拖更了三年的博客,Lilian Weng终于发出来了。
就在刚刚,前OpenAI副总裁Lilian Weng一篇拖了三年多的长文刷屏了。
在这篇名为《Scaling Laws, Carefully》博客里,她直接把Scaling Laws从头拆到尾——
AI行业砸了数百亿美元押注的这条定律,远比任何人想象的脆弱。
一分钟速览:这篇万字长文讲了什么
一条公式管了全行业五年。Scaling Laws说「模型做大、数据喂多、算力堆够,性能就会按固定比例往上涨」。它让AI从玄学变成了能算账的生意,间接指挥了上千亿美金的流向。
OpenAI和DeepMind给出了相反的答案。同一个问题「算力预算怎么分配」,2020年OpenAI说模型该比数据涨得快,2022年DeepMind说两边得一起涨。后来发现,分歧的根源是一个参数统计口径的差异,加上实验规模不够大。
赢家的公式里也藏着bug。DeepMind那条被全行业照抄两年的最优配比,2024年被人逐行复现时发现:损失函数取了均值而不是求和,导致优化器提前停了,输出的参数根本不是最优解。
拿小模型的规律去预测大模型,要非常小心。这条曲线是在相对小的模型上拟合出来的,外推到万亿参数级别时,一个四舍五入的差别就能让结论差出一大截。博客里附了一个交互式模拟器,拖一下滑块就能亲眼看到。
还有个更根本的问题:数据快用完了。公式默认数据可以无限供应,但高质量文本是有限的。这也是为什么整个行业集体转向强化学习、测试时计算和合成数据。
一条直线,千亿美金
众所周知,Scaling Laws的核心可以简单地总结成一句话——
模型越大、数据越多、算力越猛,表现就越好。而且这个「越好」不是随机的,它有精确的数学规律。
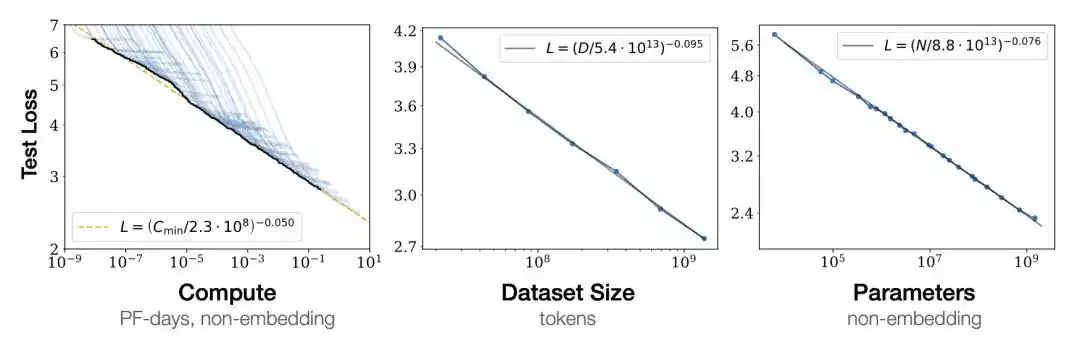
把模型训练的损失画在对数坐标上,它随着模型参数量N、数据量D、算力C的增加,呈一条直线下降。
