En una fábrica de ropa en India, los trabajadores clasifican telas como de costumbre, pero esta vez llevan una cámara en la cabeza que graba vídeos en primera persona de su labor.
Tras su procesamiento, estos vídeos se convertirán en activos de datos, vendidos a empresas de inteligencia corporeizada que necesitan grandes volúmenes para entrenar robots.
Negocios similares han comenzado este año a acelerar la formación de una nueva cadena de suministro, cuyo surgimiento responde al principal cuello de botella de la industria de la inteligencia corporeizada: los datos.
«Este año la demanda ha aumentado notablemente», comentó a 42º Onda Radio un profesional de la recolección de datos para robots, cuyo equipo provee a empresas robóticas occidentales que están comprando masivamente datos de trabajo humano. Actualmente, su equipo cuenta con casi cien recolectores produciendo datos de entrenamiento, generando miles de horas mensuales de vídeo en primera persona.
Los recolectores deben seguir procedimientos estandarizados para tareas como doblar ropa, organizar la cocina o agarrar objetos, usando cámaras en la cabeza y, en algunos casos, guantes de datos para capturar movimientos finos de las manos.
«Antes la industria hablaba de modelos y hardware; ahora cada vez más preguntan: ¿podemos obtener un suministro estable de datos?»
Se ha tomado conciencia de que la falta de escala de datos es el mayor obstáculo para el avance de las capacidades de los modelos.
Ante la enorme brecha de datos para modelos corporeizados, el negocio de la recolección de datos ha comenzado a formarse rápidamente.
¿Por qué los robots carecen ahora de datos?
Si retrocedemos tres años, la robótica se parecía más a la automatización industrial tradicional.
La mayoría de los robots estaban fijos en fábricas, con flujos de trabajo altamente estructurados: soldar, transportar, pintar, ensamblar. No necesitaban comprender entornos complejos ni aprender capacidades de generalización, solo repetir movimientos en trayectorias predefinidas.
Ahora, muchas empresas, desde Tesla y Figure hasta PI, ya no buscan hacer robots industriales tradicionales. La industria intenta que los robots, como los grandes modelos lingüísticos, sean entrenados y posean capacidades generales.
Por ello, el camino de los modelos corporeizados se parece cada vez más al de los Grandes Modelos de Lenguaje (LLM), aunque es más arduo, especialmente en el ámbito de los datos.
Para los LLM, Internet es una mina de oro natural de datos: décadas de páginas web, libros, artículos y repositorios de código constituyen un corpus masivo. Las empresas de modelos suelen solo necesitar filtrar y limpiar datos, rara vez crearlos desde cero.
Pero los modelos corporeizados son distintos; se enfrentan al mundo físico, un desierto de datos. Los datos de movimiento de los robots no se generan espontáneamente. Aunque hay muchos vídeos de trabajo humano en Internet, su volumen y calidad son insuficientes para los robots.
Si los LLM nacieron en una biblioteca, los robots nacieron en un desierto.
Mientras la IA avanza hacia la competencia en potencia de cálculo y la optimización del razonamiento, la inteligencia corporeizada sigue atascada en el problema más básico: ¿de dónde vienen los datos?
Por eso, a pesar de la creciente complejidad de las arquitecturas de los modelos, los robots aún están lejos de entrar en hogares y escenarios complejos.
Porque les falta suficiente experiencia en el mundo real.
Brett Adcock, fundador de Figure, expuso una idea directa: «Si, chasqueando los dedos, pudiéramos introducir los datos masivos necesarios en el modelo Helix, tendríamos robots universales listos de inmediato».
Pero el problema es: ¿de dónde vienen los datos?
¿Cómo se produce una hora de datos?
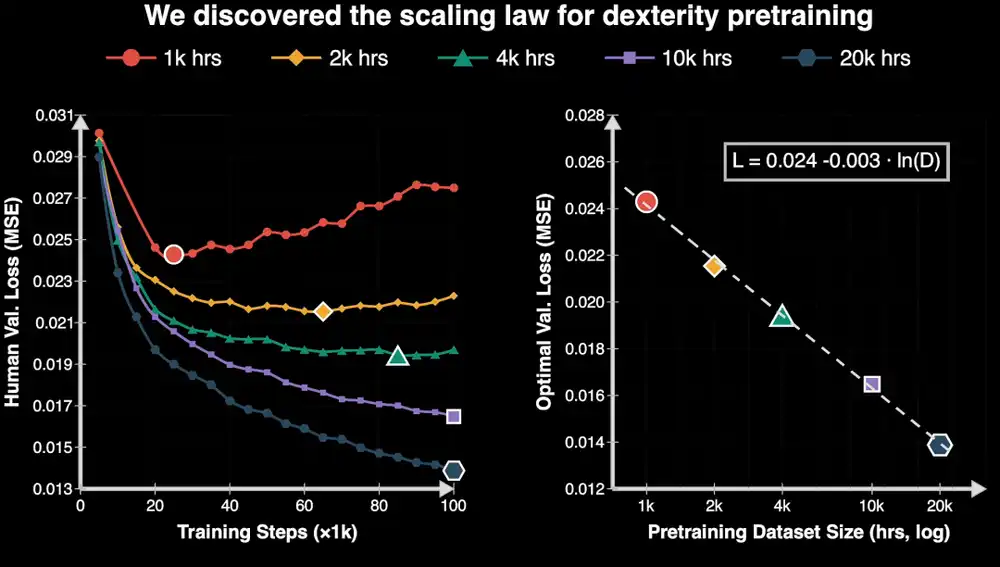
En febrero, un hallazgo de investigación entusiasmó a la industria.
