Thập kỷ qua, việc AI trở nên mạnh mẽ hơn chủ yếu dựa vào một con đường: đổ nhiều dữ liệu và sức mạnh tính toán hơn vào các mô hình lớn hơn, để kinh nghiệm lắng đọng trong các tham số mạng nơ-ron. Con đường này đã tạo ra bước nhảy vọt của mô hình lớn sau ChatGPT, và cũng để lại một bài toán khó: mô hình ngày càng mạnh, nhưng lý do tại sao nó thành công, tại sao thất bại, nhiều khi vẫn khó giải thích và sửa chữa.
Thí nghiệm gần đây của kỹ sư OpenAI Weng Jiayi đã đề xuất một khả năng khác: trong môi trường có mục tiêu rõ ràng, có thể chạy và vòng phản hồi khép kín, AI không chỉ có thể trở nên mạnh hơn thông qua việc huấn luyện mô hình, mà còn có thể trở nên mạnh hơn thông qua việc 'tự sửa code'.
Ngày 8 tháng 5 năm 2026, Weng Jiayi đã hệ thống viết ra nhóm thí nghiệm này trên blog cá nhân 'Learning Beyond Gradients', đồng thời công khai kho lưu trữ code, nhật ký thí nghiệm CSV và bản ghi lại video. Anh ấy lâu nay tập trung vào cơ sở hạ tầng học tăng cường và hậu huấn luyện, tham gia vào lần ra mắt ban đầu của ChatGPT, và đảm nhiệm các công việc liên quan trong các dự án GPT-4, GPT-4 Turbo, GPT-4o, o-series, GPT-5; trước khi gia nhập OpenAI, anh tốt nghiệp đại học khoa Máy tính Đại học Thanh Hoa, thạc sĩ học tại Đại học Carnegie Mellon, cũng là tác giả chính của thư viện học tăng cường mã nguồn mở Tianshou và công cụ môi trường song song hiệu suất cao EnvPool.

Hình ảnh được tạo bởi AI
Anh ấy để Codex liên tục viết code chiến lược, chạy môi trường, đọc nhật ký, xem bản ghi lại, xác định vị trí thất bại, sau đó sửa code, bổ sung kiểm thử, tiếp tục đánh giá. Sau nhiều vòng lặp lại, Codex 'nuôi dưỡng' ra một bộ chiến lược thủ tục thuần Python: đạt điểm lý thuyết tối đa 864 trong Atari Breakout, trong các môi trường mô phỏng điều khiển robot như MuJoCo Ant và HalfCheetah, cũng chạy ra điểm số gần bằng với các thuật toán học tăng cường sâu thông thường.
Điểm thực sự quan trọng của nhóm thí nghiệm này, là một vấn đề cốt lõi: Khi coding agent đủ mạnh, việc học có nhất thiết phải xảy ra trong trọng số mạng nơ-ron không?
Trong bộ thí nghiệm này, kinh nghiệm được viết vào code, kiểm thử, nhật ký và bản ghi lại, trở thành một hệ thống phần mềm có thể đọc, sửa, xem xét và kiểm toán. Nếu hướng đi này tiếp tục thành lập, bước tiếp theo của Agentic AI có thể không chỉ là huấn luyện mô hình lớn hơn, mà còn là để mô hình tham gia duy trì một hệ thống kỹ thuật liên tục tiến hóa.
01
Vòng khép kín kỹ thuật từ 387 điểm đến điểm tối đa
Weng Jiayi viết trong blog, điểm xuất phát của thí nghiệm này thực ra là một nhu cầu kỹ thuật. Trong thời gian rảnh anh duy trì EnvPool, cần một cách rẻ hơn 'mỗi lần chạy một mạng nơ-ron' để kiểm tra môi trường trò chơi có chạy bình thường không, vì đưa mạng nơ-ron vào CI quá đắt. Vấn đề ban đầu là: Có thể viết ra các quy tắc heuristic rẻ, có thể tái hiện, rõ ràng mạnh hơn chiến lược ngẫu nhiên, để đưa môi trường đến trạng thái giàu thông tin không?

Anh ấy dùng Codex (mô hình cơ bản là gpt-5.4) thử viết một phiên bản hoàn toàn dựa trên quy tắc. Lời nhắc đầu tiên rất trực tiếp: 'Viết một chiến lược có thể giải quyết Breakout.' Kết quả không lý tưởng. Điểm thấp bản thân không cung cấp bất kỳ thông tin nào, ví dụ ngữ nghĩa hành động có thể sai, phát hiện trạng thái có thể sai, quy trình đánh giá có thể sai, cấu trúc chiến lược bản thân cũng có thể quá yếu.
Sau đó Weng Jiayi thay đổi hình thức nhiệm vụ. Anh không yêu cầu Codex trực tiếp giao ra một policy.py, mà yêu cầu nó duy trì toàn bộ một vòng lặp: dò tìm hành động và quan sát, viết bộ phát hiện trạng thái, viết chiến lược, chạy toàn bộ episode, ghi lại trials.jsonl và summary.csv, tạo video hoặc đường cong, kiểm tra mẫu thất bại, sửa chiến lược, đơn giản hóa code, chạy hồi quy.
