Autor: Matt White, Director de Tecnología Global de IA de Linux Foundation
Compilado por: Felix, PANews

Wang Xingxing (CEO de Unitree) con Matt White
Hace unas semanas, en Shanghai, un amigo con el que viajaba (inteligente, que suele estar al día de las noticias y observa las cosas, pero no conoce mucho la robótica) hizo durante la cena la pregunta que llevaba esperando todo el viaje.
"Esos perros robóticos que vemos por todas partes, los robots humanoides que hacen artes marciales en el escenario de demostración de la oficina de Unitree, los brazos robóticos que vimos doblando ropa. ¿Cómo lo hacen? ¿Son impulsados por grandes modelos de lenguaje (LLM)? ¿Cómo funciona esto exactamente? ¿Hay algún modelo de lenguaje controlando sus movimientos?"
Es una buena pregunta y, para ser sincero: en cierto modo sí, pero la historia real es mucho más interesante. Los robots que ves en las redes sociales no son un ChatGPT con una armadura metálica. Ejecutan una pila tecnológica (múltiples capas de IA trabajando en conjunto). Esta pila ha cambiado más en los últimos tres años que en los treinta anteriores. Los modelos de lenguaje son parte de ella. También lo son los modelos visuales, los modelos de movimiento, los árboles de comportamiento, los bucles de control clásicos y una familia emergente de sistemas llamados "modelos del mundo". Y estos últimos son quizás los más importantes de todos.
Este es un artículo largo. Comenzaremos desde el principio, luego pasaremos por cada cambio importante, y finalmente llegaremos a donde estamos ahora: robots que no solo reaccionan al mundo, sino que también pueden imaginarlo.
I: La Era Pre-LLM: Cuando los robots eran solo software
Durante décadas, construir un robot significó escribir mucho código, y casi todo ese código no requería aprendizaje.
Los robots industriales clásicos eran torres de módulos cuidadosamente diseñados. Piensa en esos brazos robóticos naranjas de los años 90 que soldaban los chasis de Toyota, o el BigDog de Boston Dynamics a principios de los 2000.
- Percepción: Filtrar las imágenes de la cámara, detectar bordes, usar coincidencia geométrica para identificar la posición de una pieza.
- Estimación del estado: Combinar codificadores de ruedas, giroscopios y acelerómetros (fusión de sensores) para determinar la posición y velocidad del robot.
- Planificación: Dada una pose objetivo, usar algoritmos como A* o RRT para calcular una ruta libre de colisiones en un mapa conocido.
- Control: En el nivel más bajo, los controladores PID ajustan el par del motor cientos o miles de veces por segundo para seguir esa ruta.
Estas capas solían ser escritas por diferentes personas en diferentes laboratorios y unidas con un cuidado exquisito. Los comportamientos (por ejemplo, "si la taza es roja, agárrala; de lo contrario, espera") se codificaban como máquinas de estados o árboles de comportamiento: diagramas de flujo que el robot seguía paso a paso.
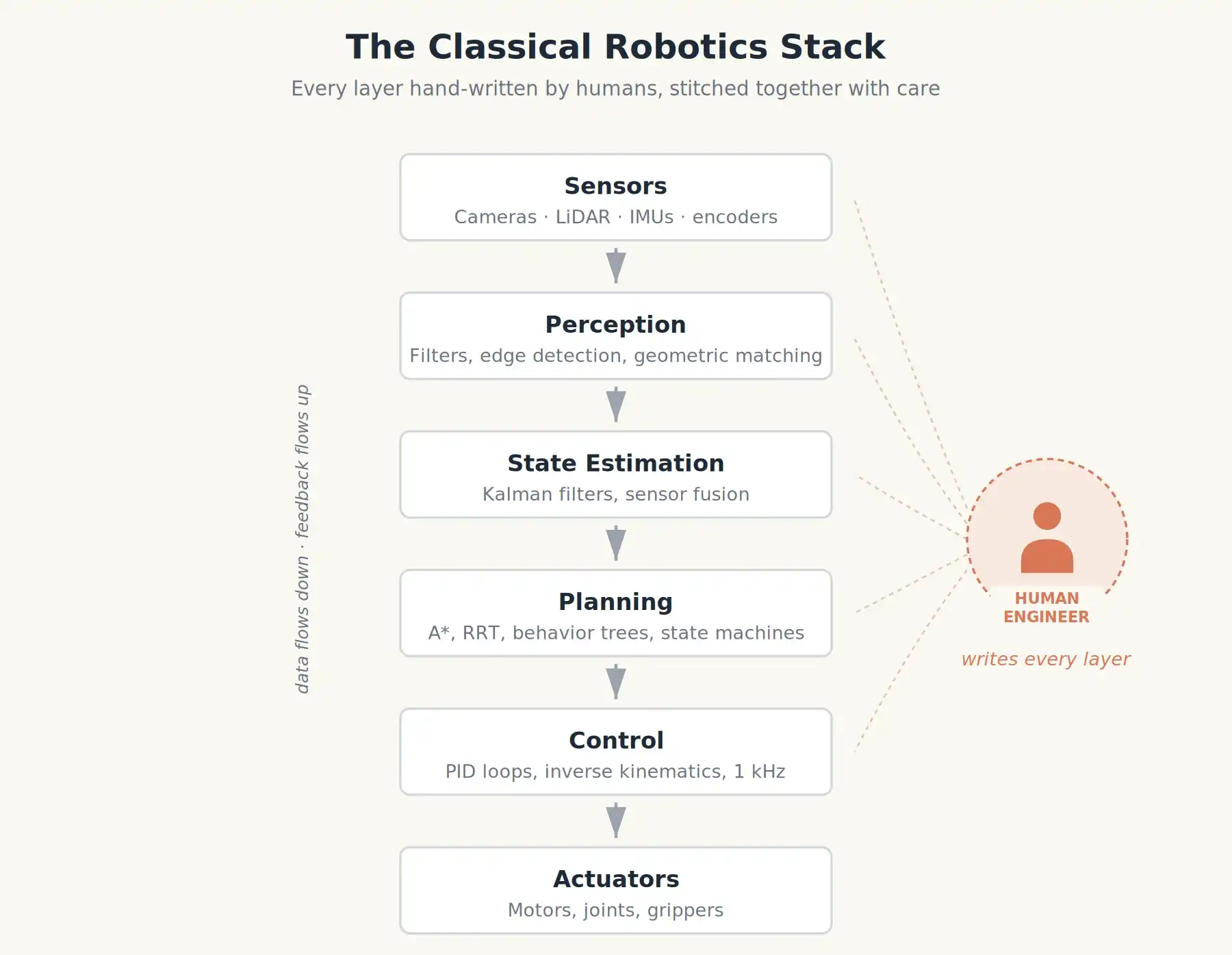
Las ventajas de este enfoque son obvias. Es predecible, cumple con los estándares de seguridad. Por eso tu coche tiene un ABS eficaz.
Las desventajas también son obvias. Un robot así solo es tan inteligente como el escenario que el ingeniero previó. Ponlo en una fábrica nueva, con una iluminación diferente o una taza de otro color, y se vendrá abajo. Su capacidad de generalización es casi nula.
II: El aprendizaje automático se infiltra sigilosamente
En la década de 2010, el aprendizaje profundo comenzó a abordar la capa de percepción. Las redes neuronales convolucionales (CNN) que superaron a los humanos en tareas de clasificación de imágenes de ImageNet podían reentrenarse para detectar puntos de agarre en objetos, segmentar muebles en una habitación o reconocer posturas humanas. De repente, la capa superior de "percepción" en la pila no necesitaba ser diseñada a mano; podías entrenarla.
Luego, el aprendizaje se extendió a la capa de "control". Investigadores de Berkeley, DeepMind y OpenAI demostraron que el aprendizaje por refuerzo (hacer que un agente robótico intente millones de veces en un simulador y refuerce lo que funciona) podía producir zancadas sorprendentemente hábiles, manipulación de objetos con la mano (el cubo de Rubik de OpenAI en 2019 fue un hito), y estrategias de locomoción que se adaptaban a diferentes terrenos.
Una línea de investigación paralela fue el aprendizaje por imitación, a menudo llamado clonación de comportamiento: grabar cientos de intentos de un humano controlando remotamente un robot para una tarea, luego entrenar una red neuronal para predecir qué acción tomaría el humano basándose en lo que el robot observa.
La clave de todo esto: cada política aprendida era demasiado estrecha. Entrena una red para recoger un bloque rojo, y no sabrá qué hacer con una taza amarilla. Entrénala para caminar en hierba, y se caerá en un piso de baldosas. La generalización seguía siendo el santo grial.
