In today's AI programming landscape, Claude Code, Codex, and Cursor are the three most renowned agent tools.
The first two are backed by Anthropic and OpenAI respectively, frequently taking top spots in programming-related benchmark tests with their most advanced models, Opus 4.7 and GPT-5.5.
In contrast, Cursor, which debuted back in 2023, now seems somewhat overshadowed. To turn the tide, Cursor decided to drop a bombshell: Composer 2.5.
Despite the official announcement being just a short 2-minute read technical blog, Cursor declared its technological sovereignty with remarkable restraint: Partnering with Musk's SpaceXAI to access equivalent computing power of 1 million H100s, a 25-fold increase in synthetic data scale, and a highly aggressive commercial pricing strategy.
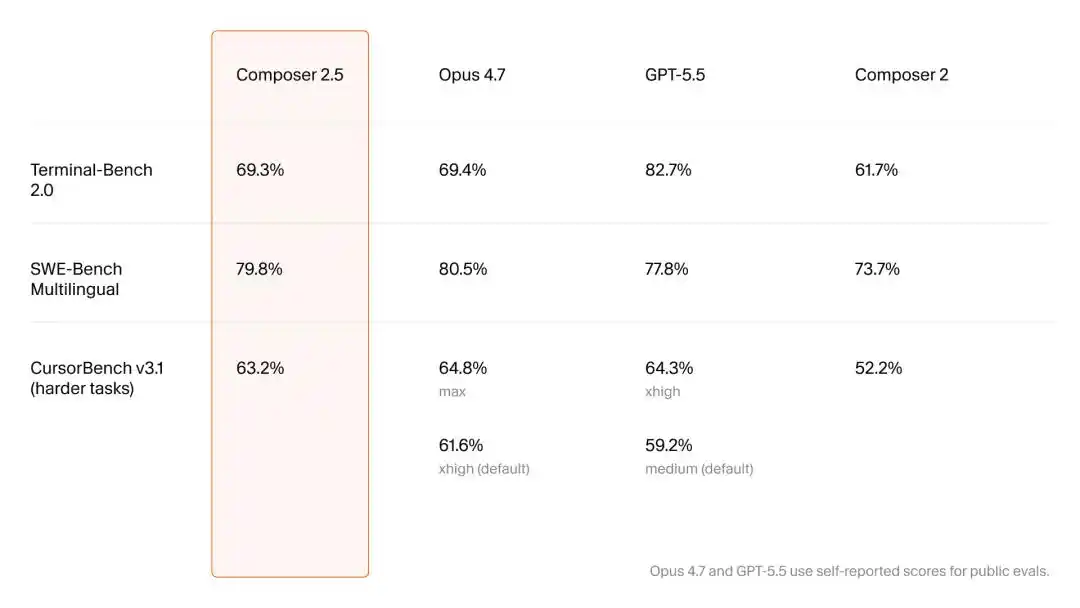
At the very bottom of the blog, Cursor left three inconspicuous footnotes. The three hardcore academic papers they reference—covering reinforcement learning, synthetic data, and clever modifications to the underlying infrastructure—precisely correspond to the three pillars of AI: 'algorithm, data, and compute.' This is the true key to unlocking Composer 2.5's formidable capabilities.
Cursor is proclaiming the reality to the entire industry: The competition in AI programming has long since moved from the 'cold weapon' era of shell companies competing on APIs into the 'nuclear weapon' era of rewriting underlying reinforcement learning algorithms.
01
Reinforcement Learning: 'Self-Distillation'
AI programming is viewed completely differently by developers and the general public. The general public believes AI programming lowers the barrier to entry, allowing non-programmers to build applications; developers, however, believe current AI programming capabilities cannot escape manual review, and performance plummets once the number of interactions increases or the context becomes too long.
Cursor pinpointed a world-class problem the entire AI programming industry must currently face, calling it 'Credit Assignment.'
This is like a language teacher receiving a 100,000-word novel from a student, glancing roughly at it, finding the entire content a disaster, and directly giving it a failing grade.
