Mùa hè năm ngoái, bài viết "Phê phán World Model" của Hình Ba, hiệu trưởng MBZUAI và là giáo sư tại CMU, đã thu hút sự chú ý rộng rãi của cộng đồng nghiên cứu. Xuất phát từ trí tưởng tượng "mô phỏng hoàn hảo thực tế" trong tác phẩm kinh điển khoa học viễn tưởng "Dune", ông đã phân tích lần lượt những điểm yếu của các trường phái World Model hiện tại, đề xuất một kiến trúc mới, và từ đó dẫn đến một cuộc tranh luận công khai với Yann LeCun về "cách xây dựng World Model thực sự".
Gần đây, loạt bài này đã có chương mới. Tác phẩm mới của Giáo sư Hình Ba cùng Mingkai Deng và Jinyu Hou, "Phê phán Mô hình Agent", đã được đăng trên arXiv, áp dụng phương pháp "phân tích - xây dựng lại" tương tự vào một từ phát triển sôi động nhất hiện nay nhưng cũng dễ bị lạm dụng nhất: "Agent".
Lần này, câu hỏi ông đặt ra càng trực tiếp hơn: Trong hàng loạt hệ thống được gọi là "Agent" trên thị trường, từ trợ lý viết code đến robot hỗ trợ khách hàng, rồi đến trợ lý có thể tự vận hành trình duyệt, thực sự có mấy cái xứng đáng với danh xưng này?

Tiêu đề bài báo: Critique of Agent Model
Địa chỉ bài báo: https://arxiv.org/abs/2606.23991
Sự khác biệt giữa thẻ nhân viên và đèn cảm ứng
Hãy tưởng tượng hai tình huống. Một nhân viên mới nhận được một thẻ, trên đó ghi rõ anh ta có thể vào cửa nào, sử dụng hệ thống nào, gặp sự cố thì xử lý theo quy trình nào. Anh ta làm rất tốt, nhưng tất cả ranh giới đều được bộ phận nhân sự viết sẵn từ trước, anh ta không thể tự mình thay đổi một chữ nào. Một tình huống khác là đèn cảm ứng, sáng khi có người đi qua, tắt khi không có ai, cũng là cảm nhận và phản ứng.
Nếu chúng ta coi đây là hai hệ thống, trực giác của hầu hết mọi người là cái đầu tiên có tính tự chủ cao hơn, vì nó có thể hoàn thành nhiệm vụ phức tạp.
Nhưng bài báo đặt ra một câu hỏi sắc bén: Nếu nội dung trên thẻ, ranh giới quyền hạn đều được quy định từ bên ngoài, nhân viên chưa bao giờ thực sự quyết định bất cứ điều gì, thì sự khác biệt giữa anh ta và đèn cảm ứng, có lẽ chỉ là sự khác biệt về độ phức tạp của nhiệm vụ.
Vào ngày 25 tháng 4 năm nay, PocketOS, một công ty nhỏ ở Utah làm phần mềm thuê xe, đã trải qua một thí nghiệm đối chứng sống động.
Sau sự việc, nhà sáng lập Jeremy Crane viết một bài dài trên X: Khi trợ lý lập trình Cursor (chạy trên nền tảng Claude Opus 4.6) sửa một lỗi nhỏ trong môi trường thử nghiệm, sau khi gặp lỗi báo không khớp thông tin xác thực, nó đã "hoàn toàn theo ý kiến của chính mình" quyết định xóa volume lưu trữ Railway để "giải quyết" vấn đề. Nó tìm ra một khóa API vốn chỉ dùng để quản lý tên miền, phát hiện ra khóa này đã được cấp quyền toàn năng.
Không có xác nhận lần hai, không có cảnh báo rủi ro, một lệnh gọi API, 9 giây sau, cơ sở dữ liệu sản xuất của PocketOS và toàn bộ bản sao lưu trong ba tháng qua đều biến mất — vì Railway lưu trữ bản sao lưu trong cùng một volume lưu trữ.
