原创 | Odaily 星球日报(@OdailyChina)
作者|Golem(@web 3_golem)

当国内大厂争先恐后地推出“一键安装 OpenClaw”时,争议也跟着来了。
3 月 12 日,OpenClaw 创始人 Peter Steinberger 在 X 上公开质疑腾讯创建的 Skillhub,使官方速率下降导致无法快速抓取数据,并称“他们抄袭,却不以任何方式支持这个项目”。
面对争议,腾讯很快回应表示理解 Peter Steinberger 的担忧,称 SkillHub 是腾讯基于 OpenClaw 生态系统打造的本地化 Skills 平台,作为本地镜像站点,不仅始终注明 ClawHub 为数据来源,在上线首周还为用户处理了 180GB 的流量(87 万次下载),仅从官方源拉取了 1GB 的非并发请求。同时,腾讯表示愿意成为赞助者。
照理说,腾讯这一轮回应,已经把最容易引发舆论反弹的“是否在疯狂消耗源站”的问题解释清楚了,但 Peter 看完后并不买账,表示这不是重点,他可以把 SkillHub 做成官方第五镜像,同步下载统计,但腾讯应该事先主动与其沟通。
事情到这虽然结束了,但如果只把这件事理解为“OpenClaw 创始人情绪化开炮”或者“大厂正常做本地化被误解”,那实在就把问题看浅了。
问题不是镜像,而是大厂的“霸道”
如果只看技术动作,这事其实并不稀奇。
在中国的开发者生态里,镜像开源项目是常规操作,npm、PyPI、Docker Hub 这些国际开源基础设施,均有大量中国本地镜像。也正因如此,腾讯否定自己创建的 Skillhub 是抄袭,而是本地化 Skills 平台,它解释自己不是在薅羊毛和抽空官方,而是在做分发、加速和适配,帮 OpenClaw 在中国落地。
从某种意义上来说,腾讯的做法确实切中了中国“养虾户”们最现实的需求。OpenClaw 在中国热到失真,但不是每个人都愿意或者都能稳定访问原始社区,更不用说很多 Skill 的安装、发现、检索体验本身就还很原始。
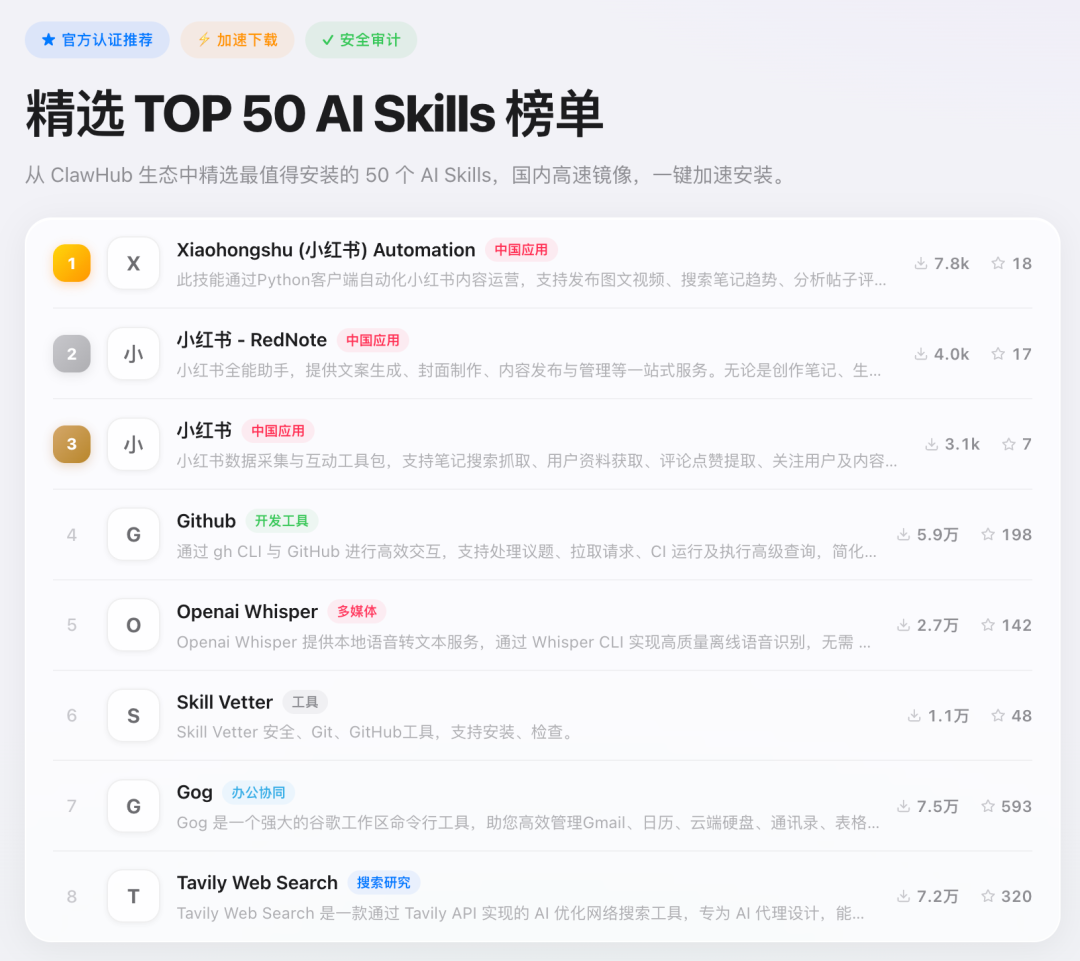
Skillhub
但问题是,镜像站就天然无罪吗?答案是未必。
因为开源协议允许什么、社区伦理接受什么、商业现实最终会发生什么,往往是三套不同的账。