Es importante mencionar que en esta época emergió una pieza de infraestructura que aún sostiene casi todo: ROS, el Sistema Operativo para Robots (lanzado por primera vez en noviembre de 2007). ROS no es un sistema operativo en el sentido de Windows o Linux, sino un marco de middleware, una tubería genérica para robots. Permite que "nodos de cámara", "nodos de navegación", "nodos de control de brazo" y otros docenas de nodos publiquen y se suscriban a mensajes a través de un bus compartido.
La versión actual, ROS2, se ejecuta en el fondo de la gran mayoría de robots de investigación y comerciales en el mundo, desde laboratorios en Stanford hasta startups chinas de humanoides. Cuando la gente habla del "sistema operativo" de un robot, casi siempre se refiere a ROS2 más los paquetes de software de percepción, planificación y control que se ejecutan encima.
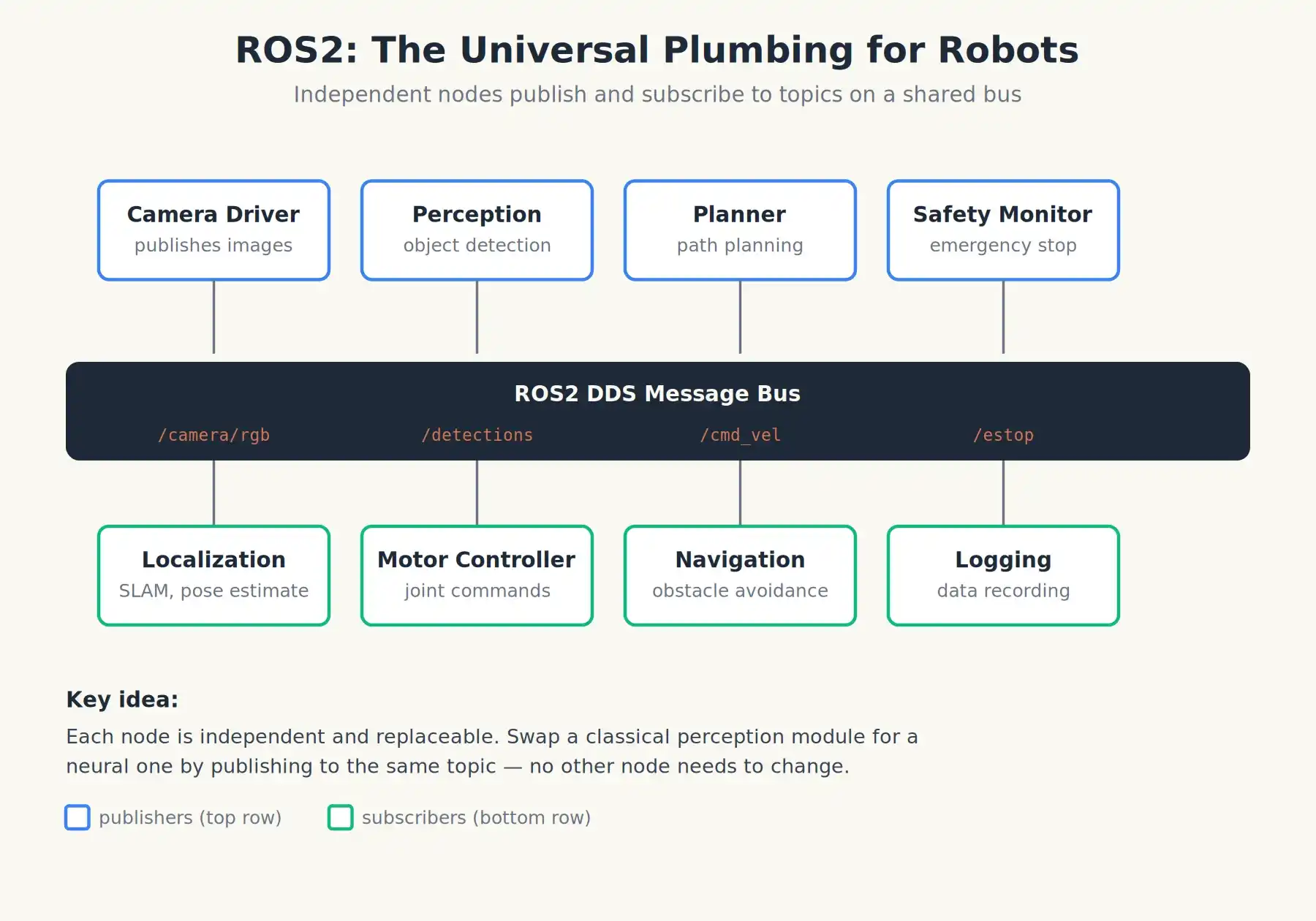
ROS2: No es un sistema operativo, es la tubería común que hace que el software robótico independiente se comunique.
III: LLMs Llegan a la Robótica
Y luego llegó ChatGPT.
De repente, existía esto: un LLM. Podía leer instrucciones simples en inglés, razonar en múltiples pasos, escribir código y llamar funciones. Los roboticistas se dieron cuenta casi de inmediato: esto era la pieza faltante que habían estado intentando resolver durante años. La parte más difícil de hacer que un robot hiciera algo útil en una casa u oficina, a menudo no era el control del motor, sino la interfaz: ¿cómo le dice la persona al robot qué hacer, y cómo descompone el robot ese objetivo en acciones atómicas que ya sabe ejecutar?
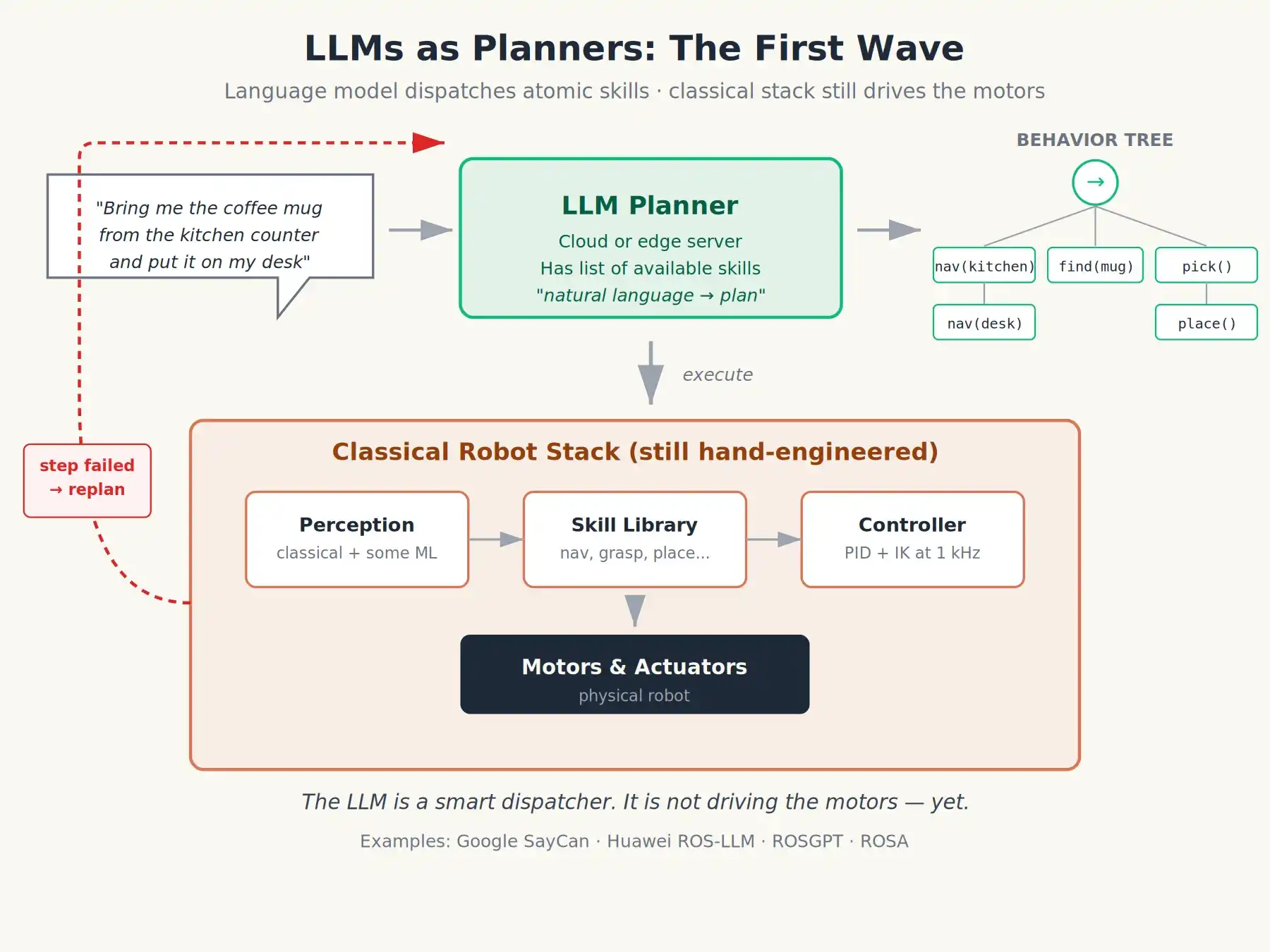
La primera ola de trabajo aplicando LLMs a robots los trataba como un compilador de lenguaje natural sobre ROS. El patrón era:
-
El usuario dice en inglés: "Trae la taza de café de la encimera a mi mesa."
