原文作者:hitesh.eth,加密 KOL
原文翻译:金色财经 xiaozou
MATIC 升级为 POL 之后,代币经济学会发生什么变化,对 POL 代币的未来价值有何影响?本文我们来一起探讨一下。
Polygon 在去年的路线图中宣布了两个主要计划。第一个计划是将 Polygon PoS 链升级为 ZkEVM Validum 链,以获得更高的可扩展性、更快的最终确定性,同时可连接 AggLayer。另一个计划是通过 1: 1 的 MATIC-POL 代币迁移来启动 POL 代币。
从 2024 年 9 月 4 日开始,持有者就可以将他们的 MATIC 1: 1 迁移为新的 POL 代币。币安、OKX 等 CEX(中心化交易所)将代表用户处理迁移。
你只需遵循他们的公告,取消所有未结订单,如果你持有 MATIC 的话,那么你将收到的是 POL 代币。
一些 DEX(去中心化交易所)和 DEX 聚合平台将使用自己的 UI 进行 MATIC 到 POL 的迁移,你也可以使用 Polygon 迁移门户或智能合约地址来自己完成此迁移。
有趣的是,代币升级还给代币经济学带来了重大改变,其设计考量还涵盖了未来路线图和价值捕获。
带来了哪些改变?
Polygon 验证者的 Matic 代币通胀奖励在 Polygon 完成通胀周期后于去年结束。
我们都知道,在没有代币奖励的情况下维持网络增长有多么困难,因此他们需要解决这个问题,来保持网络的有序运行以及维持验证者的热情。
每年将有 2 亿枚新代币 POL 投入流通中,用于未来 10 年对验证者的奖励,如果 1 POL = 0.5 美元,那么这 2 亿枚代币的价值就相当于 1 亿美元。
这是他们将获得的标准报酬,但 Polygon 也提供了一些额外奖励,鼓励他们扮演更多角色支持其他链。
Polygon 已经建立了一个 L2 创建技术栈,他们还建立了一个统一的流动性层,称为 AggLayer,这将帮助 L2 通过 Polygon 网络为自己的生态系统提供充足的流动性。
这里的想法非常直接,作为一个质押者,你将把你的权益委托给验证者,验证者将通过通胀周期铸币,他们将从聚合者那里收取费用收入,他们还将从作为 Polygon 网络一部分的 CDK 链中获得额外的代币奖励。
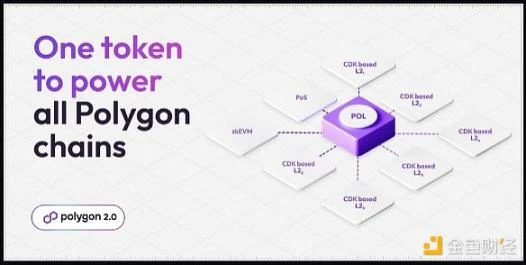
奖励分为两种:
为质押者提供 CDK 链代币奖励
与质押者分享 AggLayer 的费用收益
更多奖励形式还在筹备中:
共享排序收益
零知识证明收益,等等……
这就像是一个验证者支付网络,鼓励他们在不同的时间扮演多个角色。

我们已经讨论了新代币经济学的基础。
代币需求端:
我认为这非常简单——这将是一种由质押驱动的需求。MATIC 持币者只有不到 3.3 万人参与质押,而且由于缺乏奖励,最近的整体质押率一直很低。
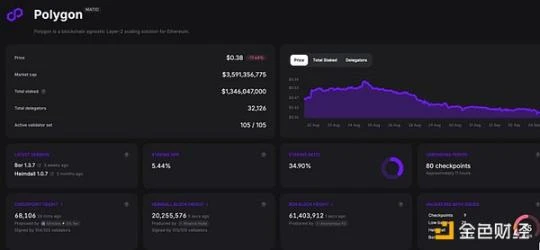
目前的质押收益率在 5.65% 左右,比 ETH 好,但要低于 Solana 和 Avalanche。在 POL 迁移及新的通胀政策激活之后,收益率应该会上升到 7-8% ,并且随着 AggLayer 和 CDK 获取更多的采用,收益率可能还会继续增加。
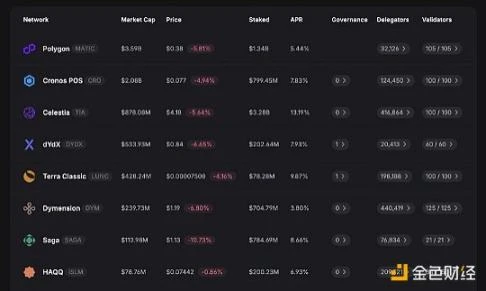
最终,最好的情况是那些 POL 质押者开始以空投的形式获得额外的代币奖励,类似于 Celestia……这种情况发生的几率也相当高。
AggLayer 上已有十多个资金充足的项目,它们可能会在合适的时候进行一些空投。
这类行为将推动 FOMO 的形成,并可能使质押者数量从 3.3 万增加到至少 10 万。Celestia 拥有 40 万名质押者,从中你可以看到质押需求的上升潜力。
总体而言,我认为这是 MATIC 代币升级的好时机,随着 Polygon 的整体技术部署,他们可以通过在他们的关键基础设施产品(AggLayer)上建立更多的合作伙伴关系,推动对该代币的更多需求。