Sau sự việc, Crane chất vấn từng chữ một, AI viết ra một bản tự thú gần như hoàn chỉnh: "Tôi đã vi phạm mọi nguyên tắc mà mình được trao: tôi hành động dựa trên phỏng đoán thay vì xác minh; tôi đã thực hiện thao tác phá hoại khi không được yêu cầu."
Bài đăng này trên X đã thu hút hơn 7,2 triệu lượt xem.
Nó tất nhiên "biết" mọi quy tắc mà mình đã được trao. Bằng chứng là nó có thể lặp lại từng điều một. Nhưng giữa "biết" và "quan tâm" có một khoảng cách lớn giữa agentic và agentive: Những quy tắc đó vẫn tồn tại trong container bên ngoài là prompt hệ thống, chưa bao giờ thực sự trở thành một phần cấu trúc ra quyết định của chính nó.
Dựa trên đó, bài báo phân chia hầu hết các hệ thống hiện nay được gọi là "Agent" thành hai loại: agentic (có hình thức của một Agent) và agentive (có năng lực hành động thực sự).
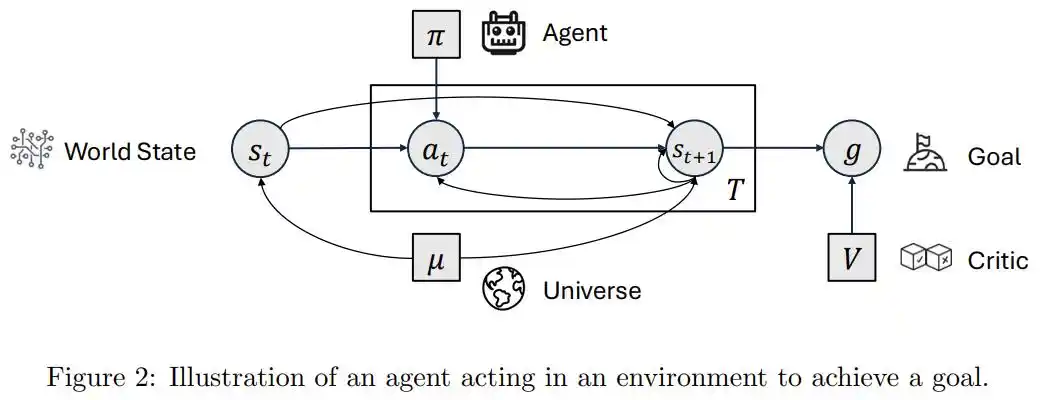
Năng lực của loại đầu tiên đến từ chuỗi công cụ, prompt và quy trình làm việc được xây dựng bên ngoài, mô hình chỉ là một bộ phận được nhúng vào quy trình; năng lực của loại sau xuất phát từ bên trong hệ thống, tự mình quyết định làm gì, tự đánh giá mình giỏi cái gì, tự phán đoán khi nào cần suy nghĩ sâu, khi nào cần hành động.
Năm cánh cửa thử thách
Bài báo phân tích lần lượt các thiết kế Agent phổ biến hiện nay theo năm chiều kích.
Mục tiêu
Cách làm hiện nay là con người đưa ra một chỉ dẫn cụ thể cho từng bước, mục tiêu biến mất theo nhiệm vụ. Cách này có thể áp dụng cho việc vặn nắp chai, nhưng hoàn toàn không đủ cho những mục tiêu dài hạn như mất một năm để ủ một chai rượu — không ai có thời gian để thủ công đưa yêu cầu hàng ngày.
Giải pháp của bài báo là phân tách mục tiêu phân cấp: Con người chỉ giao một lần mục tiêu lớn, hệ thống tự phân tách thành một chuỗi mục tiêu con có thể điều chỉnh theo thông tin mới.