El equipo de NVIDIA publicó EgoScale, que preentrena un modelo con más de 20,000 horas de vídeo en primera persona anotado con acciones, y luego lo afina con pocos datos de robots, permitiendo que la mano diestra de 22 grados de libertad Sharpa Wave realice tareas como desenroscar tapas o doblar ropa.

Lo más importante es que el estudio mostró que, al aumentar la escala de datos humanos, el rendimiento del modelo mejora de forma estable y predecible.
Esta investigación es crucial para la industria corporeizada, pues una vía de datos escalable implica que el crecimiento de las capacidades de los robots podría entrar en un ciclo virtuoso similar al de los grandes modelos: «más datos, mayor capacidad».
Durante mucho tiempo, la industria ha tenido la ansiedad de que, incluso con más inversión, la mejora de los modelos sigue siendo impredecible. Los datos del mundo real son escasos y costosos, y pocos se atreven a invertir grandes sumas en datos.
Pero EgoScale demostró algo: al menos para los datos en primera persona (Ego Data), la escala sí aporta beneficios estables a la operación de manos diestras.
Cada vez más empresas robóticas adoptan la ruta de muchos datos humanos + pocos datos del robot físico.
El vídeo en primera persona humana enseña al modelo cómo completan las tareas las personas; los datos del robot enseñan al modelo cómo debe actuar su propio cuerpo.
El valor principal de Ego Data es servir como conocimiento previo más fácil de escalar, permitiendo que el robot comprenda el mundo físico primero, y luego se adapte mediante pocos datos reales.
Así, la nueva cadena de suministro en torno a Ego Data también ha acelerado notablemente este año.
Una persona lleva una cámara en la cabeza o el pecho y realiza tareas concretas, como ordenar ropa, organizar la cocina o clasificar paquetes. La cámara graba el vídeo en primera persona.
En cierto modo, los humanos somos los robots universales más maduros. Al entrar en una cocina, evaluamos naturalmente qué hacer primero, y si falta espacio, liberamos la otra mano. Con objetos frágiles, ajustamos inconscientemente la fuerza.
Tras estos actos aparentemente instintivos hay una lógica profunda de comprensión espacial, planificación de tareas e interacción con objetos.
Y hasta ahora, los robots casi nunca han obtenido sistemáticamente esta experiencia.

Pero Ego Data no es simplemente grabar vídeos. Grabar a gran escala no es el mayor desafío; la clave es convertir esta experiencia en un producto de datos realmente utilizable por los modelos.
Un profesional que está acelerando su despliegue en datos Ego este año dijo a 42º Onda Radio que la recolección real suele comenzar con un documento de especificaciones de tareas del cliente.
Este documento no solo pide «datos de organización de cocina», sino que suele especificar claramente:
Tipo de tarea, si las manos deben estar completamente en cuadro, posición de la cámara (cabeza/pecho), si se permiten interrupciones, variaciones ambientales requeridas, necesidad de muestras de fallo, formato de entrega compatible con el marco de entrenamiento.
Por ejemplo, para organizar una cocina, el cliente puede requerir: abrir la puerta del armario, buscar un recipiente, hacer espacio, colocar objetos y cerrar la puerta en secuencia continua, sin saltos de cuadro u obstrucciones graves.
En cierto modo, esto se parece más a producir un artículo industrial, y todo el proceso de recolección es mucho más "fabril" de lo que se imagina.
En algunos centros de recolección, los operadores entran por turnos en cocinas, vestidores o áreas de estanterías preparadas, ejecutando tareas repetidamente según un Procedimiento Operativo Estándar (SOP) unificado.
Algunos se encargan de doblar ropa, otros practican agarrar objetos de distintos tamaños, y otros recogen datos de organización de cocina o transporte.
Una misma acción suele repetirse por personas de diferente estatura, mano dominante y hábitos operativos, intentando abarcar todas las situaciones posibles en el mundo físico. Al fin y al cabo, los robots se enfrentan a un mundo real complejo, no a una única respuesta estándar.
El simple acto de guardar una taza en un armario varía: algunos hacen espacio primero, otros cambian de mano, otros abren la puerta primero. Estas diferencias sutiles son precisamente parte de la capacidad de generalización del robot.
Por eso, muchos modelos corporeizados necesitan aprender la lógica de «cómo suele completar un humano esta tarea».
Este tipo de datos, comparado con los datos reales del robot, es más fácil de producir en masa. Ante la gran demanda de la industria, si se alcanza escala y los costos laborales son bajos, se sientan las bases para obtener ganancias y generar flujo de caja.
Pero si los datos no cumplen los requisitos del cliente, hay que rehacerlos. La duración efectiva que pasa la validación del cliente y puede usarse directamente para entrenar es mucho menor que la duración grabada originalmente.