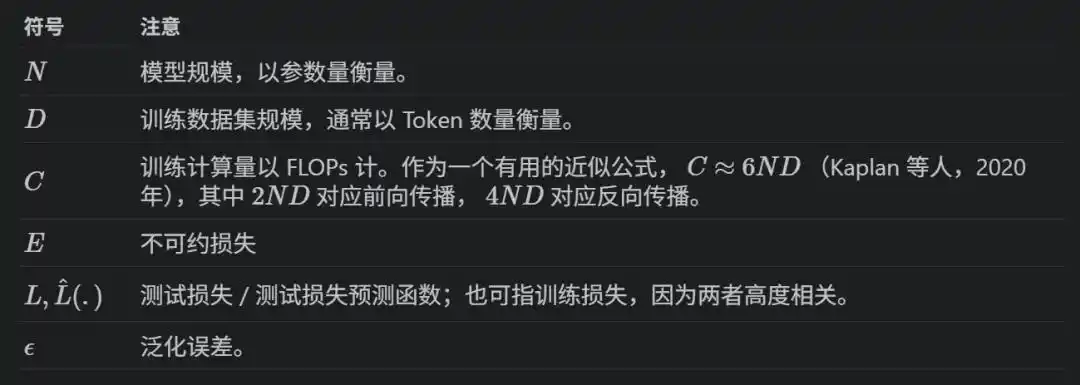
用公式写就是L(x) = E + A/x^α,其中x可以是N、D或C,E是理论最优损失(数据本身的熵),A和α是拟合出来的常数。
训练一个N参数的模型跑D个token,总算力C ≈ 6ND——前向传播2ND,反向传播4ND。
这条直线意味着性能提升是可预测的。
先跑几个小模型,拟合出那条直线,往右外推,就能预估大模型训出来的表现。不用真花几亿美元把大模型训完才知道它行不行。
在这之前,深度学习一直被讥讽为「炼金术」,知道什么有效,不知道为什么有效。
2020年OpenAI的Kaplan发表了这条幂律,第一次把玄学拽进了「可预测」的地界。
这就是所有大模型公司敢砸钱的底气。
但公式给出的最关键建议,给定算力预算,模型和数据怎么分配,OpenAI和DeepMind给出了相反的答案。
同一道题
OpenAI和DeepMind做出了相反的答案
2020年OpenAI的Kaplan团队得出的结论是:最优模型大小N_opt ∝ C^0.73。
翻译过来就是:算力翻10倍,5.5倍给模型、1.8倍给数据——模型涨得要比数据快得多。
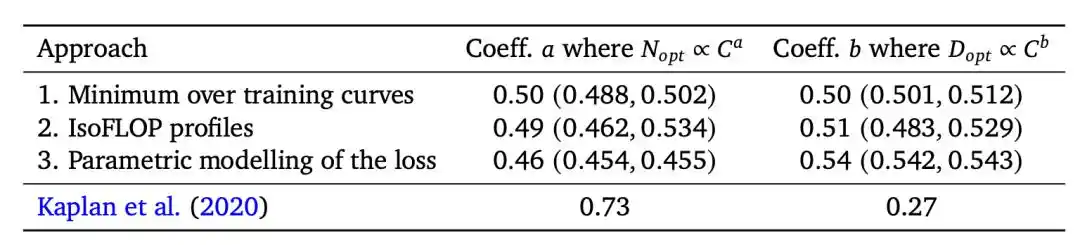
这直接指导了GPT-3的训练方案。
1750亿参数的模型,只喂了3000亿个token(token是模型处理文本的最小单位,大约一个词对应1-2个token)。
按后来的标准看,这属于严重训练不足。
2022年DeepMind的Chinchilla团队得出了相反的结论:N_opt ∝ C^0.50,模型和数据应该等比增长。

工程师们后来把它提炼成一个张口就来的数字:最优token和参数比大约20:1。
然后DeepMind做了一场正面对决。
自家的Gopher,2800亿参数配3000亿token。Chinchilla,700亿参数配1.4万亿token。两个模型用了相同的算力。
