4-17%. Es la tasa de lectura de la caché de prompt de Claude Code durante el último mes. El nivel normal es 97-99%.
Esto significa que, cuando recuperas una sesión anterior, Claude Code no reutilizó el contexto ya procesado, sino que cada vez procesó todo el contenido desde cero, consumiendo de 10 a 20 veces más crédito de lo normal. Creías que estabas continuando una conversación, pero en realidad estabas comenzando una conversación completamente nueva y de precio completo cada vez.
Este número proviene de las mediciones de monitoreo de proxy del desarrollador independiente ArkNill. Al configurar un proxy transparente, registró cada solicitud entre Claude Code y la API de Anthropic, descubriendo al menos dos errores de caché del cliente que impedían que el servidor API coincidiera con el prefijo de conversación ya almacenado en caché, obligándolo a reconstruir todos los tokens desde cero en cada turno.
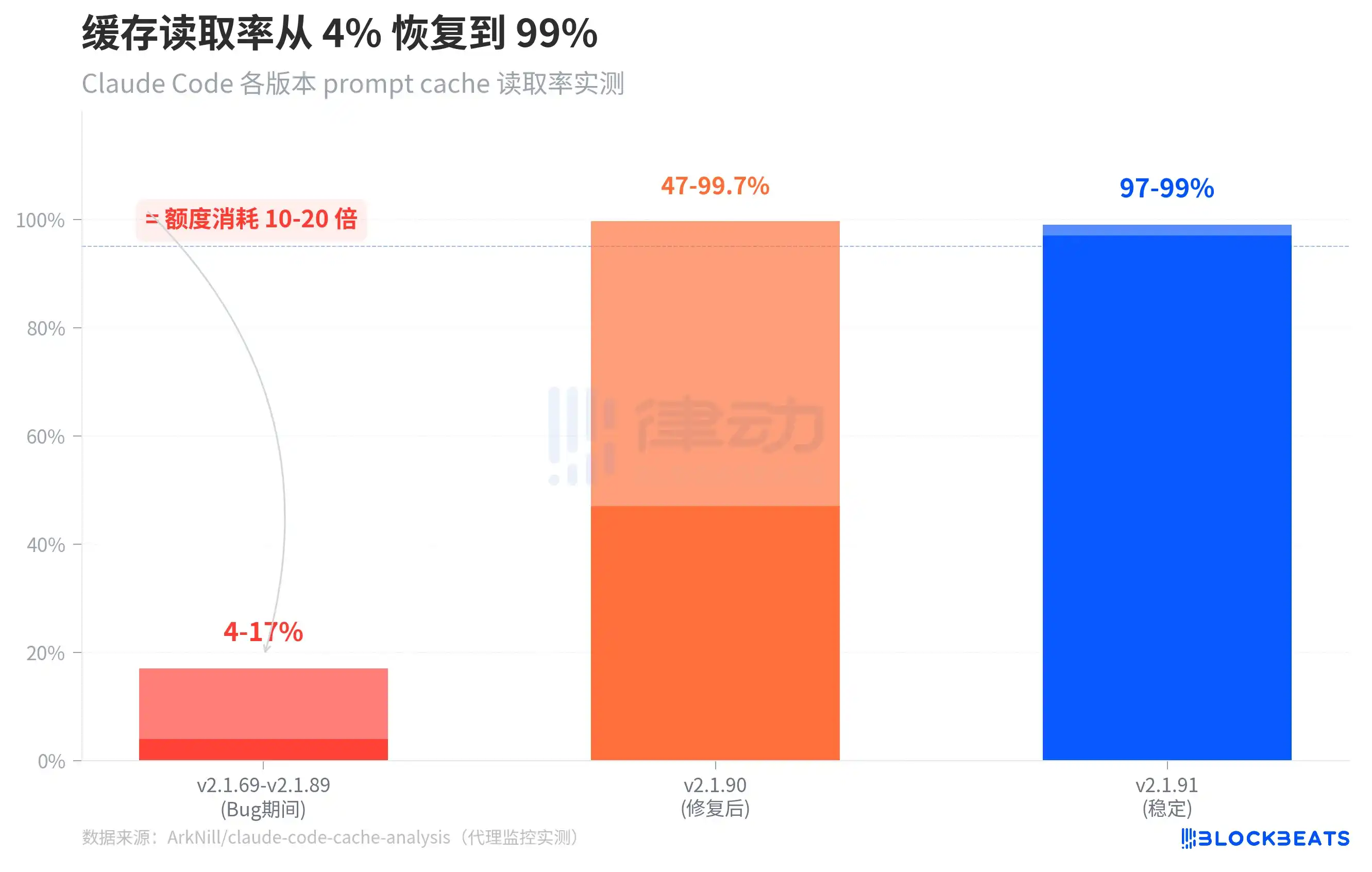
El gráfico anterior muestra una comparación de las tasas de lectura de caché en tres etapas. Durante el período de v2.1.69 a v2.1.89 (es decir, el período con el error), la tasa de lectura de caché de la versión standalone fue de apenas 4-17%. Después de que v2.1.90 corrigió uno de los errores clave, la tasa de lectura de caché en frío volvió a 47-99.7%. Para v2.1.91, la tasa de lectura de caché en funcionamiento estable se recuperó a 97-99%.
