DeepSeek V4 acaba de realizar una actualización.
Se ha lanzado un nuevo marco de decodificación especulativa (Speculative Decoding) llamado DSpark, y simultáneamente se ha hecho de código abierto el stack completo de decodificación especulativa que lo respalda, DeepSpec.
DeepSeek-V4-Pro-DSpark no es un modelo de arquitectura completamente nueva, sino que introduce un módulo de decodificación especulativa basado en DeepSeek-V4-Pro. El foco de esta actualización está en la implementación de ingeniería, no en la iteración de las capacidades intrínsecas del modelo.
DSpark ya ha sido desplegado en el tráfico real en línea de DeepSeek-V4 (tanto Flash como Pro), acelerando significativamente la velocidad de inferencia de los modelos de lenguaje grandes (LLM).

Informe técnico: «DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation»
Enlace al informe técnico: https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
El objetivo central de DSpark es abordar los cuellos de botella de latencia y capacidad de procesamiento que enfrenta la inferencia de LLM en entornos de producción, especialmente en escenarios de alta concurrencia. En resumen, DSpark combina con éxito la «generación paralela» de alto rendimiento con la «verificación adaptativa consciente de la carga».
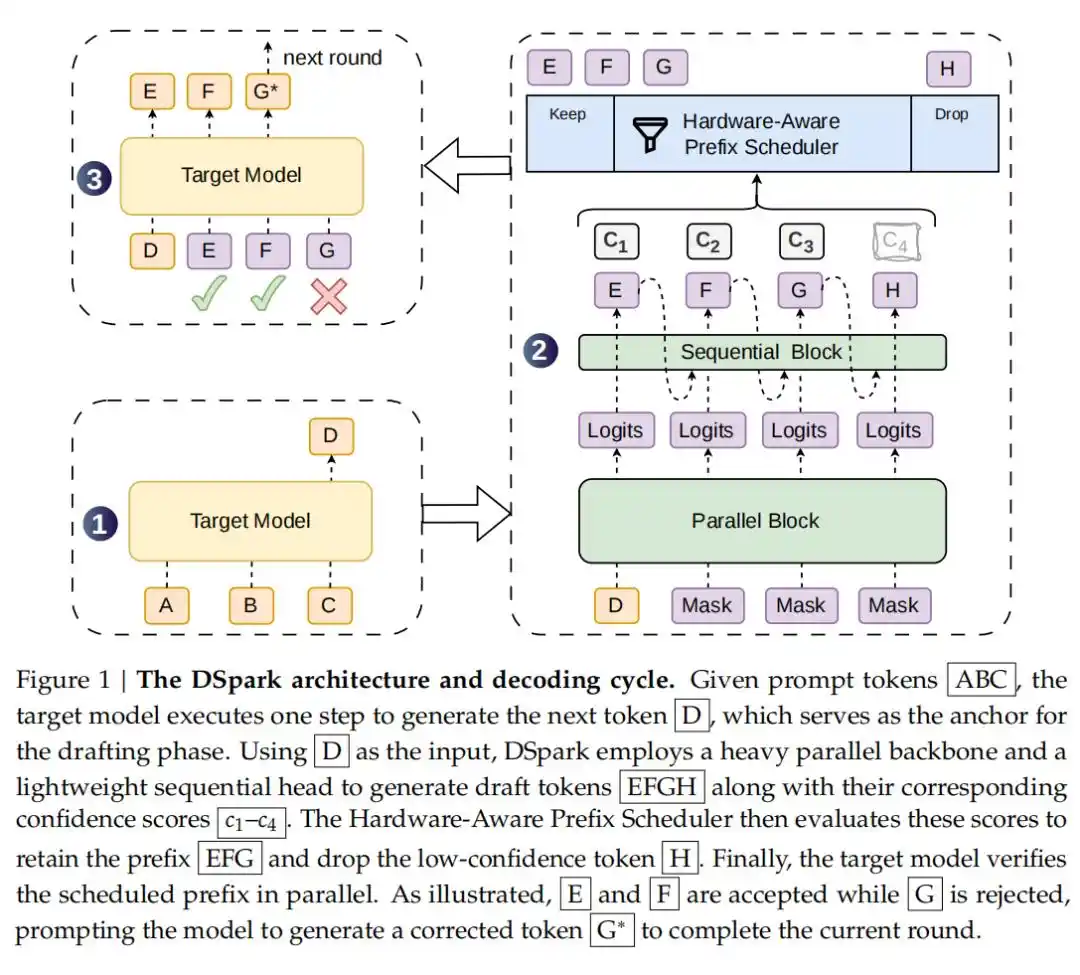
La decodificación especulativa es una técnica para acelerar la inferencia de modelos de lenguaje grandes sin alterar la distribución de salida del modelo. Su idea central es introducir un «modelo borrador» (draft model) liviano que genera previamente varios tokens candidatos, y luego el modelo objetivo (target model) valida y acepta este lote de candidatos de manera masiva. Esto transforma la generación token por token, que es en serie, en una verificación por lotes en paralelo, reduciendo drásticamente la latencia de extremo a extremo.