-
El LLM genera un plan basado en una lista de habilidades atómicas disponibles para el robot: puede ser una secuencia de llamadas a funciones, una máquina de estados, o un árbol de comportamiento escrito en XML.
-
Los nodos ROS2 ejecutan el plan paso a paso. Si un paso falla, se le informa al LLM para que replanifique.
SayCan de Google en 2022 fue una versión muy limpia de esta idea: el LLM propone habilidades, un modelo de "afordamiento" separado evalúa la probabilidad de éxito actual de cada habilidad, el robot elige la combinación con la puntuación conjunta más alta. Marcos abiertos como ROS-LLM, ROSGPT y ROSA (impulsados principalmente por Huawei Research Labs) popularizaron este patrón.
Fue un salto significativo. De repente, podías decirle a un robot "limpia la mesa, pon los reciclables en el cubo azul" e intentaría algo razonable. Pero nota: todavía había un problema aquí. El modelo de lenguaje estaba todavía en la capa de planificación. Las órdenes de movimiento reales aún las generaban controladores cuidadosamente diseñados o entrenados específicamente. El modelo de lenguaje era solo un programador inteligente. No conducía.
IV: Modelos Visual-Lenguaje-Acción (VLA), Cuando el Cerebro Conduce

El robot Keenon XMAN-R1 tomando medicamentos de un estante en una farmacia automatizada de Galbot en Beijing. Por solo 100,000 dólares.
El siguiente salto fue más difícil y más importante. Los investigadores plantearon una pregunta más ambiciosa: ¿y si el modelo no solo pudiera planificar, sino generar directamente las acciones? ¿Qué tal si alimentas directamente una imagen de la cámara y una instrucción en lenguaje natural en una red neuronal, y obtienes el movimiento articular para el próximo milisegundo?
Eso es un Modelo Visual-Lenguaje-Acción (VLA). Ahora es el paradigma dominante en humanoides y cuadrúpedos.
El primer VLA ampliamente conocido fue RT-2 de Google DeepMind en 2023. La elegancia fue esta: toma un gran modelo de lenguaje visual (entrenado para describir imágenes y responder preguntas) y continúa entrenándolo con datos de demostración de robots, pero tratando las acciones del robot como otro tipo de token a predecir. La misma red neuronal que podría generar "un gato sentado en una alfombra" ahora podría generar una secuencia de tokens que codifican "mueve la pata derecha 3 cm hacia adelante, cierra la garra, levanta 5 cm". El razonamiento y la acción ocurren en el mismo modelo.
Luego, a mediados de 2024, un equipo liderado por Stanford lanzó OpenVLA, un modelo VLA de código abierto de 7 mil millones de parámetros, entrenado en el conjunto de datos Open X-Embodiment, que reúne más de un millón de episodios de entrenamiento de 21 laboratorios diferentes en 22 cuerpos robóticos distintos. Fue la primera vez que alguien fuera de Google podía descargar un modelo genérico de robot y comenzar a modificarlo. Cambió el campo de la noche a la mañana.
Hoy, los VLA líderes son pocos pero crecen rápidamente:
- π0 y π0.5 de Physical Intelligence: Excelente adaptación de tareas.
- NVIDIA Isaac GR00T N1.7: Pesos abiertos, licencia comercial, diseñado para humanoides, el modelo en el que la mayoría de las empresas de hardware chinas están haciendo fine-tuning con sus propios datos actualmente.
- Helix de Figure AI y el más reciente Helix-02: Propietario, pero arquitectónicamente importante.
- Genie Envisioner de AgiBot: Plataforma basada en modelo del mundo chino.
- SmolVLA, NORA, ACoT-VLA, CogACT: Una explosión de VLA académicos explorando diferentes direcciones de diseño.
Cómo funciona un VLA (sin matemáticas)
Piensa en un VLA como fusionar tres flujos de entrada en un flujo de salida.
Primer flujo: Visión. Una cámara RGB (a veces un sensor de profundidad o LiDAR), a veces sensores táctiles en las yemas de los dedos, procesados por un codificador visual (normalmente un modelo Transformer como DINOv2 o SigLIP) que comprime cada imagen en unos cientos de "tokens visuales", resumiendo lo que el robot ve.
Segundo flujo: Lenguaje. Tu instrucción ("pásame el destornillador") se tokeniza como en ChatGPT.
Estos dos flujos se concatenan y alimentan un "tronco" Transformer (normalmente un modelo de lenguaje pequeño y de código abierto como Qwen3 o Llama). Este tronco hace el razonamiento, combinando lo que ve con lo que se le pregunta.
Tercer flujo: Acción, sale por el otro lado. Aquí es donde divergen los diseños arquitectónicos:
- Tokens de acción discretos: El modelo genera tokens que se decodifican directamente en ángulos articulares o posiciones del efector final, como ChatGPT genera palabras. Sencillo, pero puede ser espasmódico a alta frecuencia.
- Cabezales de acción por difusión o emparejamiento de flujos (flow-matching): Una mini-red separada toma la salida del tronco y la desruidifica en una trayectoria suave de posiciones articulares, como un modelo de difusión de imágenes, pero para movimiento. Así lo hace π0, produciendo movimientos más suaves y naturales.
- Fragmentación (chunking) de acciones: En lugar de predecir la siguiente instrucción única, predice el siguiente medio segundo de instrucciones a la vez, alisando los espasmos.
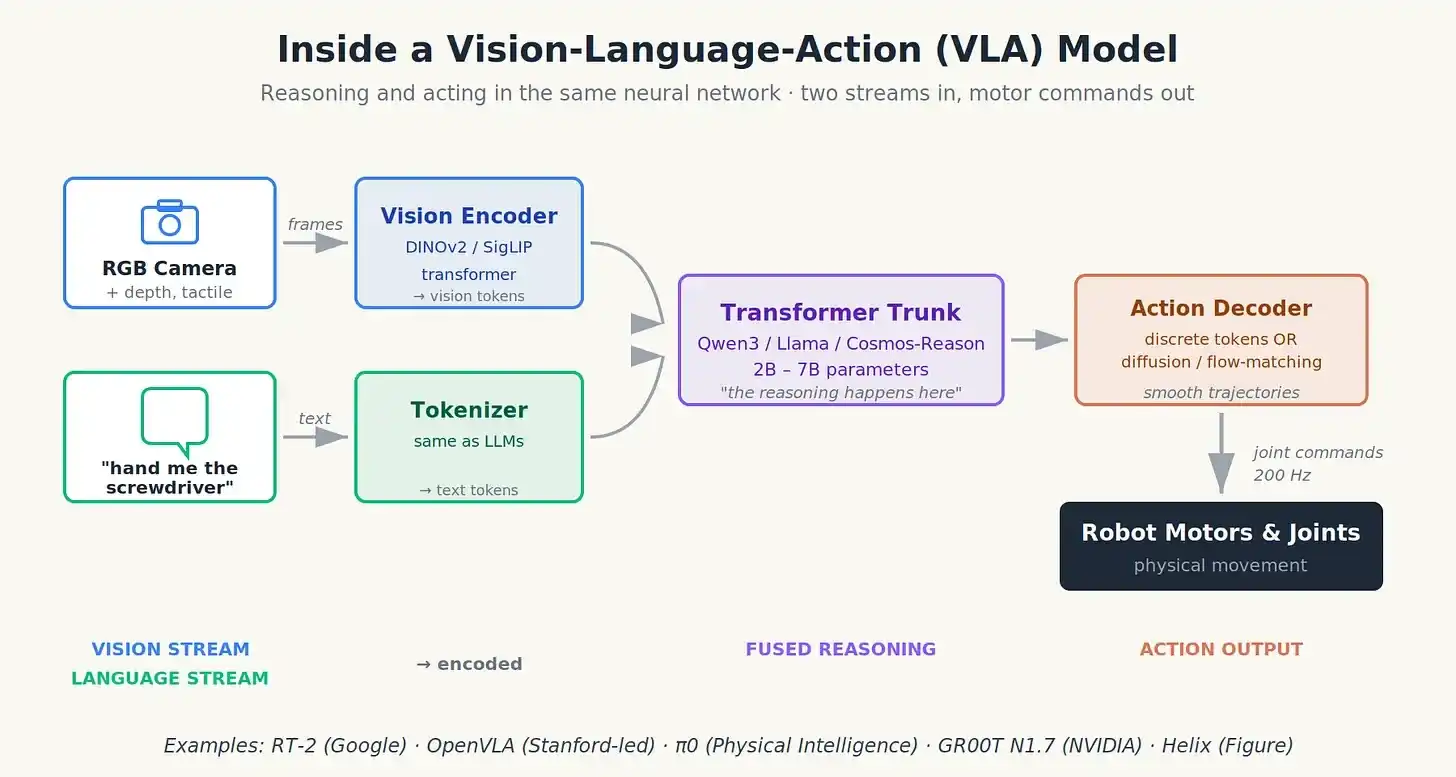
En un modelo VLA: Dos flujos de entrada, órdenes de movimiento de salida. Razonamiento y acción fusionados en una red.
