仿生人会做梦吗?如果他们做梦的话,会梦见电子羊吗?

电影《银翼杀手》截图
1968 年,科幻电影《银翼杀手》的原著小说作者菲利普·K·迪克,在打字机前敲下这个抽象又超前的问题时,他大概不会想到,半个多世纪后,硅谷的科技巨头们会一脸严肃地给出答案。
会,他们不仅能梦到电子羊,还能把梦可视化。
昨天,Anthropic 在旧金山的开发者大会上,发布了智能体构建平台 Managed Agents 的一系列新功能,记忆扩展、结果输出、多智能体协作,以及「做梦 Dreaming」。
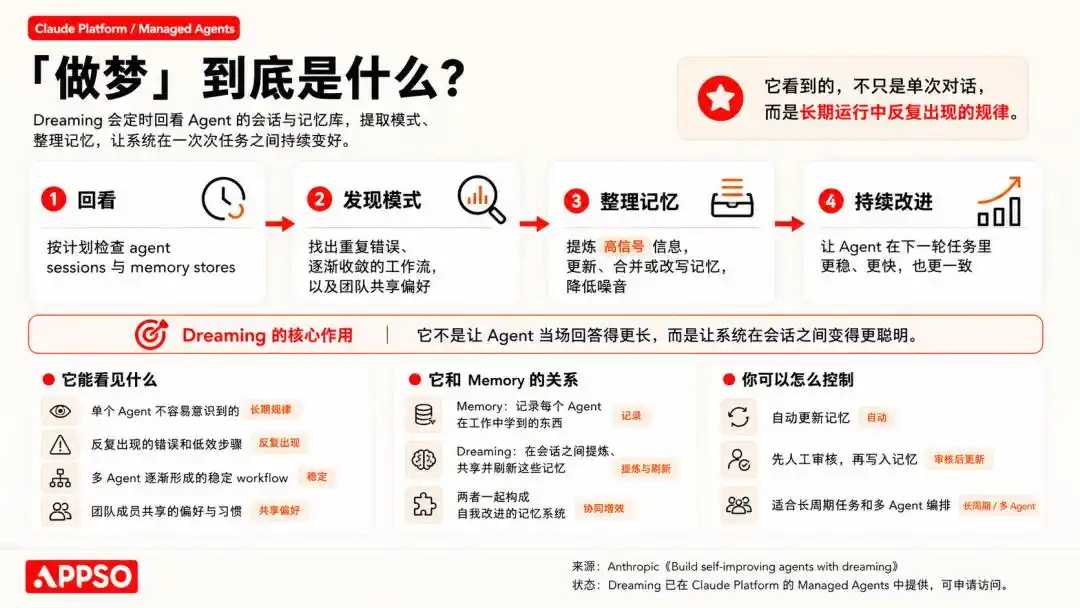
按 Anthropic 自己的说法,「memory(记忆)和 dreaming(做梦)共同构成了一个稳健的、能够自我改进的 agent 记忆系统」。

又是做梦,又是记忆,对 AI 领域不太关注的朋友,大概都会满头问号,这些属于人类的词语,什么时候开始可以如此丝滑地套用在 AI 身上了。
早在 2024 年 OpenAI 推出 o1 系列时,「一系列被设计成在回应前花更多时间思考的 AI 模型」,「思考」二字用得极其自然,自然到没人停下来追问一句,一个统计预测下一个 token 的程序,凭什么叫思考?
紧接着是 reasoning(推理)、memory(记忆)、reflection(反思)、Imagining(想象),一个一个把人类才会做的事情,挨个搬到产品发布会上。

探讨梦的电影《红辣椒》截图
「思考」还能解释成隐喻,「记忆」也勉强算技术行话的延伸,「做梦」真就有点过了。文史哲几千年都没研究清,AI 公司却能直接说:我们不仅做出了能思考的机器,我们还做出了会做梦的机器。
什么是做梦,除了做梦,找不到任何一个能精确描述这件事的工程术语了吗?