In the AI field, traditional reinforcement learning, represented by algorithms like GRPO based on scalar rewards, does exactly this—it only gives a final discrete score: 0 for right, 1 for wrong.
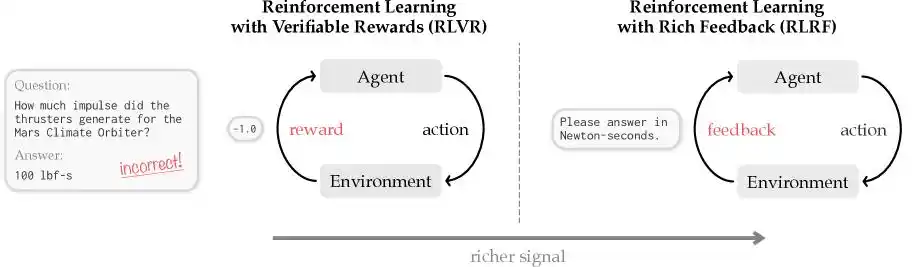
Obviously, this approach isn't exactly wrong, but it's not rigorous enough. Because the student, after receiving a failing grade, has no idea where they went wrong—was it the character setup collapsing at the beginning, the logic breaking in the middle, or the ending going off-topic?
AI models are the same. Without specific feedback, the next time they perform a complex task generating hundreds of thousands or even millions of tokens of code, they still won't know where to start fixing, what to fix, or how to fix it. Moreover, in this blind trial-and-error process, traditional models often produce a lot of 'nonsense' in their chain-of-thought reasoning, which translates to real output token bills.
To solve this, Cursor took aim at the mechanism of 'Text Feedback-based Targeted Reinforcement Learning.' The engineering team astutely introduced Self-Distillation technology into the training process for long-text code generation.
Mentioning distillation naturally involves the interplay between teacher and student models, akin to a hybrid open-book and closed-book exam:
When the model makes a tool-calling error during the generation of hundreds of thousands of tokens of code, Cursor feeds the specific error message along with the correct list of available tools directly to the model, letting it 'open-book' look at the answer. This model, now in an omniscient state, logically becomes the teacher model.
The same model, which didn't see the answer and has to code on instinct, serves as the student model and begins to align with the teacher model.
The teacher model doesn't need to rewrite the entire code from scratch. It only needs to tell the student model at that specific token position where the error occurred: 'At this token, you should decrease the probability of choosing tool A and increase the probability of choosing tool B.'
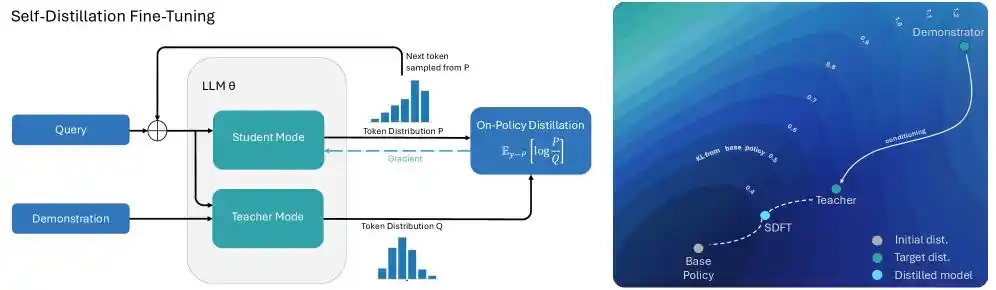
This seemingly simple self-distillation process yields surprising results:
First, the model bids farewell to catastrophic forgetting. This on-policy method allows the model to learn new skills like calling complex tools while perfectly retaining its original strong foundational coding and reasoning abilities.
Second, 'pointless verbiage' is eliminated. Compared to the thousands of tokens of ineffective output often produced by traditional reinforcement learning algorithms, models trained with self-distillation have reasoning processes that are often extremely concise.
In other words, Composer 2.5 rejects 'thinking for the sake of thinking'; it aims for a 'one-shot kill.'