Este es el cambio arquitectónico crucial: el razonamiento y la acción ya no están separados. Enseñarle a una red neuronal a reconocer una taza también le enseña cómo agarrarla. Es este acoplamiento lo que permite a los VLA generalizar donde sus predecesores no podían.
V: Estrategia de Dos Cerebros: Cómo Trabajan Juntos los LLM y los VLA
Hay un detalle que rara vez se explica claramente en el marketing. Los humanoides de mejor rendimiento hoy no ejecutan un sistema VLA único; ejecutan dos modelos a diferentes velocidades, comunicándose entre sí. A veces se llama arquitectura de dos sistemas o Sistema 1 / Sistema 2, tomado del marco psicológico de Daniel Kahneman que postula que los humanos tienen un cerebro rápido e intuitivo y uno lento y deliberativo.
Helix de Figure AI hizo clásico este diseño, y ahora se copia (y varía) en casi todas partes. Es especialmente importante que el GR00T N1.7 de NVIDIA adopte este diseño, al igual que la mayoría de los humanoides chinos. Se ve así:
- Sistema 2 (S2): El cerebro lento y pensante. Un modelo visual-lenguaje de ~7 mil millones de parámetros, que corre a unos 7-9 Hz (es decir, 7-9 veces por segundo). Su trabajo es observar la escena, analizar la instrucción, hacer razonamiento de múltiples pasos (p. ej., "el tazón está detrás de la caja de cereales; necesito mover la caja primero") y emitir intenciones de alto nivel, normalmente un conjunto de vectores internos compactos, no palabras en sí mismas.
- Sistema 1 (S1): El cerebro de reacción rápida. Una política visomotora mucho más pequeña (~80 millones de parámetros) que corre a 200 Hz. Toma el vector de intención de S2 más los datos de sensores más recientes y emite órdenes articulares continuas. No "piensa" en ningún sentido real, solo reacciona.
Recientemente, Helix-02 de Figure agregó un Sistema 0. Va por debajo del sistema de dos cerebros, es una capa refleja, no una tercera capa cognitiva. Es una red de 10 millones de parámetros que corre a 1 kHz, encargada del equilibrio de bajo nivel y la coordinación corporal, reemplazando más de 100,000 líneas de código C++ escrito a mano para control de movimiento. Puedes pensar en S0 como una médula espinal aprendida: no razona ni planifica, solo mantiene el cuerpo erguido y coordinado mientras los cerebros de arriba piensan.
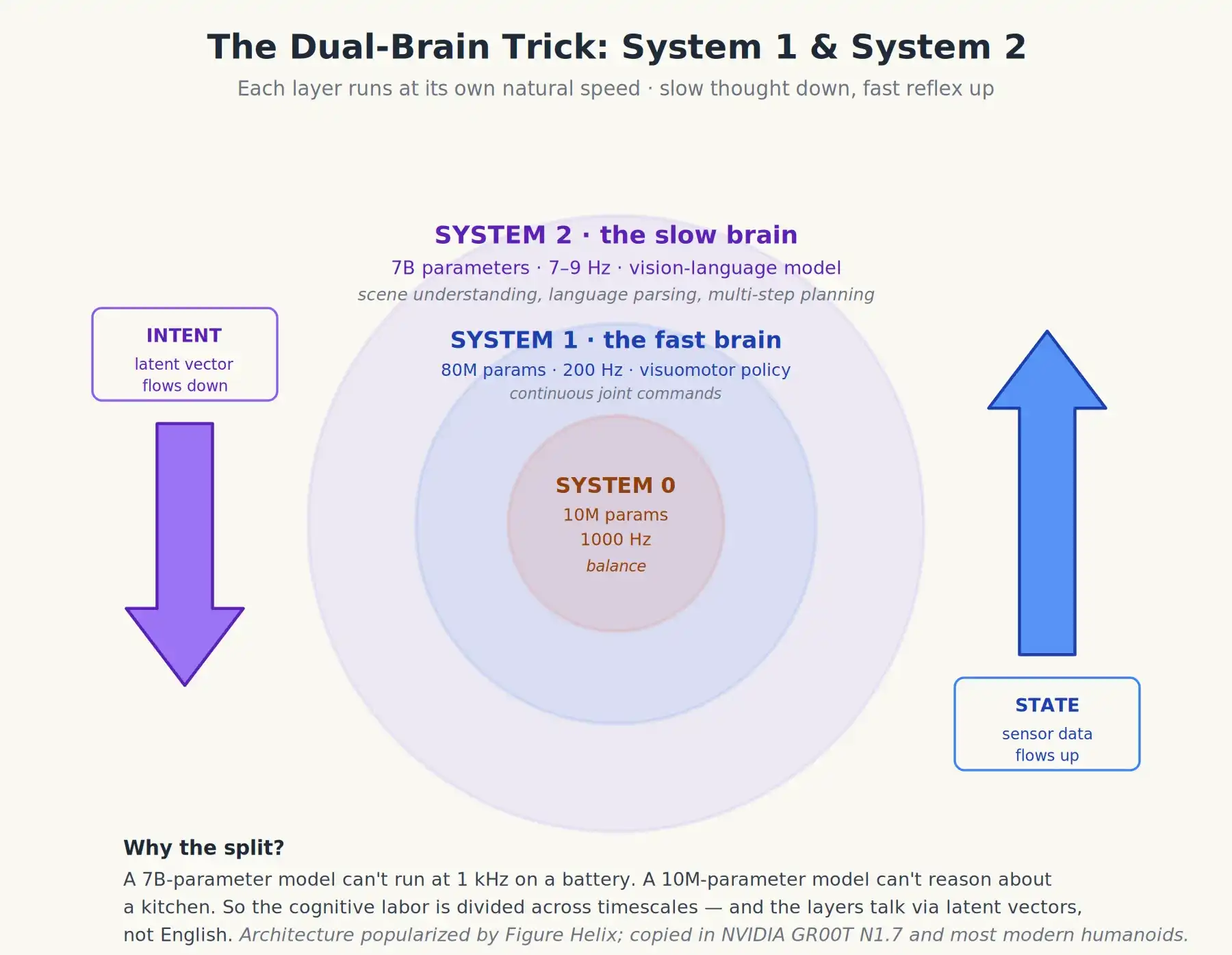
Arquitectura de doble cerebro de un humanoide moderno: El Sistema 2 piensa despacio, el Sistema 1 reacciona rápido – y debajo hay un Sistema 0 reflejo para equilibrio, contacto táctil y coordinación corporal total
Esta división surge de las limitaciones de la física. Si emites órdenes de movimiento solo cada 200 milisegundos (la velocidad a la que corre un VLA grande), el robot se movería como si estuviera bajo el agua. Las órdenes de movimiento deben actualizarse más rápido que la oscilación natural de las articulaciones que controlan, lo que significa cientos o miles de actualizaciones por segundo. Ningún modelo Transformer de 7B puede correr tan rápido en un robot con batería.
