According to statistics, the total financing in the domestic embodied intelligence field this year has exceeded 37 billion yuan.
The Ministry of Industry and Information Technology and the State-owned Assets Supervision and Administration Commission jointly launched the 'Humanoid Robots and Embodied Intelligence Real-World Training Special Action', with China National Radio News directly labeling this year as the 'critical year for commercialization and implementation'. Funding from the primary market and narratives from the secondary market are all pointing in the same direction: implementation, implementation, implementation.
But here comes the question: How should embodied intelligence be implemented?
A widely accepted viewpoint is that embodied intelligence should tackle tasks that humans cannot do and replace humans in performing high-risk, heavy, repetitive jobs that people don't want to do and shouldn't be doing.
On June 22nd, the 4th China International Supply Chain Expo (CISCE) opened in Beijing, featuring a dedicated artificial intelligence zone for the first time.
However, ideas are one thing; for robots to truly 'enter' these scenarios, the first barrier is enough to deter most companies: explosion-proof certification.
In flammable and explosive environments such as gas stations, oil and gas stations, and chemical plants, robots themselves absolutely must not become potential ignition sources. This imposes extremely stringent requirements on the hardware's design from the very beginning. For example: the circuit level must adopt an intrinsically safe design, limiting loop energy to ensure it cannot ignite environmental gases even in case of a fault; mechanical structures must meet flameproof requirements to withstand internal explosions without damaging the housing; all connection points must be made increased-safety to prevent spark risks during normal operation; key components must also be isolated from hazardous contact through encapsulation, etc.

Where Can Embodied Intelligence Go
The challenge for robots in this scenario lies in the 'coherence of fine operations.' After the customer places an order, the robot must sequentially perform over ten actions: opening the outer cover, unscrewing the inner cap, detaching the nozzle from the pump, aiming and inserting it into the fuel filler neck, waiting for the tank to fill, removing the nozzle, hanging it back on the pump, closing the inner cap, and closing the outer cover. The tolerance for each action is only a few millimeters; getting stuck at any step means the entire chain is interrupted. Moreover, different vehicle models have vastly different fuel tank locations, cover structures, and opening methods. A robot cannot rely on fixed programs to handle all situations.
The pain points of station patrol inspections are entirely different from those of gas stations. Gas stations test fine operation, while station patrols test the comprehensive capability of 'long-duration autonomous patrolling + multi-type anomaly recognition + on-site immediate response.' Inspectors walk fixed routes daily—a job that is dull, dangerous, and requires extremely high concentration. The error rate of humans increases significantly after several hours of continuous inspection.
Port Scenario: Exploring Multi-Robot Collaboration
The most unique aspect of this scenario is that it naturally requires multiple robots to collaborate.
Currently, most embodied intelligence system architectures are 'pipeline-style,' where the vision module is responsible for seeing, the language module for understanding, and the action module for execution.
This architecture might handle simple tasks with short sequences and low interference, but once faced with scenarios requiring dozens of consecutive steps, highly dynamic environments, and extremely low fault tolerance, even minor deviations at any intermediate step propagate like dominoes. Traditional pipeline architectures are almost incapable of ensuring end-to-end stability in the face of tasks at this scale.
World Model-Driven Predictive Capability
In the gas station scenario, the task chain faced by embodied intelligence is extremely long: guiding the vehicle, identifying the fuel tank location, opening the outer cover, opening the inner cap, retrieving the nozzle, aligning with the filler neck, inserting, fueling, removing, returning the nozzle, closing the inner cap, closing the outer cover. Minor deviations at any step propagate backward.
This capability is particularly crucial in long-sequence tasks. Refueling is not a simple 'grasp-and-place' operation; it's an entire chain of actions with causal relationships. The world model enables embodied intelligence to possess the forward-looking ability of 'looking three steps ahead before taking one.'
