С конца 2024 года трейдеры активно ставили на дальнейший рост, скупая колл-опционы со страйками $100 000, $120,000 и $140 000. Последний вариант до недавнего времени был самым востребованным на бирже Deribit — открытый интерес (ОИ) по контракту стабильно превышал $2 млрд.
«Теперь картина другая. Открытый интерес по колл-опционам со страйком $140 000 составляет $1,63 млрд. При этом в лидеры вышел пут со страйком $85 000 и открытым интересом $2,05 млрд. Путы $80 000 и $90 000 также обогнали по этому показателю колл $140 000», — поделился наблюдениями исследователь.
Диаграмма ниже иллюстрирует концентрацию ОИ в пут-контрактах с более низкими ценами исполнения.
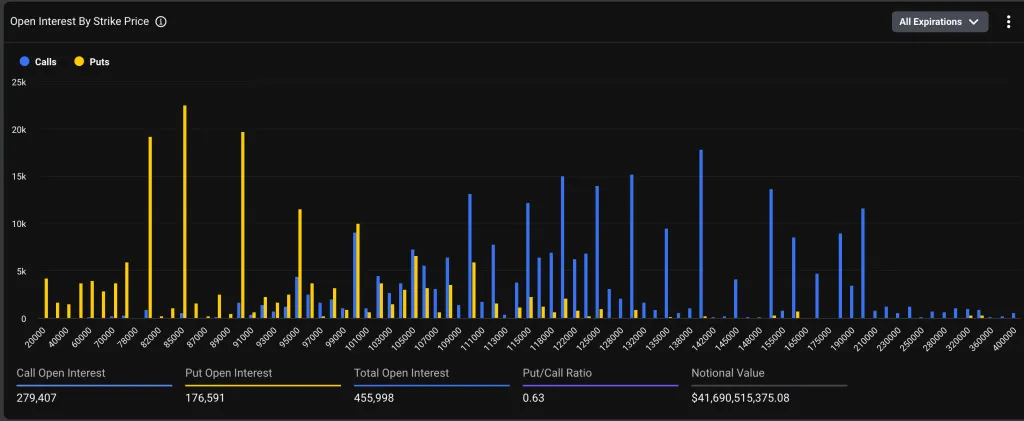
Объем открытых коллов все еще значительно выше, однако путы торгуются с заметной премией. Это указывает на смещение спроса в пользу «медвежьих» контрактов и свидетельствует об опасениях инвесторов относительно дальнейшей коррекции рынка.
«Опционы отражают осторожность рынка к концу года. В настоящее время наибольший оборот приходится на краткосрочные пут-опционы со страйками $84 000-80 000. Подразумеваемая волатильность опционов с ближайшими сроками экспирации — около 50%, кривая показывает выраженный перекос в сторону путов (+5-6,5%) для защиты от снижения», — прокомментировал коммерческий директор Deribit Жан-Давид Пекиньо.
Активность на децентрализованной биржи Derive.xyz также указывает на усиление медвежьих настроений: 30-дневный перекос снизился с −2,9% до −5,3%. Это признак того, что трейдеры все чаще хеджируют риски коррекции опционами пут.
«Рассматривая ситуацию на конец года, вокруг экспирации 26 декабря формируется заметная концентрация пут-опционов на биткоин, особенно со страйком $80 000», — прокомментировал исследователь Derive.xyz доктор Шон Доусон.
На фоне сохраняющихся опасений касательно устойчивости рынка труда США и снижения вероятности декабрьского понижения ставки до примерно 50%, на макроуровне остается немного факторов, поддерживающих бычьи настроения трейдеров, отметил эксперт.
Пут опционы дают покупателю право, но не обязательство, продать базовый актив по заранее установленной цене в будущем. Такие контракты обычно выбирают участники рынка, ожидающие снижения стоимости актива или стремящиеся застраховаться от падения цены. Покупатель колл-опциона, напротив, рассчитывает на рост рынка.
Что дальше?
Несмотря на нисходящий тренд, давление продаж может скоро снизиться: технические индикаторы сигнализируют о перепроданности, а метрики рыночных настроений уже продолжительное время в зоне «экстремального страха».
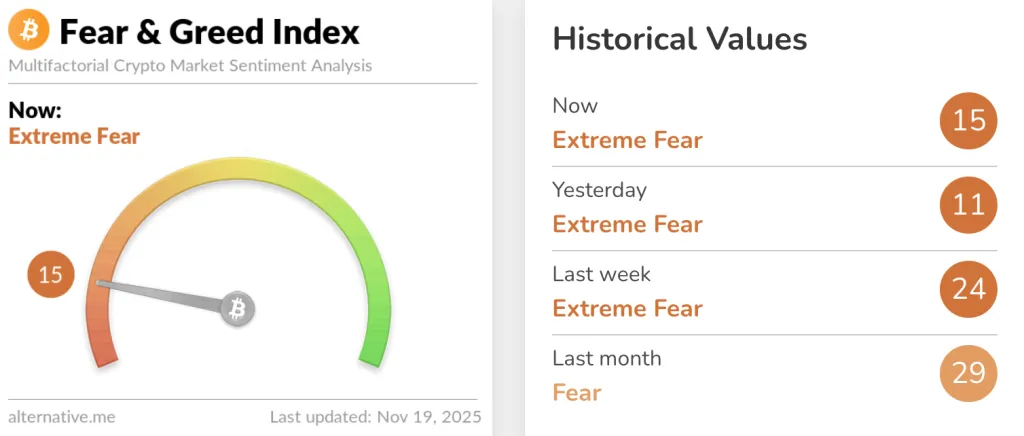
«При индексе страха и жадности около 15 и RSI, приближающемся к отметке 30 (зона перепроданности, но не экстремум), крупные кошельки (с балансом свыше 1000 BTC) заметно нарастили позиции за последнюю неделю. Это намекает на накопление активов “умными деньгами” на пониженных уровнях», — сказал Пекиньо.
Он добавил, что в целом страх дальнейшего снижения в краткосрочной перспективе оправдан. Путь наименьшего сопротивления пока пролегает вниз, но «подобные экстремальные ситуации в прошлом вознаграждали тех, кто шел на риск».
Напомним, Хасиб Куреши из Dragonfly назвал текущую коррекцию «незначительной» и призвал не паниковать.