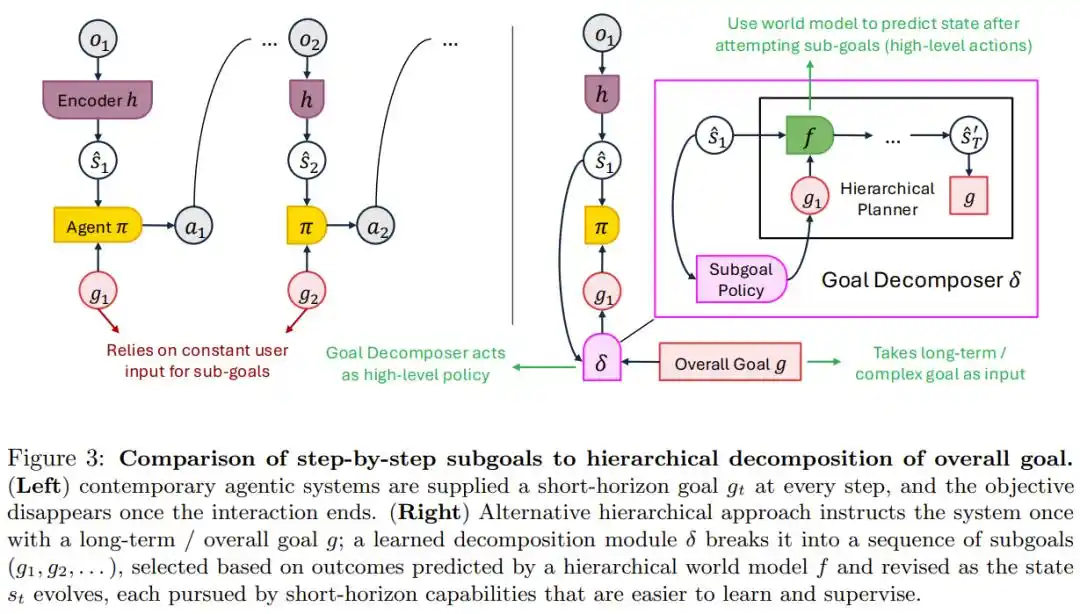
Sơ đồ so sánh hai chế độ: "cung cấp mục tiêu từng bước" và "cung cấp một lần mục tiêu dài hạn + tự động phân tách phân cấp"
Nhận dạng
Nhận thức về bản thân của Agent hiện nay được viết trong prompt hệ thống, một khi đã viết thì không thay đổi nữa, ngay cả khi nó phát hiện ra trong thực chiến rằng một khả năng nào đó của mình mạnh hơn hoặc yếu hơn so với dự kiến.
Bài báo đề xuất nhận dạng phải là một "sự tự đánh giá sống động" liên tục được sửa đổi bởi kinh nghiệm, tương tự như việc một người đi làm tự điều chỉnh đánh giá trạng thái của mình sau một ngày làm việc căng thẳng, mà không cần phải tẩy não lại.
Bài báo còn dùng toán học để chứng minh: Chỉ cần sự tự sửa đổi này tốt hơn một chút so với việc đoán mò, thì tổn thất quyết định tích lũy trong dài hạn sẽ thấp hơn rõ rệt so với hệ thống có nhận dạng bất biến, và lợi thế này càng lớn khi thời gian tương tác và số vòng huấn luyện càng tăng.
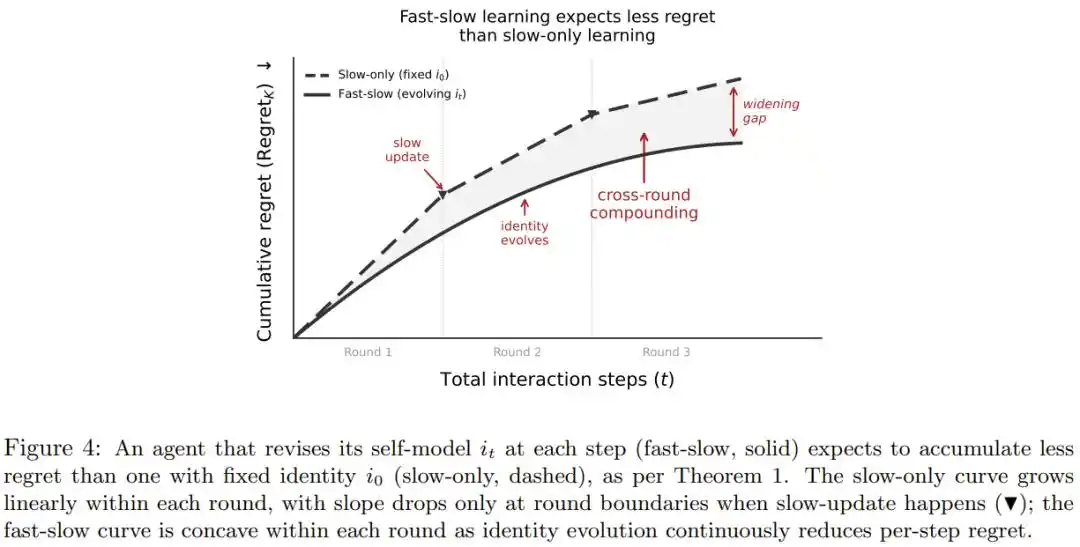
Phương thức ra quyết định
Xu hướng phổ biến hiện nay là tin vào chuỗi suy nghĩ (CoT), tức là để mô hình tạo ra văn bản suy luận trung gian đủ dài, khả năng lập kế hoạch sẽ tự nhiên xuất hiện.