Sobre esta base, la innovación de DSpark radica en introducir una arquitectura de generación semi-autoregresiva (Semi-Autoregressive Generation): conserva la ventaja de alto rendimiento del modelo borrador paralelo, mientras incorpora un módulo serial liviano que modela las dependencias entre tokens dentro de un bloque, para mitigar el problema del deterioro de la tasa de aceptación que suelen presentar los modelos borrador paralelos en posiciones posteriores.
Además, introduce una verificación programada por confianza y consciente del hardware (Confidence-Scheduled Verification): La decodificación especulativa anterior solía enviar ciegamente todos los tokens borrador generados para su verificación. En momentos de alta carga del sistema, estos tokens finales, que tienen una alta probabilidad de ser rechazados, desperdiciaban seriamente la valiosa capacidad de procesamiento por lotes. DSpark introduce una cabecera de confianza (Confidence Head) para evaluar la probabilidad de supervivencia de cada token. Combinado con un programador de prefijos consciente del hardware, el sistema puede, según las características de rendimiento en tiempo real del motor, asignar dinámicamente una longitud de verificación óptima para cada solicitud, destinando la capacidad de cálculo solo a los tokens con la mayor recompensa esperada.
Para ser implementado en una infraestructura en línea real, el programador de DSpark adopta un mecanismo asíncrono, compatible con la programación de sobrecarga cero (ZOS) y la reproducción continua de grafos CUDA. Utiliza predicciones históricas de los dos pasos anteriores para decidir la longitud de truncamiento dinámico actual, ocultando así la latencia de programación, evitando pausas en la tubería de la GPU y garantizando al mismo tiempo una reproducción completamente fiel de la distribución de salida del modelo objetivo.
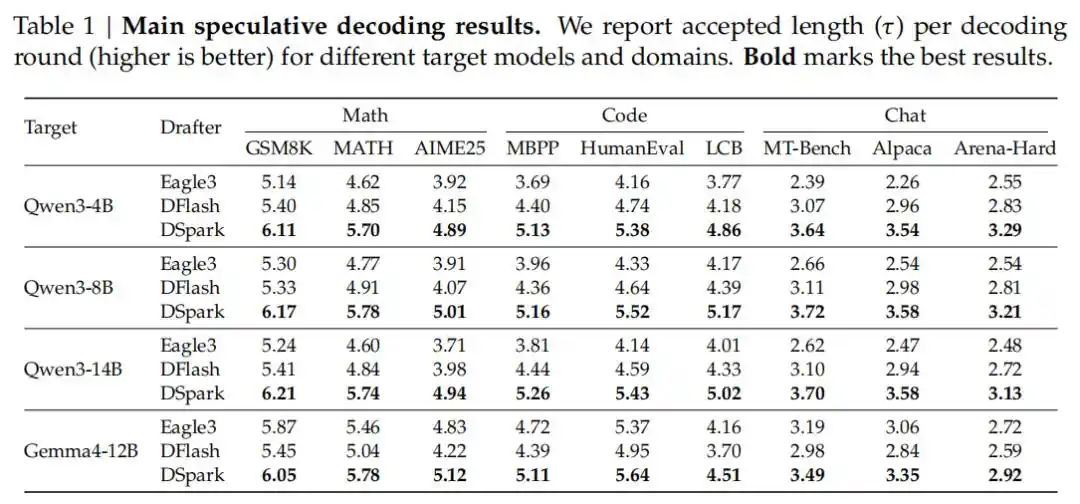
En pruebas que cubren múltiples áreas, como razonamiento matemático, generación de código y conversaciones cotidianas, DSpark superó significativamente a los modelos autoregresivos de vanguardia actuales (Eagle3) y a los modelos borrador paralelos (DFlash). Por ejemplo, en modelos objetivo de la serie Qwen3 (4B, 8B, 14B), su longitud de aceptación promedio superó a Eagle3 entre un 26.7% y un 30.9%, y a DFlash entre un 16.3% y un 18.4%.