Chinchilla全面碾压。
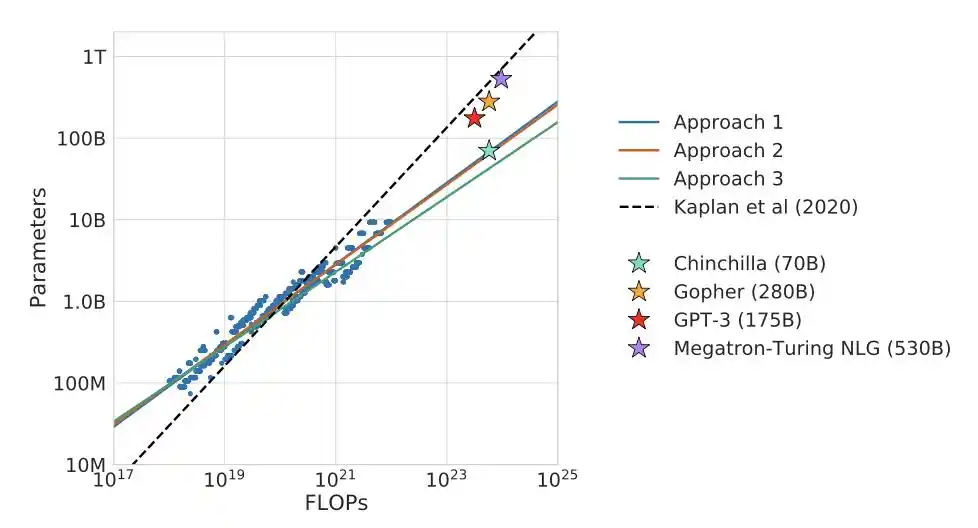
一个又小又「吃得多」的模型,把又大又「饿着」的对手打趴下了。
整个行业的共识因此翻转:从「把模型做大」变成「大多数模型都训练不足」。
0.73 vs 0.50,同一个问题,相反的答案,会让你把算力预算往两个完全不同的方向分配。
原因竟是一个「簿记问题」
2024年,两位研究者在机器学习顶刊TMLR发了一篇调和论文,把这个分歧追到了底。
结论让人哭笑不得。
第一个原因:两边数参数的方式不一样。
模型里有一类叫embedding的参数层,负责把文字转换成模型能理解的数字向量。小模型里这一层占总参数量的比例非常大,几千万参数的模型可能占到三分之一。
Kaplan在统计参数量时把embedding排除在外,Chinchilla则把它算进去了。
就这么一个参数统计口径的差异,就足以扭曲最终拟合出来的幂律指数。
他们给出了一个简洁的校正公式:N = N_\E + ω·N_\E^(1/3),其中N_\E是去掉embedding后的参数量,ω是常数。小模型时第二项占比大,embedding影响显著;模型越大,第二项趋近于零,两种数法殊途同归。
第二个原因:Kaplan的实验规模太小。
Kaplan测试的最大模型只到15亿参数,而Chinchilla的实验扫到了160亿以上。在对数坐标里,微小的拟合偏差在外推时会被急剧放大。
他们用统一的参数统计口径重新推导了Chinchilla的公式,发现了一个关键规律——
幂律指数会随着算力规模的增大而变化。在Kaplan的小规模实验范围内,指数确实接近0.73;但规模增大后,指数收敛到0.50。
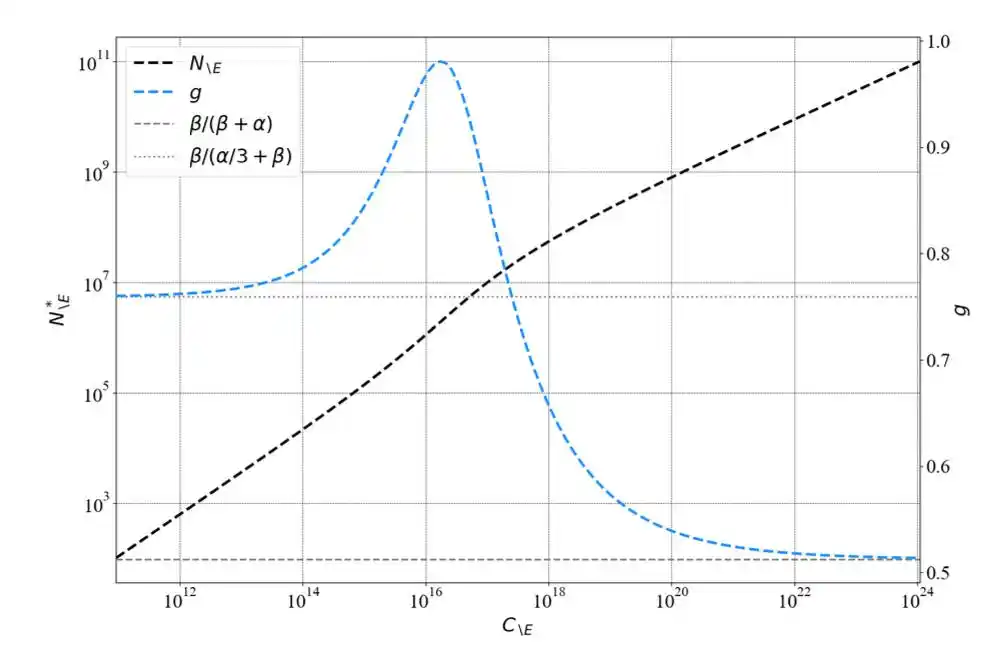
Kaplan没有「错」,他在自己的实验范围内是对的。
