作者:Yanhua
Antonio Gullí 是 Google 的工程总监。他写了本 453 页的书,把 AI Agent 开发拆成了 21 种设计模式。
但这不是一篇书评。我读这本书的动机很具体:我写过 Harness Engineering,写过 Clawdbot 的踩坑经验,写过“AI 智能体不是魔法”那篇从烧 Token 到真正好用的七个转折,每次写完之后都有一个没完全想透的问题:这些东西背后有没有一套可以复用的底层逻辑?
这本书给了我答案,而且比我想的更深。
你写的可能根本不是 Agent
书里最狠的判断藏在 prologue 里。
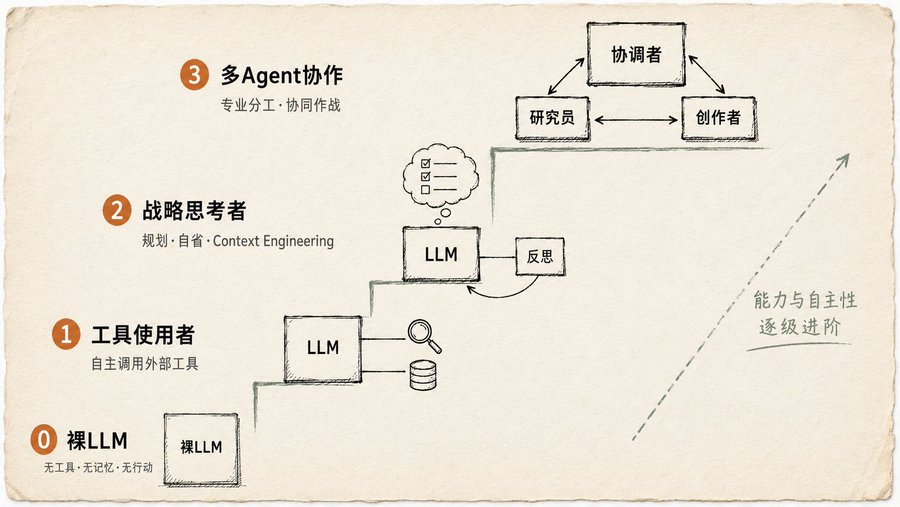
大多数人在用的“AI”,只是 Level 0:裸 LLM,没有工具、没有记忆、不会行动。你问它 2025 年奥斯卡最佳影片是哪部,它猜。书里说得很直白:Level 0 的东西,不是 Agent。
往上走才是真 Agent:
-
Level 1:工具使用者
Agent 开始用工具了:搜索、API、数据库。但它不光是“能调接口”,更要自己判断什么时候该调、调什么、结果怎么用。书里给了一个很具体的例子:用户问“最近有什么新剧”,Agent 自己意识到这条信息不在训练数据里,主动调搜索工具去找,然后合成结果。关键一步在“自己意识到”。不是人类告诉它“你去搜一下”,是它自己判断需要搜。这个判断能力,是 Level 1 的门槛。
-
Level 2:战略思考者
多了两样东西:规划和 Context Engineering。书里定义了 Context Engineering:不做信息堆砌,做的是精心筛选、裁剪、打包上下文。例子很妙:用户要在两个地点中间找咖啡店。Agent 先调地图工具拿到一堆数据,然后自己判断“下一步只需要街道名称”,把地图输出裁剪成一个短列表,再喂给本地搜索工具。每一步都在做信息降噪。
书里有一句话我反复看了几遍:“要让 AI 达到最高准确率,必须给它短小、聚焦、有力的上下文。” Context Engineering 就是干这件事的。
到了这个级别,Agent 还能自我反思。干完活后自己审一遍,发现问题自己改。我后面会细讲。
-
Level 3:多 Agent 协作
书的立场很明确:别老想着造一个全能 super agent。真正靠谱的做法是像搭团队一样,项目经理 Agent + 研究员 Agent + 设计师 Agent + 文案 Agent。书里举的例子是新产品发布:一个“项目经理 Agent”做总调度,下发任务给“市场研究 Agent”、“产品设计 Agent”、“营销 Agent”。关键是通信:Agent 之间怎么传数据、怎么同步状态、怎么处理冲突。这章画了六种通信拓扑结构,从最简单的单 Agent 到最灵活的自定义混合,每种适合什么场景都有说明。