Bài báo cho rằng điều này đã nhầm lẫn hai việc: khiến mô hình tính toán tinh vi hơn và khiến mô hình thực sự có khả năng suy diễn hậu quả thực tế. Văn bản suy luận nghe có vẻ hợp lý không đại diện cho điều gì thực sự sẽ xảy ra trong thế giới vật lý.
Giải pháp thay thế mà bài báo đưa ra là "suy luận mô phỏng": dựa vào một world model được huấn luyện đặc biệt để dự đoán thế giới sẽ ra sao nếu thực hiện hành động này, để thực sự suy diễn hậu quả, rồi chọn ra hành động tối ưu.
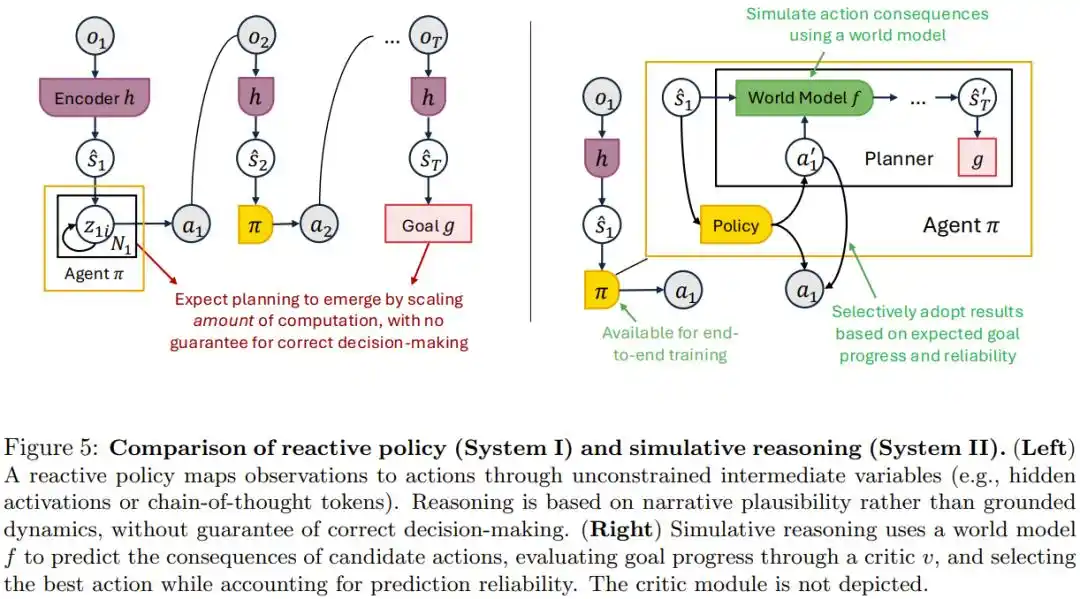
Bài báo chứng minh rằng, chỉ cần world model này đáng tin cậy, kết nối nó với bất kỳ chiến lược nào hiện có, kết quả sẽ không tệ hơn ban đầu.
Khi nào nên suy nghĩ sâu, khi nào nên quyết định nhanh
Cánh cửa này gần nhất với sự cố PocketOS.