Bản ghi thí nghiệm Breakout ghi lại quá trình này rất rõ ràng. Vòng đầu Codex xác nhận không gian hành động và hình dạng quan sát, từ khung hình RGB nhận diện màu sắc của bóng, ván chắn và viên gạch, sau đó dùng nhãn hình ảnh quét RAM 128 byte của Atari. Baseline ban đầu chỉ có 99 điểm. Sau khi thêm logic lệch đường hầm, điểm số tăng lên 387.
387 điểm là một điểm cao cục bộ dễ khiến người ta đánh giá sai. Chiến lược đã có thể ổn định đỡ bóng, nhưng đường bóng bị mắc kẹt vào vòng lặp tuần hoàn: không mất mạng, cũng không đánh trúng viên gạch mới, điểm số bị kẹt. Nếu là người viết code, có thể sẽ tiếp tục điều chỉnh 'độ chính xác đỡ bóng'. Codex xem video và vài chục bước gần đây, định vị vấn đề ở đường bóng thiếu nhiễu loạn.
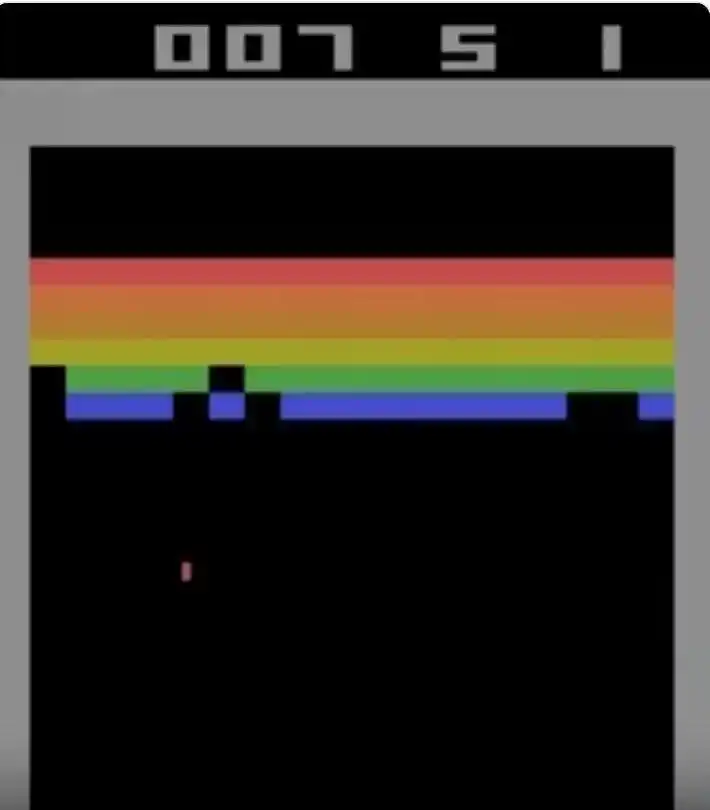
Hình: Cảnh trò chơi Atari Breakout. Người chơi điều khiển ván chắn ở dưới để đánh trả lại quả bóng nhỏ, đập vỡ từng tầng tường gạch màu ở phía trên. Codex đã đạt điểm lý thuyết tối đa 864 trong trò chơi này.
Sau đó Codex thêm một cơ chế 'phá vỡ vòng lặp': nếu lâu không có phần thưởng, thì định kỳ thêm một lượng lệch cho dự đoán điểm rơi, đưa bóng ra khỏi vòng lặp cục bộ. Điểm số nhảy từ 387 lên 507. Khi tiếp tục lặp lại lại xuất hiện vấn đề mới: đối với bóng thấp nhanh, đánh chặn thông thường sẽ khiến ván chắn 'vượt dẫn quá mức' mà trôi đi. Codex thêm tham số fast_low_ball_lead_steps=3, điểm số từ 507 nhảy lên 839. Cuối cùng sự cải thiện từ 839 lên 864 giống như đang duy trì một hệ thống đã trở nên phức tạp: thử deadband, lệch phát bóng, lệch kẹt, thiên vị cân bằng viên gạch, số bước nhìn trước; nhiều hướng không có hiệu quả, sửa đổi hữu ích cuối cùng là điều kiện giai đoạn sau, 'sau khi đập xong bức tường gạch đầu tiên, chỉ kích hoạt lệch kẹt khi bóng cách xa ván chắn, khi bóng gần thì từ từ giải phóng'.