AI 做梦也要花钱
早在 Claude Code 代码泄露事件中,就有网友发现 Anthropic 正在准备一项名为 Auto Dreaming 的功能。当时,大家都在想,难道 AI 也和我们人类一样,需要睡觉,得到足够的休息,才能变得注意力更集中,更聪明吗?
但只要了解目前 AI Agent 的工作原理,就会发现所谓的「做梦」,本质上只是一次自动化的离线日志批处理。
AI Agent 现在擅长完成一些长链路的复杂任务。比如「帮我调研一下这五家竞品的最新财报,并整理成表格」。在这个过程中,Agent 需要在不同的网页间跳转,读取多个文档,调用不同的工具,甚至可能因为遇到反爬虫机制而碰壁重试。
当这一长串繁杂的在线任务结束后,Agent 的后台会留下海量的运行日志。
图片由 AI 生成
Anthropic 的「做梦」功能,就是让 Agent 在闲置时间里,重新梳理这些历史记录。它会从中寻找模式,比如发现「每次遇到这种弹窗,点击右上角就能关掉」,从而优化下一次的操作路径。
「记忆」负责在工作时捕获学到的东西,而「做梦」则在会话之间提炼这些记忆,并在不同的 Agent 之间共享。
说白了,这就是一种基于历史数据的强化学习和自我纠错机制。

梦的介绍:https://platform.claude.com/docs/en/managed-agents/dreams
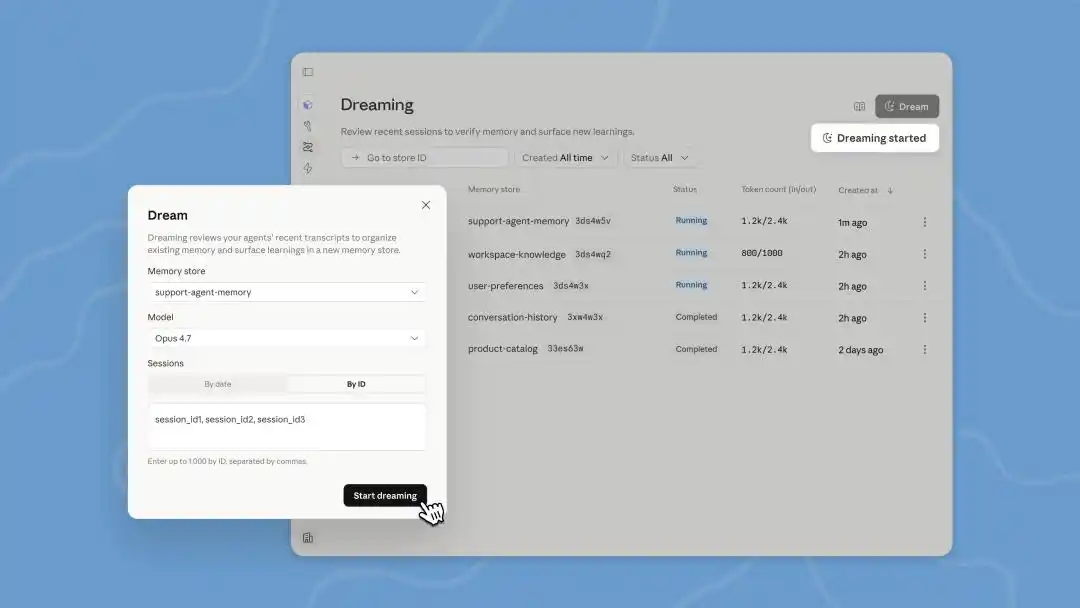
这次开发者大会上更新 Managed Agents 里的 Dreams,是个后台处理的任务,我们需要手动触发。Claude 一次能读最多 100 个 session 的对话历史,然后产出一份全新的 memory,供我们审查后再决定要不要用上。
而之前在 Claude Code 里已经悄悄上线的 AutoDream,是每次跟 Agent 聊完一轮,Claude Code 就会在后台检查「该不该做梦」,默认是 24 小时跑一次。
