Cuối năm 2024, một bài báo có tiêu đề "Học tăng cường sâu dạng luồng cuối cùng đã chạy thông suốt" (arXiv:2410.14606) đã gây ra cuộc thảo luận sôi nổi trong giới học thuật. Tác giả đến từ nhóm Mahmood tại Đại học Alberta, họ đã dành nhiều trang để mô tả một thực tế đáng ngượng: Học tăng cường vốn là một phương pháp "học trong khi làm", nhưng trong thời đại mạng nơ-ron sâu, nó hầu như không thể làm được điều đó. Chỉ cần loại bỏ bộ đệm phát lại, chỉ cần đặt kích thước lô là 1, quá trình huấn luyện sẽ sụp đổ. Họ gọi đây là "rào cản luồng" (stream barrier).
Thuật toán StreamX được đề xuất trong bài báo đó, dựa vào các siêu tham số được điều chỉnh tinh vi, khởi tạo thưa thớt và các kỹ thuật ổn định hóa khác nhau, đã may mắn vượt qua bức tường này.
Tuy nhiên, chưa đầy một năm rưỡi sau, một thành viên của cùng nhóm nghiên cứu đó, cùng với các cộng tác viên từ Viện Openmind, đã đưa ra một câu trả lời hoàn toàn khác: Nguồn gốc của rào cản luồng không phải là "dữ liệu không đủ nhiều", mà là "bước học đã chọn sai đơn vị".

Tiêu đề bài báo: Intentional Updates for Streaming Reinforcement Learning
Địa chỉ bài báo: https://arxiv.org/pdf/2604.19033v1
Kho mã nguồn: https://github.com/sharifnassab/Intentional_RL
Một lần đạp ga, tạo ra hố lớn thế nào
Hãy tưởng tượng bạn đang học lái xe và đỗ xe. Người hướng dẫn nói với bạn mỗi lần "đạp ga 0.1 giây". Vấn đề là, cùng đạp ga 0.1 giây, lên dốc, xuống dốc, không tải, đầy tải, quãng đường xe tiến lên có thể khác nhau một trời một vực. Đôi khi chỉ thiếu một centimet là đỗ vừa khít, đôi khi thiếu 30 centimet và đâm thẳng vào tường.
Bước học (learning rate) truyền thống trong học dựa trên gradient, làm chính xác điều này: nó quy định tham số di chuyển bao nhiêu mỗi lần, nhưng không kiểm soát được đầu ra của hàm số thực sự thay đổi bao nhiêu. Trong huấn luyện theo lô, lỗi trung bình từ hàng trăm, hàng nghìn mẫu làm loãng các trường hợp cực đoan, vấn đề không quá rõ ràng. Nhưng trong môi trường "luồng", mỗi bước chỉ có một mẫu, không có sự trung bình nào. Một khi hướng gradient không ổn định, biên độ cập nhật sẽ lúc lớn lúc nhỏ — hôm nay tiến 30 centimet, ngày mai lùi 50 centimet, quá trình học sụp đổ trong dao động dữ dội.
Hiện tượng "vượt quá và không đủ" (overshooting and undershooting) này đặc biệt nghiêm trọng trong học tăng cường, vì gradient ở mỗi bước thời gian không chỉ khác nhau về độ lớn mà hướng cũng thay đổi cực nhanh.
Định nghĩa lại "một bước nên làm bao nhiêu"
Arsalan Sharifnassab từ Viện Openmind cùng Mohamed Elsayed, A. Rupam Mahmood và Richard Sutton từ Đại học Alberta, trong bài báo gần đây, đã đề xuất một giải pháp suy nghĩ từ một góc độ khác: Thay vì chỉ định tham số di chuyển bao nhiêu, hãy trực tiếp chỉ định đầu ra hàm số nên thay đổi bao nhiêu.
Ý tưởng này không phải xuất hiện từ hư không. Năm 1967, học giả Nhật Bản Nagumo và Noda trong bài báo "A learning method for system identification" đã đề xuất thuật toán "Bình phương sai số trung bình tối thiểu chuẩn hóa" (NLMS) trong lĩnh vực lọc thích ứng; về bản chất cũng là sử dụng sự thay đổi đầu ra mong muốn để suy ngược bước học, chứ không phải ngược lại. Chỉ có điều thuật toán đó chỉ áp dụng được cho các tình huống tuyến tính đơn giản.