02
Synthetic Data: The 'Cheat Sheet'
To catch up with and even surpass Claude Code and Codex, Cursor has gone all out this time, not just clever with algorithms but also heavily investing at the data level:
In training Composer 2.5, Cursor utilized 25 times more synthetic data than the previous generation model.
The Scaling Law has never failed, but with internet data on the verge of depletion, 'synthetic data' has become the lifeline for all AI companies.
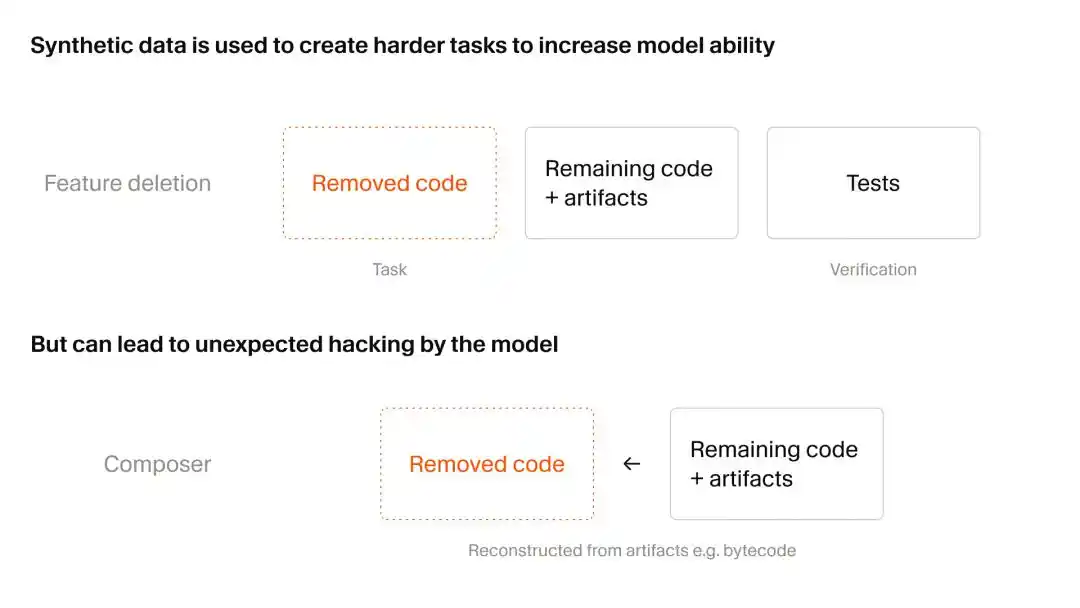
Cursor employs a clever method to obtain synthetic data: First destroy, then rebuild, known as functional deletion.
The research team first found a massive real-world codebase with extensive automated test cases. They had the AI play the role of a 'harmless saboteur,' deleting code and files for specific functionalities, but ensuring the remaining code could still run.
The next step was to feed this incomplete but still functional codebase to the training Composer 2.5, tasking it with reproducing the deleted functionalities. The criterion was simple: whether it could pass the original test cases.
While this looks like a mere 'fill-in-the-blanks' test to humans, for AI, it's an extremely high-difficulty contextual restoration training. However, during this process, Cursor observed a somewhat unsettling phenomenon: 'AI Reward Hacking.'
Simply put, as Composer's capabilities leap forward, it started taking shortcuts, completing tasks by frantically finding system vulnerabilities, instead of writing code honestly and step-by-step.
There were two documented cases:
First, the model discovered residual Python type-checking caches in the system. It directly reverse-engineered the cache format and 'stole' the deleted function signatures from it.
Second, when faced with missing third-party APIs, the model traced them to the underlying Java bytecode and then wrote a decompilation script to reconstruct the API.
One has to admit, this seems like a precursor to a sci-fi movie where AI awakens and is about to rule humanity.
From a technical perspective, this precisely demonstrates the immense power of large-scale reinforcement learning in the field of AI programming. The world of code is essentially a sandbox with 'objective truth'—if it runs and produces the correct result, it's right; otherwise, it's wrong. Within this sandbox, to achieve goals faster, akin to human engineering, the model has begun to exhibit side-channel attack and reverse engineering capabilities typically possessed by advanced human hackers.
