原创 | Odaily星球日报
作者 | 南枳

近期,Layer 2 Manta 的 TVL 和币价迎来长足上涨;ZKF 一度上冲至 0.025 USDT 后现已腰斩,但 TVL 仍然高企;部分 Layer 2 如 zkSync、Linea 也预计将于 24 年发币。
一片火热之下,Odaily星球日报将基于 TVL、市值等多方面数据,进行 Layer 2 之间的比较,横向对比高估低估情况。
新老 L2 的 TVL 与市值对比
根据L2 BEAT 数据,TVL 前十的 Layer 2 如下表所示(其中 Blast TVL 结合 Dune 数据)。同时,Odaily星球日报也综合 Coingecko 将已发币的 Layer 2 代币流通市值和全稀释市值(FDV)一并汇总:
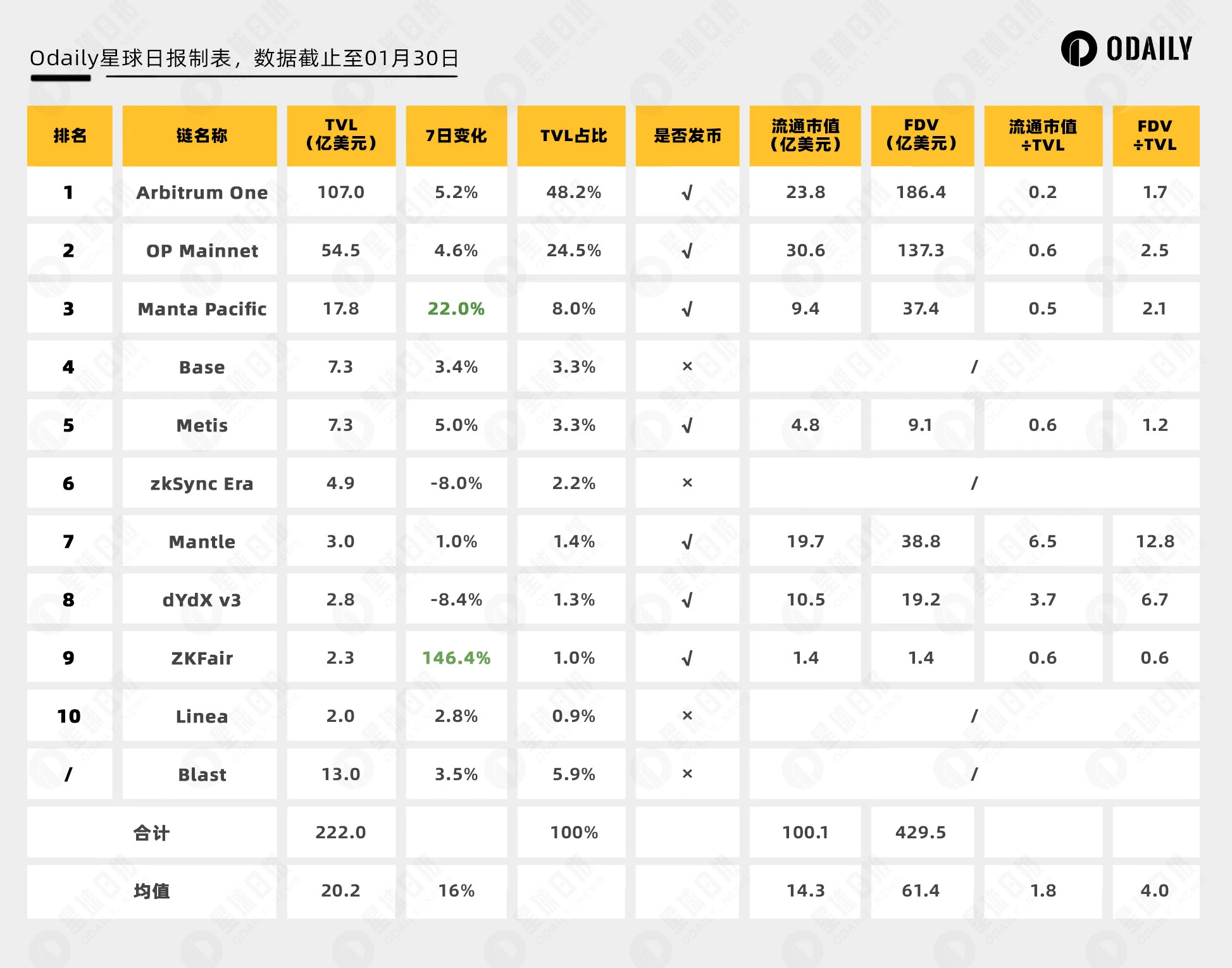
基于下表,存在以下显著特征:
近期仅 Manta、ZKFair TVL 有显著提升,其余 Layer 2 变化不大;