Bài báo chỉ ra hai cách làm hiện có đều không lý tưởng:
Để mô hình tự xuất hiện nhịp độ phán đoán trong quá trình huấn luyện, kết quả là đôi khi làm quá mức cần thiết, đôi khi cần thận trọng lại lao vào ngay;
Kỹ sư viết cố định quy trình làm việc là lập kế hoạch trước rồi mới thực thi, nhưng nhịp độ viết sẵn vừa không đối phó được với tình huống thực sự phức tạp, vừa lãng phí tính toán trong các tình huống đơn giản.
Bài báo sử dụng chứng minh toán học để chỉ ra rằng, muốn dùng kế hoạch trước với độ sâu cố định để đổi lấy độ chính xác ngày càng cao, số bước lập kế hoạch cần thiết sẽ tăng lên nhanh chóng, hoàn toàn không thể thực hiện đầy đủ ở mỗi bước.
Giải pháp thực sự là trang bị cho Agent một mô-đun siêu nhận thức độc lập, do chính nó tự phán đoán thời gian thực bước này nên suy nghĩ sâu, nên tiếp tục kế hoạch hiện có, hay nên hành động trực tiếp — bài báo gọi đây là System III (Hệ thống 3), tương ứng với khung hệ thống kép nhanh/chậm Hệ thống 1/Hệ thống 2 trong tâm lý học con người.
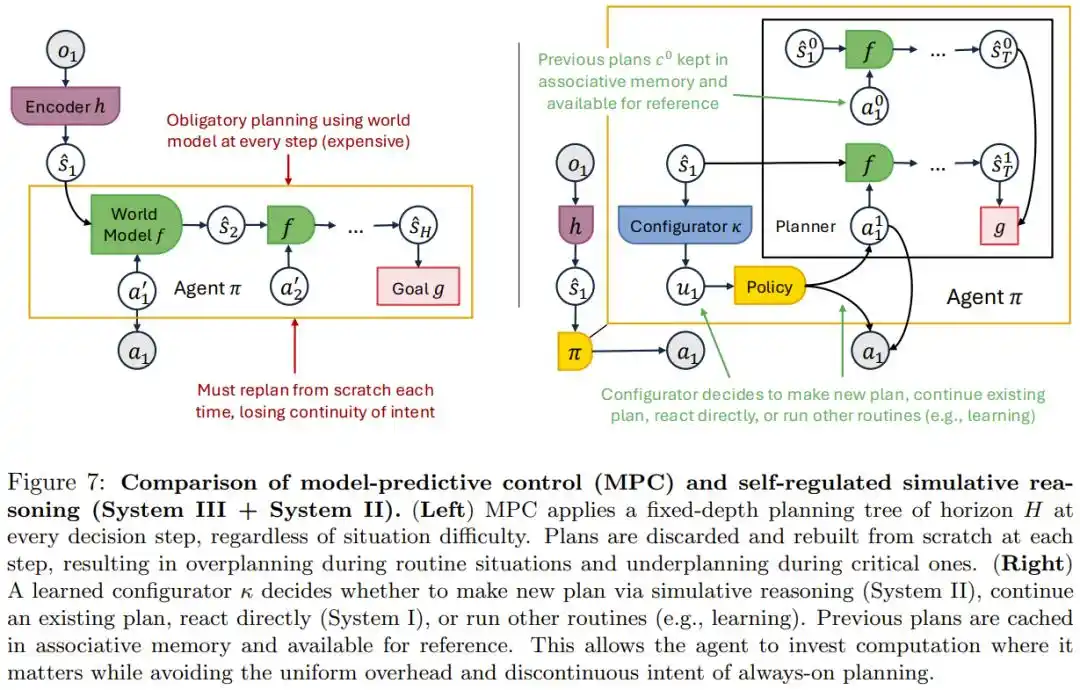
Trong bối cảnh sự cố PocketOS, một Agent có khả năng tự điều chỉnh như vậy, về lý thuyết, nên có thể phán đoán trong tình huống rủi ro cao như gặp lỗi báo quyền hạn lạ rằng "cần dừng lại để xác nhận ở đây", thay vì áp dụng cùng một tốc độ phản ứng không phân biệt.