但他把一个局部成立的规律,外推成了全局结论。
一个参数怎么数的簿记问题,加上实验规模不够大,就让两个顶级团队给出了相反的资源分配建议。
全行业照着这个结论调了两年的训练配方。
连赢家也有bug
Kaplan被Chinchilla纠正了,这是大家都知道的标准叙事。
但Weng往前走了一步——Chinchilla自己的方法论,也有问题。
Chinchilla论文用了三种独立方法交叉验证自己的结论:
方法1固定模型大小变数据量
方法2画等算力曲线(IsoFLOP profiles)
方法3直接对损失公式L(N,D) = E + A/N^α + B/D^β做参数拟合
三条路指向同一个结论,看起来非常扎实。
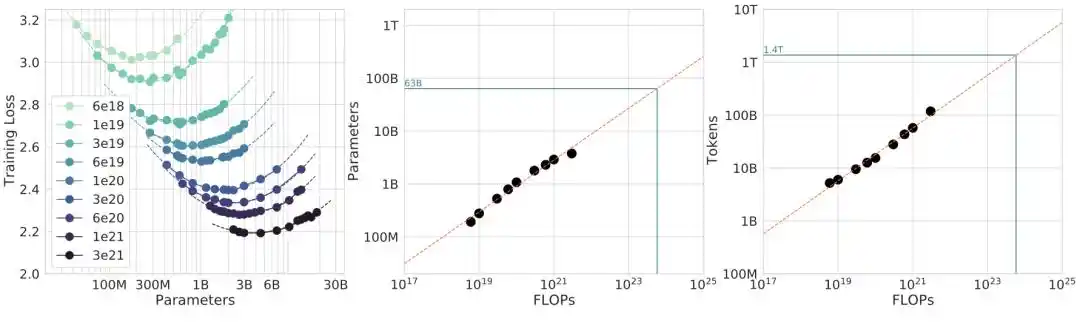
方法3的数学推导尤其优雅:在约束C ≈ 6ND下对L(N,D)求最优,可以得到闭合解N_opt ∝ (C/6)^(β/(α+β))。当α ≈ β时,指数约等于0.5,也就是模型和数据等比增长。这就是0.50的数学来源。
2024年,AI研究机构Epoch AI的团队从Chinchilla论文的图表中手动提取原始数据点,重新跑了方法3的拟合。
两个bug,一个比一个离谱。
Bug 1:损失函数取了均值而不是求和。
Chinchilla在拟合这五个参数时,需要最小化预测损失和实际损失之间的差距。
完整的优化目标如下:min Σ Huber_δ(log L̂(Nᵢ,Dᵢ) − log Lᵢ),其中Huber Loss是一种对异常值不敏感的损失函数(δ = 10⁻³),配合L-BFGS-B优化器来搜索最优解。
问题出在一个细节上:他们对每个样本的Huber Loss取了平均值(mean)而不是求和(sum)。几百个样本一平均,损失值被压缩到了极小的量级。
L-BFGS-B优化器有一个内置的收敛判据。当损失值足够小时自动停止。它看到这么小的数值,误以为已经收敛,直接停了。
