En los últimos días, un modelo pequeño de 3B se ha vuelto viral en X porque, en algunas tareas de razonamiento con verificación de dificultad (como la programación), ha entrado en el rango de rendimiento de modelos de vanguardia como Gemini 3 Pro, GPT-5 high, Claude Opus 4.5, GLM-5, Kimi K2.5, y su tamaño es mucho menor que el de estos modelos.

Este modelo se llama VibeThinker-3B, es un modelo denso de razonamiento con 3 mil millones de parámetros, diseñado para explorar hasta qué punto se puede impulsar la capacidad de razonamiento verificable en un modelo pequeño y estricto.
Después del lanzamiento del modelo, muchas personas quedaron impresionadas con sus resultados y expresaron su deseo de probarlo.


Vale la pena señalar que también es un modelo chino, proveniente del equipo de Sina Weibo.
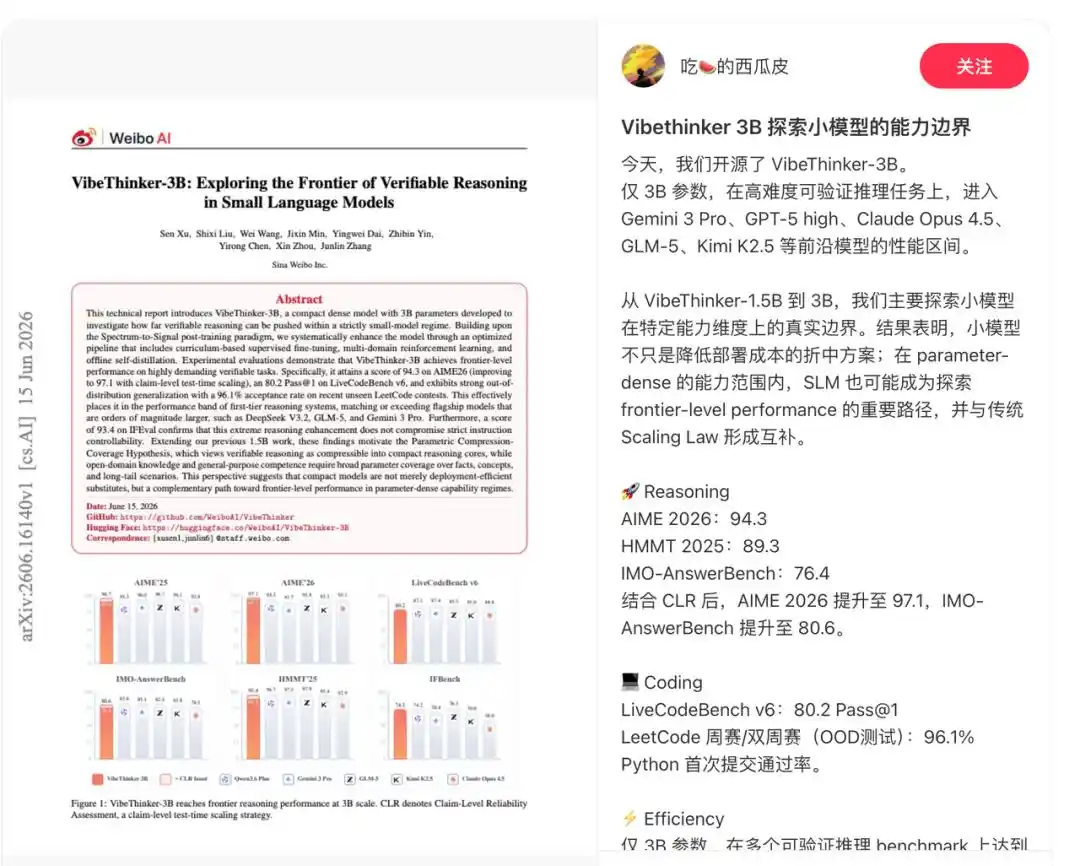
El informe técnico muestra que el modelo está diseñado específicamente para tareas con señales de verificación confiables, incluyendo razonamiento matemático, programación competitiva, razonamiento STEM y ejecución de instrucciones con restricciones claras.
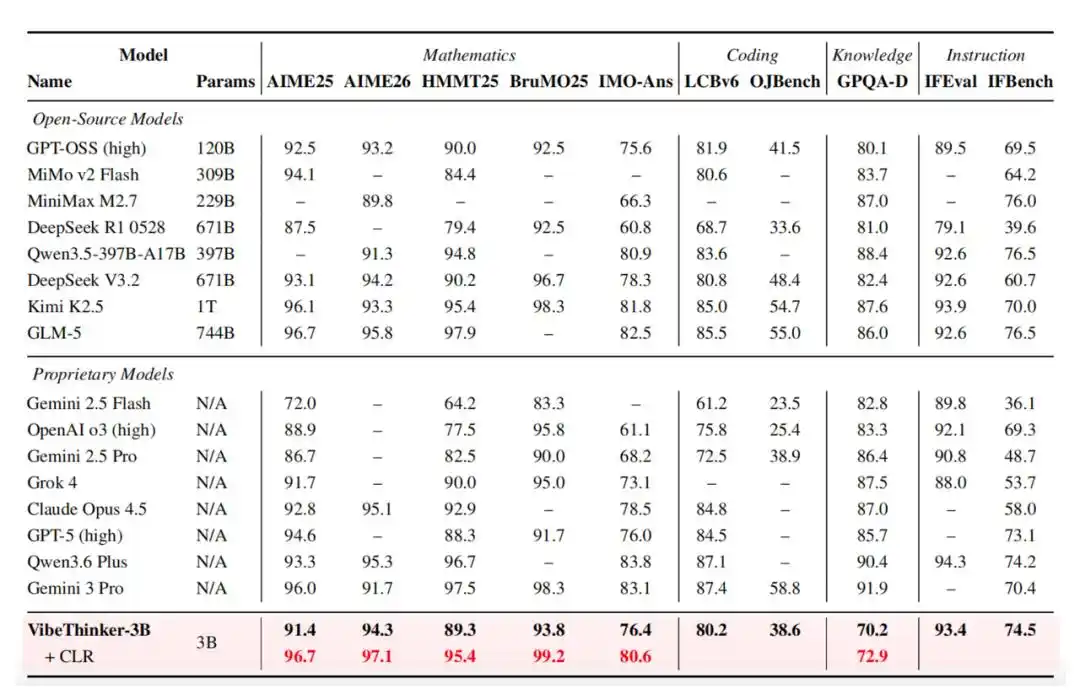
Por lo tanto, tiene un rendimiento sobresaliente en varias pruebas de referencia. Obtuvo una puntuación de 94.3 en la prueba AIME26, 89.3 en HMMT25, 80.2 (Pass@1) en LiveCodeBench v6, y logró una tasa de aprobación del 96.1% en los concursos semanales y quincenales más recientes y no públicos de LeetCode entre el 25 de abril y el 31 de mayo de 2026.

