Биткоин может достичь отметки в $120 000 в ближайшее время, прогнозируют аналитики QCP Capital в своем новом отчете. 14 ноября первая криптовалюта обновила исторический максимум, достигнув $93 480.
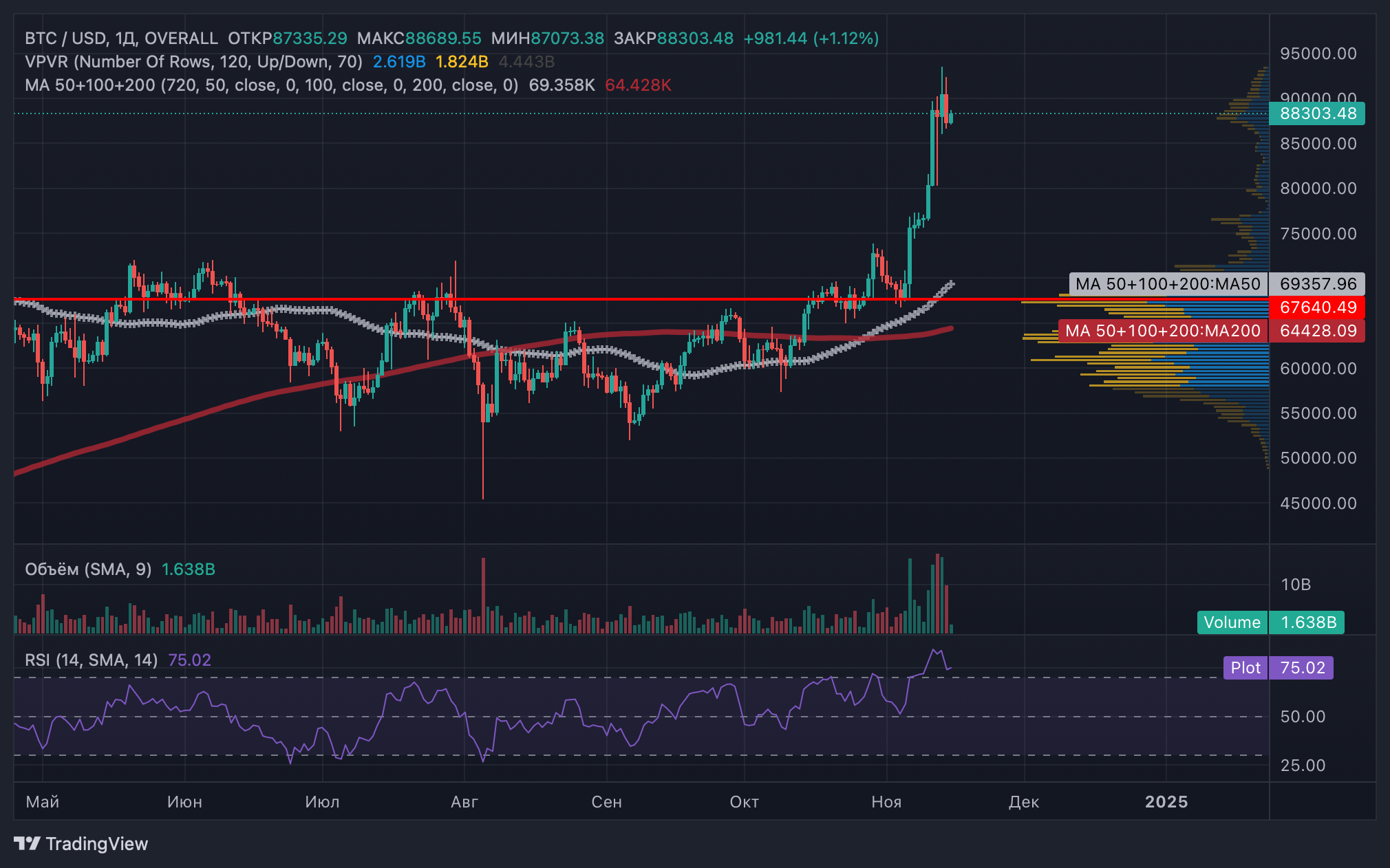
Аналитики QCP Capital отмечают, что общая капитализация криптовалютного рынка превысила $3 трлн, побив предыдущий рекорд 2021 года в $2,77 трлн. Этот рост произошел на фоне публикации данных по потребительской инфляции в США (CPI), которая соответствовала ожиданиям: базовая инфляция составила 3,3%, а общий показатель — 2,6%.
Ожидания рынка
По оценкам QCP Capital, цена биткоина может достичь диапазона $100 000–120 000. Эксперты связывают потенциальный рост с ожиданиями возвращения Дональда Трампа (Donald Trump) в Белый дом и его планами по созданию стратегического резерва биткоина.