优化器根本没有跑完。输出的参数不是真正的最优值。
Bug 2:关键参数只保留了两位小数。
Chinchilla论文里有两个控制幂律形状的核心指数,只保留到了小数点后两位。
看起来是无伤大雅的四舍五入。
但从这两个粗糙的数反推其他常数时,误差被指数级放大。最终的置信区间窄得不合理,窄到需要超过60万次实验才能达到的精度,而他们实际只跑了不到500次。
一个被全行业奉为圭臬的公式,背后藏着一个loss函数没跑完的bug,而且这个bug藏了整整两年。
Weng在博客里还附了一个交互式模拟器,三个滑块分别控制损失精度、损失噪声和拟合区间。
每动一下,拟合出来的Scaling Law就变一个样。
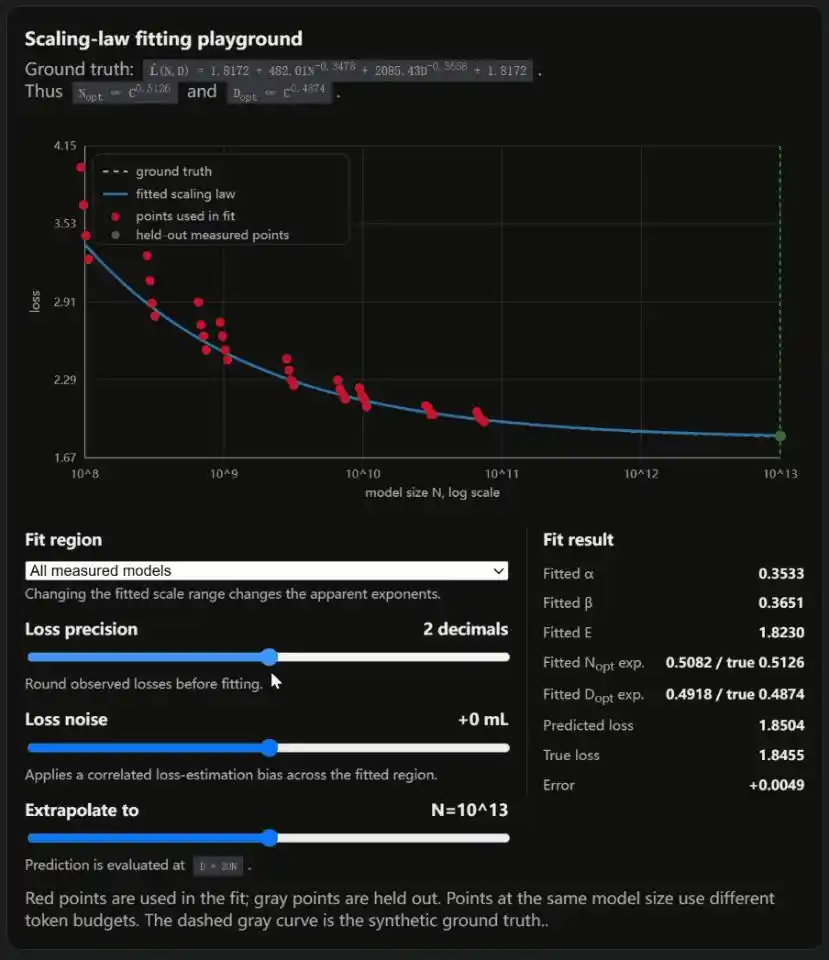
OpenAI的结论有局部性偏差,DeepMind的结论有方法论瑕疵。AI行业最重要的学术争论,双方都有裂缝。
数据快烧完了
前面三节讲的都是拟合方法的问题,参数怎么数、损失怎么算、精度取几位。
但即使这些问题全部修好,经典Scaling Laws还有一个更根本的隐患——
它假设每个 训练数据 都是唯一的,不重复、不训多轮,默认你有无限的数据。
现实是,高质量文本数据预计在2026到2028年之间就会被各大实验室扫荡殆尽。
数据重复训练不可避免,经典公式的前提正在崩塌。
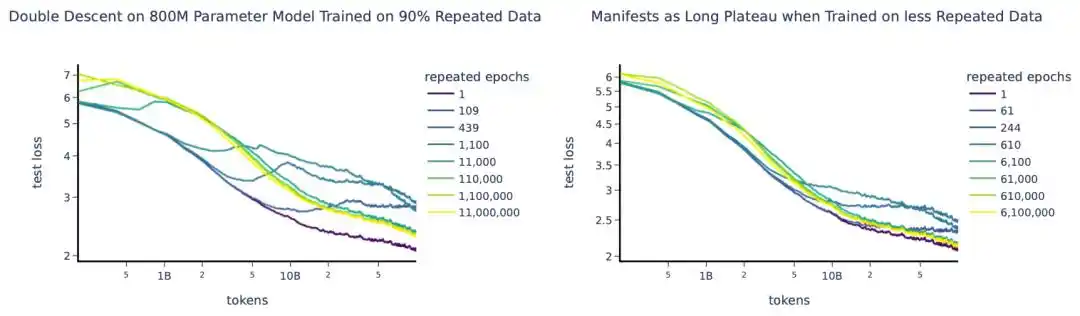
2023年的一项大规模实验训了约400个模型,从千万到90亿参数,最多重复训练1500轮。
核心思路是引入「有效数据量」的概念来替代实际数据量——
如果你有U条唯一数据重复了R轮,有效数据量并不是U×R,而是按D_eff = U·(1 - e^(-R))的指数衰减曲线折算。第一轮重复还能学到不少新东西,到第五轮、第十轮,边际学习收益趋近于零。