Cấu hình RAM mặc định cuối cùng cho ra đầu ra ổn định 864 / 864 / 864 điểm trên ba vòng episode, đạt đến giới hạn lý thuyết của Breakout. Codex sau đó lại di chuyển cùng một bộ điều khiển hình học đó sang phiên bản đầu vào thuần hình ảnh — không đọc RAM, chỉ dựa vào phân đoạn RGB để nhận diện ván chắn, bóng và cân bằng viên gạch. Phiên bản hình ảnh lần chạy đầu tiên ra 310 điểm, chạy tiếp ra 428 điểm, sau lần episode thứ bảy đạt 864 điểm, tương ứng 14504 bước môi trường chiến lược cục bộ.
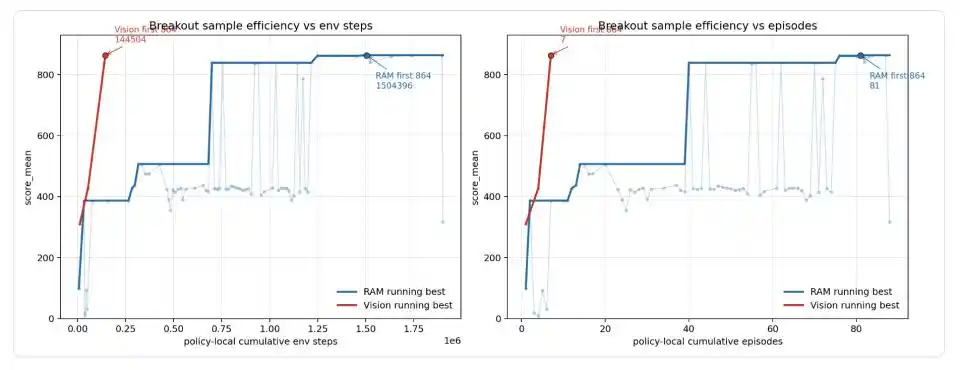
Hình: Đường cong hiệu suất mẫu của Codex trên Breakout. Đường xanh là phiên bản đọc trực tiếp bộ nhớ trò chơi (RAM), đường đỏ là phiên bản chỉ xem màn hình (Vision). Phiên bản RAM trải qua nhiều bước nhảy 99 → 387 → 507 → 839 → 864, cuối cùng lần đầu đạt điểm tối đa ở episode thứ 81, tích lũy 1.5 triệu bước môi trường; Phiên bản Vision do là cấu trúc trưởng thành được di chuyển từ phiên bản RAM, chỉ dùng 7 episode, khoảng 1.45 vạn bước môi trường đã đạt 864 điểm.
Weng Jiayi đặc biệt nhắc nhở, điều này không nên được hiểu là 'đầu vào hình ảnh từ con số không chỉ dùng 14.5K bước đạt điểm tối đa'. Quy trình thực tế là Codex trước tiên trong phiên bản RAM phát hiện bộ điều khiển hình học, phá vỡ vòng lặp và giải phóng lệch giai đoạn sau, cấu trúc ổn định sau đó mới chuyển lớp đọc trạng thái từ RAM sang RGB. 14.5K là ngân sách di chuyển của phiên bản hình ảnh.
02
Định nghĩa của Heuristic Learning
Đặt tên cho 'chiến lược phần mềm' không ngừng tiến hóa này, khó hơn viết phiên bản chiến lược đầu tiên. Weng Jiayi cuối cùng đặt tên quá trình này là Heuristic Learning (HL, Học heuristic), và đối tượng được duy trì ra đặt tên là Heuristic System (HS, Hệ thống heuristic).
Theo định nghĩa của anh trong blog, HL được cấu thành từ code chương trình, giống như học tăng cường sâu phổ biến hiện nay, nó có một vòng lặp trạng thái, hành động, phản hồi, cập nhật. Khác biệt là, đối tượng được cập nhật là cấu trúc phần mềm, không phải tham số mạng nơ-ron; phản hồi của nó được coding agent tiêu hóa, có thể đến từ phần thưởng môi trường, trường hợp kiểm thử, nhật ký, video, bản ghi lại hoặc phản hồi con người; cập nhật của nó không sử dụng lan truyền ngược, mà là coding agent trực tiếp chỉnh sửa chiến lược, bộ phát hiện trạng thái, kiểm thử, cấu hình hoặc bộ nhớ.
Cần bổ sung, 'dùng chương trình thay vì mạng nơ-ron làm chiến lược' không phải khái niệm do Weng Jiayi sáng tạo ra đầu tiên. Giới học thuật đã thảo luận nhiều năm về học tăng cường theo chương trình (Programmatic RL): khuôn khổ PROPEL do Đại học Rice và Caltech đề xuất năm 2019, nghiên cứu phương pháp học tăng cường biểu diễn chiến lược như các chương trình ngắn trong ngôn ngữ ký hiệu; công trình LEAPS năm 2021 tiến thêm học không gian nhúng chương trình, kết hợp chiến lược chương trình khả vi với huấn luyện RL; HPRL tại ICML 2023 đề xuất học tăng cường theo chương trình phân tầng, để meta-policy kết hợp nhiều chương trình; khuôn khổ LLM-GS năm 2024 từ Đại học Quốc gia Đài Loan và Microsoft dùng khả năng lập trình và lập luận thường thức của LLM để hướng dẫn tìm kiếm chiến lược RL theo chương trình.