Ключевые тренды и риски
Эксперты QCP Capital отмечают несколько важных тенденций на рынке опционов:
- Во время роста цены наблюдается снижение подразумеваемой волатильности, поскольку многие крупные игроки были заранее подготовлены к такому развитию событий
- Крупные игроки активно продают опционы на покупку биткоина по более высокой цене (колл-опционы) и одновременно приобретают опционы на продажу (пут-опционы), чтобы защитить свои позиции от возможного падения цены
- На рынке наблюдается рискованная ситуация с маржинальной торговлей, особенно в альтернативных криптовалютах. Трейдеры активно используют заемные средства, из-за чего ставки по бессрочным контрактам достигают 50-100%
- Существует значительный риск массового закрытия позиций, открытых с использованием заемных средств
Монетарная политика
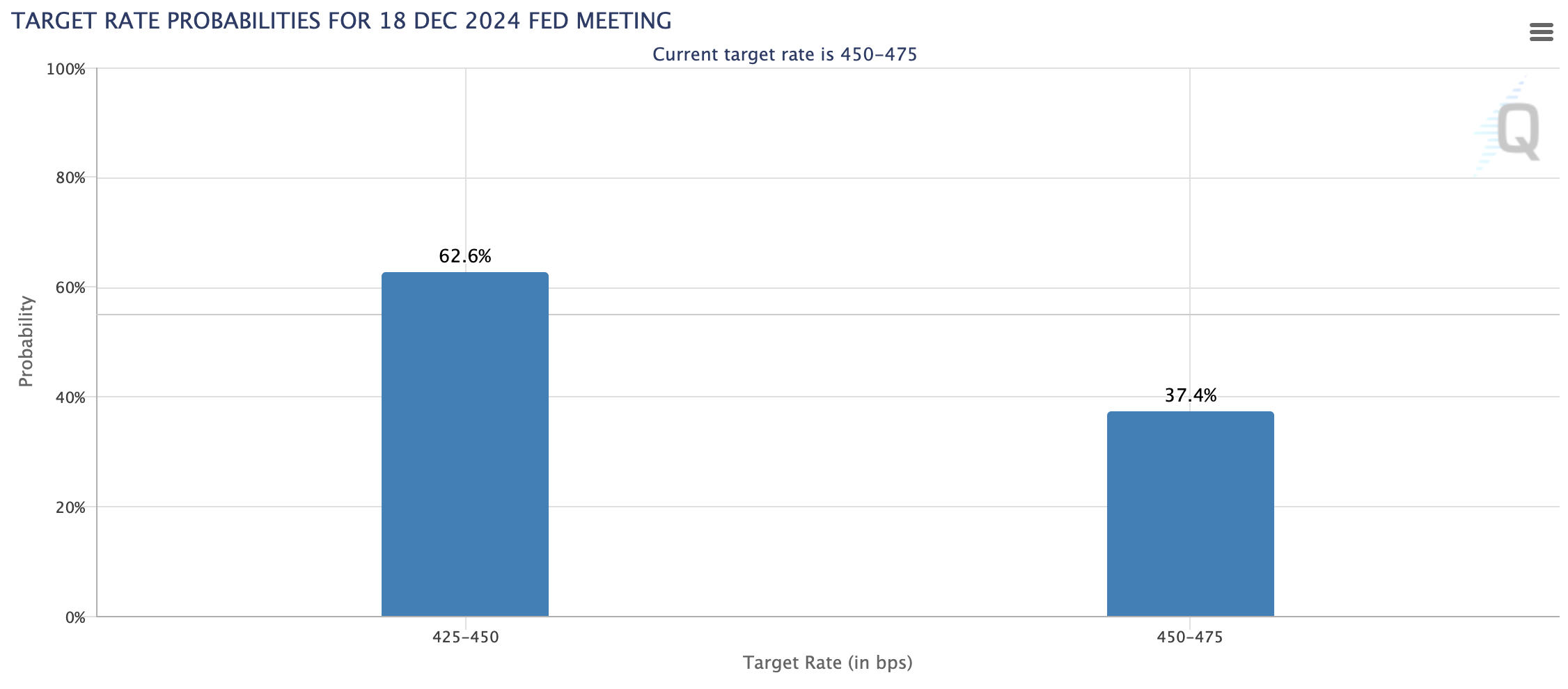
Рынок оценивает вероятность снижения ключевой ставки ФРС на декабрьском заседании в 62,6%. На решение регулятора могут повлиять предстоящие данные по индексу потребительских расходов (PCE) 27 ноября и потенциальные изменения в политике, связанные с возможным возвращением Трампа.
В предыдущем отчете QCP Capital от 13 ноября сказано, что институциональный интерес к криптовалюте продолжает расти — за три дня в биткоин-ETF поступило $2,28 млрд, причем $1,8 млрд пришлось на период после выборов в США. Этот приток средств отражает растущее признание биткоина как казначейского актива среди корпораций, государственных структур и институциональных инвесторов.