类似做梦的功能,Hermes Agent 也有。Hermes Agent 主打就是能自我学习和进化,它不仅支持自动从过去的任务里面总结出经验,放在记忆文件里。

其中一项叫 Curator 的功能,还能将这些提炼出来的操作指南,自动整理成 Skill。
这些 Skill 会被打分、重复的进行合并、长期不用的自动归档,甚至还有 active、stale、archived 这样的生命周期。我们还能把重要 Skill Pin 住,不让系统自动清掉。
OpenClaw 在最近的几次更新里,也添加了相关的机制,像是跨对话的持久记忆、定时的任务调度、子 Agent 隔离执行,以及直接叫 Dreaming 的做梦功能。
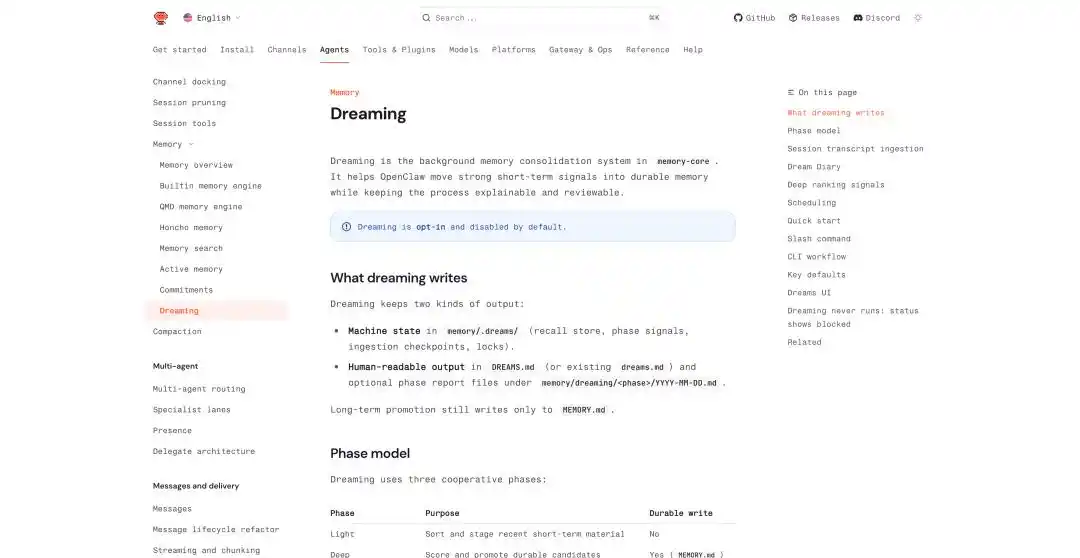
OpenClaw 的做梦:https://docs.openclaw.ai/concepts/dreaming
在 OpenClaw 的做梦机制里,它把梦境的行程概括成三个阶段,light、REM、deep。前两者负责整理、反思和主题归纳,deep 才真正把内容写入长期记忆 MEMORY.md。
而深度睡眠阶段的巩固,会由 6 个加权信号进行决定,是否需要写入长期记忆。这六个信号包括频率、相关性、查询多样性、时效性、跨天重复度、概念丰富度。

图片由 AI 生成
写入长期记忆,会生成两份文件,一份面向机器的状态文件,放在 memory/.dreams/;另一份是面向用户的可读记录,写入 DREAMS.md 和按阶段生成的报告。
此外,Dreaming 可以自动定时运行,默认每天凌晨 3 点跑一次完整流程,顺序是 light → REM → deep。
除了做梦的输出,OpenClaw 还维护这一个叫 Dream Diary 的文档, 系统会自动生成一份「梦境日记」,用叙事方式记录记忆整理过程,强调可解释、可审阅,而不是黑箱写库。