A partir de aquí, la industria muestra una estratificación cada vez más clara. Diferentes datos tienen valores muy distintos. Desde una perspectiva de costo y valor, se puede formar una «pirámide de datos».
Los distintos tipos de datos tienen valores muy diferentes
En la «pirámide de datos», la base son los datos de Internet, con un costo de recolección casi nulo y cierta escala.
Los robots pueden aprender cómo son los objetos o la disposición general de una cocina. Pero el problema es obvio: solo ayuda al robot a "saber", difícilmente a "hacer". Lo realmente difícil del mundo real son las acciones: fricción, peso, variaciones de material, limitaciones de espacio, riesgo de colisión. Esto no se aprende solo con vídeos ordinarios.
El siguiente nivel son los datos humanos de mayor calidad, donde Ego Data es la parte más importante. Desde la primera persona, muestra al modelo cómo operan los humanos. Estos datos de vídeo pueden usarse a gran escala para preentrenamiento, como en EgoScale.
Pero el robot aún debe resolver cómo debe actuar su propio cuerpo. Desenroscar una tapa es fácil para una mano humana, pero un robot puede fallar repetidamente.
Por eso, los datos de percepción de guantes de datos son cada vez más importantes. El Ego Data ordinario solo muestra al modelo lo que vio el humano y qué tarea completó. Pero el robot también necesita saber cuándo aumentar la fuerza o cuándo relajarse.
Estos movimientos sutiles son difíciles de inferir solo con vídeo. Así, cada vez más empresas intentan alinear la captura de movimiento de manos, estimación de postura, trayectorias articulares con datos visuales.
El vídeo aporta comprensión espacial; los guantes, detalles de movimiento; y los datos reales de teleoperación ayudan aún más al robot a entender cómo ejecutar las acciones con su propio cuerpo.

Pero la industria aún enfrenta un problema real: la falta de estandarización en los guantes. La frecuencia de muestreo, definición de articulaciones, precisión y formas de expresar movimientos varían mucho entre dispositivos. Mapear de forma estable acciones humanas a distintos cuerpos robóticos sigue siendo un gran obstáculo.
Por eso, si solo se usa una cámara en la cabeza sin guantes de datos, el precio de Ego Data no es muy alto. Pero al añadir guantes, el precio se dispara rápidamente.
Subiendo en la pirámide están los datos de simulación. Mediante entornos de gemelo digital, los robots pueden entrenarse a alta velocidad en mundos virtuales, repitiendo millones de veces acciones de agarre, navegación y evitación de obstáculos. El volumen de datos que lleva un mes en la realidad puede completarse en días en simulación.
Pero la simulación no es el mundo real. Aunque es masiva y de bajo costo, factores casuales como fricción, variaciones de material o reflejos son difíciles de replicar por completo. Esto es la conocida «brecha Sim-to-Real»: un robot que aprende bien en simulación a menudo ve sus capacidades mermadas en entornos reales.
La cima de la pirámide la ocupan los datos reales del robot, de mayor calidad, más caros y escasos. Se obtienen principalmente mediante teleoperación, donde un operador controla al robot para completar tareas, y el robot registra simultáneamente visión, acciones, señales de control y estado de sensores.
A diferencia de los datos humanos, estos datos existen naturalmente en el espacio de acciones del robot, por lo que el modelo no necesita esforzarse en entender cómo mapear acciones humanas al cuerpo robótico. Además, incluyen datos de trabajo autónomo generados durante su aplicación, aunque actualmente los robots aún no se despliegan masivamente, por lo que estos datos también son escasos.
El problema clave de los datos reales es su baja eficiencia productiva. Para aumentar la escala, se necesitan más robots y operadores, además de costos elevados de espacio y desgaste de equipos, lo que rápidamente incrementa el precio.
Varios profesionales del sector indican que el precio aproximado es de solo unas decenas de yuanes por hora para Ego Data simple, mientras que los datos reales del robot que involucran teleoperación suelen costar cientos o incluso miles de yuanes por hora.
En el entrenamiento de modelos robóticos de diferentes fabricantes, cada nivel de la pirámide de datos desempeña un papel distinto, lo que ha dado lugar a empresas de datos ascendentes con distintos enfoques, como simulación o datos en primera persona humana.
¿Quién comercia con estos datos?
Cuando surge una industria a gran escala, los primeros en obtener ganancias suelen ser los "vendedores de agua" ascendentes.
Lo mismo ocurre en la inteligencia corporeizada. En el último año o dos, han surgido muchas startups robóticas en todo el mundo, atrayendo talento de diversos sectores.
Casi a diario, nuevas empresas anuncian rondas de financiación. En China, cada vez hay más empresas valoradas en miles de millones, algunas incluso camino a una OPV. En el extranjero, Figure, tras su ronda Serie C el año pasado, alcanzó una valoración de 39,000 millones de dólares, liderando las empresas de robots humanoides.
Todos quieren hacer robots humanoides universales y necesitan datos masivos. Además, con la continua afluencia de capital, el sector aún no carece de fondos.
Por ello, detrás de estas empresas con fuerte demanda de datos y fondos de I+D suficientes, hay cada vez más "vendedores de agua" ascendentes en la industria robótica, formando gradualmente una cadena de producción de datos.
