[Introduction] At the just-concluded WWDC, Siri's rebirth powered by AI was a key topic, and 'on-device models' have become a trend! Earlier, Andrej Karpathy called for stripping models of knowledge, retaining only the 'cognitive core'. A Chinese company claims to have realized this direction—4B parameters, achieving performance akin to trillion-parameter large models in collective intelligence tasks. What can on-device cognitive models truly change?
Last night, Siri was reborn with the help of Google's 1.2 trillion-parameter Gemini.
However, on the other hand, Amazon shut down its highly controversial internal AI leaderboard—employees extensively used AI tools, causing computing costs to skyrocket to a point where management could no longer ignore it.
Token cost has become the hardest barrier to large-scale AI adoption.
Andrej Karpathy previously suggested a direction in an interview: strip the massive knowledge from the model, leaving only a 'cognitive core' capable of thinking, planning, and knowing what it doesn't know—1B-level parameters would suffice.

https://www.youtube.com/watch?v=lXUZvyajciY
This direction is being validated.
A 4B-parameter model has achieved results equivalent to trillion-parameter large models like GPT-5.4 in collective intelligence tasks, and supports on-device deployment.
It comes from a founding team that previously topped the Japanese Hugging Face leaderboard with a 3.6B model defeating the 65B Llama.
This time, they have created the industry's first on-device cognitive model.
Karpathy's Prediction and the Bill for Compute
The pressure of compute costs has shifted from a technical issue to a financial one, with Amazon's case being just the tip of the iceberg.
Amazon employees frequently used internal AI tools to call upon large model inference capabilities, driving up overall compute expenditures, forcing management to urgently halt the leaderboard mechanism to curb usage.

https://www.ft.com/content/b1a62a7f-6df5-4c90-94ce-64ce9c9961b6?syn-25a6b1a6=1
The industry is experiencing its first 'Token retreat,' with the daily compute consumption of some companies reaching the hundred-million-yuan level.
The business model of large models is hitting a structural wall: the more powerful the capability and the deeper the reasoning chain, the higher the cost per call.
GPU Cost / Revenue is a key metric for all AI companies, and the trend of continuously expanding model parameters only worsens this ratio.
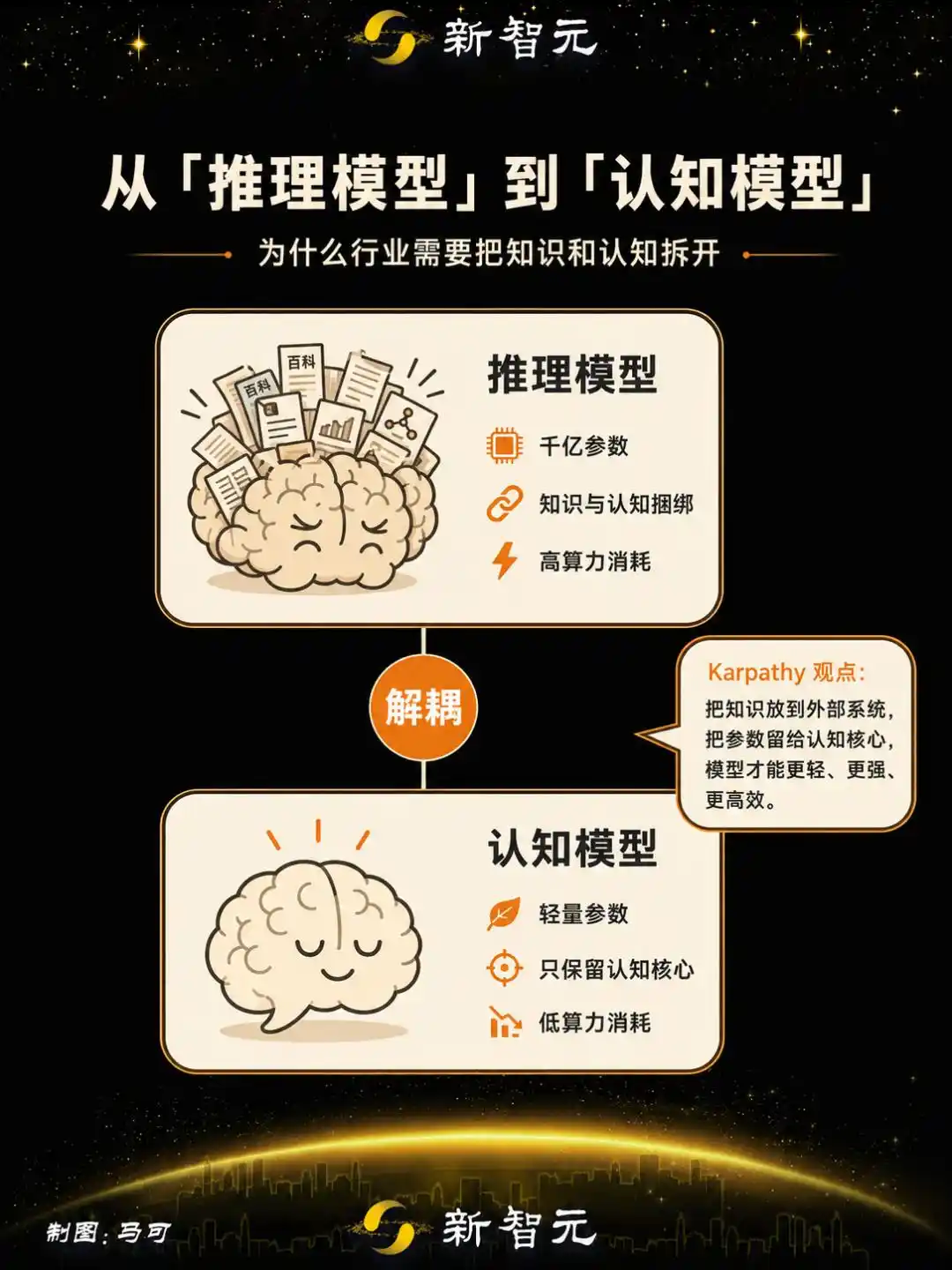
Karpathy's thinking points to another path: he proposed the need to strip 'memory/knowledge' from models, retaining what he calls the 'cognitive core'—
An entity stripped of massive facts and knowledge, but retaining thinking algorithms, intelligent magic, and problem-solving strategies.
He believes that even at a scale of 1 billion parameters, efficient human-like thinking can be achieved:
It will think like a human... If you ask it a factual question, it might need to look it up—it knows it doesn't know and will go check.