神经科学里有一个非常经典的理解:人类白天获取的信息,先进入更偏临时存储的系统;而在睡眠过程中,大脑会对这些信息进行重放、巩固和清理,把重要的留下,把无意义的丢掉。
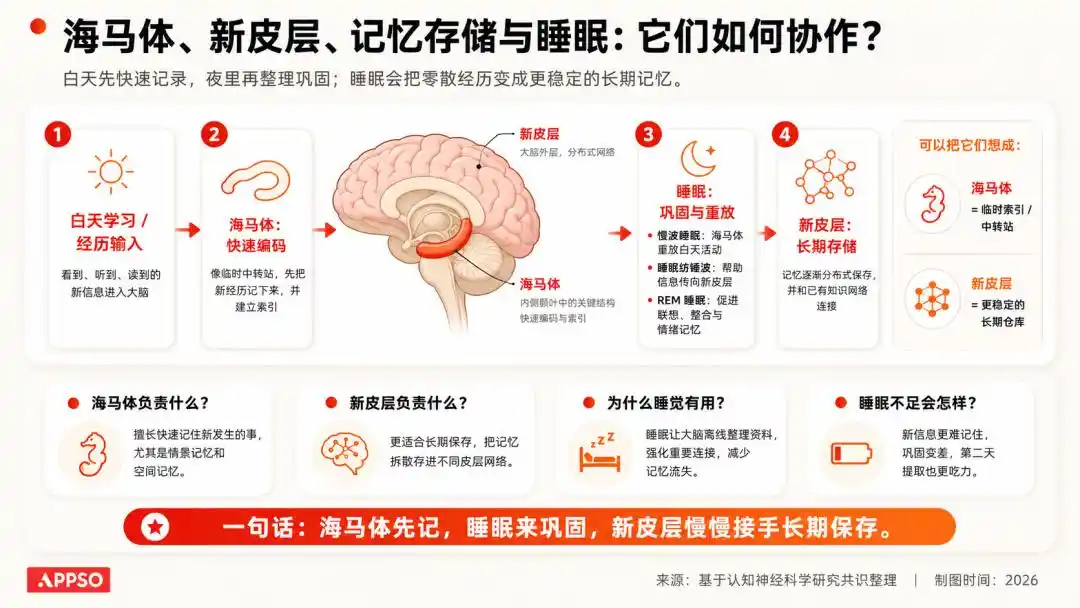
图片由 AI 生成
我们不会记得昨天上班路上每一辆车的颜色,但会记得怎么去公司。
这些梦,听起来和我们人做梦确实一样,非得找点不同,大概就是 Claude 做梦的时候,还是在消耗我们的 Token。
但 Anthropic、OpenClaw 都没有选择叫它「基于会话的优化(session-based optimization)」,或者是「任务后调优(post-task tuning)」等,偏向工程方面的名字。
毕竟,当把那些复杂名字,直接变成「做梦」,我们感受到的就不再是软件功能,而像一个「有内心活动的数字生命」。
AI 的记忆,是琐碎的上下文
既然提到了「做梦」,就不得不提它的前置条件,记忆(Memory)。
过去一段时间,AI 圈最火的词从提示词工程,变成上下文工程、Skill 工程、Harness 工程,但无论怎么变化,目前最有价值的还是上下文工程。
系统提示、用户输入、短期对话、长期记忆、检索回来的文档、工具和 Skill 调用的输出、当前用户状态,这些层叠加起来,就是 agent 真正在用的「上下文」。
让 Agent 能记得更多,记下更有用的内容,一直是过去很长一段时间以来的难题。
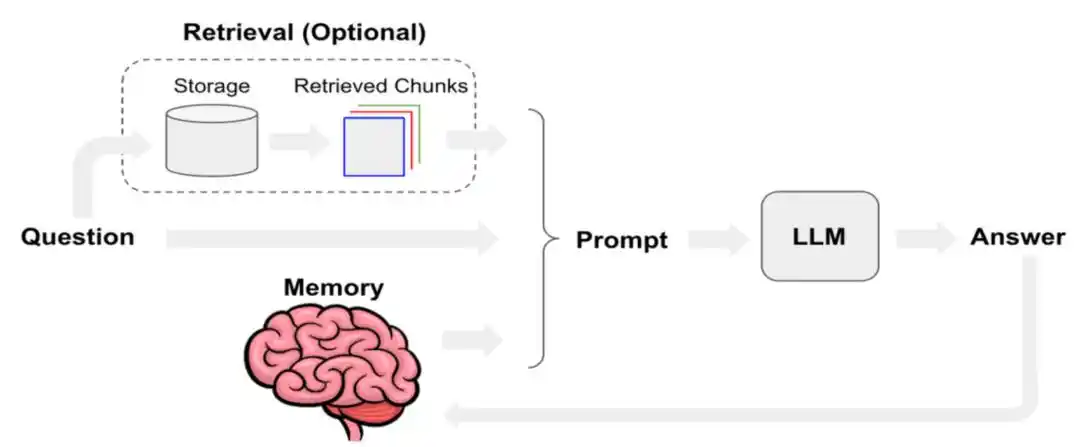
Manus 去年发了一篇技术博客,专门讲 Manus 是如何优化上下文工程。里面提到了把 KV-Cache 缓存命中率,定义为生产环境中 AI Agent 最重要的单一指标之一。同时在工具调用层面,优先做「遮蔽」而不是「移除」;以及把文件系统作为终极上下文等方法。
要理解所谓的 KV Cache(键值缓存),我们可以把大模型想象成一个每次只能读一个字的极度强迫症患者。