看完这四个等级,我突然明白为什么很多人说“我的 Agent 不好用”。模型没问题,问题是你在把它当聊天机器人用,它可能连 Level 1 都没到。
Context Engineering:书里最被低估的概念
我写过一篇 Harness Engineering,讲的是赛道的设计比引擎的马力更重要。看完这本书我发现,Context Engineering 就是 Harness Engineering 在 prompt 层面的映射。
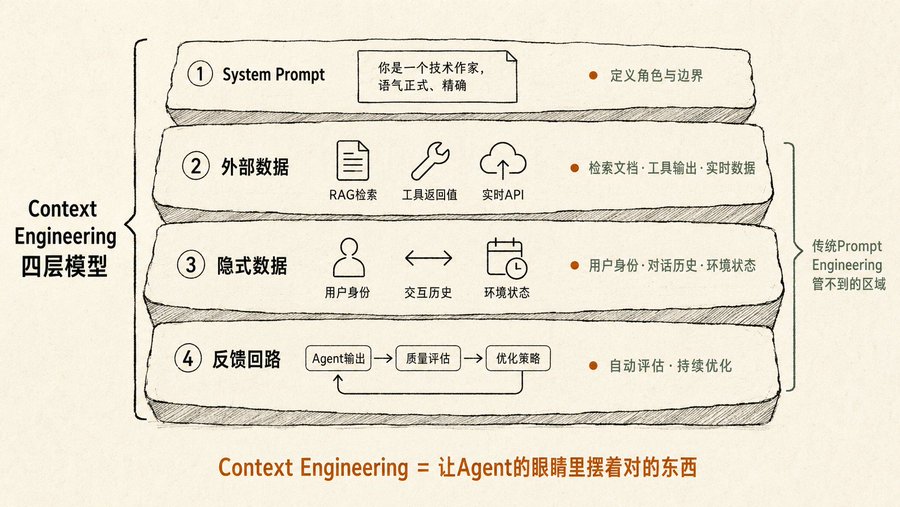
传统的 Prompt Engineering 只管“你怎么问”。书里的 Context Engineering 管的是“问之前,Agent 的眼前摆着什么”。它包括四层信息:
-
第一层,system prompt。定义 Agent 是谁、什么语气、什么边界。大多数人只写了这一层。
-
第二层,外部数据。RAG 检索到的文档、工具调用的返回值、实时 API 数据。这是大部分人卡住的地方:知道要喂数据,但不知道怎么喂才不会把模型淹没。
-
第三层,隐式数据。用户身份、交互历史、环境状态。你没明说但 Agent 应该知道的东西。比如你跟 Agent 说“帮我给 John 发邮件确认明天的会议”,它应该知道你日历里明天的会议是什么、你和 John 是什么关系。
-
第四层,反馈回路。Agent 每次输出之后,自动评估质量、调整下次的上下文策略。书里把这叫“自动化的 context 优化”,Google 的 Vertex AI Prompt Optimizer 就是这个思路的工程化实现。
我读到这里的时候想起之前写那篇“AI 智能体不是魔法”,里面有一条经验是“你的智能体需要规则,而且是很多规则”。现在回头看,那些规则本质上就是 Context Engineering 的手工版,书里把它系统化了。
Reflection:两个 Agent 真的比一个好
这是全书对我最有实战价值的一个 Pattern。
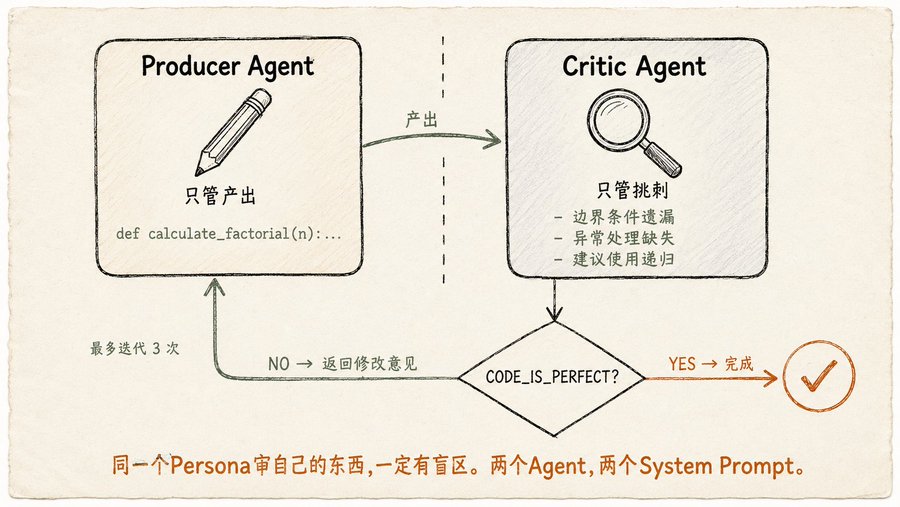
Reflection 的核心很简单:Agent 干完活后自己审一遍,发现问题自己改。但实现方式有讲究。书里明确说了:Producer 和 Critic 必须用两个不同的 Agent,给不同的 system prompt。 同一个 persona 审自己的东西,一定有盲区。你让同一个 LLM 先写代码再审查自己写的代码,它大概率会说“挺好的”。