TVL 方面 Arbitrum 和 OP 占据显著的领先地位,并且在该体量下仍有高于中位数的表现;
而 Manta 和 Blast 的 TVL 已经在 Layer 2 之间排行第三和第四;
除 Metis 外,几个“老牌”Layer 2 市值量级接近,均为数十亿美元。
Odaily星球日报在此提出两个计算指标“流通市值/TVL”和“FDV/TVL”,该数值越大,相应代币的高估程度相对越高。其数据和排行如下图所示。
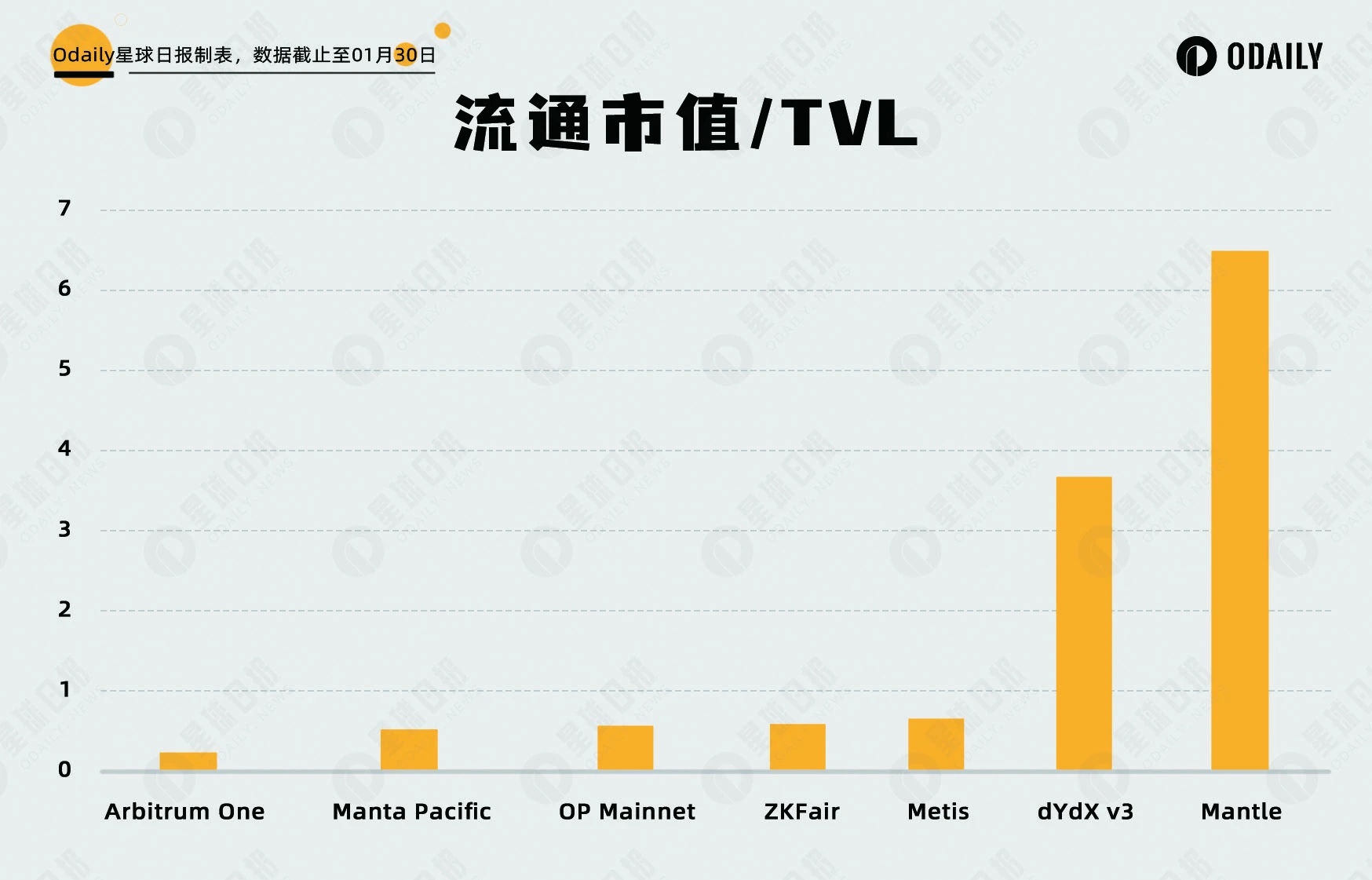
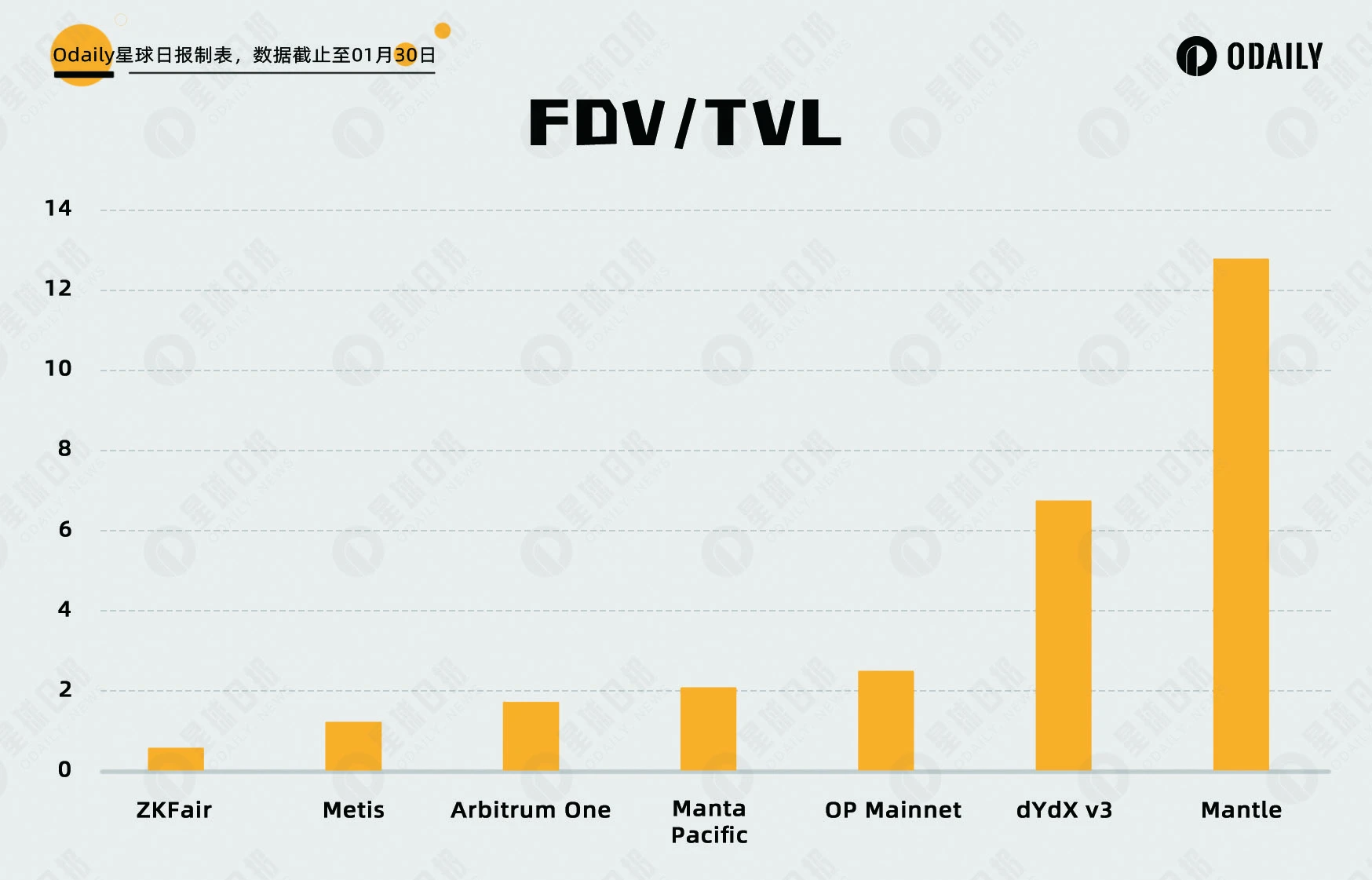
可以看出,快速上涨的 Manta 估值仍处于主流 Layer 2 的平均水平范围内,而 ZKF 在腰斩后的 FDV/TVL 显著低于其他 Layer 2 。
生态活跃对比
根据 DefiLlama 数据,各生态的协议数量、TVL、 24 小时 DEX 交易量如下表所示:
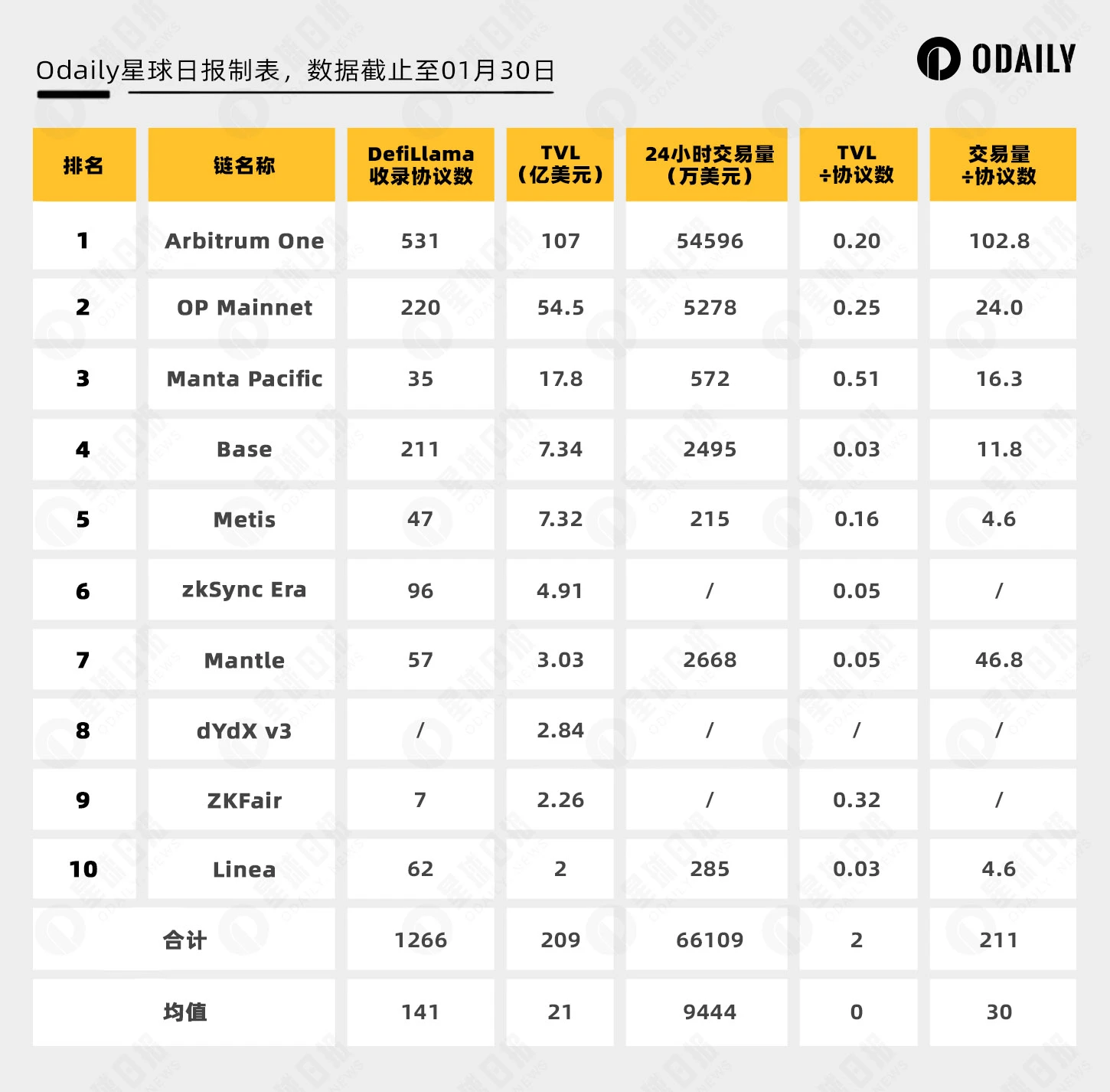