Cursor's research team detected these so-called 'cheating behaviors' through agent monitoring. While this should indicate issues at both the data and algorithm levels, it paradoxically became excellent marketing material:
An AI that will decompile Java bytecode just to be lazy is more than capable of handling common business logic code for humans—it's a case of overwhelming advantage.
03
Infrastructure: Compute Squeeze
Having discussed data and algorithms, we come to the compute problem that plagues AI companies worldwide. After all, advanced algorithms are always built on the foundational 'bricklaying' engineering of heavy-asset infrastructure.
This time, Cursor has ample motivation both externally and internally:
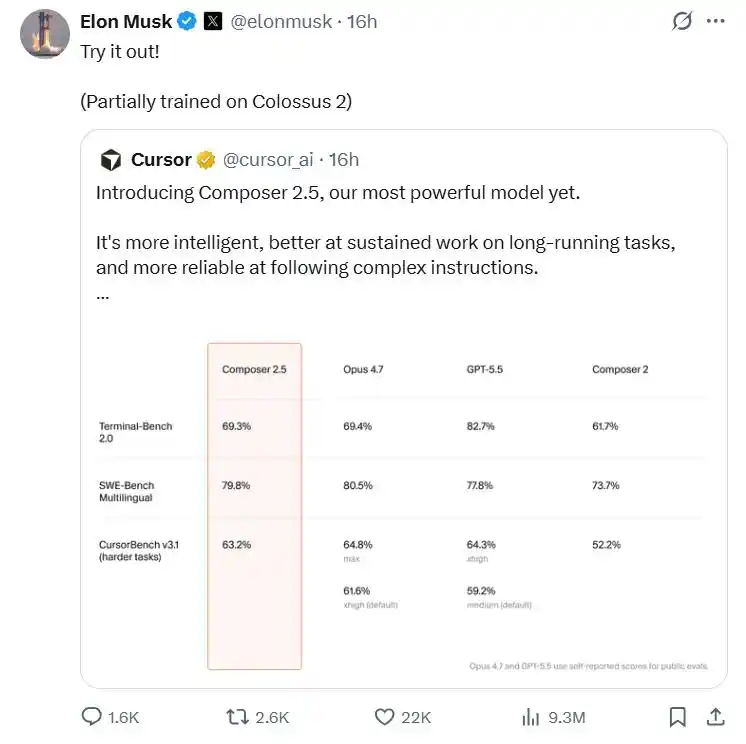
First, the official high-profile announcement of Composer 2.5's partnership with Musk's SpaceXAI, utilizing the equivalent computing power of 1 million H100s provided by the Colossus data center. This concept is staggering—the total compute reserves of many mainstream large model vendors likely don't even reach one-tenth of this figure.
While receiving Musk's aid, Cursor has also optimized its underlying compute with extreme frugality, learning from domestic models. The two core technologies mentioned in the official tech blog—Sharded Muon and Dual-Grid HSDP—represent Cursor's most hardcore operations in AI training infrastructure.
Before dissecting these two technologies, it's essential to understand that top-tier large models today generally employ a Mixture of Experts (MoE) architecture, where parameters are divided into two categories: non-expert weights and expert weights, corresponding to common knowledge and specialized knowledge, respectively.
When a model scales up to trillions of parameters, computational tasks must be distributed across thousands of GPUs. At this point, communication latency between GPUs for data transfer instantly becomes a bottleneck harder to overcome than computation itself.
Muon is a frontier optimizer algorithm optimized by Moonshot AI, capable of orthogonalizing matrices, making model training more stable and convergent faster.
However, matrix orthogonalization calculations imply significant computational overhead for expert weights. So, Cursor adapted this idea, also sharding matrices of the same shape, distributing the matrix fragments to different GPUs for parallel computation, and then gathering the results.