Así que la cognición se divide: el modelo grande y lento piensa; el modelo pequeño y rápido actúa. No se comunican en inglés, sino en vectores latentes aprendidos: el lento emite objetivos abstractos, y el rápido sabe cómo interpretarlos.
VI: Nube, Computación de Borde y Dónde Va el "Cerebro"
¿Dónde se realiza toda esta computación?
Hoy, existe un consenso fuerte, casi ideológico, entre los equipos de robótica de que los bucles de control críticos para la seguridad deben ejecutarse localmente. Dos razones:
Latencia. El tiempo de ida y vuelta por WiFi o celular, en el mejor de los casos, es de 30-80 ms. Las órdenes de acción necesitan actualizaciones cada 1-5 ms. Ese ciclo de red simplemente no funciona.
Fiabilidad. Los robots operan en fábricas, almacenes, cocinas, hospitales. La red puede caerse en cualquier momento. Si un robot se detiene cada vez que se cae el Wi-Fi, es un peligro.
Así que la división moderna es aproximadamente así:
A bordo (local), en un módulo como NVIDIA Jetson Thor o AGX Thor (~2,000 TFLOPS, 128 GB de RAM, 40–130 W de consumo):
- Todo S0/S1: Equilibrio, locomoción, control fino de movimientos.
- El VLA en sí (Sistema 2), cada vez más cuantizado a FP8 o FP4 para encajar. Los modelos de 2B a 7B ahora pueden ejecutarse en el dispositivo.
- Percepción, fusión de sensores, y cualquier monitoreo de seguridad que cubra todo lo demás.
Nube o servidor remoto (si existe):
- Interfaz conversacional ("Oye robot, ¿qué debo cocinar para cenar?"): Puede tolerar latencia.
- Aprendizaje de flota: Miles de robots envían datos de teleoperación al servidor para agregarlos a la siguiente versión del modelo.
- Planificación a largo plazo a gran escala que podría usar modelos de última generación.
- Paneles de control y monitoreo del operador.
También hay una capa intermedia creciente: servidores de borde local en la fábrica o almacén que se comunican con un clúster de robots a través de la red local con latencia de un solo dígito de milisegundos. LLMs más grandes pueden vivir aquí, haciendo planificación de alto nivel que un robot individual no necesita hacer por sí mismo.
La ola china de humanoides se construye sobre este supuesto: Unitree, AgiBot, Xiaopeng IRON, Fourier, EngineAI. Sus robots tienen computación a bordo (normalmente Jetson, a veces chips domésticos como Huawei Ascend), y usan la nube para aprendizaje de flota e interfaz conversacional, no para bucles de control.
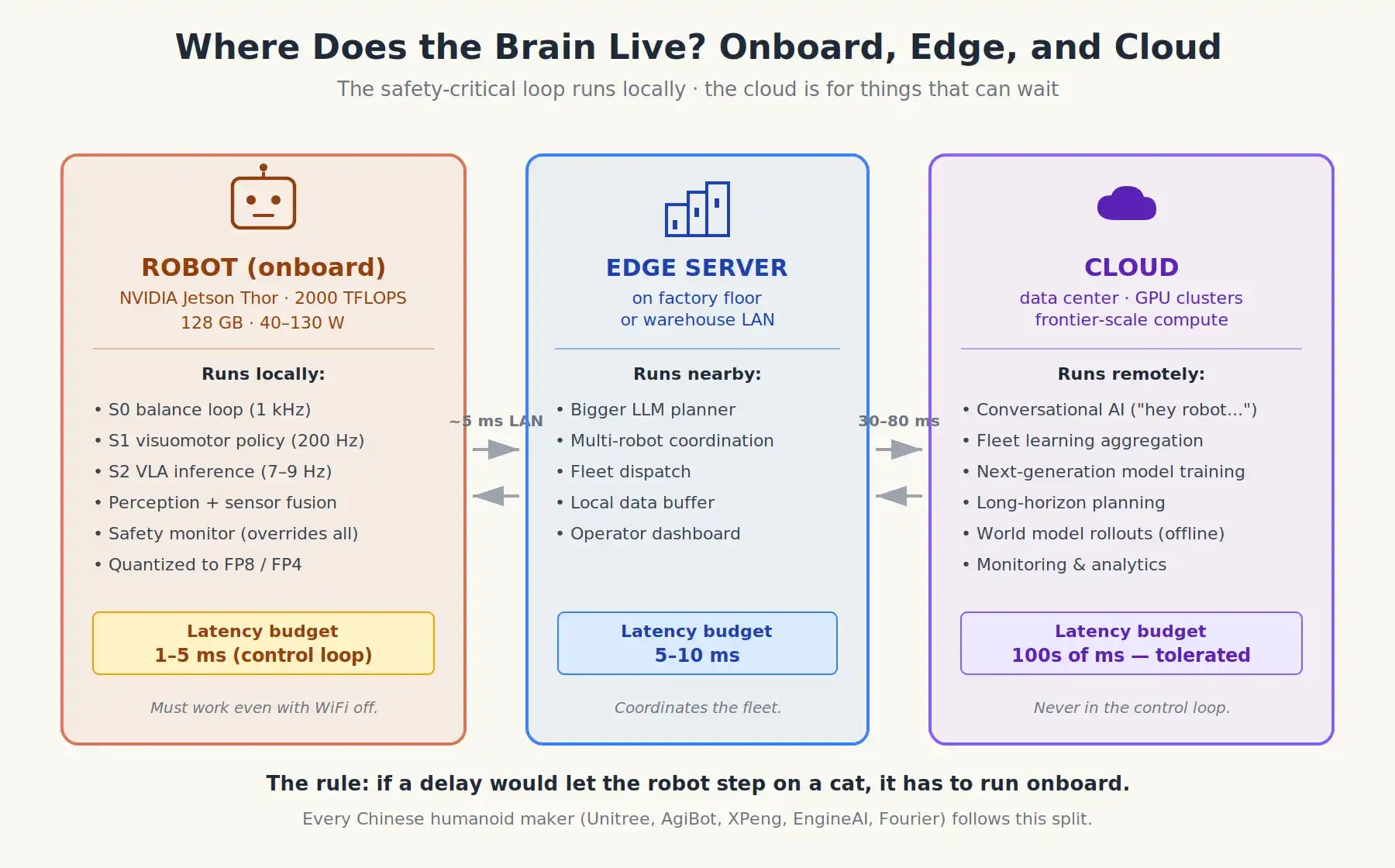
Dónde vive realmente el cerebro del robot: Los bucles críticos para la seguridad corren localmente, la nube es para cosas que pueden esperar.
VII: Por Qué los Modelos de Código Abierto Son el Secreto a Voces
Si solo vieras las demostraciones, pensarías que el campo está dominado por un puñado de empresas estadounidenses bien financiadas. La realidad es mucho más compleja. El ritmo de progreso en IA física está impulsado en gran medida por pesos de modelo de código abierto que cualquiera puede descargar y ajustar.
Esta lista es corta pero significativa:
- OpenVLA (Stanford): El primer modelo genérico de robot de 7B de código abierto.
- NVIDIA Isaac GR00T (N1, N1.5, N1.7): Pesos de código abierto próximos, licencia comercial próxima, entrenado con decenas de miles de horas de video en primera persona humana. GR00T N1.7 salió en marzo de 2026, y cualquiera con un humanoide podrá usar gratis su arquitectura de doble sistema.
- π0 de Physical Intelligence: Pesos lanzados para investigación.
- NVIDIA Cosmos: Modelo base del mundo abierto.
- AgiBot World: Conjunto de datos de código abierto masivo de una startup de Shanghai con demostraciones de teleoperación de humanoides.
- LeRobot de Hugging Face: Una biblioteca abierta que se ha convertido en el punto de encuentro para todas las plataformas anteriores.
- mimic-video de Mimic robotics: Un modelo de video-acción de código abierto que es 10 veces más eficiente en muestras que los VLA tradicionales.
Importa por dos razones. Primero, las startups de robótica no tienen que gastar decenas de millones para preentrenar un modelo base: pueden tomar GR00T o π0 y hacerle fine-tuning con los datos de su propio robot. Así es como lo hacen Unitree, EngineAI, Booster, Galbot y docenas de empresas chinas más pequeñas. Por eso una empresa con solo unos cientos de empleados puede sacar un humanoide que camina, habla y dobla ropa: están sobre los hombros de una pila de código abierto.