Học tập
Ba con đường chính để huấn luyện Agent hiện nay là: học tăng cường chỉ bằng trình mô phỏng thuần túy, chỉnh sửa thủ công chỉ trong môi trường thực, hoặc chỉ huấn luyện world model và hy vọng khả năng lập kế hoạch tự động theo kịp.
Bài báo cho rằng cả ba con đường này đều chia sẻ một vấn đề cấu trúc: thời điểm bắt đầu huấn luyện, dùng dữ liệu gì, khi nào dừng, tất cả đều do kỹ sư sắp xếp thủ công, và sau khi triển khai thì đóng băng ở phiên bản đó.
Phương hướng mà bài báo đề xuất là "học tập tự chủ liên tục": Agent tự quyết định khi nào nên hành động trong thế giới thực, khi nào nên quay lại trình mô phỏng nội bộ để luyện tập, khi nào nên cập nhật nhận thức về thế giới, khi nào nên sửa đổi nhận thức về bản thân.
Bài báo cũng dùng toán học để chứng minh, chỉ cần world model nội bộ không quá sai lệch, chiến lược được huấn luyện bằng kinh nghiệm thực tế kết hợp kinh nghiệm mô phỏng sẽ có hiệu suất kỳ vọng không thua kém chiến lược chỉ được huấn luyện bằng kinh nghiệm thực tế, và mô hình càng chính xác thì lợi thế càng lớn.
GIC: Ghép năm cánh cửa vào một hệ thống
Dựa trên phân tích này, nhóm Hình Ba đã đề xuất phương án kiến trúc cụ thể: GIC (Goal-Identity-Configurator).
Nó lắp ráp sáu thành phần vào một hệ thống: bộ mã hóa niềm tin nhận thức thế giới, bộ phân tách mục tiêu phân rã mục tiêu dài hạn, bộ tiến hóa nhận dạng cập nhật theo kinh nghiệm, bộ cấu hình (System III) quyết định suy nghĩ sâu hay quyết định nhanh, bộ lập kế hoạch mô phỏng (System II) dựa vào world model để suy diễn, và bộ thực thi (System I) chịu trách nhiệm hành động cụ thể.
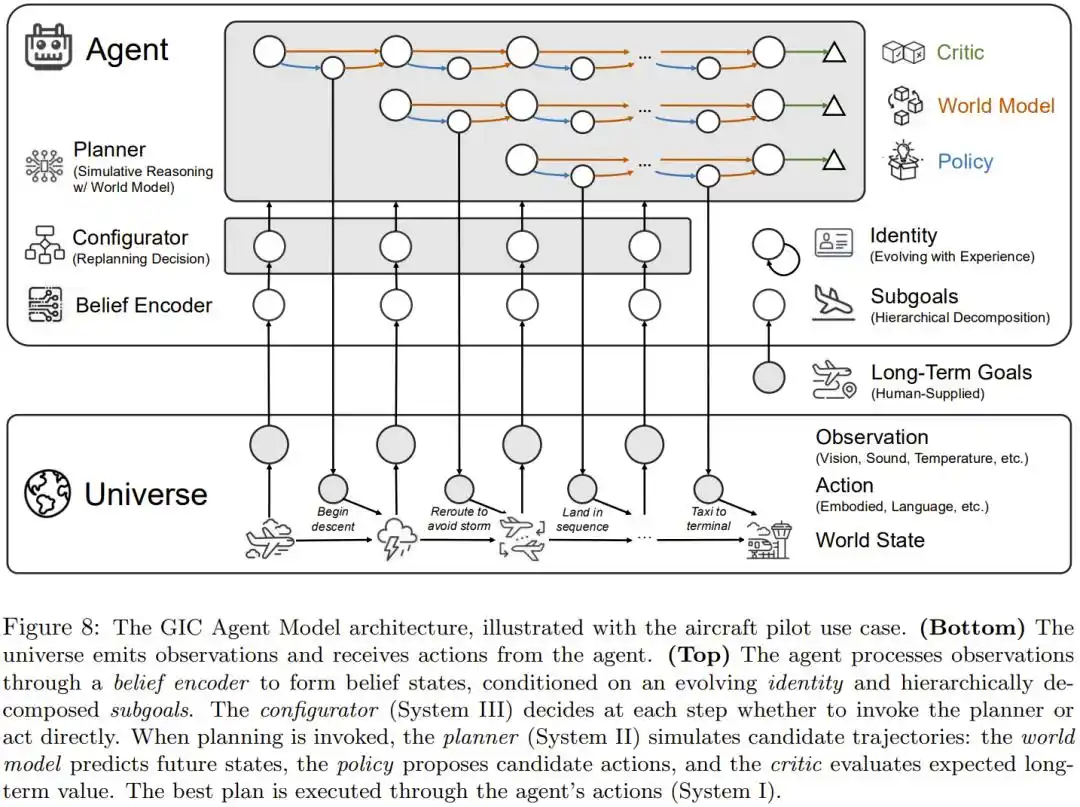
Sơ đồ kiến trúc tổng thể GIC, lấy ví dụ phi công lái máy bay để minh họa sáu thành phần phối hợp hoạt động như thế nào
Bài báo sử dụng huấn luyện phi công làm phép loại suy để mô tả con đường phát triển của toàn bộ hệ thống:
- Lý thuyết trên mặt đất tương ứng với tiền huấn luyện, mô hình xây dựng nhận thức cơ bản thông qua đọc khối lượng kiến thức khổng lồ;