Đồng thuận của các nghiên cứu này là: so với chiến lược thần kinh, chiến lược theo chương trình có khả năng giải thích tốt hơn, khả năng xác minh hình thức hóa tốt hơn, và khả năng tổng quát hóa cho các cảnh chưa thấy.
Đóng góp thực chất lần này của Weng Jiayi, nằm ở việc coi coding agent là kênh kỹ thuật để duy trì hệ thống heuristic. Trước đây làm RL theo chương trình, hoặc dựa vào ngôn ngữ chuyên dụng lĩnh vực thiết kế thủ công, hoặc dựa vào thuật toán tìm kiếm trong không gian chương trình bị hạn chế; Weng Jiayi thì dựa vào Codex đưa code, nhật ký, kiểm thử, bản ghi lại video, điều chỉnh tham số đều vào cùng một quy trình công việc của agent, khiến chi phí lặp lại chiến lược chương trình bị hạ thấp một lần. Nói cách khác, anh đang lập luận một con đường kỹ thuật mới: khi coding agent đủ mạnh, những chiến lược heuristic trước đây bị chê 'chi phí duy trì quá cao' có thể trở nên hợp lý trở lại.
Weng Jiayi đưa ra một bảng so sánh trong blog, nói rõ sự khác biệt giữa HL và Deep RL: về hình thức chiến lược, cái trước là code gồm quy tắc, máy trạng thái, bộ điều khiển, điều khiển dự đoán mô hình (MPC), hành động vĩ mô, cái sau là tham số mạng nơ-ron; về hình thức trạng thái, cái trước là biến hiển thị, bộ phát hiện và bộ nhớ đệm, cái sau là vector quan sát mạng có thể đọc; về hình thức phản hồi, cái trước coi kiểm thử, nhật ký, bản ghi lại đều là tín hiệu hiệu quả, cái sau chủ yếu dựa vào hàm phần thưởng cố định; về hình thức bộ nhớ, cái trước có thể lưu trữ hiển thị thử nghiệm, tóm tắt, nguyên nhân thất bại và diff phiên bản, cái sau trong thuật toán on-policy cơ bản không có, trong thuật toán off-policy dựa vào replay buffer.
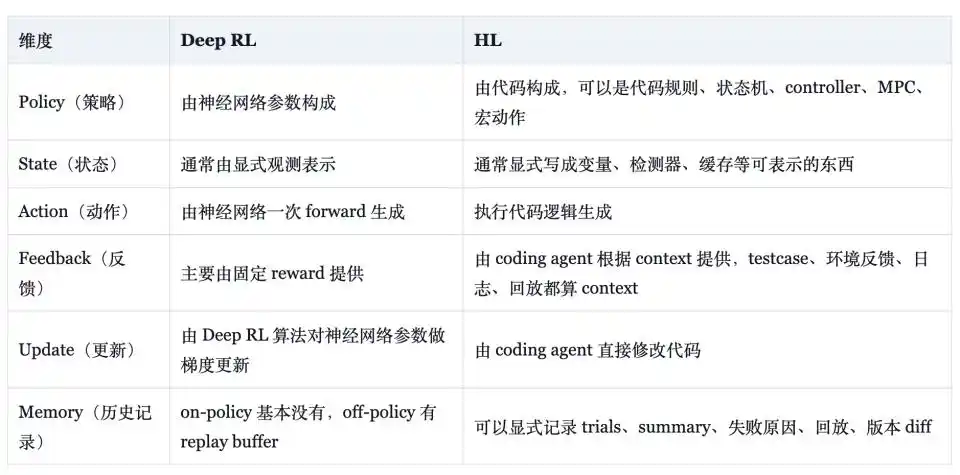
Bộ so sánh này chứng minh HL có một số thuộc tính về mặt kỹ thuật: chiến lược có thể giải thích, có thể dịch thành ngôn ngữ tự nhiên; hiệu suất mẫu tính bằng đơn vị 'một lần sửa code hiệu quả', không phải cập nhật gradient chậm; khả năng cũ có thể trở thành kiểm thử hồi quy, bản ghi lại hạt giống cố định hoặc trường hợp vàng; sự quá khớp với hạt giống huấn luyện hoặc lỗ hổng kiểm thử, có thể được ràng buộc thông qua đơn giản hóa, kiểm tra hồi quy và đánh giá đa hạt giống; khả năng cũ không nhất thiết chỉ tồn tại trong trọng số, cũng có thể tồn tại trong tập quy tắc và kiểm thử, phần này hồi đáp vấn đề quên thảm khốc mà mạng nơ-ron lâu nay chưa giải quyết tốt.