This statement sparked widespread discussion in the tech community.
Consensus on the direction is forming, but teams that can push the 'cognitive core' from concept to deployable product are the real variables.
4B Matches Trillion-Parameter: What Nextie Alpha Has Done
The entity that pushed Karpathy's described 'cognitive core' from concept to product is Nextie.
This company conducted reinforcement learning training on open-source reasoning models, decoupling knowledge from cognition—stripping the model of memorized knowledge reserves while enhancing generalization and abstract thinking capabilities.
The resulting model is named Nextie Alpha, with a parameter scale of 4B. It has completed training and been deployed, making it the industry's first product defined as a 'cognitive model'.
Specifically regarding its training method, it actually starts from an uncommon origin.
The Nextie team compiled human academic papers from 1800 to 2020, spanning 220 years, attempting to trace the evolutionary trajectory of collective intelligence as a reference for their technical roadmap.
Based on this research, they performed reinforcement learning on open-source reasoning models, focusing on improving generalization and abstraction capabilities.
To give an intuitive example: the trained model can transfer a Go player's decision-making patterns to daily life scenarios—Karpathy's idea of 'retaining thinking algorithms' finds concrete technical implementation here.
In terms of effectiveness, Nextie Alpha achieved output quality equivalent to large models like GPT-5.4 in collective intelligence tasks (debate, reflection, challenge, voting, etc.) with 4B parameters, offering significant advantages in compute consumption and inference speed.
More noteworthy is the application space unlocked by this model, with three layers of progressive significance.
First layer: improvement in multi-agent decision-making quality.
Within the Harness decision-making framework, using the cognitive model yields better output than using a reasoning model.
Upgrading the underlying model from 'reasoning' to 'cognition' brings a leap in the overall quality of the decision-making chain within multi-agent collaborative systems.
Second layer: orders-of-magnitude reduction in compute costs.
4B compared to trillion-parameter models drastically reduces compute overhead for cloud deployment.
Nextie Alpha also supports on-device deployment—it can run directly on MacBooks, embodied intelligence devices, etc., converting compute costs into electricity costs.
This is particularly significant for the field of embodied intelligence: using a trillion-parameter model to drive a household robot consumes large amounts of Tokens with every 'thought,' potentially making the comprehensive cost higher than hiring a human. 4B on-device deployment fundamentally rewrites this equation.
Third layer: unlocking proactive scenarios.
Currently, the vast majority of AI products operate in a reactive mode—the user gives a command, the model responds.