Y a medida que avanza la industria, estas empresas ascendentes centradas en los datos para entrenar robots también muestran una clara estratificación. Según la estructura actual del sector,大致 se pueden clasificar en cinco tipos de actores.
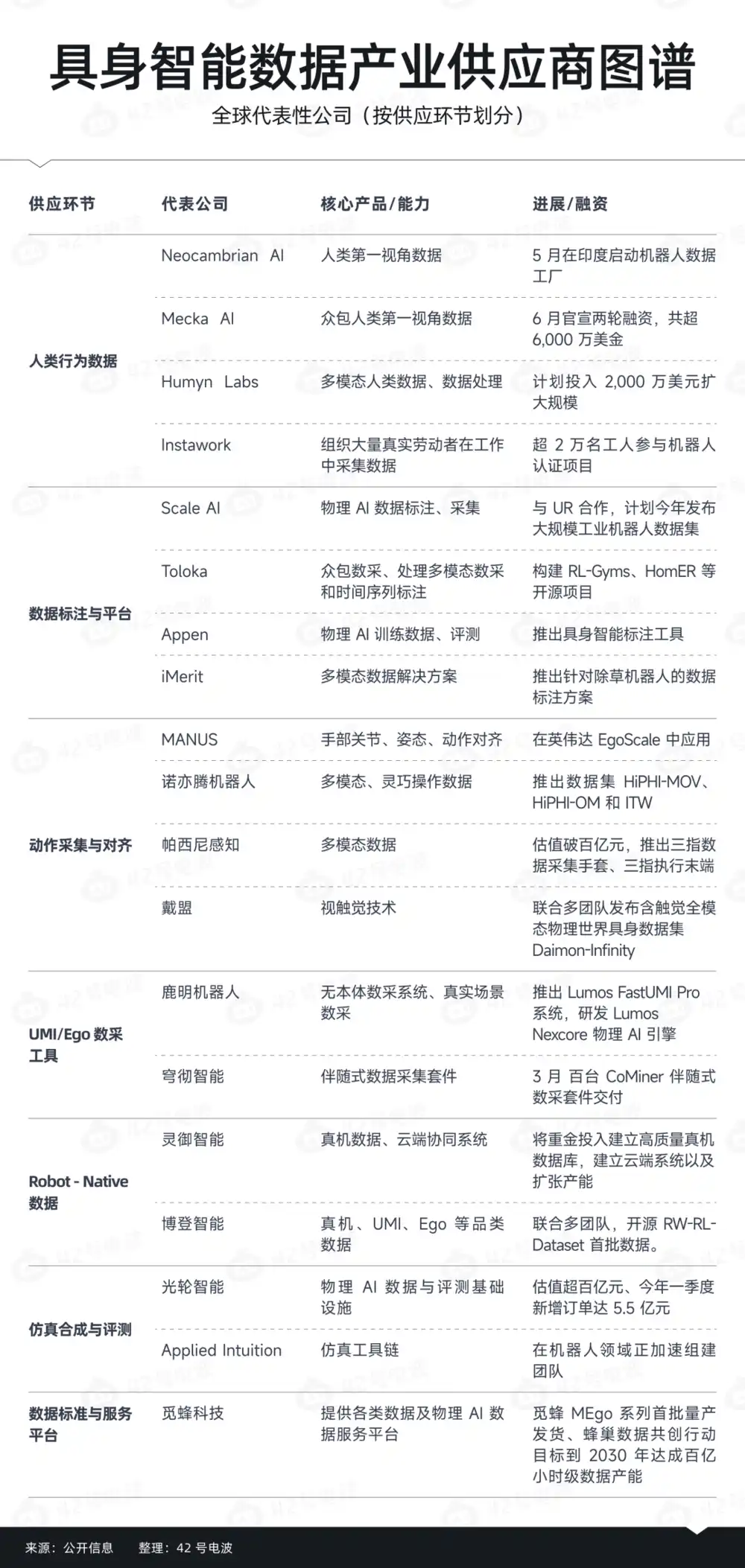
El primer tipo son las fábricas de datos de bajo costo, enfocadas en Ego Data. En India, Tailandia y otros lugares, cada vez más equipos organizan mano de obra barata y construyen redes de recolección.
Por ejemplo, recientemente la startup Neocambrian AI inició en India un proyecto de fábrica de datos robóticos para recopilar datos de movimiento humano, especialmente Ego Data. Su fundador destacó que India, con su vasta fuerza laboral, es una gran ventaja para desarrollar conjuntos de datos de IA física.
Los recolectores usan dispositivos de cámara en la cabeza y guantes de captura de movimiento, completan tareas según procedimientos, y luego equipos de backend limpian, anotan y validan los datos para entregarlos a empresas robóticas.
En cuanto a modelo de negocio, se parecen a las empresas de anotación de datos que servían a los grandes modelos antes, solo que antes anotaban texto, imágenes y voz, y ahora producen experiencia del mundo físico.
Un profesional del sector nos dijo que en el último año ha notado un aumento claro en la demanda de clientes extranjeros, especialmente empresas robóticas occidentales: «Ellos tienen especificaciones más claras, saben lo que quieren».