03
Xác minh hàng loạt trên Atari57: Ranh giới và điểm yếu
Nếu chỉ nhìn Breakout, câu chuyện dễ bị đơn giản hóa thành 'AI viết ra một chiến lược hoàn hảo'. Nhưng Weng Jiayi không dừng ở Breakout, anh lại mở rộng hàng loạt quy trình công việc Codex này đến Atari57, chạy 57 trò chơi, hai chế độ quan sát, ba lần lặp lại, tổng cộng 342 đường tìm kiếm 'không người trông coi'.
Thiết kế thí nghiệm khá khắt khe. Mỗi trò chơi lần lượt được kiểm thử bằng hai cách nhập liệu: một là đọc trực tiếp bộ nhớ trò chơi, một là chỉ xem màn hình, mỗi cách lặp lại độc lập ba lần. Như vậy tổng cộng tạo ra 342 đường thí nghiệm 'không người trông coi': mỗi Codex agent nhận cùng một mẫu nhắc, tự mình mò mẫm hành động, tự viết code, tự chạy thí nghiệm, tự ghi lại kết quả, không có ai ở bên cạnh đưa gợi ý. Điều kiện ràng buộc được viết rất chặt, không cho phép huấn luyện mạng nơ-ron, không cho phép đọc mã nguồn trò chơi, không được sử dụng bất kỳ thông tin ẩn nào, tất cả số bước dùng để gỡ lỗi và thử sai đều phải tính vào tổng chi phí. Đây là để tránh Codex dùng bất kỳ cách nào 'nhìn lén đáp án' để gian lận.
Khi đo lường kết quả thường sử dụng một chỉ số gọi là HNS (Human-Normalized Score, Đi số chuẩn hóa theo con người) — đơn giản nói là chuẩn hóa điểm số mỗi trò chơi theo 'mức trung bình của người chơi = 1', thuận tiện so sánh ngang giữa các trò chơi khác nhau.
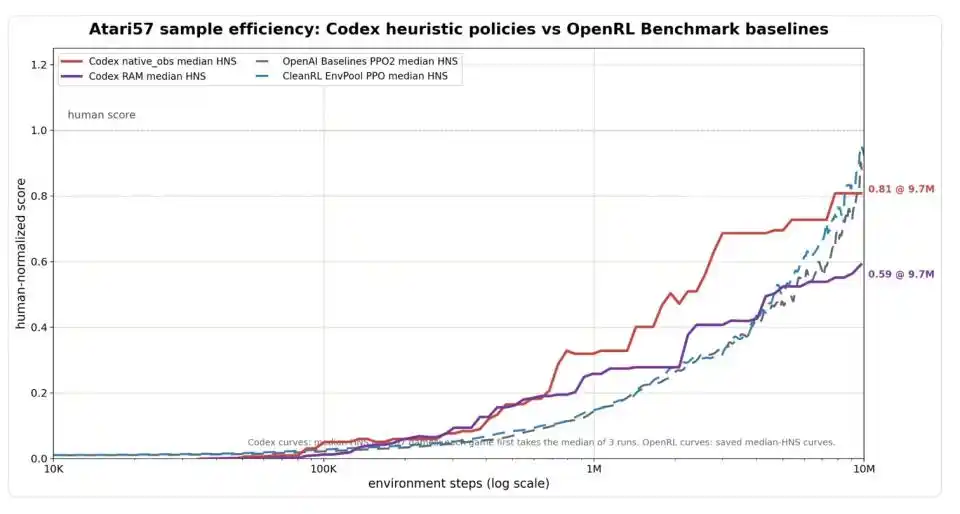
Hình: So sánh hiệu suất mẫu trên toàn bộ Atari57. Trục ngang là số bước môi trường (thang logarit), trục dọc là HNS (Đi số chuẩn hóa theo con người, 1.0 biểu thị đạt mức trung bình người chơi). Phiên bản nhập liệu màn hình của Codex (đường đỏ) hiệu quả rõ ràng dẫn đầu so với đường cơ sở PPO (đường chấm xanh/xám) ở giai đoạn đầu, đến 9.7 triệu bước đạt 0.81, gần với mức của PPO ở khoảng 10 triệu bước; Phiên bản nhập liệu bộ nhớ của Codex (đường tím) thì hội tụ ở 0.59.
Theo tiêu chuẩn này, hiệu quả của Codex ở giai đoạn đầu khá sáng. Chỉ tiêu thụ 1 triệu bước môi trường, trung vị HNS của Codex dùng đầu vào hình ảnh đã đạt 0.32, dùng đầu vào bộ nhớ đạt 0.26, rõ ràng cao hơn mức của các thuật toán học tăng cường kinh điển như PPO cùng kỳ. Đến 9.7 triệu bước, phiên bản hình ảnh của Codex đạt 0.81, đã gần với mức khoảng 0.88 đến 0.92 của PPO ở 10 triệu bước. Nếu cho phép chọn cách nhập liệu mà Codex thể hiện tốt hơn cho mỗi trò chơi để tổng hợp, trung vị HNS của Codex là 0.83, OpenAI Baselines PPO2 là 0.80, CleanRL EnvPool PPO là 0.98 — cơ bản hòa ngang.