Các nhà nghiên cứu đã mở rộng ý tưởng này cho học tăng cường sâu. Họ gọi nó là "Cập nhật có chủ đích" (Intentional Updates): Trước mỗi lần cập nhật, đầu tiên xác định rõ "tôi hy vọng bước này đạt được điều gì", sau đó suy ra nên sử dụng bước học lớn bao nhiêu.
Đối với học giá trị (tức dự đoán phần thưởng tương lai), chủ đích họ định nghĩa là: Sau mỗi lần cập nhật, lỗi dự đoán giá trị của trạng thái hiện tại nên thu nhỏ một tỷ lệ cố định — ví dụ thu nhỏ 5%, không nhiều cũng không ít. Đối với học chính sách (tức tối ưu hóa hành vi quyết định), chủ đích họ định nghĩa là: Xác suất lựa chọn hành động hiện tại, mỗi bước chỉ cho phép thay đổi một lượng "vừa phải".
Dùng phép ẩn dụ lái xe: Điều này giống như tài xế trước mỗi thao tác quyết định trước "tôi muốn xe tiến lên 20 centimet", sau đó tự động tính toán nên đạp ga sâu bao nhiêu dựa trên tình trạng đường (độ dốc, tải trọng), thay vì mỗi lần đều đạp cùng một độ sâu và phó mặc cho số phận.
Nhà đạt giải Turing và mảnh ghép của ông
Một trong những tác giả của bài báo, là Richard S. Sutton — người đạt giải Turing năm 2024, được mệnh danh rộng rãi là "cha đẻ của học tăng cường hiện đại".
Vị thế của Sutton trong giới học thuật có lẽ tương đương với Feynman trong vật lý: Ông không chỉ đề xuất hai khuôn khổ nền tảng của học tăng cường hiện đại là Học sai phân thời gian (TD learning) và Gradient chính sách (policy gradient), mà còn đồng tác giả với Andrew Barto cuốn sách giáo khoa có thẩm quyền nhất trong lĩnh vực này "Reinforcement Learning: An Introduction" (hiện đã xuất bản đến ấn bản thứ hai, có thể đọc trực tuyến miễn phí). Ông và Barto đã cùng chia sẻ giải Turing năm 2024, lời bình của giải thưởng là "đặt nền móng khái niệm và thuật toán cho học tăng cường".
Sau khi nhận giải, Sutton không chọn nghỉ hưu, mà đầu tư tiền thưởng vào Viện Openmind do ông sáng lập, chuyên tài trợ cho những nhà nghiên cứu trẻ sẵn sàng khám phá các vấn đề cơ bản trong "môi trường không bị áp lực thương mại". Bài báo mới này, chính là xuất phát từ tổ chức phi lợi nhuận này.
Còn tác giả chính Sharifnassab, trước đó vừa công bố tại ICML 2025 khung MetaOptimize, nghiên cứu cách tự động điều chỉnh tốc độ học trực tuyến. Hai chủ đề có sự tập trung rất trùng khớp: Làm thế nào để bản thân bước học trở nên thông minh hơn.
Chi tiết thuật toán: Đơn giản hơn tưởng tượng
Việc suy luận toán học của "Cập nhật có chủ đích" không phức tạp, công thức cốt lõi của nó có thể mô tả trong một câu: Bước học bằng "lượng thay đổi đầu ra mong muốn" chia cho "ảnh hưởng thực tế của hướng gradient lên đầu ra".
Trong học giá trị, "ảnh hưởng thực tế" này là chuẩn (norm) của vector gradient (tương đương với đo độ "dốc" của vùng tham số hiện tại): Càng dốc thì bước học càng nhỏ, càng bằng phẳng thì bước học càng lớn, nhờ đó đảm bảo mỗi lần cập nhật tác động nhất quán lên hàm giá trị.
Trong học chính sách, "lượng thay đổi mong muốn" được định nghĩa tỷ lệ với hàm lợi thế: Hành động hiện tại tốt hơn mức trung bình bao nhiêu, chính sách sẽ di chuyển về hướng đó bấy nhiêu — thông qua một trung bình động để chuẩn hóa cấp độ, đảm bảo về lâu dài biên độ thay đổi chính sách ổn định trong một phạm vi có thể giải thích được.
Các nhà nghiên cứu còn kết hợp ý tưởng cốt lõi này với hai thực hành kỹ thuật: Thu nhỏ theo đường chéo kiểu RMSProp (xử lý sự khác biệt cấp độ giữa các chiều tham số) và vết đủ tư cách (eligibility traces, giúp tín hiệu phần thưởng lan truyền về các bước thời gian trước đó).