Porque los datos robóticos no son simplemente "grabar vídeo". Muchos clientes realmente necesitan un conjunto de datos que pueda integrarse directamente en la tubería de entrenamiento: series temporales, imágenes multiespaciales, trayectorias de movimiento, estado de sensores, postura de manos, metadatos del entorno y formato de entrenamiento adaptado.
En este proceso, cada vez más empresas descubren que depender solo de mano de obra barata difícilmente forma una barrera a largo plazo. Para estas fábricas de datos de bajo costo, la mayor barrera competitiva futura será si los datos entregados pueden usarse más fácilmente de forma directa.
Y el problema es real: este negocio es naturalmente susceptible a la comoditización. Si un equipo puede hacerlo, otro teóricamente también puede. Al transparentarse los precios, el margen de beneficio suele comprimirse.
Por tanto, la capacidad de entrega a bajo costo es su mayor ventaja, pero también puede convertirse en su techo.
El segundo tipo es la capa de captura y alineación de movimientos. Más que solo recoger vídeo, estos actores intentan resolver el problema de «cómo entiende realmente la máquina las acciones». Su enfoque no es solo el volumen de datos, sino la expresión del movimiento.
Por ejemplo, guantes de datos, captura de movimiento, seguimiento de manos, redireccionamiento de acciones, interfaces de recolección de operaciones.
Porque la parte realmente difícil para los robots muchas veces no es si entienden, sino cómo moverse. Agarrar una taza varía según los grados de libertad de la mano diestra, la estructura de los dedos o la capacidad de control de fuerza de cada robot.
Esto genera un problema clave: ¿cómo se mapean de forma estable las acciones humanas a distintos cuerpos robóticos?
Por eso, cada vez más empresas se centran más en el redireccionamiento de acciones. En este proceso, el vídeo le dice al robot qué hizo el humano; la capa de acciones responde aún más cómo debe actuar el robot mismo.
El verdadero valor de esta capa a menudo no es el hardware en sí, sino la capacidad de completar establemente la «traducción de acciones».
El tercer tipo es la capa de datos nativos para robots (Robot-Native), generalmente proveedores de servicios de teleoperación y datos reales de terceros. Su característica central es estar más cerca del robot físico, y a menudo requieren una vinculación profunda con la empresa robótica.
Porque, comparado con otras subdivisiones de recolección, los datos reales dependen en gran medida de robots concretos. El hardware varía entre empresas: grados de libertad, espacio de acciones, interfaces de control son muy diferentes. La misma tarea de agarre puede requerir recolección desde cero con otro robot.
En el proceso, ofrecen capacidades de teleoperadores, espacios y recolección real, ayudando a las empresas robóticas a acumular rápidamente datos de entrenamiento, especialmente en la fase de validación temprana del modelo, cuando la empresa aún no tiene equipo o espacio suficientes; los proveedores externos pueden comenzar más rápido.
El cuarto tipo son las empresas de datos sintéticos de simulación. No solo venden datos, sino que intentan construir una capacidad de datos más completa.
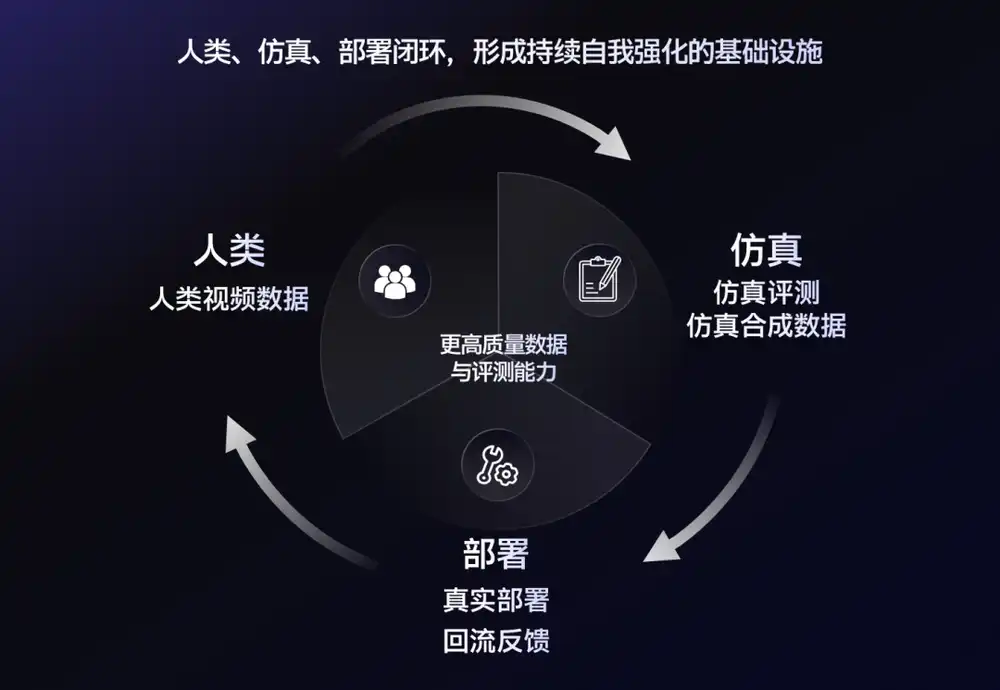
Al producir datos, también ayudan a los clientes a responder por qué falla el robot en una tarea y cómo recolectar el siguiente lote de datos. Esta es la nueva ruta que siguen hoy muchas empresas.