Nhưng chính Weng Jiayi rất tỉnh táo vạch một ranh giới: đây chỉ là so sánh hiệu quả tương tác môi trường, không tính chi phí đọc nhật ký, viết code, xem video của Codex vào. 'Chạy nhanh' không bằng 'tổng chi phí thấp', cái sau hiện tại vẫn là một hộp đen.
Đáng quan tâm hơn là, biểu hiện của Codex trên 57 trò chơi không đồng đều. Trong các trò chơi có cấu trúc hình học rõ ràng như Breakout, Boxing, Krull, chiến lược heuristic và học tăng cường sâu đều có thể vượt rõ ràng mức con người; trong các trò chơi có quy tắc rõ ràng như Asterix, Jamesbond, Tennis, chiến lược heuristic thậm chí mạnh hơn; nhưng trong các trò chơi nhịp độ nhanh, mẫu phức tạp như Atlantis, VideoPinball, RoadRunner, StarGunner, PPO vẫn áp đảo.
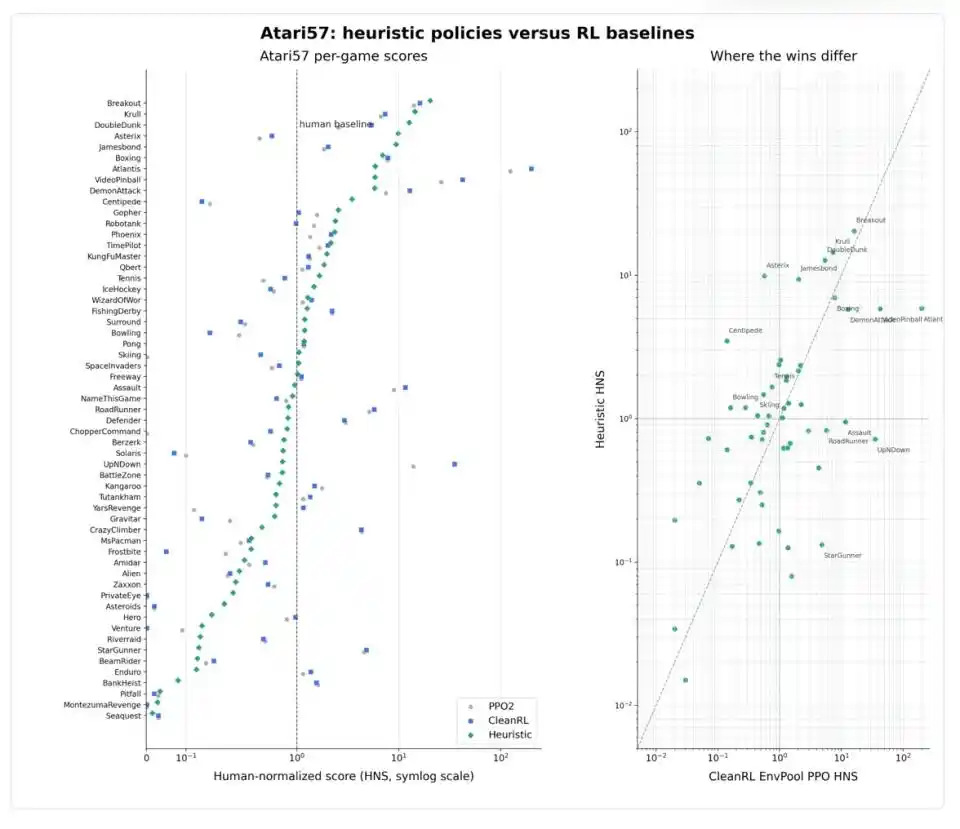
Phản ví dụ mang tính cảnh báo nhất là Montezuma’s Revenge. Đây là 'xương sống' nổi tiếng trong lĩnh vực học tăng cường, nhân vật chính cần tìm chìa khóa, tránh kẻ địch, mở cửa trong mê cung phức tạp, tín hiệu phần thưởng cực kỳ thưa thớt, là vấn đề 'lập kế hoạch dài hạn + khôi phục sau thất bại' kinh điển. Codex trên trò chơi này thực sự đạt 400 điểm, nhưng mở file chiến lược nó tạo ra sẽ thấy, đó không phải là một 'chiến lược' thực sự, mà là một chuỗi 86 chuỗi hành động được mã hóa cứng, tương ứng 1769 bước môi trường: giống như học thuộc một tuyến đường cố định, hơn là học được đi mê cung. Weng Jiayi đặc biệt đề cập: 'Đây là một trường hợp ranh giới, không nên được hiểu là chiến lược Montezuma tổng quát.'