Segundo, los modelos de código abierto son la única forma realista de abordar la seguridad. Un modelo completamente cerrado que corre dentro de un robot en una línea de fábrica, sin visibilidad externa de su razonamiento, es una pesadilla regulatoria. Los modelos abiertos permiten a auditores, investigadores y operadores inspeccionar realmente para qué se entrenó al robot.
VIII: Qué Problemas Todavía No Están Resueltos
Si has visto suficientes videos de demostración de robots, también has visto suficientes videos de fallos. La generación actual de robots LLM+VLA es impresionante, pero tiene limitaciones claras. Esto es lo que falla:
- Recuperación a mitad de tarea. Los VLA manejan cambios inesperados mejor que cualquier tecnología anterior. Pero cuando las cosas realmente salen mal (agarre fallido, objeto que rueda, alguien entra en el espacio de trabajo), volver a encarrilarse sigue siendo una debilidad. El robot repite ciegamente la acción fallida.
- Eficiencia de muestras. Entrenar un VLA desde cero requiere decenas de miles de horas de datos de teleoperación. Un humano aprende a usar una herramienta nueva en minutos. Esta brecha de eficiencia es enorme.
- Generalización entre entidades. Un modelo entrenado en un brazo Franka en un laboratorio de Stanford no se transfiere perfectamente a un humanoide Unitree en un almacén de Shenzhen. La física es diferente.
- Tareas a largo plazo. Cualquier tarea que requiera más de 30-60 segundos de comportamiento coherente con múltiples subobjetivos tiende a desviarse. "Hazme el desayuno" sigue siendo imposible.
- Sentido común físico. Los VLA se entrenan por imitación, no por comprensión. No entienden realmente que el agua se derrama si vuelcas una taza. Solo han visto ejemplos y predicen lo que sigue a partir del emparejamiento de patrones.
- Razonamiento espacial. Aunque son multimodales, son sorprendentemente débiles en tareas como "rodear un obstáculo en lugar de atravesarlo" o "apilar estas cosas sin que se caigan".
Esta última serie de debilidades es lo que está haciendo que el campo apueste por un tipo de modelo completamente diferente.
IX: Modelos del Mundo
Imagina esto: ¿y si en lugar de entrenar a un robot para predecir acciones, lo entrenas para predecir las consecuencias de las acciones?
Un Modelo del Mundo es una red neuronal que, dado el estado actual del mundo (normalmente un video o una secuencia de fotogramas) y una acción propuesta, predice cómo se verá el mundo a continuación. En términos simples, piensa en ello como un predictor de video aprendido con un volante. Le das el último segundo de imágenes de la cámara y le dices "el robot moverá el brazo 10 cm hacia adelante", y genera un video realista del siguiente segundo.
¿Por qué importa?
Porque una vez que tienes un modelo del mundo, un robot puede pensar antes de actuar. Puede imaginar tres o cuatro acciones candidatas diferentes, predecir el resultado de cada una, puntuarlas y elegir la mejor. Todo antes de que se mueva ningún motor. Así es como funcionan los motores de ajedrez: no memorizan movimientos, simulan futuros. Nunca antes habíamos tenido esto para robots físicos porque nunca antes habíamos tenido un modelo lo suficientemente preciso del desordenado mundo real.
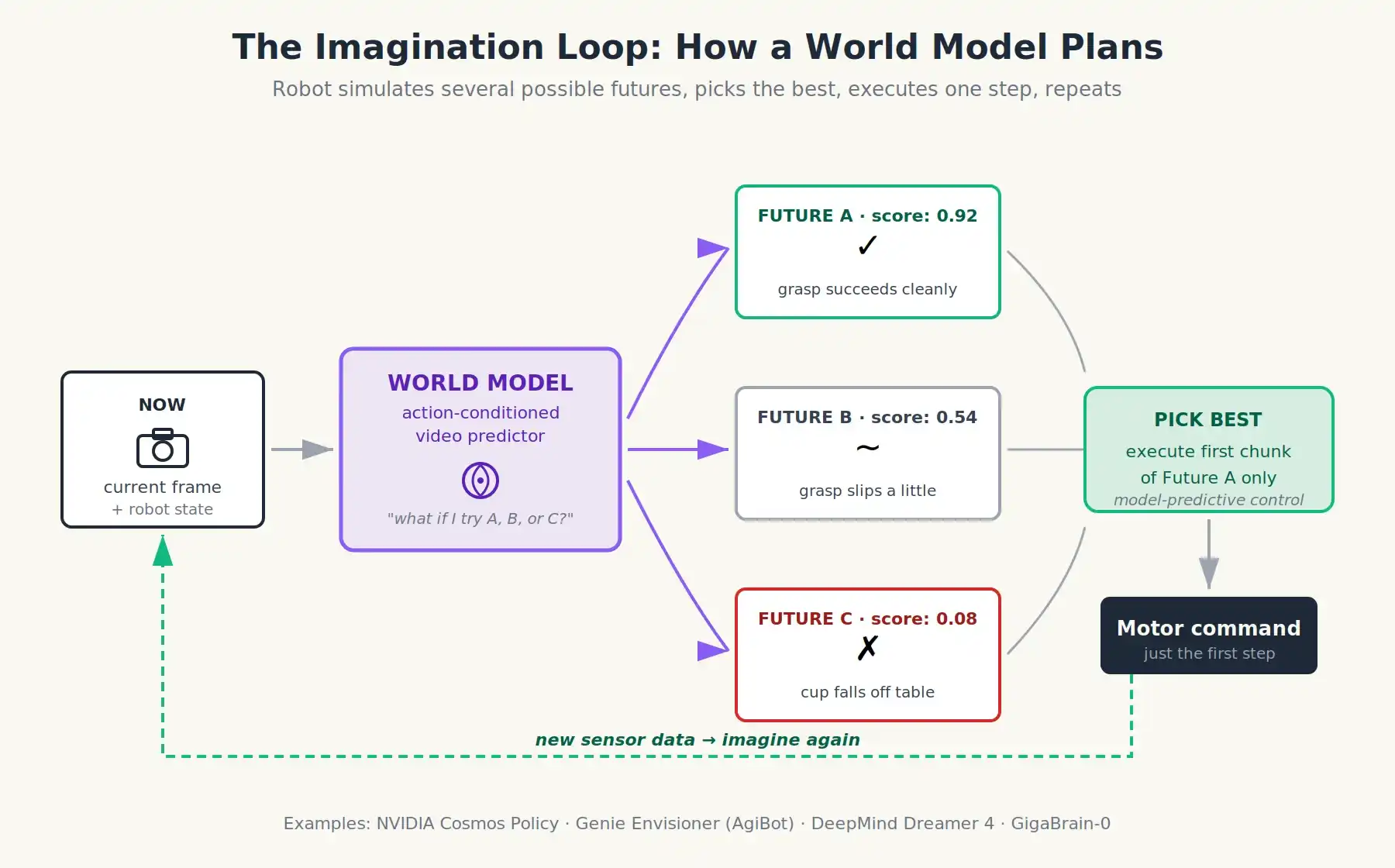
Los modelos del mundo permiten a los robots simular múltiples futuros posibles, puntuarlos y elegir el mejor antes de que se mueva ningún motor.
¿Cómo son los modelos del mundo de 2026?
Los modelos del mundo de vanguardia actuales son diversos pero evolucionan rápidamente. Aquí algunos:
- NVIDIA Cosmos: Una familia de modelos base del mundo abierto, incluidos Cosmos Predict 2.5 (modelo generativo), Cosmos Transfer 2.5 (modelo de simulación controlable), Cosmos Reason 2 (razonador visual-lenguaje para robots) y el más reciente Cosmos Policy. Cosmos Policy va más allá, haciendo fine-tuning del modelo del mundo para emitir directamente acciones para el control. Cosmos se entrena con decenas de miles de horas de GPU de datos de video (Cosmos Predict 2.5 es el modelo del mundo de la familia).
- DeepMind Genie 3: Un modelo del mundo interactivo que genera entornos completamente navegables a partir de indicaciones de texto, a 24 fps, y se mantiene estable durante minutos. Originalmente diseñado para entornos de juego.
- Meta V-JEPA 2: Preentrenado con más de un millón de horas de video de la web, luego condicionado con solo 62 horas de video de robot. Logra un 80% de éxito de agarre y colocación sin ajuste específico en brazos robóticos reales en diferentes laboratorios. El enfoque "JEPA" es arquitectónicamente diferente a los demás.
- DeepMind Dreamer 4: Aprendió a recolectar diamantes en Minecraft (una tarea de 20,000 pasos) usando solo datos fuera de línea, sin interacción con el entorno. Demuestra que el aprendizaje por refuerzo real es posible en mundos simulados.