Cuối cùng hình thành ba thuật toán hoàn chỉnh: Intentional TD (λ) dùng cho dự đoán giá trị, Intentional Q (λ) dùng cho điều khiển hành động rời rạc, và Intentional Policy Gradient dùng cho điều khiển liên tục.



Kết quả thí nghiệm: Không cần GPU vẫn ngang bằng SAC
Bài báo đánh giá phương pháp này trên nhiều chuẩn tiêu chuẩn, kết quả gây ấn tượng mạnh.
Trên nhiệm vụ điều khiển liên tục MuJoCo (bao gồm các robot mô phỏng phức tạp như Ant, Humanoid, HalfCheetah), phương pháp mới Intentional AC trong thiết lập luồng (kích thước lô = 1, không có bộ đệm phát lại) có hiệu suất cuối cùng, nhiều lần tiệm cận hoặc thậm chí ngang bằng SAC — một thuật toán sử dụng bộ đệm phát lại lớn và gần như là tiêu chuẩn vàng hiện tại cho nhiệm vụ điều khiển liên tục. Về lượng tính toán, số phép toán dấu phẩy động cần thiết cho mỗi lần cập nhật Intentional AC, chỉ bằng khoảng 1/140 một lần cập nhật SAC.
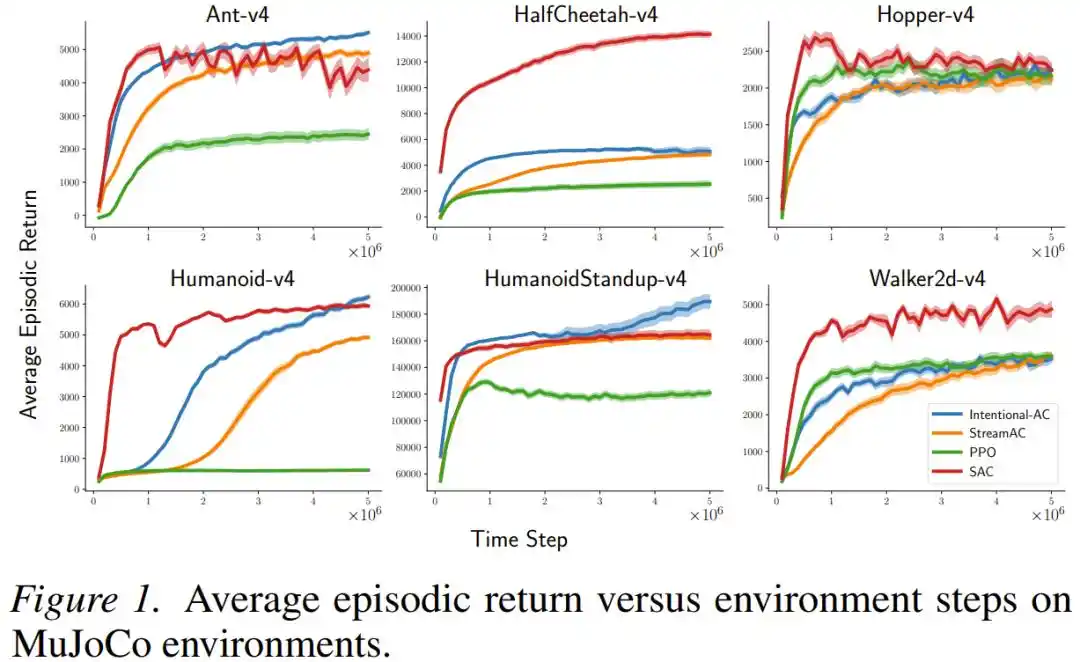
Trên các trò chơi hành động rời rạc Atari và MinAtar, Intentional Q-learning cũng có biểu hiện tương đương với DQN sử dụng bộ đệm phát lại, và chạy thông suốt tất cả nhiệm vụ với cùng một bộ siêu tham số, không cần điều chỉnh tham số cho từng cái.