Montezuma phơi bày giới hạn biểu đạt của Heuristic Learning. Chiến lược chương trình thông thường bản chất là logic phản ứng 'thấy trạng thái gì thì làm hành động đó', khó xử lý các nhiệm vụ cần thứ tự hành động nghiêm ngặt, cần tiếp tục kế hoạch từ trạng thái trung gian, cần lập kế hoạch tầm nhìn dài. Loại nhiệm vụ này cần không chỉ nhiều if-else hơn, mà là cấu trúc chương trình gần hơn với 'tổ hợp hành động vĩ mô + trạng thái tìm kiếm có thể khôi phục + bộ nhớ dài hạn'. Nó nói với chúng ta một điều: cho dù coding agent có mạnh thế nào, một số vấn đề không phải code thông thường có thể chứa được.
04
Một khi mẫu hình thành lập, ý nghĩa công nghiệp ở đâu?
Kéo góc nhìn trở lại công nghiệp. Nếu con đường Heuristic Learning này thực sự thành lập, 'tức coding agent có thể ổn định duy trì ra chiến lược theo chương trình vượt quy tắc thủ công, gần với đường cơ sở RL', ý nghĩa thực tế của nó ở đâu?
Điểm rơi đầu tiên là điều khiển robot, đặc biệt là các cảnh có cấu trúc tương đối ổn định. Viễn cảnh Weng Jiayi đưa ra trong blog là phân công theo tầng HL cấp khớp, HL cấp chi, HL cân bằng toàn thân, HL cấp nhiệm vụ. Tầng thấp xử lý an toàn và điều khiển độ trễ thấp, tầng giữa xử lý dáng đi và tiếp xúc, tầng cao xử lý nhiệm vụ và bộ nhớ dài hạn; coding agent không cần 'hiểu đi bộ', nó giống như một kênh cập nhật cắm vào hệ thống, đưa video thất bại, luồng cảm biến, kết quả mô phỏng trở lại hệ thống, sau đó viết lại phản hồi thành code, tham số, quy tắc bảo vệ và bộ nhớ.
Các cảnh như AGV kho, robot tuần tra, cánh tay robot nhà máy, phân loại tiêu chuẩn hóa, cấu trúc môi trường tương đối cố định, ranh giới an toàn rõ ràng — nếu chiến lược điều khiển cốt lõi có thể cố định hóa thành code nhẹ, mỗi bước hành động của robot không cần chạy một mạng chiến lược lớn, phụ thuộc của phía triển khai vào thẻ suy luận GPU công suất cao sẽ giảm, nhiều tải hơn giao cho bộ điều khiển truyền thống và logic chương trình cục bộ.
Điều này không có nghĩa robot không cần GPU, nhận thức, định vị, lập bản đồ, hiểu ngữ nghĩa vẫn phải dựa vào mạng nơ-ron; thay đổi là vai trò của GPU, từ 'mỗi giây đốt sức mạnh tính toán cho quyết định hành động đầu cuối' thành 'phát huy tác dụng định kỳ trong nhận thức, mô phỏng ngoại tuyến, sinh chiến lược, phân tích ngoại lệ'.
Điểm rơi thứ hai là khả năng kiểm toán của các cảnh an toàn trọng yếu. Vấn đề kỹ thuật hóc búa nhất của chiến lược thần kinh là khi xảy ra sự cố không thể định vị. Một cánh tay robot đột nhiên thất bại ở một góc độ nào đó, một chiếc xe đánh giá sai trong một cảnh biên nào đó, một robot y tế hành động bất thường dưới một tư thế hiếm gặp, kỹ sư không có cách nào trả lời 'trọng số nào dẫn đến lỗi này', cuối cùng chỉ có thể bổ sung dữ liệu, huấn luyện lại, kiểm thử hồi quy, sau đó cá cược mô hình mới không đưa vào vấn đề mới.
Nếu chiến lược tồn tại dưới dạng code, biến trạng thái, nhánh điều kiện, nhật ký thất bại và kiểm thử hồi quy đều là có thể thấy; một hành động nguy hiểm nào đó có thể bị cấm mã hóa cứng, một corner case có thể viết thành kiểm thử, một chuyển trạng thái lỗi có thể được sửa riêng biệt. Điều này không làm hệ thống tự nhiên an toàn hơn, nhưng làm vấn đề an toàn lần đầu tiên có thể vào quy trình kỹ thuật phần mềm bình thường — có thể được đánh giá code, có thể bị CI chặn, có thể được SRE trực ứng phó. Trong các lĩnh vực cần giám sát và phân chia trách nhiệm như lái xe tự động, cánh tay robot công nghiệp, robot y tế, khả năng kiểm toán này bản thân đã là giá trị thương mại.