- Genie Envisioner de AgiBot: Plataforma unificada de modelo del mundo de China, entrenada con más de 3000 horas de video de operación de humanoides del mundo real. Puede generar tanto trayectorias desplegadas predichas como trayectorias de acción ejecutables. AgiBot usa Cosmos Predict 2 de NVIDIA como red troncal y hace fine-tuning con sus propios datos. Este es exactamente el patrón "pila de código abierto + datos propios" descrito antes.
- Modelo del mundo de Toyota Research Institute basado en Cosmos: Usado para aumento de datos de teleoperación y navegación.
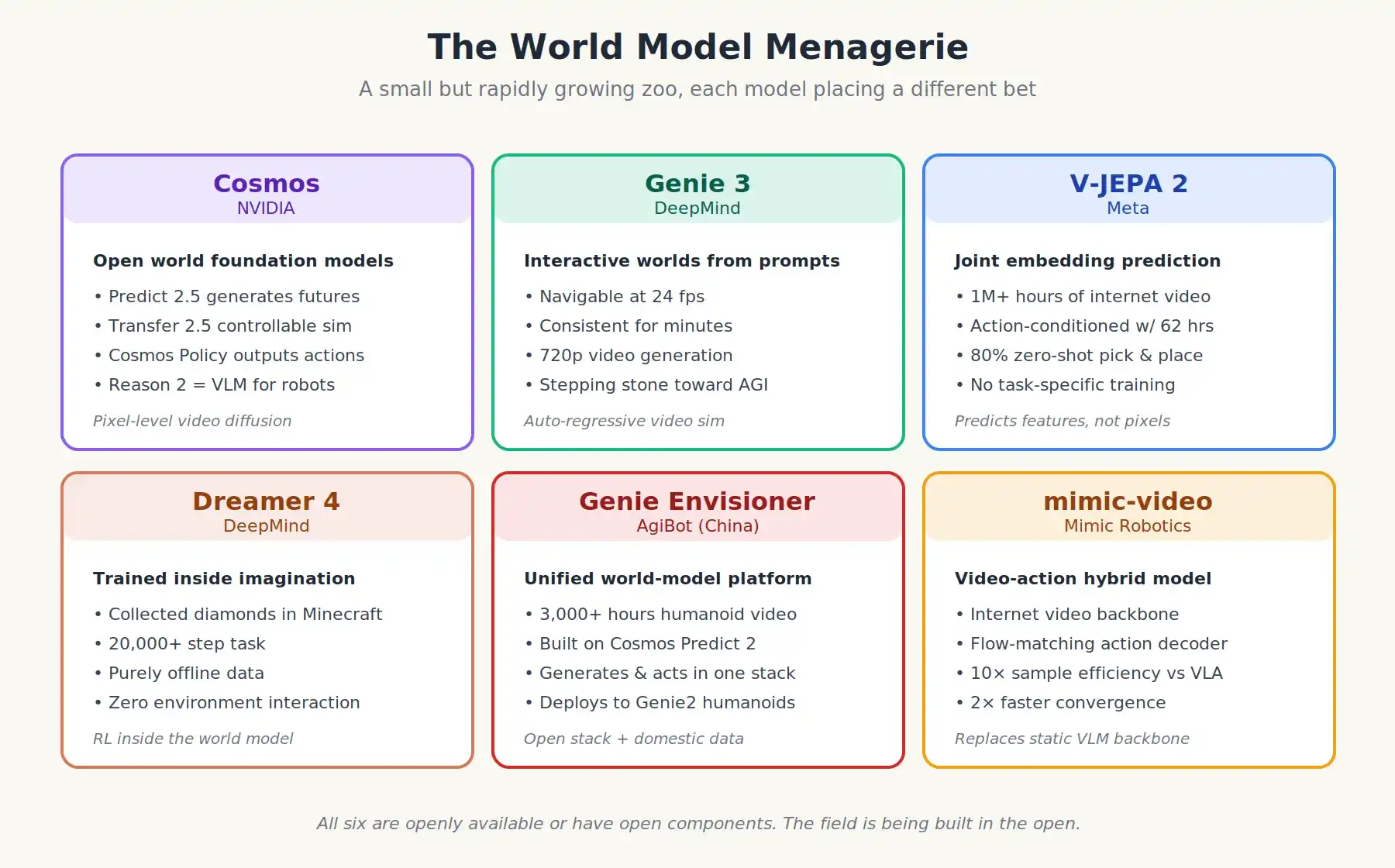
Los seis modelos del mundo más importantes de 2025-2026, cada uno con una idea diferente de cómo una máquina debería aprender física.
X: Arquitecturas Alternativas, Porque el Campo No Está Decidido
No hay un estándar único para construir modelos del mundo. La batalla arquitectónica es actualmente una de las discusiones más interesantes en IA, y afecta directamente lo que los robots podrán hacer en el futuro. Hay que prestar atención a estos tres bandos:
Difusión de video a nivel de píxel (escuela Cosmos/Sora): Usa modelos de difusión para predecir los píxeles reales de los fotogramas futuros. Ventaja: actúa como generador de datos sintéticos, puede representar demostraciones de robot completamente nuevas que nunca ocurrieron. Desventaja: costoso, a veces viola la física, y predecir píxeles que nunca verás es un desperdicio.
Arquitectura de Predicción de Incrustación Conjunta (JEPA) (escuela LeCun): No predice píxeles; predice la representación abstracta del siguiente fotograma. Desecha la textura, conserva solo la esencia semántica de lo que hay en la escena. Ventaja: eficiente, se enfoca en lo que importa para la acción. Desventaja: más difícil de usar. V-JEPA, V-JEPA 2 y nuevos híbridos JEPA-VLA exploran este espacio.
Modelos del Mundo de Acción Latente (escuela Genie/Dreamer): Aprenden a comprimir videos enteros en un "lenguaje de acción" latente que captura la estructura del comportamiento, luego entrenan el modelo del mundo para predecir el siguiente estado latente dado la siguiente acción latente. Ventaja: permite entrenar con video de la web sin acciones, luego agregar un poco de datos de robot real. Desventaja: las acciones latentes no son interpretables por humanos, lo que complica el análisis de seguridad.

Difusión de píxeles, JEPA y acción latente: el mismo objetivo, formas radicalmente diferentes de construir un modelo del mundo.
XI: Cómo Se Vería Realmente un Robot Basado en Modelo del Mundo
Si avanzas unos años, la arquitectura de un humanoide de vanguardia podría verse así:
Un VLA con un modelo del mundo encima. Cuando el robot encuentra una situación nueva, ejecuta algo como esto:
- El VLA propone algunos candidatos para la siguiente acción (sigue siendo la política).
- El modelo del mundo toma cada acción candidata y simula 1-3 segundos de video hipotético.
- Un evaluador de valor puntúa según el resultado imaginado: ¿se agarró la taza? ¿Algo se cayó? ¿Alguien resultó herido?
- El robot elige la acción con la puntuación más alta, y solo ejecuta su primera parte.
- Los datos reales del sensor retroalimentan; se repite el ciclo.
Esto es control predictivo por modelo, una técnica usada durante años para estabilizar cohetes y cuadricópteros, pero reemplazando ecuaciones físicas derivadas a mano con un modelo del mundo aprendido. Lo escalable es que el modelo del mundo se preentrena con millones de horas de video, no porque alguien escribió las ecuaciones de Navier-Stokes para una cocina.
Los beneficios se acumulan:
- Mejora en la recuperación. Si un agarre se desliza, el modelo del mundo puede imaginar múltiples trayectorias de corrección y elegir la más prometedora.
- Mayor generalización. Un modelo del mundo entrenado en video de la web ha experimentado "física" varios órdenes de magnitud más que cualquier conjunto de datos de teleoperación de robots.
- Planificación a largo plazo manejable. Planifica en la imaginación, no en la realidad.
- Brecha sim2real más pequeña. En lugar de entrenar en un simulador que construiste (p. ej., Isaac Sim, motor de física Newton) y esperar que la capacitación se transfiera, ahora puedes entrenar en un simulador que aprendió a coincidir con video real. Por lo tanto, la brecha es menor.
- Explosión de datos sintéticos. Un modelo del mundo puede generar millones de trayectorias de robot diferentes, en diferentes iluminaciones, materiales y configuraciones de objetos, casi gratis. Resuelve uno de los mayores cuellos de botella del campo.
También tiene una ventaja de seguridad importante. Un robot que puede simular las consecuencias de sus acciones puede rechazar realizar una operación peligrosa: no porque una regla escrita lo impida, sino porque prevé a alguien lastimado en el futuro.