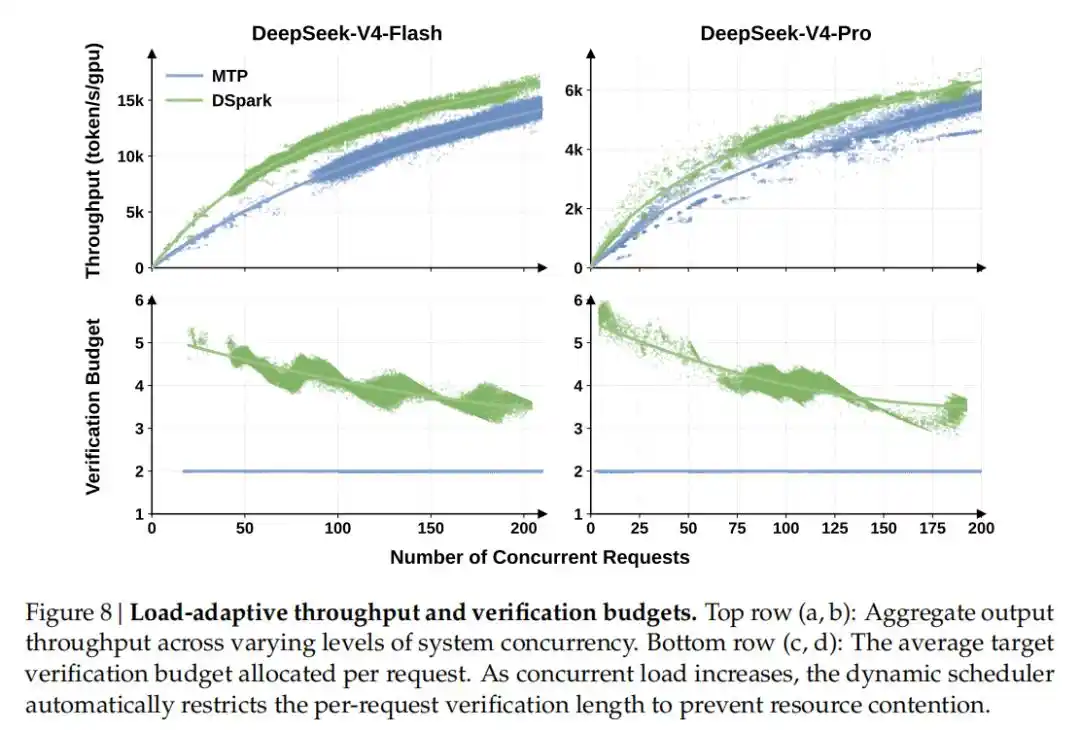
En comparación con el punto de referencia de producción por token único (MTP-1) desplegado en la generación anterior, manteniendo el mismo rendimiento total, DSpark aumentó la velocidad de generación para los usuarios entre un 60%-85% (modelo Flash) y un 57%-78% (modelo Pro).
Junto con DSpark también se ha hecho de código abierto DeepSpec, un repositorio de código completo para entrenar y evaluar modelos borrador de decodificación especulativa. Es la «infraestructura de código abierto» que alberga esta solución y otras implementaciones algorítmicas de vanguardia, incluyendo herramientas de preparación de datos, implementaciones de modelos borrador, código de entrenamiento y scripts de evaluación.
DeepSpec divide el proceso general en tres etapas: preparación de datos, entrenamiento y evaluación. Las tres etapas deben ejecutarse en orden, donde la salida de una etapa sirve como entrada para la siguiente.
En la etapa de preparación de datos, es necesario descargar datos de prompts (indicaciones), regenerar respuestas utilizando un motor de inferencia sobre el modelo objetivo y construir una caché objetivo (target cache). Es importante señalar que, tomando como ejemplo la configuración predeterminada Qwen/Qwen3-4B, el volumen de la caché objetivo puede alcanzar aproximadamente 38 TB, por lo que es necesario evaluar adecuadamente los recursos de almacenamiento antes de usarla.
La etapa de entrenamiento se inicia ejecutando bash scripts/train/train.sh. Este script llamará a train.py e iniciará un worker para cada GPU visible. Los usuarios pueden seleccionar diferentes configuraciones de algoritmo y modelo objetivo en el directorio config/ especificando config_path. El proyecto también permite ajustar la configuración del entrenamiento sobrescribiendo config_path, target_cache_dir y usando --opts para modificar campos de configuración individuales.
En cuanto a hardware, la configuración predeterminada y los scripts de DeepSpec están orientados a un entorno de un solo nodo con 8 GPUs. Si el número de GPUs es menor, los usuarios deben reducir correspondientemente el número de GPUs visibles en CUDA_VISIBLE_DEVICES.
La etapa de evaluación se inicia ejecutando bash scripts/eval/eval.sh. El script de evaluación utilizará el checkpoint del modelo borrador entrenado para medir la aceptación en múltiples tareas de referencia de decodificación especulativa. Los conjuntos de datos de evaluación listados actualmente en el proyecto incluyen GSM8K, MATH500, AIME25, HumanEval, MBPP, LiveCodeBench, MT-Bench, Alpaca y Arena-Hard-v2, cubriendo diferentes tipos de tareas como razonamiento matemático, generación de código, capacidades de conversación y preguntas y respuestas generales.
En cuanto a algoritmos, DeepSpec actualmente incluye tres modelos borrador: DSpark, DFlash y Eagle3. Respecto a las series de modelos objetivo, el proyecto actualmente admite Qwen3 y Gemma.
La apertura del código de DeepSpec integra la práctica de ingeniería de la decodificación especulativa, que antes estaba dispersa entre diversos equipos de investigación, en una cadena de herramientas estandarizada, reproducible y extensible. Para investigadores e ingenieros que deseen acelerar la inferencia de sus propios modelos grandes, esto significa que pueden entrenar modelos borrador personalizados directamente sobre un marco maduro, saltándose gran parte del trabajo repetitivo de construcción de infraestructura básica.
Enlaces de referencia:
https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
https://github.com/deepseek-ai/DeepSpec
Este artículo proviene de la cuenta de WeChat pública «机器之心» (ID:almosthuman2014), autores: Zenan, Yang Wen





