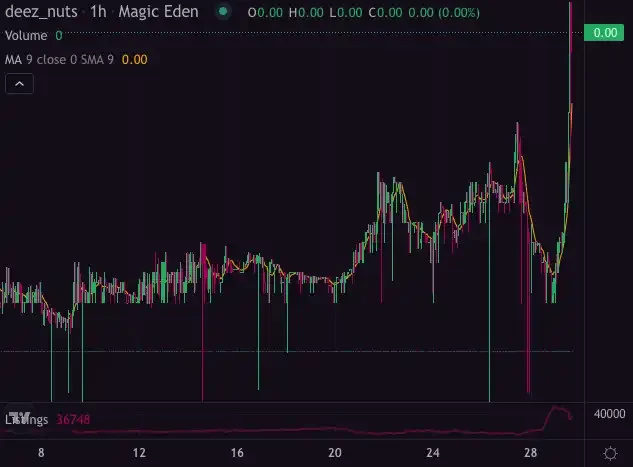
1 月 27 日,Solana 生态新代币标准 Tiny SPL 上线了 AMM 交易。随后,其代币 DN(Deez Nuts)地板价 24 小时涨幅达 185% ,截至撰稿时为 0.004 SOL。
社区首先注意到 Tiny SPL,是因为其曾获得 Solana 联合创始人 Anatoly 转发并置顶在推特主页上,BlockBeats 曾在 1 月 5 日所发布的《被 Solana 创始人推特置顶,新代币标准 Tiny SPL 是什么?》一文中介绍过 Tiny SPL。
Deez Nuts 最初可免费 mint,铸造完毕后,DN 的地板价在突破 0.2 SOL 后急速下跌至不到 0.001 SOL。而近期随着 AMM 交易功能上线,Deez Nuts 的流动性被激活,Tiny SPL 再度迎来了关注。
引入状态压缩方法的 Tiny SPL
Tiny SPL 的特别之处是引入了「状态压缩(state compression)」方法,可以让用户在 Solana 上持有代币时不需要支付存储租金。
租金是 Solana 账户模型中独有的概念。租金与交易费用不同,交易费用是为了处理网络上的指令而支付的。而租金是为把数据存储在 Solana 区块链上所付出的成本。与以太坊不同,Solana 会收取在其网络上的账户一笔用于存储数据状态的费用,即租金。租金按照账户所存储的代币余额大小进行定期收费,如果账户无法支付租金,系统将删除这个账户,以减少为那些不再维护的数据花费存储成本。
资管公司 VanEck 在一篇对 Solana 的估值报告中提到,Solana 上的租金存储费用为每字节 0.00000348 SOL,钱包数据大小为 372 字节,每个活跃钱包持有者必须保留 0.0026 SOL。同样,应用程序和代币智能合约也必须维持这些存储费用。一个像 Serum 这样大约有 340 KB 大小的程序,为了避免支付租金,需要保留 2.4 SOL 的余额。
状态压缩方法是 Solana 在 2023 年 4 月推出的一种存储数据的新方法,可将 Merkle 树的可验证性压缩成一个哈希,允许开发人员在链上存储少量数据并直接在 Solana 账本中更新,大幅降低数据存储成本,同时保持 Solana 基层的安全性和去中心化。这也是为什么 Tiny SPL 的 logo 是一颗倒过来的树。

目前,状态压缩方法已经可大幅降低 Solana 上的 NFT 铸造成本,据 Solana 基金会介绍,截至 2023 年 4 月 5 日,在 Solana 上铸造 100 万个未压缩的 NFT 成本超过 250, 000 美元。而使用状态压缩的 NFT 铸造成本大约是 110 美元。此前,热门 DePIN 项目 Helium Mobile 在迁移至 Solana 时铸造了近 100 万个 NFT,其铸造成本仅需 113 美元。
相关阅读:《详解当前热门 DePIN 项目:Honey、DIMO 以及 Helium(Mobile)》
因此,通过状态压缩功能,Solana 可为创作者和品牌方提供一种无需支付大量成本、就可向更广泛的受众提供大量 NFT 的方法。现在,Tiny SPL 将状态压缩方法应用到了代币资产上,与使用常规 SPL 标准的代币相比,Tiny SPL 代币不需要支付租金。此外,Tiny SPL 代币不会显示在用户的钱包余额中,而是仅在 NFT 部分可见。基于 Tiny SPL 的代币资产为「DN(Deez Nuts)」,因为所对应的图像是两只花生,所以中文社区也称其为「花生」。
用户可以做什么?
目前,Tiny SPL 的流动性池已经启动,支持 Tiny SPL 标准的代币交易。用户进入 https://tinys.pl/,链接钱包,点击 Swap 即可进入交易界面,只需输入需要交易的数额,点击「Swap」交易。
由于 Deez Nuts 可拆分或合并,只有用户持有中最大份额的 Deez Nuts 可进行交易,因此如果要卖出 Deez Nuts,可以提前将 Deez Nuts 进行合并。Deez Nuts 的拆分和合并过程在《被 Solana 创始人推特置顶,新代币标准 Tiny SPL 是什么?》已有介绍。
除了交易,用户还可以将持有的 NUTS 加入到 AMM 池中作为 LP,截至目前已经有超 1300 多个 SOL 被添加到 AMM 池中。贡献者将在 LP 池中锁定 1 个月,之后所得 LP 代币将按比例返还给贡献者。初始 LP 贡献者将赚取代币锁定当月交易量的全部 1% 交易费。
Deez Nuts 的「重生」离不开 Tiny SPL 的创始人sol_idity的努力,推出 Deez Nuts 后,创始人一边开发批量合成和 AMM 交易功能,一边不断呼吁 Solana 上的 DEX 聚合器 birdeye 为 DN 添加索引。得益于创始人和社区共同努力, 1 月 20 日 Deez Nuts 在官推上呼吁筹款后的 24 小时内,就完成了 800 SOL / 400, 000 NUTS 的筹款目标。
据创始人表示,接下来的几周将为 Tiny SPL 代币创建新的实用程序、改进钱包对协议的支持以及开源 Tiny SPL 标准。需要提醒的是,一方面,随着「状态质押」技术展现出更大的应用潜力,Deez Nuts 作为第一个采用这个技术的代币协议,在乐观的投资者眼中拥有「Solana 上的 ORDI」这样的定位。但 Deez Nuts 目前的定位更像是 meme 与 NFT 的结合,尚没有实际应用场景,投资者在进行交易时需谨慎评估风险。