Điểm rơi thứ ba là kỹ thuật hóa học liên tục và học trực tuyến. Weng Jiayi trong blog coi điều này làm luận chủ xuyên suốt toàn bài. Quên thảm khốc của mạng nơ-ron là vấn đề cấu trúc: học cái mới, khả năng cũ bị trôi đi. HL cũng sẽ quên, nhưng hình thức mang tính kỹ thuật hơn: một quy tắc mới sửa một mẫu thất bại nhưng phá vỡ cảnh cũ; một bộ nhớ mới liên tục dẫn agent đến hướng sai; một phạm vi kiểm thử quá hẹp, chiến lược học cách lợi dụng nó; một bản vá sửa giao diện chung, đường gọi cũ lặng lẽ mất hiệu lực.
Những vấn đề này không tự động biến mất, nhưng chúng đều là vấn đề mà kỹ thuật phần mềm đã xử lý mấy chục năm, có chuỗi công cụ sẵn — kiểm thử hồi quy, diff phiên bản, bản ghi lại hạt giống cố định, golden trace, hướng thất bại được ghi lại hiển thị.
Một HS lành mạnh phải đồng thời có hai thao tác: hấp thụ phản hồi mới, nén lịch sử bản vá; HS chỉ tăng không giảm cuối cùng sẽ trở thành một 'cục bùn code' không ai dám động. Nói cách khác, HL chuyển vấn đề toán học 'làm thế nào cập nhật tham số', thành vấn đề kỹ thuật 'làm thế nào duy trì một hệ thống phần mềm không ngừng hấp thụ phản hồi'.
Cái sau chưa chắc dễ hơn, nhưng gần hơn với ranh giới năng lực sẵn có của con người.
Điểm rơi thứ tư là lắng đọng năng lực của sản phẩm Agent. Điều sản phẩm Agent hiện tại thiếu nhất là gọi công cụ ổn định, liên kết thực thi đáng tin cậy, kinh nghiệm thất bại có thể tái sử dụng và bản ghi nhiệm vụ có thể kiểm toán. Nếu logic của HL thành lập, bộ nhớ của Agent trong quá trình thực thi sẽ lắng đọng thành tài sản code có thể tái sử dụng xuyên phiên, xuyên người dùng, xuyên nhiệm vụ. Nó có thể kết nối trực tiếp với quy trình DevOps sẵn có, cũng có nghĩa Agent của các công ty, nhóm khác nhau có thể chia sẻ heuristic, nhưng không cần chia sẻ mô hình, đây là điều phương án mạng nơ-ron không làm được.
Tuy nhiên, cần nhấn mạnh là: Bốn điểm rơi trên đều phụ thuộc vào việc con đường HL được xác minh thêm trên các nhiệm vụ phức tạp hơn. Breakout và Ant là môi trường tương đối sạch, robot thực đối mặt với thay đổi ma sát mặt đất, thay đổi ánh sáng, độ trễ cơ cấu chấp hành, nhiễu cảm biến, những điều này chưa được đánh giá hệ thống trong tài liệu công khai. Phản ví dụ Montezuma đã chỉ ra, nhiệm vụ tầm nhìn dài cần hình thức chương trình vượt quá if-else thông thường. Viễn cảnh này cuối cùng có thể đi xa đến đâu, còn phải xem thí nghiệm giai đoạn tiếp theo.
05
Nợ kỹ thuật chuyển từ trọng số sang code
Phán đoán Weng Jiayi đưa ra trong blog rất kìm chế. Anh viết, HL không thể hoàn thành tất cả việc mạng nơ-ron có thể làm, nó bị giới hạn bởi nội dung code có thể biểu đạt, đặc biệt trong nhận thức phức tạp và tổng quát hóa tầm nhìn dài. Với nhận thức hiện nay, anh không thể tưởng tượng một agent dùng code Python thuần, không dựa vào bất kỳ mạng nơ-ron nào để giải quyết ImageNet. Vấn đề đáng thảo luận thực sự, là làm thế nào kết hợp mạng nơ-ron và HL cùng xử lý Online Learning và Continual Learning.
Sự phân công anh đưa ra mượn ngôn ngữ System 1 / System 2: mạng nơ-ron nông chuyên biệt đảm nhiệm một phần của System 1, phụ trách nhận thức nhanh, phân loại và ước tính trạng thái vật thể; HL cũng đảm nhiệm một phần của System 1, phụ trách xử lý dữ liệu tươi mới, quy tắc, kiểm thử, bản ghi lại, bộ nhớ, ranh giới an toàn và khôi phục cục bộ; LLM agent đảm nhiệm System 2, cung cấp phản hồi cho HL, cải thiện dữ liệu, và định kỳ trích xuất thông tin từ dữ liệu HL sinh ra để cập nhật bản thân.
Nếu như học sâu mười năm qua chứng minh 'kinh nghiệm có thể được nén vào trọng số', thì giả thuyết Weng Jiayi lần này đề xuất là một đề mệnh lệnh khác: trong thời đại coding agent, kinh nghiệm có lẽ có thể trở lại thành phần mềm có thể đọc, sửa, kiểm thử.
Bài viết này đến từ tài khoản WeChat công chúng 'Tencent Technology', tác giả: Xiaojing, biên tập: Xu Qingyang