To understand with a metaphor: When an experienced driver refuels, regardless of how smoothly the fuel cap opens, their mind always knows the final state to achieve, adjusting every intermediate step toward that end state. It shifts embodied intelligence from 'linear execution' to 'goal-state alignment.'
First, generate the target observation. After receiving the task instruction and the current camera feed, the system first predicts 'what the world should look like after the task is completed.' For example, after a refueling task, the nozzle should be returned and the fuel cap closed. This predicted 'final-state image' becomes the target observation, providing a clear semantic anchor for all subsequent reasoning processes.
Second, synthesize intermediate transition frames. With the goal established, the system then infers the visual states that should occur in between. If the starting point is 'fuel cap closed' and the endpoint is 'nozzle returned, fuel cap closed,' then intermediate states like 'fuel cap opened,' 'nozzle retrieved,' 'nozzle inserted into filler neck' need to appear sequentially. These synthesized intermediate observation frames provide stepwise-aligned visual references for action generation.
This mechanism allows the robot to have a complete visual imagination of the entire task process before acting. Subsequent action planning revolves around this 'imagined trajectory,' significantly reducing cumulative deviation during long-sequence execution.
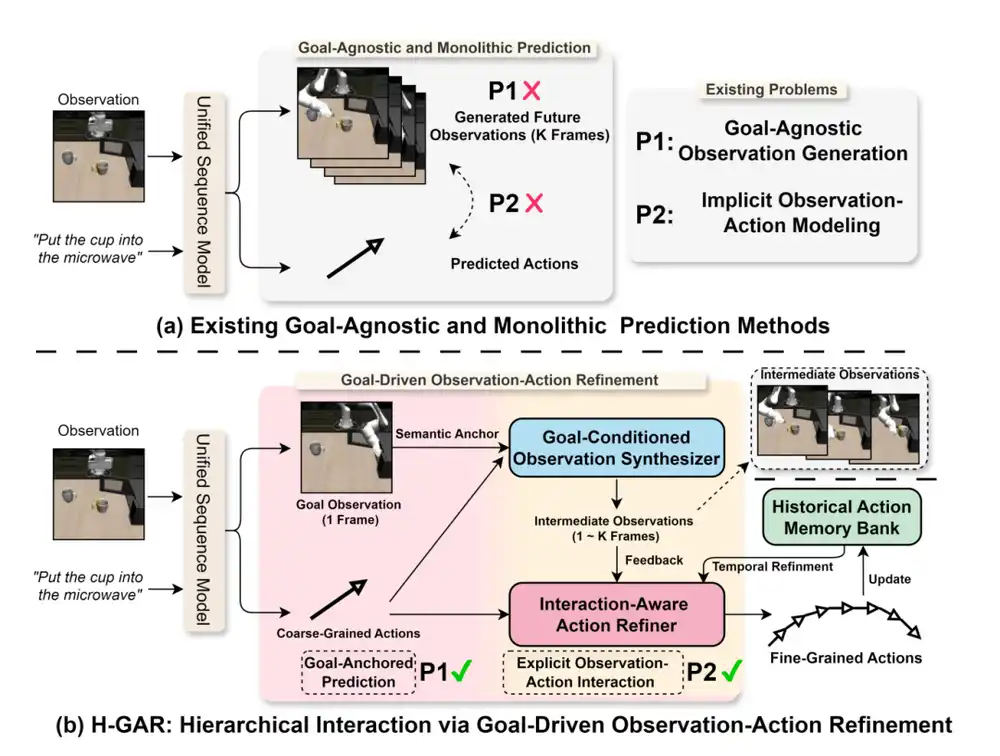
(a) Existing methods typically employ a goal-agnostic, holistic prediction paradigm. (b) H-GAR introduces a Goal-conditioned Observation Synthesizer and an Interaction-Aware Action Refiner, thereby achieving goal-anchored prediction and explicitly modeling the interaction between observations and actions.