他们还发现了一个反直觉的结论:多余的参数比重复的数据「贬值」得更快。也就是,预算有限时,与其加大模型,不如多跑几轮训练更划算。
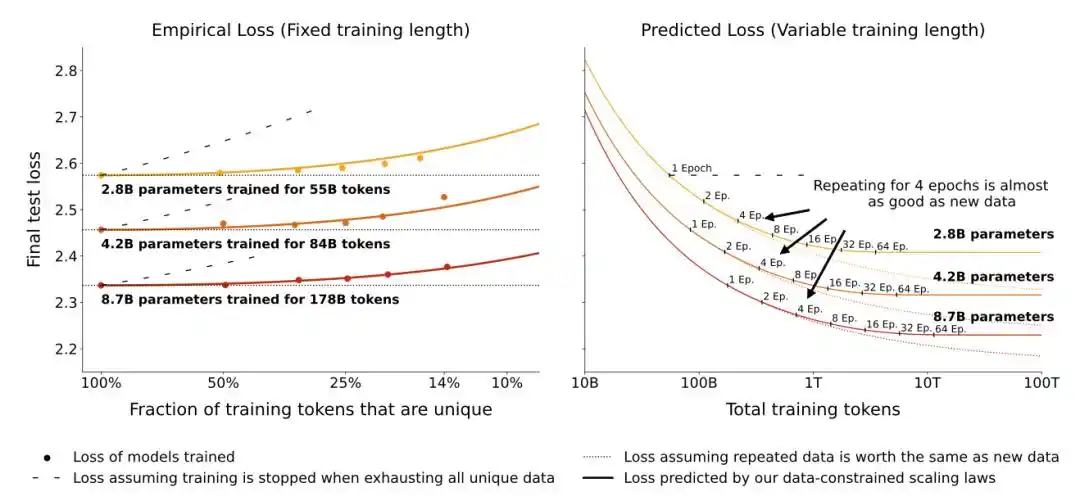
2026年5月的一篇新论文换了思路。
他们不折算有效数据量,而是直接在经典损失公式后面加了一个显式的过拟合惩罚项——模型重复看同一批数据越多次,惩罚越大,而且这个惩罚和模型大小挂钩。
他们的完整公式长这样:
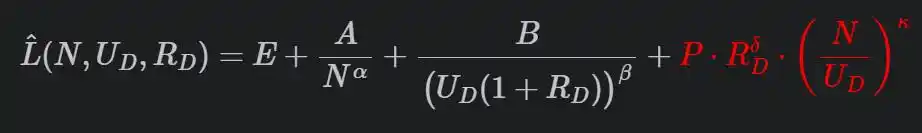
最后那个红色的惩罚项是关键。
R是重复次数,N/U是模型参数量和唯一数据量的比值(模型相对于数据有多「过剩」),P、δ、κ都是从实验中拟合出来的。重复越多、模型越大,惩罚越重。
这篇论文的核心发现是:大模型对数据重复更敏感。同样把数据重复训练10轮,一个5亿参数的模型可能还扛得住,但一个50亿参数的模型性能下降会严重得多。
另一个工程上直接有用的发现为:加强权重衰减(weight decay)可以显著缓解重复训练带来的过拟合。
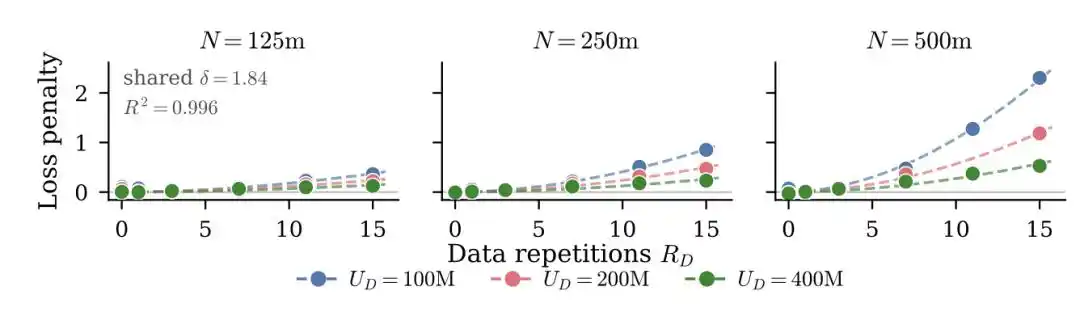
这也是为什么2025到2026年,整个行业的注意力集体转向了三条绕过数据墙的路——
强化学习,DeepSeek R1、OpenAI o系列,让模型在数学和编程等可验证的任务上自我博弈,产生训练信号。
测试时计算,不增加训练成本,让模型在回答问题时多「想」几步来换取更好的表现。
合成数据,用现有的强模型生成新数据来训练下一代模型。
三条路的潜台词一样:纯粹靠「堆规模」的那条幂律,已经不够用了。
从北大到OpenAI到自己的公司
Lilian Weng,北大本科,印第安纳大学伯明顿分校博士。
有意思的是,她的博士方向不是深度学习,而是网络科学与复杂系统,研究的是信息在社交网络里怎么传播。