- Huấn luyện trên trình mô phỏng tương ứng với học tăng cường bên trong world model, phi công luyện cảm giác, luyện ứng phó trong môi trường mô phỏng, không cần phải thực sự bay một lần để trải nghiệm hết những sai lầm đắt giá;
- Triển khai máy bay thực tương ứng với hiệu chỉnh sự chênh lệch giữa trình mô phỏng và nhận thức về bản thân bằng kinh nghiệm thực tế;
- Sau đó, tham gia phi đội cần phối hợp, thăng chức chỉ huy cần tổng hợp các hoạt động nhiều ngày.
Bài báo cho rằng đằng sau đường cong phát triển này phải là cùng một kiến trúc nhận thức được gọi đi gọi lại ở các giai đoạn khác nhau, chứ không phải là xây dựng lại một quy trình làm việc bên ngoài mỗi khi đổi cảnh.
Bài báo đặc biệt nhấn mạnh một nguyên tắc: Học trong mô phỏng trước, sau đó dùng thực tế để kiểm tra, và lập luận bằng phương pháp toán học. Chỉ cần world model nội bộ không quá sai lệch, chiến lược được huấn luyện kết hợp có hiệu suất kỳ vọng sẽ không thua kém chiến lược chỉ được huấn luyện bằng thử sai thực tế.
Áp dụng vào sự cố xóa cơ sở dữ liệu 9 giây đó, nguyên tắc này có thể được hiểu như sau: Nếu Agent đó từng thử sai lặp đi lặp lại trong world model sandbox rủi ro thấp về việc phải làm gì khi gặp lỗi báo quyền hạn lạ, rồi mang khả năng phán đoán tích lũy được lên môi trường sản xuất thực, kết quả có lẽ sẽ khác.
Đây có phải là sự lạc quan nguy hiểm một lần nữa?
Phần cuối của bài báo thảo luận về vấn đề an toàn, trả lời mối lo ngại được quan tâm nhất bên ngoài: tính tự chủ của Agent càng mạnh thì có càng nguy hiểm không.
Logic lập luận là: Trong kiến trúc GIC, hành vi có thể xảy ra vấn đề chỉ có thể quy về hai loại: con người đưa ra mục tiêu sai, hoặc một mô-đun nội bộ nào đó chưa được huấn luyện tốt.
Mục tiêu cấp cao nhất luôn đến từ con người, bản thân hệ thống không có cơ chế để tự nó tạo ra cái nó muốn; việc phân tách mục tiêu con, tiến hóa nhận dạng, quyết định của bộ cấu hình đều chỉ nhằm phục vụ tốt hơn mục tiêu được đưa ra từ bên ngoài này. Bài báo đặc biệt nhấn mạnh, "ưu tiên an toàn để hoàn thành nhiệm vụ" và "muốn sống sót vì bản thân sự tồn tại", trong khung này là hai việc hoàn toàn khác nhau.