Vale la pena señalar un detalle en el gráfico: el rango de v2.1.90 es muy amplio (47% a 99.7%), esto se debe a que cuando una sesión se reanuda, la caché aún necesita un «calentamiento», y las tasas de acierto de las primeras rondas son bajas, pero pronto vuelven a niveles normales. En la versión con el error, este calentamiento nunca ocurrió: la lectura de la caché siempre se estancó en los 14,500 tokens del prompt del sistema, y todo el historial de la conversación se facturó a precio completo cada vez.
28 días, 20 versiones
Este error no fue del tipo que se introduce en una actualización y se corrige en la siguiente. Según los registros de publicación del registro de npm, la v2.1.69 que introdujo el error se lanzó el 4 de marzo, y la v2.1.90 que lo corrigió se lanzó el 1 de abril. Hubo una brecha de 28 días, abarcando 20 versiones.
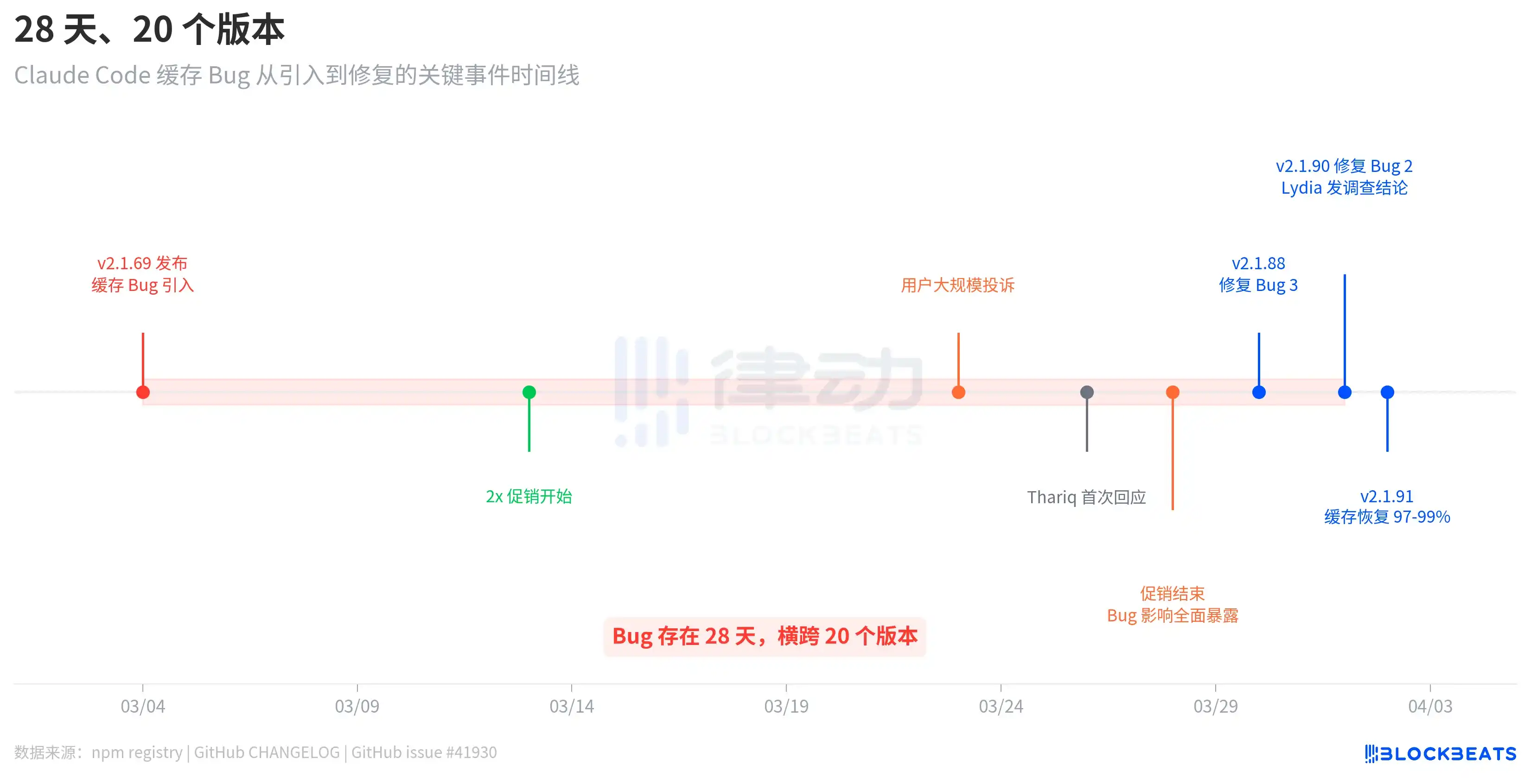
La línea de tiempo revela un detalle intrigante. Después de que el error se introdujo el 4 de marzo, los usuarios no se quejaron masivamente de inmediato. Las quejas estallaron de forma concentrada recién alrededor del 23 de marzo, con casi tres semanas de por medio. La razón, según se desprende del issue #41930 de GitHub, es que entre el 13 y el 28 de marzo, Anthropic había lanzado una promoción de doble crédito (doble en horarios de menor actividad), lo que enmascaró objetivamente el impacto del error. Cuando la promoción terminó, el consumo debido al error de caché volvió a la línea base de facturación normal, y el crédito de los usuarios se «evaporó» instantáneamente.