她毕业后先去了Dropbox做数据科学,又去了金融科技公司Affirm,2018年才加入OpenAI。
来到OpenAI后,Weng参与的第一个项目是机器人。那只花了两年学会解魔方的机械手Dactyl,她是核心贡献者之一。
后来转去搭建应用研究团队,GPT-4发布后被委任组建Safety Systems团队,到她离开时这个团队已有80多位科学家、工程师和政策专家。
2024年8月头衔升为VP of Research and Safety,三个月后宣布离开。

2017年,Weng刚接触深度学习不久,开了一个叫Lil'Log的个人博客,最初只是为了整理自己的学习笔记。
她曾说过,「把一个概念讲清楚,是检验自己是否真正理解它的最好方式」。
结果一写就是九年,强化学习、扩散模型、大模型agent,每一篇都从基础原理写起,几十页长文配自己画的图解。
这个博客后来成了AI领域被引用最多的个人技术博客之一,很多大学直接拿来当教材。
2025年2月,她和前OpenAI CTO Mira Murati成立Thinking Machines Lab,联创还包括OpenAI联创John Schulman、前研究VP Barret Zoph和Luke Metz。a16z领投种子轮20亿美元,估值120亿。
而她在公司高速推进的同时,花时间写完了这篇拖了三年的Scaling Laws长文。
你每天用的ChatGPT、Claude、Gemini,背后都是这些公式在决定下一代怎么训。
下一代AI好不好用,不取决于谁的GPU多,而取决于谁把这些细节处理得更精确。
参考资料:
https://x.com/lilianweng/status/2070237256070389897?s=20
https://lilianweng.github.io/posts/2026-06-24-scaling-laws/
本文来自微信公众号“新智元”,作者:ASI启示录,编辑:摩西