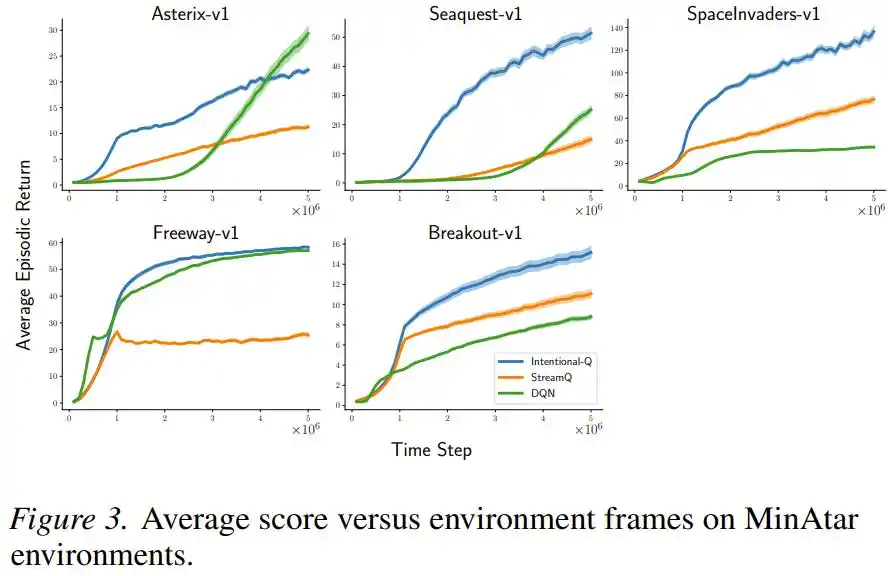
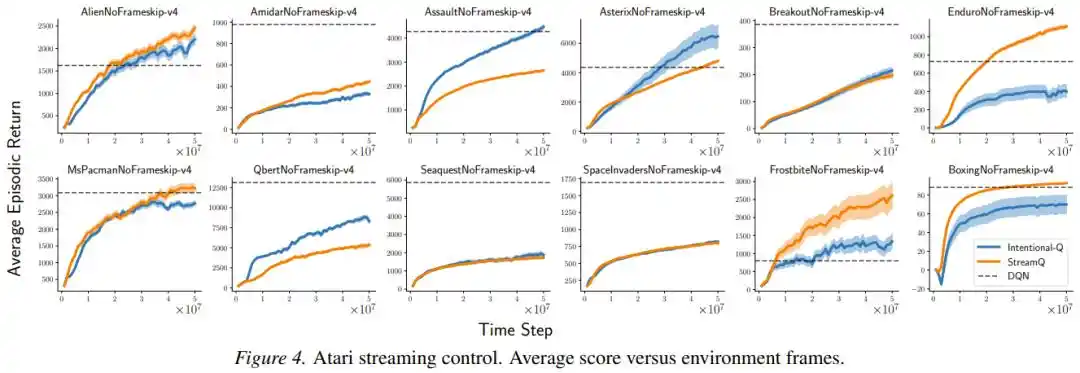
Các nhà nghiên cứu còn chuyên kiểm tra xem "chủ đích" có thực sự được thực hiện không: Họ đo tỷ lệ giữa lượng cập nhật thực tế và lượng cập nhật dự kiến. Trong thiết lập đơn giản vô hiệu hóa vết đủ tư cách, độ lệch chuẩn của tỷ lệ này chỉ từ 0.016 đến 0.029, phân vị 99 đều trong vòng 1.07; có nghĩa là trong hầu hết thời gian, cập nhật thực sự đã làm được "nói làm bao nhiêu thì làm bấy nhiêu".
Ngoài ra, một nhóm thí nghiệm loại bỏ (ablation) cho thấy, sau khi loại bỏ chuẩn hóa RMSProp hoặc thành phần σ, hiệu suất có giảm nhưng vẫn có sức cạnh tranh, và bản thân "tỉ lệ theo chủ đích" này là đóng góp chính, các thành phần khác đều là hỗ trợ.