当它处理一句话时,它会为每一个生成的 Token 计算出一个 Key(键)和一个 Value(值)向量。为了不每次都从头重新算一遍,它会把这些 (K, V) 键值对存起来,这就是 KV Cache。
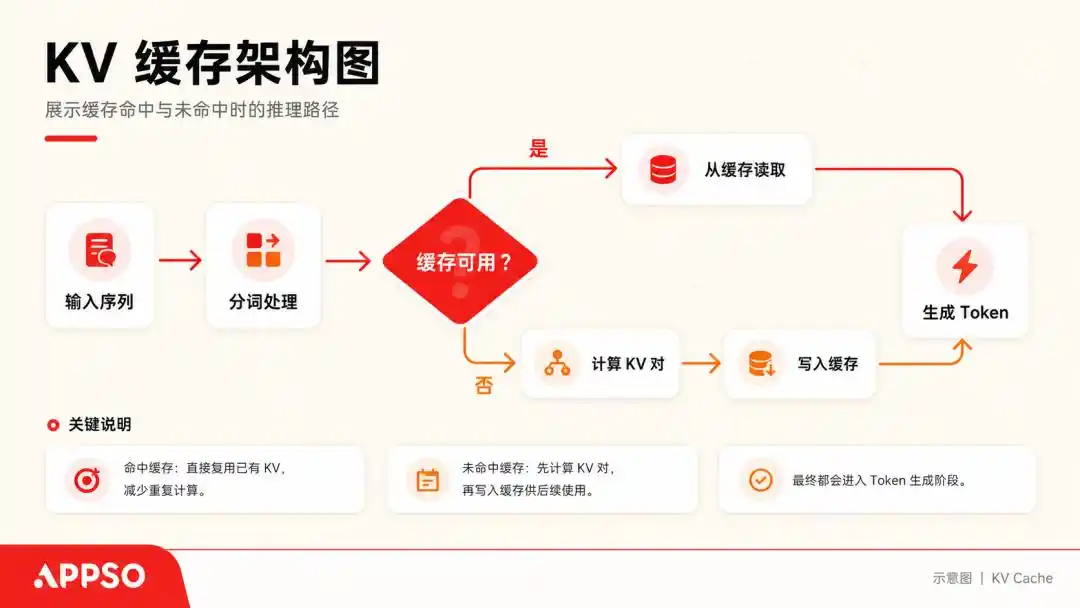
KV Cache(键值缓存)是大模型在生成文本时,用来「用空间换时间」的底层加速技术。缓存使得模型在预测下一个词时,不需要把前面的所有词重新计算一遍。图片由 AI 生成。
只要对话在继续,KV Cache 就会不断的保存。一般情况下,在面对动辄 128k 上下文的大模型时,一个 70B 参数的模型跑满 128k 上下文,单单是 KV Cache 就能一口吞掉 64 GB 的显存。
这也是为什么大多数模型的上下文窗口,目前最多都是百万级别。
昨天,一家拿到 2900 万美元种子轮融资的新公司 Subquadratic,在 X 发布 SubQ 新模型,主打更长上下文。

SubQ 宣称可支持最高 1200 万 token 上下文窗口,这是目前所有大模型里面最大的上下文窗口。
虽然还没有技术论文或模型说明文档,介绍的视频里提到,SubQ 的核心技术路线是从传统 Transformer 的「稠密注意力」,转向带有稀疏注意力的「次二次 / 线性扩展」架构。新的架构有望能解决上下文越长、算力成本越爆炸的问题。

给出的测试结果也相当激进,在 100 万 token 下,速度提升超 50 倍、成本降低超 50 倍;在 1200 万 token 时,算力需求较前沿模型可降低近 1000 倍。
而在 RULER 128K 长上下文基准上,Subquadratic 称 SubQ 以 95% 准确率、8 美元成本,对比 Claude Opus 的 94% 准确率、约 2600 美元成本,成本下降约 300 倍。
要不扩大上下文窗口,要不让模型学会做梦,自己丢弃一些东西。