La lógica es simple: un día de entrenamiento robótico real puede acumular solo unas horas de trayectorias efectivas. Pero en un mundo simulado, en el mismo tiempo el robot puede fallar millones de veces: agarres fallidos, errores de planificación de ruta, colisiones, caídas, todo puede repetirse infinitamente.
Así, la industria comienza a formar una nueva combinación: los datos reales anclan la realidad; los datos sintéticos de simulación se encargan de la expansión de escala.
NVIDIA también ha destacado repetidamente en su ruta GR00T que los modelos fundacionales robóticos no solo necesitan datos de demostración humana, sino también muchos datos sintéticos. Los desarrolladores pueden obtener conocimiento previo mediante recolección en el mundo real y luego expandir la escala de tareas con simulación.
Cuantas más veces falle el modelo en simulación, más sabrá qué datos le faltan, y quien pueda producir estos datos más rápido tendrá más ventaja.
El quinto tipo de actor se inclina más hacia la capa de estándares y plataformas de datos. Al expandir la escala de datos, exploran cómo hacer que el suministro de datos sea más estándar y fluido.
Porque hay cada vez más empresas robóticas, y los datos están altamente fragmentados: métodos de recolección, expresión de acciones, formatos estándar son diferentes. Muchas veces, incluso el mismo conjunto de datos difícilmente puede reutilizarse directamente.
En este contexto, este año han aumentado notablemente los intentos de estandarización y recolección colaborativa de datos corporeizados.
Para la industria robótica actual, la falta de datos es solo uno de los problemas. Que los datos puedan generarse de forma continua y estable y entrar más fácilmente en el flujo de entrenamiento también es crucial.
Pero, ya sean actores de datos humanos, reales o de simulación, todos deben responder a esta pregunta: ¿las empresas robóticas externalizarán estas capacidades centrales a proveedores externos?
Después de todo, para la mayoría de las empresas corporeizadas actuales, los datos no son solo un costo, sino también una barrera.
¿Deben las empresas robóticas comprar datos o recolectarlos ellas mismas?
Este año, los datos tienen un peso decisivo en la industria robótica. Todos saben que a los robots les faltan datos.
En comparación con antes, hoy hay cada vez más opciones de suministro de datos en el mercado, con proveedores para distintos tipos de datos. Para las empresas robóticas, comprar datos es cada vez más fácil.
Pero la realidad es algo diferente: por un lado, cada vez más empresas robóticas compran datos; por otro, las empresas líderes se esfuerzan por construir sus propios equipos de datos.
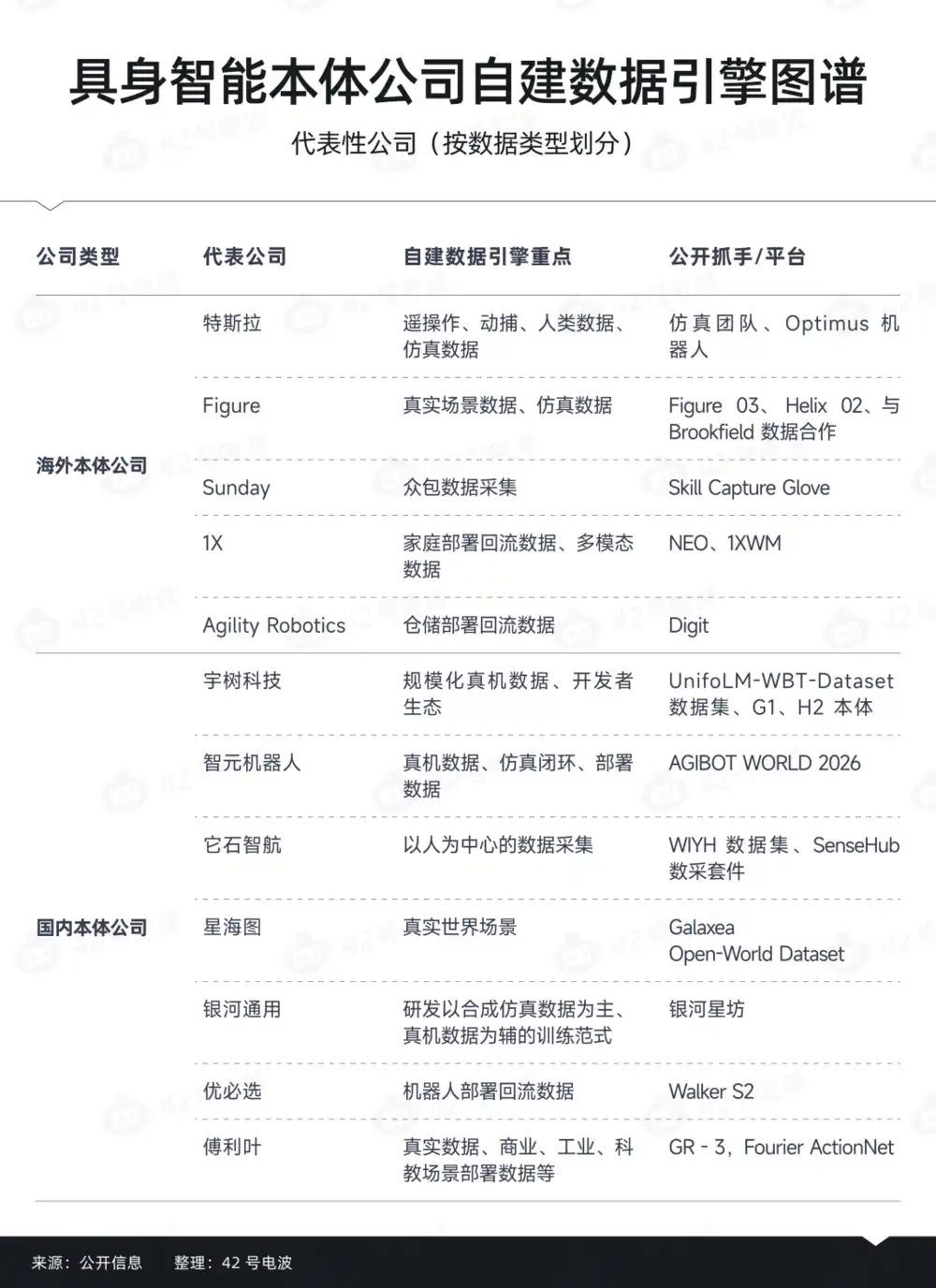
Desglosándolo, se ve que distintos datos determinan formas organizativas completamente diferentes.