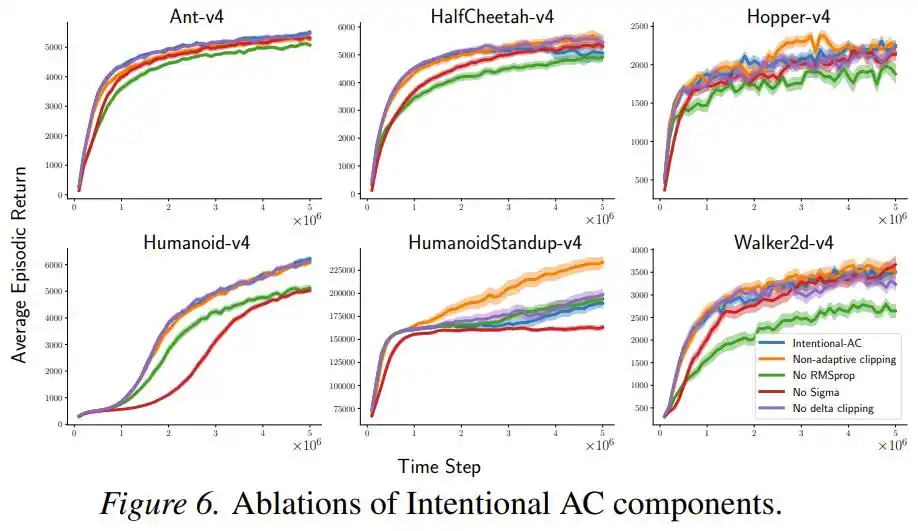
Vẫn còn vấn đề
Khung "Cập nhật có chủ đích" cũng thể hiện ưu thế rõ ràng về tính mạnh mẽ (robustness). Khi các nhà nghiên cứu lần lượt loại bỏ các kỹ thuật hỗ trợ ổn định hóa mà phương pháp StreamX phụ thuộc vào (khởi tạo thưa, tỉ lệ phần thưởng, chuẩn hóa đầu vào, LayerNorm), sự suy giảm hiệu suất của Intentional AC rõ ràng ít hơn so với StreamAC nguyên bản, cho thấy tỉ lệ theo chủ đích đã từ gốc rễ giảm sự phụ thuộc vào các "chiếc nạng" bên ngoài.
Nhưng bài báo cũng thẳng thắn chỉ ra một vấn đề chưa được giải quyết hoàn toàn: Trong học chính sách, bước học phụ thuộc vào hành động được lấy mẫu hiện tại, điều này sẽ khiến các hành động khác nhau được ngầm gán những "trọng số" khác nhau, có thể làm thay đổi hướng kỳ vọng của gradient chính sách. Trong nhiệm vụ Humanoid và HumanoidStandup, bằng cách đo độ tương đồng cosin của hướng cập nhật kỳ vọng, các nhà nghiên cứu thấy sự lệch này ở giai đoạn học then chốt tiệm cận 0.96 (hầu như không ảnh hưởng); nhưng trong Ant-v4, mức độ thẳng hàng giảm xuống trung vị 0.63, cho thấy vấn đề không phải lúc nào cũng có thể bỏ qua.
Tác giả chỉ ra rằng, nghiên cứu tương lai nên tìm kiếm chiến lược chọn bước học không phụ thuộc vào hành động, để "chủ đích" về mặt kỳ vọng cũng giữ được không thiên lệch. Đây là bài tập rõ ràng để lại cho những người tiếp bước theo hướng này.
Kết luận: Để AI học trong khi làm như con người
Mô hình huấn luyện chủ đạo hiện tại của các mô hình lớn, phụ thuộc vào việc tiêu hóa theo lô lượng dữ liệu khổng lồ: Đưa toàn bộ văn bản và mã code từ Internet vào, lặp đi lặp lại, cuối cùng xuất hiện khả năng đáng kinh ngạc. Lộ trình này đã được chứng minh là hiệu quả, nhưng về cơ bản nó là "học trước, dùng sau": Một khi huấn luyện hoàn thành, mô hình sẽ đóng băng, không thể cập nhật liên tục từ mọi lần tương tác thực tế tiếp theo.
Học tăng cường dạng luồng theo đuổi, là một chế độ học hoàn toàn khác: Không phụ thuộc vào phát lại khối lượng lớn, không phụ thuộc vào cụm GPU đồ sộ, mỗi bước trải nghiệm ngay lập tức chuyển hóa thành cập nhật tham số, liên tục, rẻ tiền, tự thích ứng. Điều này gần với cách học thực tế của con người và động vật hơn.
Từ bước đột phá ban đầu "cuối cùng đã chạy thông suốt" của Elsayed và cộng sự năm 2024, đến nguyên tắc "Cập nhật có chủ đích" được đề xuất trong bài báo này, học tăng cường sâu dạng luồng đang trưởng thành với tốc độ bất ngờ. Nó sẽ không thay thế các mô hình lớn được huấn luyện theo lô, nhưng đối với robot cần thích ứng trực tuyến lâu dài, thiết bị biên, và bất kỳ kịch bản ứng dụng nào không thể chịu đựng bộ đệm phát lại quy mô lớn và cụm GPU, con đường này đang ngày càng trở nên thuyết phục.
Bước học không chỉ là một siêu tham số, nó là cam kết "muốn làm bao nhiêu" ở mỗi bước của AI. Khi cam kết này cuối cùng trở nên có thể kiểm soát, bản thân việc học đã ổn định.
Bài viết này từ tài khoản công chúng WeChat "机器之心" (ID:almosthuman2014), tác giả: 关注RL的