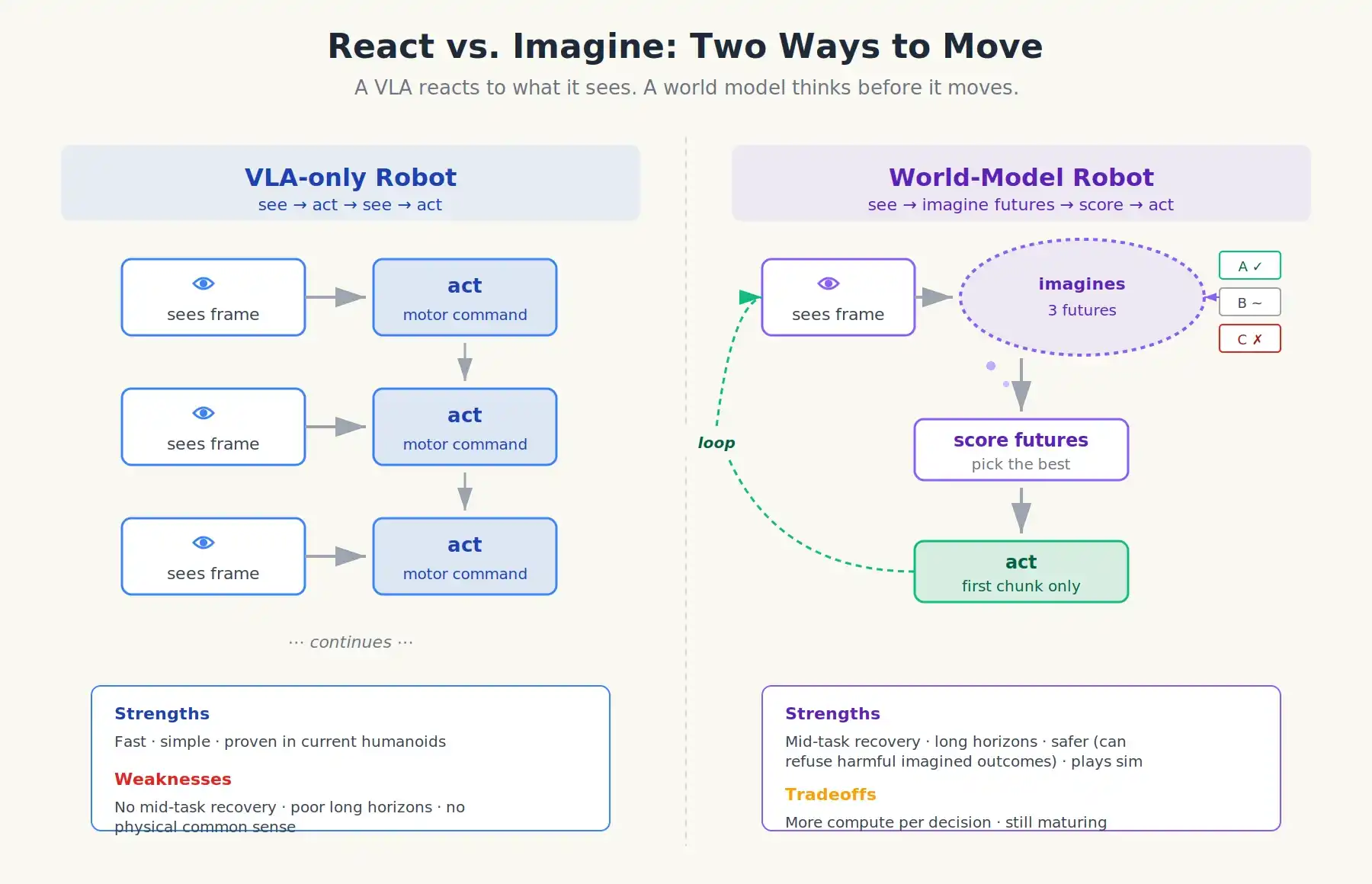
Dos formas de moverse: El robot VLA reacciona a lo que ve; el robot con modelo del mundo piensa antes de moverse.
XII: Cosas Más Que Deberías Saber
Los datos son el verdadero núcleo del problema: Toda la innovación arquitectónica del mundo no sirve si no puedes alimentar al modelo. Actualmente, la teleoperación (humanos usando equipo VR para manipular remotamente un robot como un títere) es el principal cuello de botella de ingeniería. La ventaja competitiva de una empresa de robótica depende cada vez más de su canalización de recolección de datos, no del modelo en sí. AgiBot tiene almacenes llenos de operadores. La ley de escalado de destreza del GR00T N1.7 de NVIDIA muestra que más video en primera persona humana mejora directamente y predeciblemente la destreza del robot. Esta es también una parte donde China tiene ventaja estructural: costos laborales más bajos para la recolección de datos, entornos de implementación más permisivos y coordinación estatal activa de la cadena de suministro.
La simulación es un universo paralelo. Isaac Sim de NVIDIA, el nuevo motor de física Newton de código abierto (la versión 1.0 saldrá oficialmente en abril de 2026) y la plataforma Omniverse permiten a las empresas entrenar robots en millones de simulaciones paralelas sin desplegarlos en el mundo real. La mayoría de lo que parece "inteligencia robótica" se cultiva primero en simulación y luego se transfiere al hardware.
La economía comienza a tener sentido. Unitree entregó alrededor de 5,500 humanoides en 2025 y planea 10,000-20,000 en 2026. El precio promedio ha bajado de $85,000 a $25,000 en dos años. El R1 de Unitree cuesta $5,900. El Noetix Bumi saldrá al mercado a $1,400. El hardware de los humanoides se está acercando al precio de la electrónica de consumo, mientras que la IA en su interior sigue estando por detrás de las demostraciones. Esa brecha se cerrará, y cuando lo haga, el volumen cambiará drásticamente la industria.
Los modos de fallo se ven extraños. Cuando los robots basados en LLM fallan, a menudo lo hacen de formas que los robots tradicionales no podrían: hacer las cosas mal con confianza, percibir funciones "alucinadas", caer en bucles de conversación con su propio planificador. La comunidad robótica tradicional es bastante escéptica, con razón, insistiendo en que los sistemas de aprendizaje deben estar encerrados en jaulas de seguridad y restricciones de comportamiento. Los robots más confiables desplegados actualmente son híbridos: un cerebro VLA colocado dentro de una jaula de seguridad diseñada a mano.
La narrativa del "momento ChatGPT" es una metáfora útil pero engañosa: Jensen Huang le ha estado diciendo a todo el mundo que el momento ChatGPT de los robots ya está aquí. Lo dice porque NVIDIA vende palas y picos. La versión más honesta es: actualmente estamos aproximadamente en la era GPT-2 de la IA física. Es poderoso, puede sorprenderte; no es lo suficientemente poderoso para desplegarse sin supervisión. Itera rápidamente, pero no ha alcanzado un punto de inflexión de adopción viral, sino una trayectoria de ascenso lenta y constante.
Conclusión

La evolución de los cuadrúpedos de Unitree (de derecha a izquierda)
En la demostración que vi en la oficina de Unitree, cinco humanoides G1 realizaban artes marciales coreografiadas, con controladores de estilo VLA a bordo haciendo ajustes finos y operadores remotos asegurando que todo saliera bien. Fundamentalmente, no era completamente autónomo. Pero toda la pila: percepción, planificación, control de movimiento, está siendo reemplazada por redes neuronales. En dos años, el mismo robot podría hacer la misma rutina sin coreografía, porque habrá imaginado el movimiento completo por adelantado y elegido la mejor versión.
Todo el desarrollo descrito en este artículo, desde controladores escritos a mano, hasta percepción por aprendizaje automático, planificadores LLM, VLA, arquitecturas de doble sistema y finalmente modelos del mundo, es en realidad el lento movimiento de dónde reside la inteligencia robótica. Comenzó en la mente del ingeniero, luego se convirtió en código escrito a mano, luego se movió a la capa de percepción, al planificador, a la política. Y ahora finalmente se está moviendo hacia un modelo que aprende el mundo mismo.
Cada transición ha hecho que los robots sean más generales, más adaptables, más útiles. Si la transición al modelo del mundo funciona, realmente les dará un poder: suficiente para que la pregunta ya no sea "¿qué pueden hacer los robots?" sino "¿qué deberíamos hacer que hagan?"
Lectura relacionada: Un análisis de más de 30 empresas de robots humanoides: ¿Quién ganará en 2026?