¿Cómo se entrenó este modelo? El informe técnico revela algunos detalles.
Primero, se basa en Qwen2.5-Coder-3B y utiliza un proceso actualizado de Spectrum-to-Signal para el post-entrenamiento. Este proceso reforzó la síntesis de datos, el filtrado de calidad y el aprendizaje curricular en el ajuste fino supervisado (SFT), extendió el aprendizaje por refuerzo al estilo MGPO a múltiples dominios verificables, conservó trayectorias completas de razonamiento de contexto largo y consolidó las capacidades mediante auto-distilación fuera de línea y aprendizaje por refuerzo de instrucciones (Instruct RL).
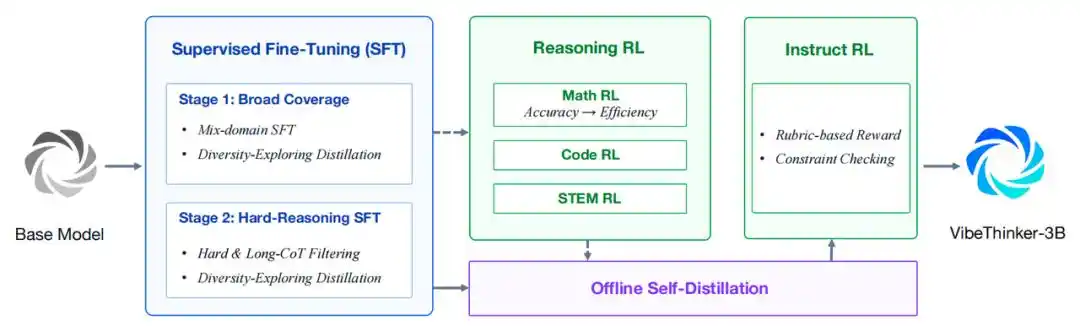
Flujo de entrenamiento general de VibeThinker-3B
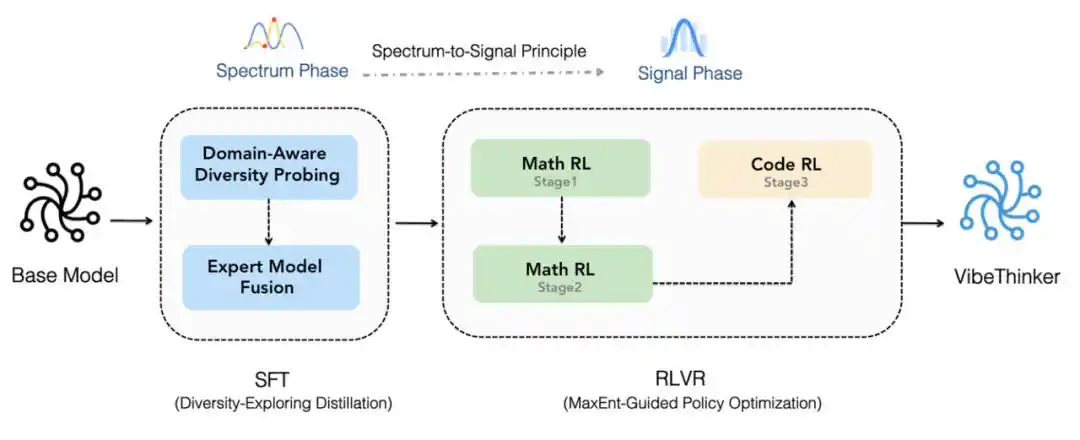
Proceso Spectrum-to-Signal.
Además, VibeThinker-3B introduce la evaluación de confiabilidad a nivel de afirmación (CLR), una estrategia de escalado en tiempo de prueba para razonamiento verificable orientado a respuestas. CLR mejora aún más el rendimiento en pruebas de referencia matemáticas, elevando AIME26 de 94.3 a 97.1, HMMT25 de 89.3 a 95.4, y llevando BruMO25 a 99.2.
Su flujo de entrenamiento específico es el siguiente:
- SFT en dos etapas basado en currículum. La primera etapa se centra en la cobertura amplia de capacidades como razonamiento matemático, programación, STEM, diálogo general y seguimiento de instrucciones. La segunda etapa se orienta hacia muestras de razonamiento más difíciles y de mayor alcance. La destilación de exploración de diversidad se usa para conservar múltiples rutas de solución efectivas.
- Aprendizaje por refuerzo de razonamiento en múltiples dominios. VibeThinker-3B reutiliza MGPO. El aprendizaje por refuerzo se aplica secuencialmente a tareas de razonamiento matemático, de programación y STEM. El entrenamiento utiliza una única ventana de contexto largo de 64K para conservar trayectorias completas de razonamiento de largo plazo.
- Auto-distilación fuera de línea. Se filtran y refinan trayectorias de alta calidad desde los puntos de control de RL matemático, de programación y STEM, formando finalmente un modelo de estudiante unificado. La puntuación de potencial de aprendizaje prioriza aquellas trayectorias correctas que el estudiante aún no imita bien.
- Instruct RL. La etapa final mejora la controlabilidad ante indicaciones orientadas al usuario. Para datos instructivos sensibles al formato y de tipo abierto, se utilizan verificadores basados en reglas y modelos de recompensa basados en criterios de evaluación.
En una publicación reciente, el reconocido investigador y blogger de IA Sebastian Raschka resumió sistemáticamente los puntos clave revelados en el informe técnico de VibeThinker-3B, incluyendo los siguientes:

Si estás interesado en este contenido, puedes consultar su informe técnico en detalle. Actualmente, el modelo también está disponible para descarga pública.

Título del informe: VibeThinker-3B: Explorando la frontera del razonamiento verificable en modelos de lenguaje pequeños
Enlace al informe: https://arxiv.org/pdf/2606.16140
Enlace de HuggingFace: https://huggingface.co/WeiboAI/VibeThinker-3B
Sin embargo, el ámbito de aplicación de este modelo tiene limitaciones claras, ya que no sobresale en áreas que requieren conocimiento general.
Los autores también señalan esto claramente y proponen la "hipótesis de compresión paramétrica por cobertura": diferentes capacidades dependen de los parámetros del modelo de maneras radicalmente distintas. El razonamiento verificable se acerca más a una capacidad altamente compresible y paramétricamente densa, cuyo núcleo reside en el razonamiento de múltiples pasos, la satisfacción de restricciones, la autocorrección y la verificación de respuestas. Cuando el espacio de tareas es suficientemente estructurado y las señales de retroalimentación son lo suficientemente confiables, los modelos compactos también pueden poseer capacidades de razonamiento cercanas a la vanguardia. En contraste, el conocimiento de dominio abierto, el diálogo general y la comprensión de escenarios de cola larga dependen más de grandes parámetros para cubrir ampliamente hechos, conceptos y conocimiento del mundo. Esta hipótesis es muy reveladora. VentureBeat escribió en su reportaje: "Revela que existe un desacoplamiento parcial entre la capacidad de razonamiento y el conocimiento fáctico, y que la primera puede comprimirse de manera más eficiente de lo que se pensaba — una perspectiva que tiene implicaciones profundas en cómo la industria ve el diseño de modelos, los costos de implementación y la accesibilidad de funciones avanzadas de IA."

Los autores indican que su objetivo no es crear un modelo pequeño que reemplace a los modelos grandes, sino examinar los límites reales de los modelos pequeños a lo largo de dimensiones de capacidad específicas. Con VibeThinker-3B, esperan mostrar que los modelos pequeños no deben verse meramente como una solución de compromiso para reducir los costos de implementación. En dominios de capacidad con mecanismos claros de retroalimentación y verificación, los modelos de lenguaje pequeños están mostrando una vía de investigación prometedora para lograr un rendimiento de nivel de vanguardia, formando una relación fundamentalmente complementaria con el paradigma tradicional de escalado de parámetros.
Actualmente, el modelo aún enfrenta algunas dudas en la comunidad. Si estás interesado en este modelo, puedes probarlo personalmente.

Enlaces de referencia:
https://x.com/orcus108/status/2066876960073281582
Este artículo es de la cuenta oficial de WeChat "机器之心" (ID: almosthuman2014), autor: Zhang Qian.