Specifically, the workflow of H-GAR is divided into three steps:
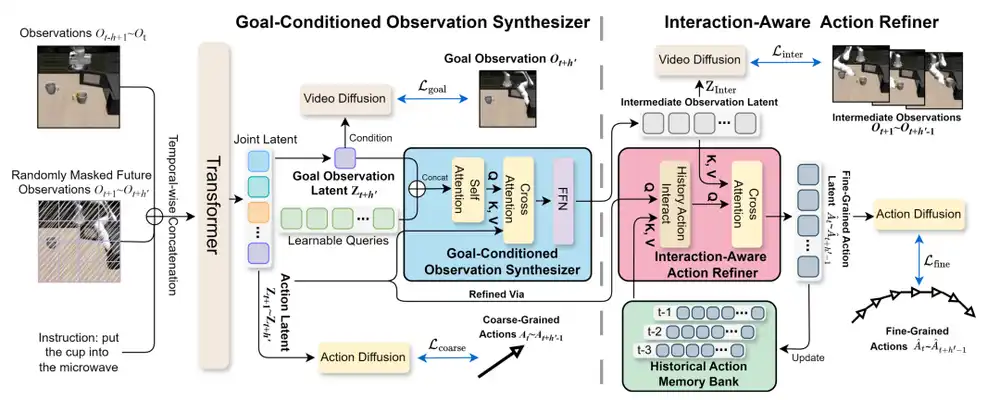
H-GAR Architecture Diagram
Step 1: Coarse-grained action draft. Based on historical frames and task instructions, the system first generates a set of coarse action sequences. These actions describe a 'rough path' from the current state to the goal, similar to a human driver's rough mental plan before refueling, knowing roughly which steps to take—the preparation before execution.
Step 2: Goal-conditioned Observation Synthesis (GOS module). After obtaining the coarse actions, the system synthesizes intermediate visual frames guided by the target observation. The key here is that the synthesized frames are not generated arbitrarily but are constrained by both the final goal state and the coarse actions. This ensures the intermediate transition frames align with both action logic and the final goal.
Step 3: Interaction-Aware Action Refinement (IAAR module). The final step refines the coarse actions into fine-grained executable commands. IAAR refines actions using feedback from two directions: first, the visual context provided by intermediate observation frames, aligning actions with the actual scene; second, a historical action memory library, which records previously executed fine-grained actions, ensuring the currently generated actions maintain temporal consistency with the historical trajectory. When the memory library exceeds its capacity threshold, the system employs a similarity-based eviction strategy, merging the most similar adjacent actions to preserve memory diversity.
Paper address: https://arxiv.org/pdf/2511.17079
Unexpected events are almost the norm in real-world scenarios. The fuel cap might not open at the right angle, the customer might park slightly off the expected position, or there might even be obstructions around the filler neck. An action that succeeds 99 times out of 100 in the lab might see its success rate drop by 30% when deployed in outdoor, real environments.
Epilogue: Unity of Knowledge and Action
Guiding embodied intelligence into specialized scenarios is an endeavor that requires a long-termist mindset.
To enter specialized industries, mechanical structure design must consider safety from the ground up, requiring the capability to develop the embodied platform itself. To execute tasks in special environments, an embodied brain is indispensable. The deep coupling of brain and platform has moved beyond being a plus; it is the entry requirement.
As the embodied intelligence industry collectively stands at the crossroads of commercialization and implementation, those players who have first established the closed loop of 'brain-platform-data' will most likely gain a competitive edge in the upcoming race.
This article is from the WeChat official account: 机器之心 , Editor: Cold Cat, Author: Focus on Embodied Intelligence, Original Title: 'Domestic First Explosion-Proof Certification, World's First Fueling Brain Solution: How Did They Secure Two 'Firsts'?'
![Assessing Sonic’s [S] 12% price drop and why more selling may be next](https://d1x7dwosqaosdj.cloudfront.net/images/2026-06/161e3d66eea4402796d2e6a66d93d453.jpg)