在协议层面,只要遵循许可、标明来源,很多镜像与再分发行为是成立的;在社区伦理层面,腾讯的 SkillHub 标注了 OpenClaw 的官方源身份,并且还主动降低了源站的带宽成本,似乎也承担了责任。
但腾讯忘了,OpenClaw 不是一个小的、需要大厂刻意注入资源的开源项目,其是一个在 GitHub 上热度第一、获星最多的项目,这时腾讯不打招呼的行为就变成了“霸道”。因为它不再只是单纯的镜像问题,而是会迅速牵扯到三个更敏感的问题:谁在代表官方生态,谁在拿走用户入口,谁又在定义下载、分发和统计口径。
这才是让 Peter 真正不舒服的地方,其表示腾讯这种行为会直接影响到下载统计数据。Peter 不是不支持腾讯做 OpenClaw 的中国本地化,而是认为最好能事先沟通,而不是腾讯先把平台搭起来、把用户接过去,再在舆论压力下解释说自己其实是来帮忙的。
并且,从商业现实的角度来说,一旦 SkillHub 这种平台壳形成规模,那 OpenClaw 社区原本掌握的官方性和统计权,也就很容易被边缘化。今天是本地化 Skills 平台,明天可能就是“默认 Skills 分发市场”,再往后,就可能是“谁决定什么 Skills 被看到、被安装、被商业化”。
这才是这场争议背后真正的危险信号,也是过去十多年中国互联网最熟悉的一幕:圈地运动。
大厂不是在“养龙虾”,是在借龙虾圈地 AI
过去一段时间,“养龙虾”成了中国 AI 圈最热的梗,OpenClaw 也被迅速推成了一个近乎情绪化的行业符号。大家都在说龙虾代表 Agent 时代的新想象,代表个人 AI 助手的未来,听起来很热血。
但大厂看龙虾,看的从来不是理想主义,看到的是入口、流量、分发权和下一代操作系统外壳。
3 月 11 日凌晨,马化腾在朋友圈为腾讯全系“龙虾”产品宣传,腾讯的“龙虾全家桶”为普通用户、开发者和企业级用户都量身定制了一只“小龙虾”,支持用户无门槛一键安装。 SkillHub 也是在此时同步推出的,其内置了 1.3 万个本土化 Skill 一键调用,小红书运营、百度搜索等场景都可直接调用。
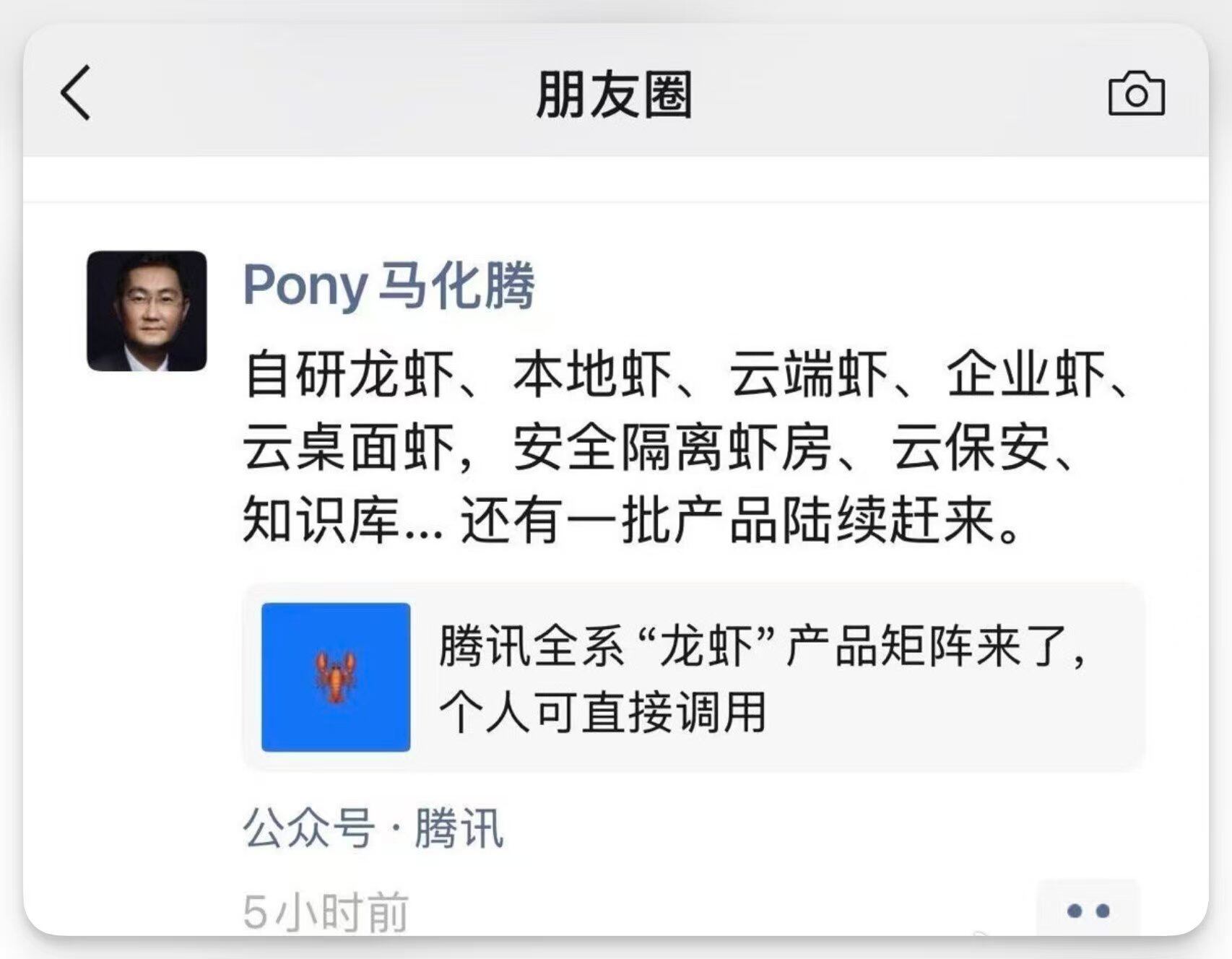
当然不止腾讯一家在“闻风而动”,一旦把时间线拉开就会发现,国内大厂几乎是集体下场帮用户解决“养龙虾”难题,动作整齐得像按下了同一个开关,只不过目前腾讯做的最全面。