这也是为什么 Anthropic 等 Agent 产品,现在必须推出 Dreaming。在上下文窗口受限的情况下,更聪明的 AI 不能光靠塞进更多内容,还需要有的放矢。
承认机器只是机器,比想象中难
了解了 AI 的做梦与记忆机制,我们或许能知道它和人类活动之间的关系。
但把所有这些 AI 公司造出来用在机器上的词放在一起,OpenAI 的 thinking 思考、行业通用的 memory 记忆和 hallucination 幻觉、Anthropic 这次的 dreaming 做梦,以及 Anthropic 那本宪法里的美德和智慧。
我们能看到,AI 公司远不只是在卖产品,它们在重新分配「人」这个概念里的词汇所有权。每挪用一个词,机器和人的边界就模糊一寸。

语言会塑造预期,预期塑造容忍度,容忍度决定我们愿意把多少东西交给它。这是一条很长的链条,但起点就是发布会上那些无害的词。
更隐蔽的一层影响是责任分配。当工具被描述成有「思考」、「记忆」、「价值观」的实体,它出问题时,我们会自然地把它当成一个独立的「行为主体」来追责,是这个 AI 它需要被「教育」「调试」「校准」。
可真正应该被追问的,是把这个程序部署到我们工作流里的那家公司,和写出「dreaming」这个词的那个产品团队。词一换,「被告席」上坐着的人也换了。
而我们看着一台会「思考」、会「记忆」、现在还会「做梦」的机器,也开始下意识地相信里面有什么东西。因为承认这只是一个机器,那种「我在跟一个会思考的存在对话」的体验感就消散了,回到的是冷冰冰的工具关系。

白日梦功能介绍|图片由 AI 生成
我已经想到了,Dreaming 做梦是处理过去的内容,接下来 AI 公司还会推出 Daydreaming,白日梦,用来预演未来。
介绍就是,白日梦或者走神,能让 Agent 在活跃的状态下,用一小部分的空闲算力,结合当前的正在进行的项目,同时去做探索性生成,准备未来可能的任务。
本文来自微信公众号“APPSO”,作者:发现明日产品的APPSO