书里给了一个完整的代码示例。
-
Producer 的 prompt 是“你是一个 Python 开发者,写一个计算阶乘的函数,处理边界条件和异常”。
-
Critic 的 prompt 是“你是一个吹毛求疵的高级工程师,逐行审查代码,检查 Bug、风格、遗漏的边界条件、可改进的地方。如果完美就输出
CODE_IS_PERFECT,否则列出所有问题”。 -
然后是一个 for 循环:Producer 写代码 → Critic 审 → Producer 根据意见改 → Critic 再审 → 直到 Critic 说
CODE_IS_PERFECT或者达到最大迭代次数。
就这么简单。但书里提醒了一个容易被忽略的成本问题:每次反射循环都是一次新的 LLM 调用,迭代次数越多越贵。而且随着对话历史膨胀,上下文窗口被前期版本和批评意见占满,实际可用的推理空间在缩小。所以 Reflection 的最佳实践是:设一个合理的最大迭代次数(书里用的是 3),一旦 Critic 满意就停,不要追求完美。
用途远不止写代码。写文章、做计划、总结文档、解决逻辑题,Producer-Critic 模型全都能套。书里列了七种应用场景,核心逻辑一样:先产出,后审查,再修正。
Multi-Agent 不是越复杂越好
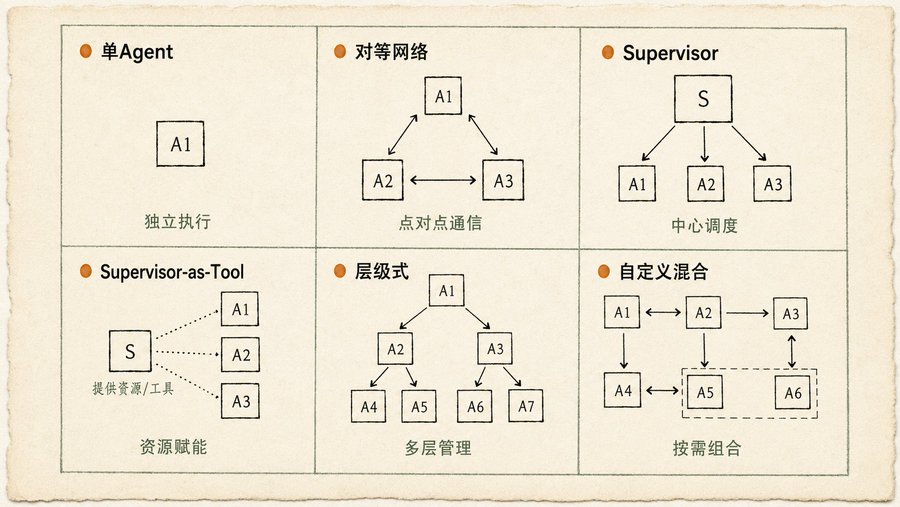
Multi-Agent Collaboration 这章我最喜欢的是那六种通信拓扑图。很多人一上来就搞复杂的,但其实大部分场景三种就够了:
-
单 Agent(独立执行):任务能拆成互不依赖的子问题,每个 Agent 自己搞定自己的。简单,好维护。
-
对等网络(Peer-to-Peer):Agent 之间直接通信,没有中心控制节点。去中心化,容错性好,一个 Agent 挂了不影响全局。但协调成本高,容易乱。
-
Supervisor(中心调度):一个 Supervisor Agent 管一群 Worker Agent。分配任务、收集结果、解决冲突。层级清晰,好管理。但 Supervisor 是单点故障,也是性能瓶颈。
另外三种(Supervisor-as-Tool、层级式、自定义混合)是前三者的变体和组合。书里说得很实在:你需要的拓扑结构取决于你的任务复杂度。 任务越拆越碎,通信成本越高,到一定程度 Supervisor 模式反而比层级式更有效率。