从表中可见:
Arbitrum 在协议数量、TVL、交易量方面全部占据显著领先优势;
Arbitrum、OP、Base 协议数远高于其他 Layer 2 ,ZKF 显著少于其他 Layer 2 。
Odaily星球日报在此提出两个计算指标“TVL/协议数”和“交易量/协议数”,体现了资金和活动的分散程度,低数值代表资金在协议之间分布均匀,用户对特定协议没有使用偏好。而高数值代表着该生态有明星协议,或集中于某个协议刷量的两种可能性。
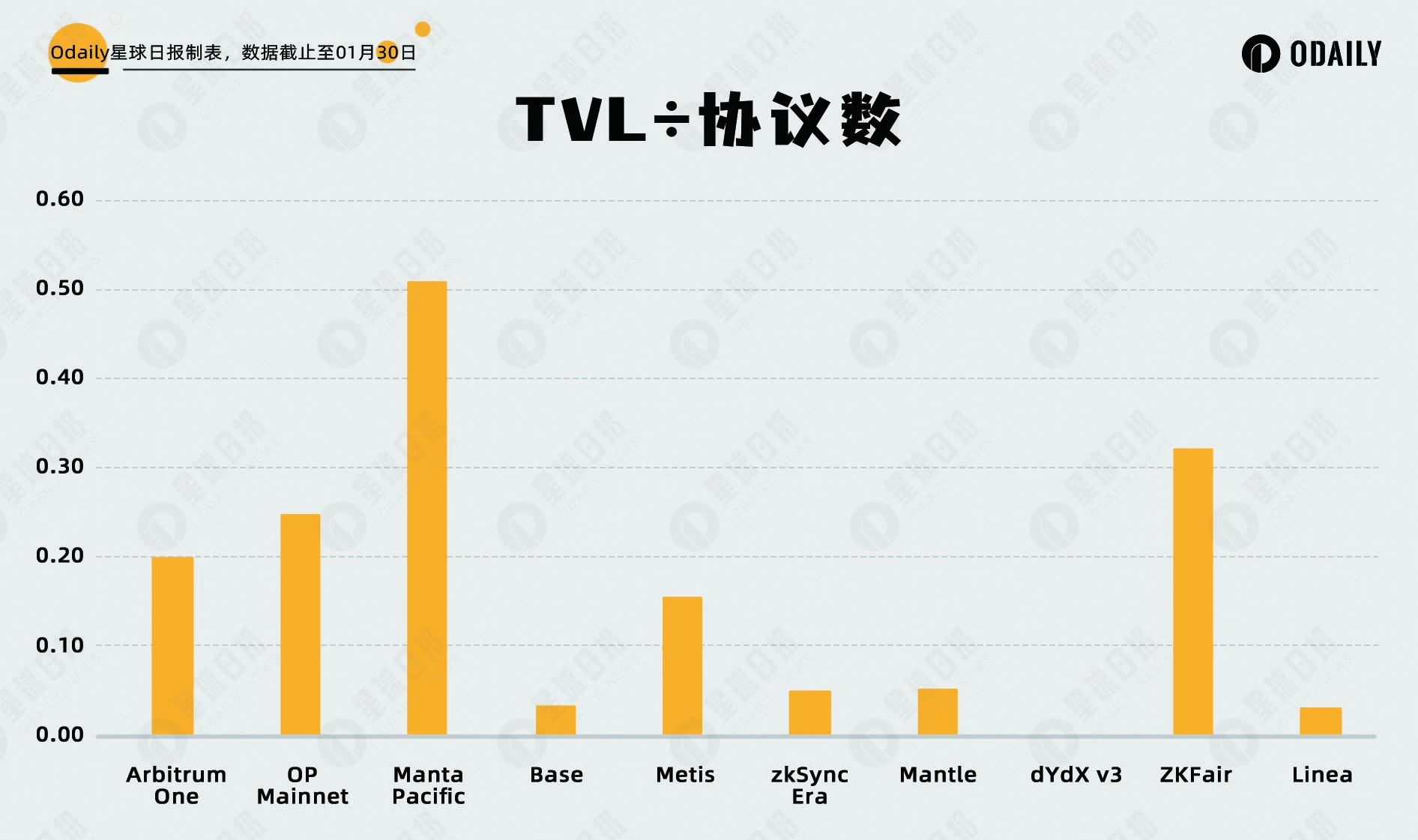
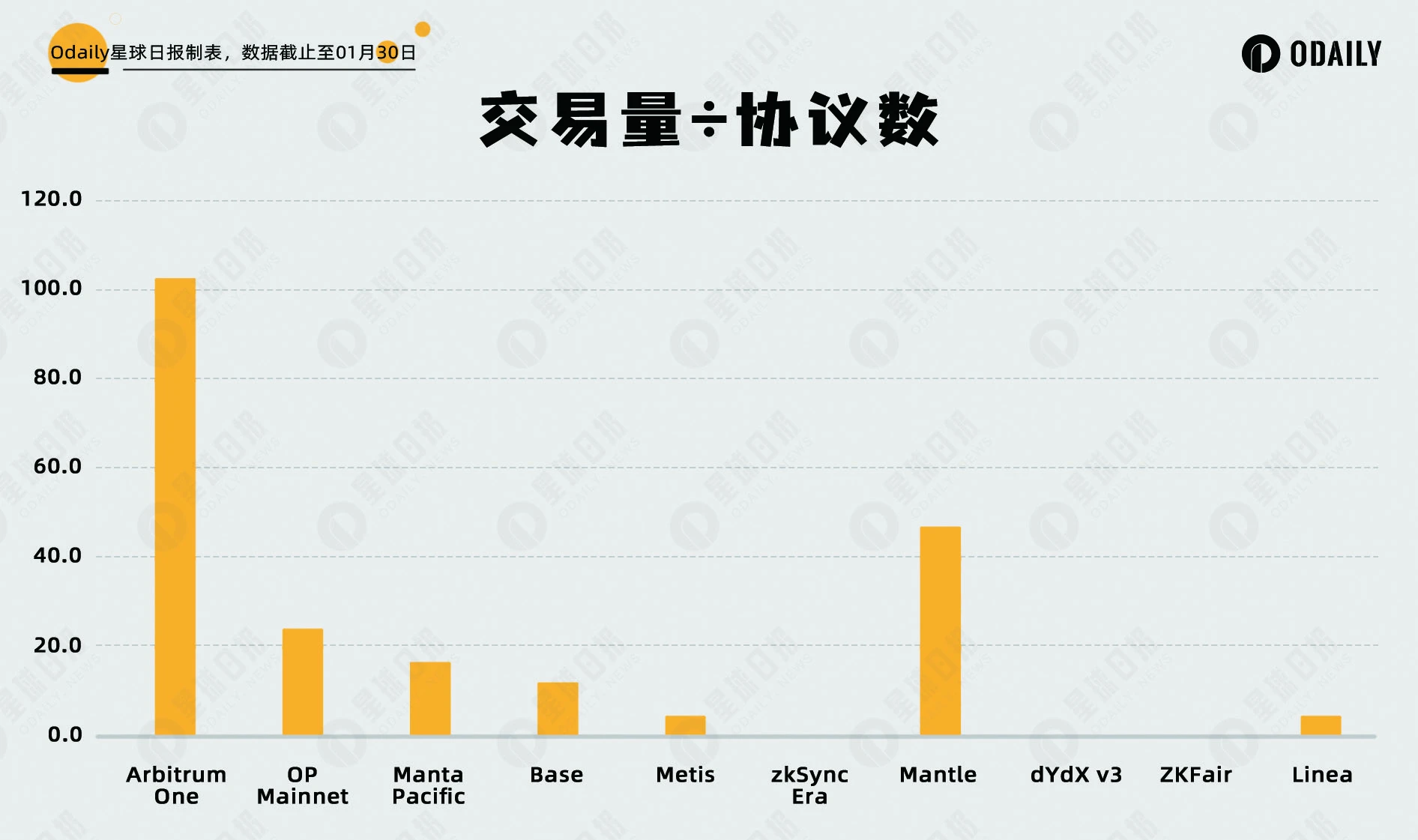
结论
基于以上数据,Manta 和 ZKF 近期的增长属于是向 Layer 2 平均估值水平的回归,目前已经处于平均线附近。Odaily星球日报在此提示,TVL 等数据受活动和发展阶段影响较大,不足以作为完整的决策基础,建议读者综合其他数据研究和决策。