表面上看,大家都是好心,但实际这里面藏着中国互联网公司们最熟悉的一套商业路径依赖,面对一个已经被市场验证、被舆论抬高热度的新生态,第一个动作不是赚钱和商业模式,而是先抢入口,先做平台,先把用户接过来。
腾讯想要的,不只是让中国用户“养龙虾”更容易,而是当中国用户第一次真正开始“用 Agent 办事”时,第一反应是在腾讯的产品壳里完成。
这才是 SkillHub 这种动作最值得玩味的地方,它表面上是一个镜像站,实质上却可能是一个更大闭环的起点。今天用户看到的是 Skills 的本地检索和下载,明天可能就是默认接入某个云、某套账号、某个企业工作台。 再往后,开发者会慢慢发现,自己虽然还在 OpenClaw 生态里开发,但真正决定曝光、推荐、审核、商业化路径的,已经变成平台了。
这套剧本中国互联网演过太多遍了。从打车到外卖、从短视频平台到云市场,几乎每一次“生态繁荣”的背后,都伴随着同一种结构性结局——平台先用免费、开放等招揽用户,然后再建立围墙,利用流量、广告等手段将生态重新变成自己的附属层。
大厂们都知道,如今搜索、社交、内容、电商这些旧入口已经卷到极限,而 Agent 可能是下一轮最值得下注的新入口。既然如此,与其等 OpenClaw 自己野蛮生长,不如趁它还处在爆发初期,就先接过来、先封装、先让用户养成在自己体系里“使唤龙虾”的习惯。
因此,所有人都太熟悉大厂们争相帮用户解决 OpenClaw 安装难题后,接下来会发生什么了。而不懂中国互联网的 Peter 自然理解不了为什么腾讯不事先与其沟通,为什么不与之同步数据。
OpenClaw 原本代表的是另一种 AI 未来:本地运行、个人掌控、社区扩展、开放连接,它最有想象力的地方是让 Agent 真正成为用户自己的执行层。可一旦这套生态被大厂用“本地化镜像”、“国产适配”、“统一分发”、“安全审核”重新包装,味道就变了。在大厂的产品逻辑里,入口归我、分发归我、那么最后的支付和商业化也最好都归我。
说得再直白一点,大厂们不是在“拥抱龙虾”,而是在“借龙虾圈 AI 时代的地盘”。
而这,才是这场小争议背后最让人不安的地方。围墙从来不是一下子立起来的,它总是以“更方便”“更稳定”的名义慢慢长出来。等开发者、用户和流量都被装进同一个壳里,所谓开放自主,最后也可能只是大厂生态里的一个组件罢了。
OpenClaw 眼下在国内面临着最吊诡的命运:龙虾还没长大,大厂已经开始围网了。