Proactive mode means the agent makes decisions and executes tasks autonomously, without waiting for commands. The commercial scale of proactive mode far exceeds that of reactive mode but has always been blocked by compute costs in the past.
Nextie Alpha supports 24/7 operation at a controllable cost, making previously shelved proactive agents—deemed too expensive—possible.

Team's Trump Card and Positioning in the Race
Nextie was founded by the founding team of Microsoft Xiaoice.
This team's signature is 'winning with small parameters against large parameters'—their previously trained open-source model rinna (Japanese Xiaoice) topped the Japanese Hugging Face leaderboard with 3.6B parameters, defeating the 65B Llama.
Nextie Alpha achieving effects comparable to trillion-parameter models with 4B continues the same technical lineage.
Nextie is heavily investing in the track of—Harness group multi-agent.
This track is gaining validation from top-tier capital—in March 2026, OpenAI invested in the startup Isara, directly pushing its valuation to $650 million. Isara's research focus is precisely multi-agent collaboration and collective intelligence.

https://www.wsj.com/tech/ai/openai-backs-new-ai-startup-seeking-bot-army-breakthroughs-a0b1fedc
In intelligent depth evaluations (IDI) for this field, Nextie's comprehensive performance is significantly higher than any single large model.
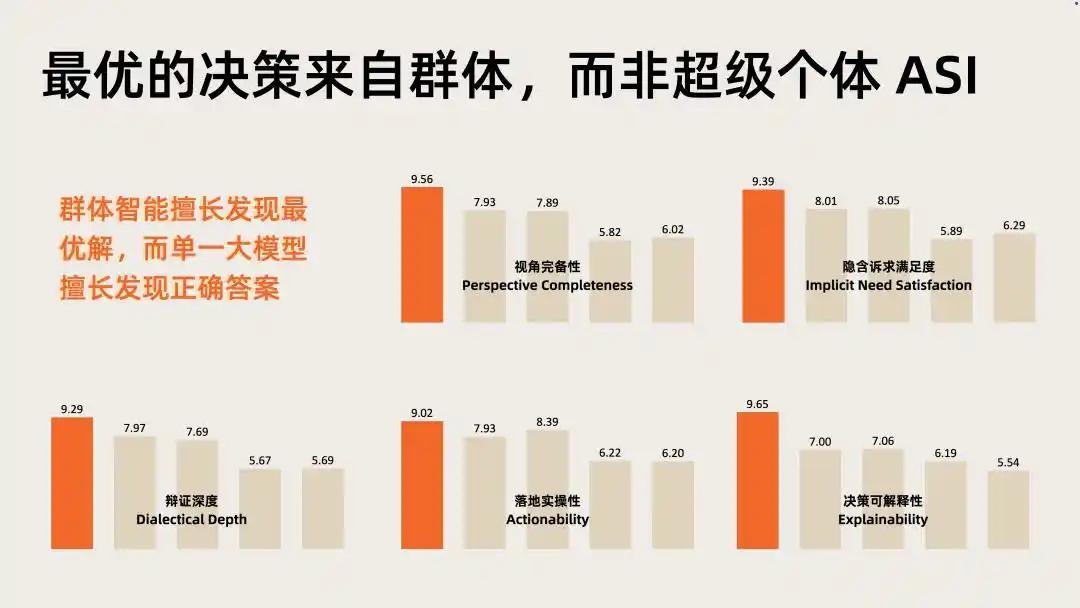
Capital validates the track's value, while evaluation data pinpoints Nextie's position within it.
The combination of these two signals points to the same judgment: group multi-agent is the next high-value direction in the AI application layer, and cognitive models are the key infrastructure driving it.
Cognitive Models Change Not Just Parameters, but the Ledger
GPU Cost / Revenue is the sword of Damocles hanging over all AI companies.
The solution provided by cognitive models fundamentally points to the reconstruction of the economic model—achieving with 4B what previously required trillion parameters means an entirely different cost structure for the same output quality.
Nextie revealed in an interview that the team is training a more generalized 8B cognitive model.
If 4B can already match GPT-5.4 in collective intelligence tasks, the capability boundaries of 8B are worth anticipating.
A more profound question is left for the entire industry: When the cost of running a cognitive model on-device 24/7 drops to a negligible level, all AI products designed today based on the 'user commands, model responds' reactive model may need to re-examine their product forms.
The commercial imagination space for proactive agents far exceeds everything under the current reactive agent paradigm.
This article is from the WeChat public account 'New Zhiyuan', author: ASI启示录