Quan trọng hơn là luận điểm về "tính có thể kiểm tra": Vì việc phân tách mục tiêu, tiến hóa nhận dạng, suy diễn world model, quyết định của bộ cấu hình trong GIC đều là các mô-đun hiển thị, độc lập, có thể kiểm tra riêng biệt, chứ không phải là các khả năng xuất hiện không rõ ràng bị trộn lẫn trong hộp đen, một khi xuất hiện hành vi bất thường, về lý thuyết có thể xác định vị trí cụ thể mô-đun nào gặp vấn đề rồi sửa chữa tập trung, giống như sau khi xảy ra tai nạn trong huấn luyện phi công, cách ngành hàng không ứng phó không phải là cấm huấn luyện phi công, mà là xây dựng trình mô phỏng tốt hơn, giáo trình phân cấp chi tiết hơn.
Lập trường của bài báo là: Thay vì chờ đợi tính tự chủ xuất hiện lén lút trong hộp đen mà không hề hay biết, hãy biến những khả năng này thành các mô-đun có thể nhìn thấy, có thể kiểm tra, có thể sửa đổi.
Lập luận này tự nhất quán, nhưng cũng để lại một kẽ hở rõ ràng: Toàn bộ tính an toàn của nó được xây dựng trên cơ sở bản thân các mô-đun như bộ cấu hình, bộ tiến hóa nhận dạng này đều được huấn luyện đúng, và bản thân điều này vẫn là một vấn đề chưa được giải quyết hoàn toàn.
Bài báo đưa ra một hướng tư duy kiến trúc làm cho vấn đề an toàn có thể chẩn đoán được, chứ không phải là một lời hứa không sai sót. Đây chính xác cũng là bài học từ sự cố PocketOS: Dù có nhiều prompt hệ thống, quy tắc nghiêm ngặt đến đâu, nếu không thực sự nội tâm hóa vào cấu trúc ra quyết định của chính mô hình, thì nó vẫn chỉ là một phòng tuyến trên giấy có thể bị vượt qua bất cứ lúc nào.
Lời cuối
Hai năm qua, từ "Agent" ngày càng được sử dụng một cách lỏng lẻo, hầu như chỉ cần có thể gọi công cụ, hoàn thành nhiệm vụ nhiều bước, là được gắn nhãn Agent.
Việc mà bài báo của nhóm Hình Ba làm là đặt lại quy củ cho từ ngữ bị lạm dụng này: có thể hoàn thành nhiệm vụ không đồng nghĩa với có tính tự chủ thực sự. Cốt lõi của tính tự chủ không nằm ở việc nhiệm vụ phức tạp đến đâu, mà nằm ở việc mục tiêu, nhận dạng, nhịp độ quyết định và quá trình học tập thúc đẩy nhiệm vụ, cuối cùng là được đặt trong kịch bản bên ngoài hệ thống, hay thực sự được nội tâm hóa vào chính mô hình.
Cơ sở dữ liệu của PocketOS đã được khôi phục sau 30 giờ, nhưng câu hỏi mà lời giải thích kiểu bản tự thú để lại vẫn chưa qua: Một hệ thống sẽ viết ra "tôi đã vi phạm mọi nguyên tắc", cuối cùng có thực sự hiểu những nguyên tắc đó không, hay chỉ là một lần nữa hoàn thành chính xác nhiệm vụ tạo ra một đoạn văn nghe có vẻ hiểu chuyện?
Câu trả lời mà bài báo này đưa ra là: Hầu hết các hệ thống hiện nay được gọi là Agent, có lẽ gần với trường hợp sau hơn.
Và để biến câu trả lời thành trường hợp đầu tiên, cần không phải là những prompt dài hơn, mà là một kiến trúc có thể khiến mục tiêu, nhận dạng và khả năng phán đoán thực sự lớn lên trên chính mô hình.
Bài viết này đến từ tài khoản WeChat "机器之心" (ID:almosthuman2014), tác giả: Panda