En cierto modo, las empresas robóticas forman realmente una lógica de «compra por capas».
La primera capa son los datos genéricos básicos, la más fácil de externalizar.
Por ejemplo, organizar la cocina, ordenar el escritorio, agarres básicos, clasificación, transporte. Estos datos tienen una característica común: sin importar cómo sea el robot, al final necesita entender cómo completan los humanos las tareas.
Cuando un robot entra en una cocina, ¿cuándo libera una mano primero? ¿Cuándo organiza objetos grandes antes que pequeños? Si hay muchos objetos, ¿cómo replanifica el espacio?
Estas capacidades pertenecen esencialmente a la cognición genérica del mundo físico, no son exclusivas de un robot en particular.
Recolectar este tipo de datos Ego desde cero requeriría formar un equipo, con altos costos de gestión.
En comparación, equipos externos pueden expandir rápidamente la escala de recolección en el Sudeste Asiático o India, produciendo miles de horas mensuales de forma estable.
Para las empresas robóticas, muchas veces comprar primero es más rentable que construir su propio equipo. En esta etapa, el objetivo no es que el robot trabaje de forma estable, sino que primero comprenda el mundo.
Por tanto, externalizar este tipo de datos es razonable, incluso una opción más eficiente.
La segunda capa son los datos de adaptación corporeizada, que las empresas robóticas tienden a recolectar internamente.
Después del preentrenamiento con muchos datos básicos, el entrenamiento comienza a involucrar el núcleo del despliegue real del robot: la alineación de tareas.
Aquí la lógica cambia, porque el cuerpo físico de cada robot varía mucho: grados de libertad, manos diestras, capacidades articulares son diferentes. La lógica de acción que el robot finalmente necesita aprender también será muy distinta.
Cuanto más cerca de la capa de ejecución de acciones, menos genéricos son los datos. Por eso, aunque muchas empresas compran mucho Ego Data, aún construyen equipos internos para recoger datos reales. Porque esta capa ya se acerca a la verdadera competitividad del modelo.
La tercera capa son los datos de despliegue y de fallos, una capa crucial que suele generarse después del despliegue real.
Cuando el robot se despliega en escenarios reales, encuentra toda clase de situaciones imprevistas en su entorno laboral. Estos datos de despliegue, ya sean de éxito o fracaso, son extremadamente valiosos. Rara vez se encuentran en la recolección previa, son difíciles de diseñar por adelantado y solo pueden acumularse poco a poco en entornos reales.
Además, muchas empresas no pueden desplegar masivamente sus robots en escenarios reales, por lo que los datos de despliegue real son inexistentes.
Durante el despliegue, el robot acumula experiencia en entornos cambiantes. Incluso los datos de fallo ayudan al equipo a encontrar causas específicas y tomar contramedidas para optimizar el modelo, promoviendo así el despliegue a escala del robot.
Estos son los datos centrales de las empresas robóticas líderes y su barrera distintiva frente a la competencia.
Esto limita en cierta medida el techo de las empresas de datos. Pueden ayudar a los robots a "empezar", pero los datos que realmente deciden el límite superior de capacidad, muchas empresas líderes finalmente optan por controlarlos ellas mismas.
Así, se vislumbran dos rutas distintas en la industria de datos: una es la fábrica de datos; la otra, el motor de datos.
Las fábricas de datos son el tipo de empresa que aparece más rápido, en mayor número y con más facilidad para generar flujo de caja en la industria actual.
Entre ellas, las fábricas de datos de bajo costo se centran más en datos de comportamiento humano, aprovechan ventajas laborales de bajo costo, cobran por hora, buscan escala y capacidad de entrega. Su flujo de caja puede volverse positivo rápidamente, pero tienen barreras limitadas, y los competidores están aumentando rápidamente, especialmente tras EgoScale, con muchas startups entrando en datos humanos.