我的体会是,很多人搭 Multi-Agent 的时候花了 80% 的时间在通信协议上,忘了问一个更基本的问题:这个任务真的需要多个 Agent 吗? 书里写得很清楚,Level 2 的单 Agent + Reflection 往往已经够用了。Level 3 是给那些单 Agent 确实搞不定的场景准备的。
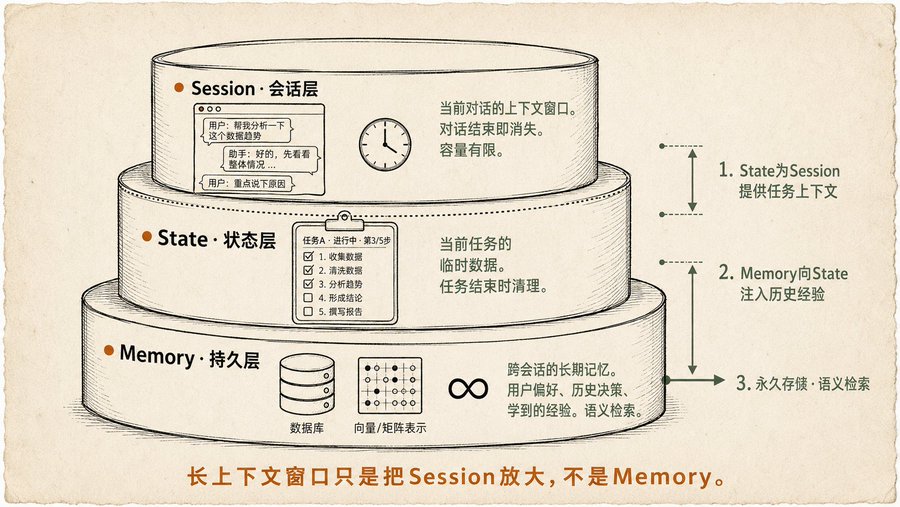
Memory 三层模型,我之前隐约感觉到了但没命名
Memory 这章我最有共鸣,因为我写 Obsidian + Claude 那两篇文章的时候,一直在琢磨一个问题:Agent 的记忆该怎么分层?
书里给了答案:
-
Session(会话层):当前对话的上下文窗口,这是最短的记忆,对话结束就没了。长上下文模型只是把这个窗口放大了,但本质上还是临时的,而且每次推理都要处理整个窗口,又贵又慢。
-
State(状态层):当前任务进行中的临时数据。比如“正在做的任务是什么”,“已经完成到哪一步”“中间产生了哪些数据”。比 Session 长,但任务结束就清理,书里用 Google ADK 的 State 机制做了完整示例。
-
Memory(持久层):跨会话、跨任务的长期记忆。用户偏好、学到的经验、重要的历史决策,存数据库或向量库里,语义检索。书里强调了一个很重要的点:Memory 不只是存下来,还要设计“存什么、什么时候存、怎么检索”的一整套策略。存太多了噪声大,存少了不够用。
我之前写 Clawdbot 那篇文章里提到“状态文件”和“工作区文档”,本质上就是在手搓 State 层和 Memory 层,书里把这件事框架化了。
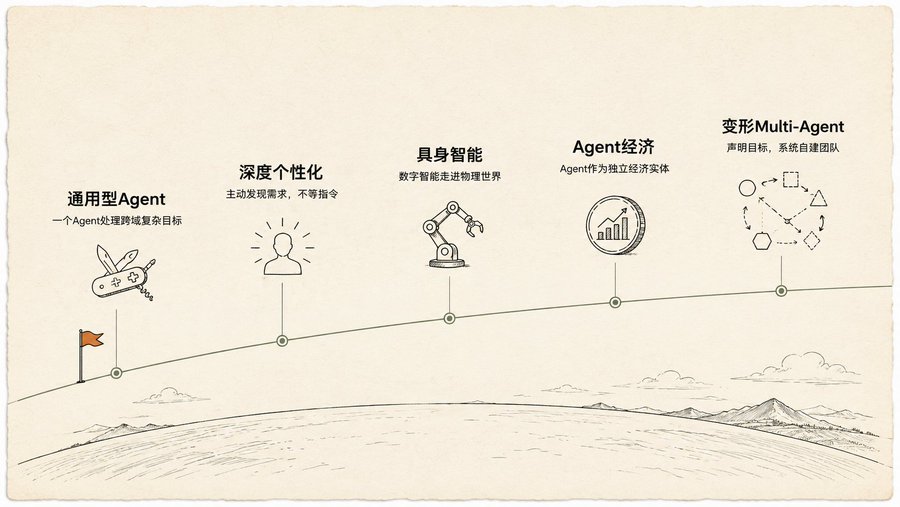
五种假设,第五个最离谱
书末提了五个关于 Agent 未来的假设,前四个还在合理推演范围内:通用型 Agent 从写代码到管项目、深度个性化主动发现你的需求、具身智能走出屏幕进物理世界、Agent 成为独立经济实体。
第五个把我震住了:变形 Multi-Agent。
你只声明目标,比如“做一个卖精品咖啡的电商生意”。系统自动决定:先创建“市场研究 Agent”和“品牌 Agent”。跑了一轮数据后,自己判断品牌 Agent 不需要了,拆成三个新的:“Logo 设计 Agent”、“建站 Agent”、“供应链 Agent”。如果建站 Agent 成了瓶颈,系统会自动复制出三个并行 Agent 同时干不同的页面。整个过程中,系统持续自动调优每个 Agent 的 prompt,不断重组团队架构。
书里管这叫“目标驱动的、自我变形的多 Agent 系统”。它不是在执行你写的计划,是在自己生成计划、自己调整计划、自己重组执行团队。