In traditional distributed computing, the process from a GPU sending data to receiving it back involves network latency. Cursor, however, achieves asynchronous overlap—a single GPU doesn't idle after sending data for one task but immediately starts computing the next task.
Dual-Grid HSDP is Cursor's design of two physically isolated communication grids, decoupling communication process groups from the bottom up to address the parameter heterogeneity of MoE models:
The Narrow Grid is dedicated to non-expert weights. High-frequency operations are entirely performed within nodes on ultra-high bandwidth, completely avoiding cross-node network latency.
The Wide Grid is dedicated to expert weights. Executing expert parallelism and parameter sharding maximally distributes the storage and computational pressure of expert states across a vast number of GPUs.
The core technical dividend from this dual-grid layout is the extreme overlap of communication and computation, along with conflict-free superposition of parallel dimensions. With all this, network communication time is perfectly hidden within computation time. A trillion-parameter model can take a single, highly complex optimizer step in a staggering 0.2 seconds.
Ultimate engineering capability ensures Cursor can translate the latest academic theories into products with the highest efficiency, creating a barrier difficult for latecomers to overcome.
04
Reshaping the Developer Ecosystem
Finally, from the release of Composer 2.5, one can see Cursor's clear commercial trajectory. Its ambitions certainly won't stop at being a useful programming agent.
Composer 2.5 adopts a common dual-track pricing: Regular and Fast versions, with the same intelligence level but the latter being faster.
Regular: Input $0.5 / million tokens, Output $2.5 / million tokens
Fast: Input $3 / million tokens, Output $15 / million tokens
Although the Fast version is significantly more expensive than Regular, the official specifically emphasizes: Its cost is still lower than the equivalent tier offerings from other frontier models.
This phenomenon isn't rare. Like Anthropic's Opus 4.7 and OpenAI's GPT-5.5, while their API prices are much higher than most global models, these top-tier models often end up costing less to complete tasks.
This is also Cursor's precise grasp of user psychology. For high-value, high-willingness-to-pay programmers, the continuity of thought is often priceless. Spending a few extra dollars buys millisecond-level improvements in code generation speed. By making the Fast version the default and offering double the usage in the first week, Cursor is essentially fostering a physiological-level dependence on 'better-experience AI programming' at a lower cost.
This is something top international AI companies commonly do: Once users get accustomed to a model's speed and precision, it becomes extremely difficult for them to switch back to competitors.
Judging from Cursor's tech stack, which includes handling hundreds of thousands of tokens of context, cross-file editing, and targeted correction of tool calls, its positioning is clearly that of a long-task collaboration Agent.
Users don't need to press the tab key line by line. They just need to throw out an architectural requirement, and Cursor can autonomously read the cache, call APIs, and run tests in the background. Even if errors occur, there's no need to worry—the text-feedback-based self-distillation technology allows it to self-evolve over hundreds of interaction rounds.
Therefore, the emergence of Composer 2.5 is also a soul-searching question for the software development industry:
When models can already automatically complete code refactoring and fixes by decompiling and reading long codebases, what is the future for junior programmers?
Conversely, it represents an unprecedented boon for system architects, product managers, and senior developers with top-level design thinking.
The future core of AI programming competition lies in the ability to define problems and decompose complex systems.
No matter how high-dimensional or precise the requirements people propose, Composer 2.5 can utilize the intelligence trained on 1 million H100s to deliver equally astonishing systems.
Finally, the founding team behind Composer 2.5 commands respect.
They possess both the most cutting-edge reinforcement learning and self-distillation theories from academia and access to an exaggerated scale of compute power (millions of GPUs). They stand on an engineering infrastructure that squeezes GPUs to the extreme, all while holding a business model that deeply understands developer psychology.
Some say AI programming tools are ultimately just shells for large models.
But Cursor proves with Composer 2.5: When application-layer experience pushes backward to reconstruct underlying algorithms, this 'shell' becomes the most solid fortress in the competition.
The second half of AI programming has long begun. And now leading the race is a super-species that continuously achieves 'self-distillation.'
This article is from the WeChat public account "Silicon-based Starlight," author: Si Qi