenAI, mientras que DeepSeek y la mayoría de las interfaces de modelos de código abierto siguen basándose principalmente en Finalizaciones de Chat (Chat Completions).
Los dos conjuntos de interfaces no son completamente consistentes en la estructura de solicitud, el modo de salida en flujo (streaming) y los mecanismos de llamada a herramientas.
Por lo tanto, si simplemente se introduce la dirección de DeepSeek en Codex, no funcionará correctamente. La situación común es que los parámetros de solicitud no coinciden o los resultados devueltos no pueden ser analizados, lo que lleva a fallos en la llamada o salidas anómalas, y no simplemente a "no conectarse".
La solución de la comunidad es añadir una capa intermedia de "capa de enrutamiento" o "convertidor de protocolos" local.
El flujo básico es el siguiente:
1. Codex envía la solicitud según la API de Respuestas (Responses API);
2. La capa de enrutamiento la convierte al formato de Finalizaciones de Chat (Chat Completions);
3. La reenvía a modelos de código abierto como DeepSeek;
4. Luego convierte los resultados devueltos al formato de Respuestas que Codex puede reconocer.
Capacidades similares no las ofrece solo CC Switch.
LiteLLM, claude-code-router, así como varios servicios proxy autogestionados por desarrolladores, esencialmente resuelven el mismo problema: permitir que diferentes modelos interactúen a través de una interfaz unificada.
OpenAI esta vez abrió una brecha, pero para implementarlo realmente, la comunidad necesita "añadir ladrillos y tejas" por sí misma.
Detrás de todo esto hay una forma de juego de enrutamiento mixto.
Por ejemplo, dejar que GPT se encargue de la planificación: descomponer tareas, diseñar la arquitectura, pensar claramente qué hay que hacer. Dejar que los modelos de código abierto se encarguen de la ejecución: convertir el plan en código ejecutable, modificar archivos por lotes.
Con tal combinación, para la misma tarea, el costo puede reducirse a más de la mitad.
Además de ser más económico, al configurar Codex con modelos de código abierto locales, el código no sale de tu propio ordenador.
Para aquellos desarrolladores individuales que no quieren subir sus proyectos privados a la nube ni seguir pagando por la API, esta tentación no es pequeña en absoluto.
La guerra de los modelos ha terminado
La guerra de las interfaces ha comenzado
En los últimos años, todos pensaban que la fosa defensiva era el modelo. Quien tuviera el modelo con más parámetros, mejores puntuaciones y respuestas más inteligentes, ganaría.
Pero esta vez, OpenAI ha convertido la capa de Codex en una interfaz intercambiable, y su valor ofrecido también comienza a desplazarse hacia la entrada del ecosistema.
Los cálculos de OpenAI probablemente sean transformarse de un vendedor de modelos a un jugador que vende plataformas y marcos de trabajo: cambia el modelo como quieras, pero la herramienta debe ser mía.
Quien ocupe la entrada que los desarrolladores abren todos los días, quien controle la distribución, se sentará en la posición central del ecosistema.
Tampoco es la primera vez que OpenAI planifica en el ecosistema de código abierto.
Aunque desde que lanzó GPT-2 en 2019 no volvió a publicar durante mucho tiempo modelos de lenguaje grandes de pesos abiertos, bajo el rápido desarrollo del ecosistema de código abierto (como los modelos Llama, DeepSeek, etc.), en agosto de 2025 relanzó la serie de modelos de pesos abiertos gpt-oss.

Estos modelos fueron rápidamente integrados y soportados por las cadenas de herramientas de la comunidad (como Ollama, LM Studio, etc.), que son precisamente las que Codex --oss ahora conecta y soporta por defecto.
En la capa de configuración, OpenAI ciertamente ha abierto la capacidad de acceso a modelos, permitiendo a través de la capa de abstracción de proveedores de modelos que los modelos de terceros se conecten, pero no cualquier modelo puede usarse directamente, debe cumplir con su protocolo de interfaz o pasar por una capa de adaptación para la conversión.
En la capa de protocolos, retiene una restricción clave: utilizar la API de Respuestas (Responses API) como estándar principal de interacción, permitiendo al mismo tiempo a través de una capa de compatibilidad soportar otras interfaces de modelos como Chat Completions.
Es decir, independientemente del modelo que se conecte, es necesario alinearse con la estructura de solicitud y respuesta definida por OpenAI. Lo que finalmente quiere hacer es mantener el estándar de interfaz en sus propias manos.
Desde esta perspectiva, esta capa de protocolo de interfaz, que antes pasaba fácilmente desapercibida, se está convirtiendo en un nuevo foco de competencia.
Quizás, esta vez OpenAI quiera, con un interruptor de configuración insignificante, desencadenar una guerra por la entrada de la programación con IA, lo que hace que su próximo enfrentamiento con Anthropic ya no esté en los modelos.
Para los desarrolladores que abren Codex todos los días, esto es una conveniencia tangible: pueden ejecutar modelos de código abierto, ahorrar tokens y trabajar localmente sin conexión.
Pero cuanto más cómodo y profundo sea su uso, más dependientes se volverán de esta entrada.
Referencias:
https://x.com/thsottiaux/status/2067181377028538431
https://developers.openai.com/codex/config-advanced#oss-mode-local-providers
https://www.ccswitch.io/en/tutorials/codex-deepseek-routing-guide
Este artículo proviene del cuenta oficial de WeChat "新智元" (Nueva Inteligencia), autor: ASI启示录, editor: 元宇