Las fábricas de datos de mayor complejidad, además de cubrir datos de comportamiento humano, despliegan robots en masa y recolectan muchos datos reales mediante teleoperación o funcionamiento autónomo.
La otra ruta intenta ser un motor de datos: organizar sistemas de clasificación de tareas, construir estructuras de datos, implementar redireccionamiento de acciones, conectar plataformas de simulación, implementar evaluación de modelos y, basándose en muestras de fallo del modelo, producir iterativamente conjuntos de datos.
En otras palabras, no solo venden datos, sino que se centran en dotar al robot de la capacidad de volverse continuamente más inteligente.
¿Aparecerá un Scale AI para robots?
Situando la industria robótica actual en el contexto de los grandes modelos de 2022, se percibe una sensación de similitud.
Entonces, la industria también descubrió que lo que realmente determina el límite superior de capacidad de los modelos son los datos.
Así, surgieron rápidamente nuevas empresas en áreas como limpieza de datos, RLHF, evaluación y post-entrenamiento. El caso clásico es Scale AI.
Esta empresa, en sus inicios, ayudaba a empresas de conducción autónoma a anotar datos. Desde 2019, Scale AI se vinculó profundamente con OpenAI en la etapa de GPT-2, asumiendo anotación de retroalimentación humana (RLHF), evaluación de grandes modelos, pruebas de equipo rojo, creación inversa de datos de casos límite.
Tras el éxito de ChatGPT, Meta Llama, Anthropic y Microsoft Azure se integraron rápidamente. La explosiva demanda de anotación de alta calidad, evaluación y datos sintéticos para grandes modelos hizo que los ingresos de esta empresa se cuadruplicaran en tres años.
Luego, esta empresa comenzó a adentrarse en capas de infraestructura más profundas: gestión de datos, evaluación de modelos, flujos de trabajo de IA.
Debido al ejemplo de éxito de Scale AI, muchos se preguntan: ¿aparecerá una empresa similar en la industria robótica?
Según el nivel actual de escasez de datos, es muy probable, pero no será una réplica exacta.
Porque los datos que necesitan los robots son mucho más complejos que el texto. Para un gran modelo, es relativamente fácil juzgar si una respuesta es correcta o incorrecta. Pero en el mundo de los robots, el éxito de una acción suele estar lleno de ambigüedad.
La taza se levantó, pero en un ángulo incorrecto. El objeto se guardó, pero se derribaron otros. Además, muchas veces completar la tarea en sí tiene múltiples rutas correctas.
Por eso, lo que la industria robótica realmente necesita no es una simple plataforma de datos, sino un ciclo cerrado completo de recolección, anotación, mapeo de acciones, expansión por simulación, evaluación de modelos y retroalimentación de fallos.
A los robots realmente no solo les faltan datos; es más escasa la capacidad de producir experiencia efectiva de forma continua.
Por eso, cada vez más empresas desplazan el foco de competencia desde el cuerpo del robot y la arquitectura del modelo hacia el sistema de datos.
Este año, ya sea Figure, 1X, PI o la ruta GR00T promovida por NVIDIA, todos reiteran una dirección común: el crecimiento de las capacidades robóticas depende en parte de la mejora del hardware, pero más datos y un entrenamiento más efectivo se están convirtiendo en protagonistas.
En cierto modo, al iniciarse la fase de producción en masa y despliegue en la industria robótica, se está pasando del período de "construir máquinas" al de "alimentar máquinas".
Cuando el robot aún no podía levantarse o caminar, la mayor competitividad de una empresa corporeizada era su capacidad para hacer bien el hardware y el control de movimiento.
Pero cuando el robot puede correr y saltar, y sus resultados en muchas competiciones superan a los humanos, la capacidad de trabajo autónomo se convierte en el mayor objetivo de la industria. Impulsados por este objetivo, la melodía principal de la industria se convierte en datos masivos de alta calidad.
Para que un robot tenga éxito continuamente en el complejo mundo real, necesita haber visto suficientes tareas que realmente existen en el espacio físico, saber que una taza puede volcarse, la ropa puede enredarse, el espacio puede ser insuficiente. Esta experiencia no existe naturalmente en Internet; solo puede producirse poco a poco.
Por eso, esta cadena de suministro de datos también se ha formado silenciosamente detrás del auge robótico de los últimos dos años.
En un extremo de la cadena están los humanos con cámaras en fábricas de India, y los robots que caen continuamente en simulación.
En el otro extremo, están empresas robóticas valoradas en decenas de miles de millones, cientos de miles de millones, incluso billones, que intentan que los robots entren realmente en hogares y fábricas.
Desde las fábricas de datos en India y los robots en simulación, hasta las grandes empresas robóticas globales, ha comenzado a formarse una nueva cadena de producción. Solo que esta vez, lo que se produce no son componentes, sino datos.
Este artículo proviene del WeChat Official Account: 42º Onda Radio , autor: Lanbo, editor: James, título original: «Los robots comienzan a 'devorar datos': La cadena de producción oculta desde las fábricas de datos en India hasta los robots humanoides de miles de millones de dólares»