La respuesta de Anthropic no fue rápida. El 26 de marzo, tres días después del estallido de las quejas de los usuarios, el ingeniero Thariq Shihipar anunció en su cuenta personal de X que se había ajustado el límite para las horas pico (días laborables de 5 a. m. a 11 a. m., hora del Pacífico). El 30 de marzo, Anthropic admitió en Reddit que «los usuarios estaban alcanzando sus límites mucho más rápido de lo esperado», diciendo que era la máxima prioridad del equipo. No fue hasta el 1 de abril que la miembro del equipo Lydia Hallie publicó las conclusiones formales de la investigación.
Durante todo el proceso, Anthropic no publicó ninguna entrada de blog, no envió notificaciones por correo electrónico, no actualizó su página de estado. Toda la comunicación oficial se realizó únicamente a través de publicaciones en redes sociales personales de ingenieros y algunos comentarios en Reddit.
¿Cuánto pagaste, cuánto duró?
El issue #41930 de GitHub reunió cientos de informes de usuarios. El caso más extremo fue el de un usuario suscrito a Max 20x ($200/mes), cuya ventana rodante de 5 horas se agotó por completo en 19 minutos. Los usuarios de Max 5x ($100/mes) informaron que su ventana de 5 horas se agotaba en 90 minutos. Según informó The Letter Two, otro usuario afirmó que un simple «hola» consumió el 13% de la cuota de la conversación. Un usuario Pro ($20/mes) dijo en Discord que su crédito «se agotaba los lunes y se reiniciaba los sábados», pudiendo usar el servicio normalmente solo 12 días en 30.
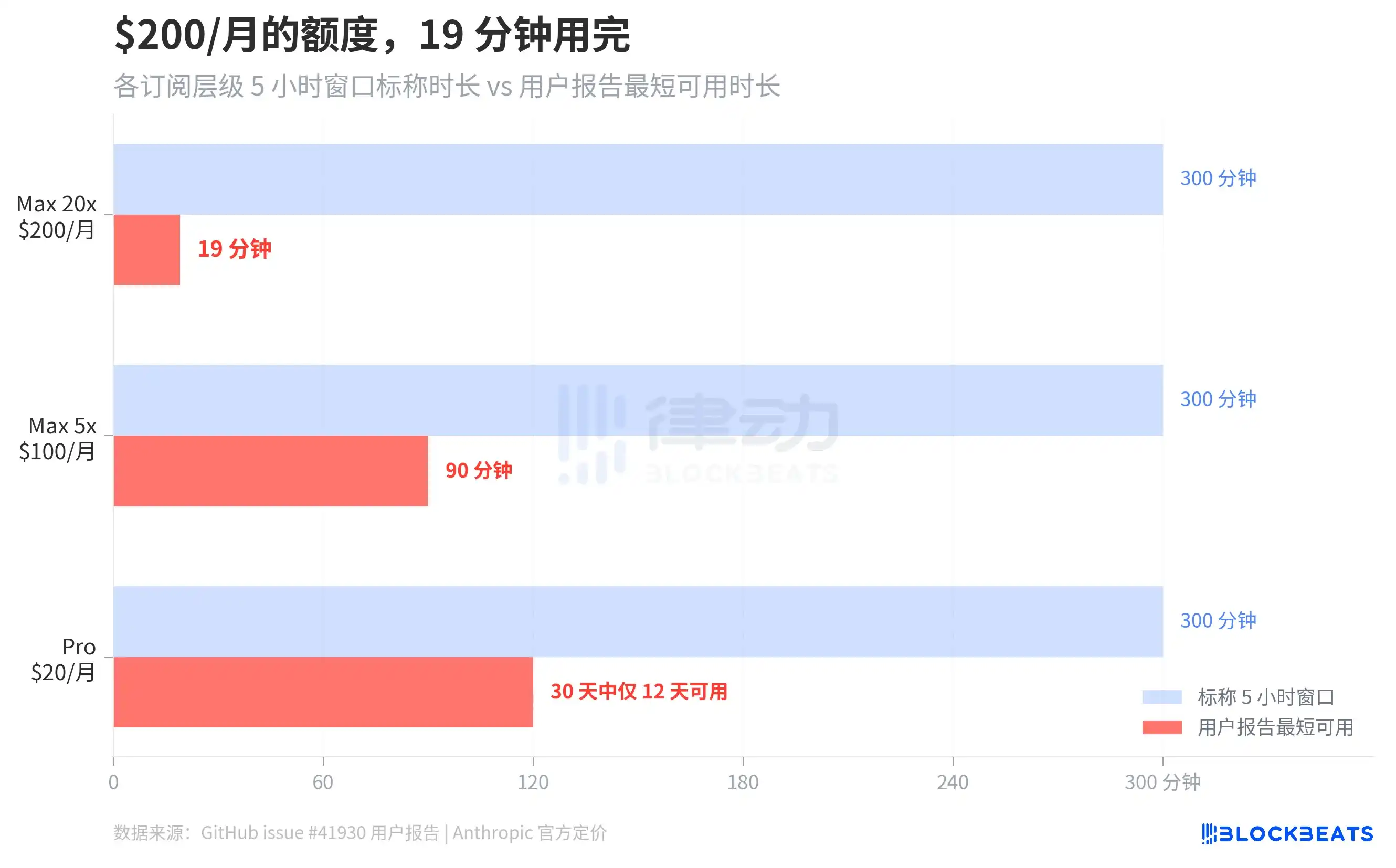
Según las pruebas de referencia de ArkNill, en la versión con error v2.1.89, el 100% de la cuota del plan Max 20x se agotaba en unos 70 minutos. También calculó el costo en crédito de una sola operación --resume en una conversación con un contexto de 500K tokens, aproximadamente $0.15, porque el sistema reproduciría todo el contexto completo.
«No lo estás usando correctamente»
Las conclusiones de la investigación de Lydia Hallie confirmaron dos puntos: primero, que los límites en horas pico efectivamente se habían ajustado, y segundo, que el consumo de las conversaciones con contexto de 1 millón de tokens había aumentado. Dijo que el equipo había corregido algunos errores, pero enfatizó que «ninguno de estos errores causó sobrecargos».