这让我想起 Karpathy 的 AutoResearch:写一个 program.md,定义目标、指标、边界,按“启动”。人类在循环外面。但这本书推得更远:连 Agent 团队怎么组建、怎么重组,都交给系统自己决定。人类只声明“要什么”。
三件可以马上做的事
读完这本书,我有三个立刻可以落地的动作:
-
第一,给你现在的 Agent 加一个 Critic。 不管你是用 Claude Code、CrewAI 还是自己搭的框架,在你现有的 workflow 末尾加一步:让另一个 Agent(用不同的 system prompt)审查上一步的输出。代码生成加代码审查,文章撰写加事实核查,计划制定加可行性评审。多一次 LLM 调用,但质量提升往往翻倍。书里的 Producer-Critic 模式是即插即用的。
-
第二,开始做 Context Engineering,不只是 Prompt Engineering。 回头看你写给 Agent 的指令文件。如果全是“你要怎么做”的规则,缺少“你现在面对什么环境”的上下文,补上。告诉 Agent 它现在在哪个项目里、之前做过什么决定、用户偏好是什么。书里的 Context Engineering 那章和你的
AGENTS.md是同一件事的两个表述。 -
第三,先别急着上 Multi-Agent。 把你的单 Agent 做到 Level 2:有工具、有 Reflection、有 Memory。书里反复强调,Level 2 的单 Agent 加上 Producer-Critic 和 Context Engineering,能覆盖绝大多数实际场景。Level 3 是给真正跨领域、多阶段、需要并行分工的任务准备的。大多数人的问题不是 Agent 不够多,是一个 Agent 都没调好。
这本书 453 页,Springer 2025 年出版。代码示例覆盖 LangChain/LangGraph、Google ADK、CrewAI、OpenAI API。前言是 Google Cloud AI VP 写的,还有个 Goldman Sachs CIO 的推荐序,意外地好看。
但我推荐它的理由不是“全面”。是你读完会意识到一件事:你过去半年在 Agent 上踩的坑,都有人整理成模式了。你不需要再去发明 Reflection,不需要再去猜 Memory 该怎么分层,不需要再去试 Multi-Agent 该用哪种通信拓扑。
有人替你画了地图,剩下的就是走。
你在用 AI Agent 做开发吗?你现在的 Agent 到了 Level 几?