Luego dio cuatro recomendaciones para ahorrar:
1. Usar Sonnet 4.6 en lugar de Opus (Opus consume aproximadamente el doble);
2. Reducir la intensidad de razonamiento o desactivar el pensamiento extendido (extended thinking) cuando no se necesita un razonamiento profundo;
3. No recuperar conversaciones largas inactivas por más de una hora, abrir una nueva;
4. Configurar la variable de entorno CLAUDE_CODE_AUTO_COMPACT_WINDOW=200000 para limitar el tamaño de la ventana de contexto.
No se mencionó ningún tipo de restablecimiento de límites o compensación.
El presentador del podcast de IA Alex Volkov resumió esta respuesta como «no lo estás usando correctamente» (You're holding it wrong), señalando que el propio Anthropic estableció el contexto de 1 millón de tokens como predeterminado, promocionó Opus como su modelo insignia y el pensamiento extendido como una ventaja, y ahora les sugiere a los usuarios pagos que no usen estas funciones.
La afirmación de «no hubo sobrecargos» también entra en tensión con los propios registros de actualización de Claude Code. Justo un día antes de que Lydia publicara su respuesta, v2.1.90 corrigió un error de regresión de caché existente desde v2.1.69: al usar --resume para recuperar una sesión, las solicitudes que deberían haber acertado en la caché provocaban un fallo completo de caché de prompt (prompt cache miss), facturando a precio completo. La respuesta de Lydia no mencionó esta anomalía de facturación confirmada.

Como contraste, OpenAI también tuvo previamente un problema similar de consumo anormal de crédito con Codex. La práctica de OpenAI fue restablecer las cuotas de los usuarios, emitir créditos de compensación y anunciar en marzo la eliminación del límite de uso de Codex. La práctica de Anthropic fue sugerir a los usuarios que degradaran el modelo, desactivaran funciones, limitaran el contexto y atribuir la responsabilidad a la forma de uso del usuario.
Anthropic vende una suscripción al «modelo más fuerte + el contexto más grande + la mayor capacidad de razonamiento», y cobra entre 20 y 200 dólares al mes. Un error de caché que duró 28 días hizo que el crédito de los usuarios pagos se evaporara de 10 a 20 veces más rápido, y la respuesta oficial es que lo uses con moderación.







