Như chúng ta đều biết, chi phí huấn luyện mô hình lớn (LLM) là cực kỳ cao.
Nhưng mọi người cũng biết rằng, việc giảm độ chính xác (precision) có thể giảm đáng kể chi phí huấn luyện. DeepSeek-V3 sử dụng FP8 để huấn luyện, đã giảm chi phí xuống còn 5,6 triệu USD, khiến cả ngành phải kinh ngạc.
Sau thành công của FP8, ngành công nghiệp vẫn không ngừng thăm dò giới hạn của độ chính xác thấp: từ FP8 xuống FP4, chi phí huấn luyện có thể giảm thêm bao nhiêu?
Về mặt lý thuyết, thông lượng tính toán FP4 có thể gấp đôi FP8. NVIDIA Blackwell và AMD MI350 series đã hỗ trợ nguyên sinh (native) các phép toán FP4 ở cấp độ phần cứng, trong đó B200 của NVIDIA công bố hiệu năng FP4 có thể đạt 4500 TOPS (thưa thớt/sparse). Phần cứng đã sẵn sàng, nhưng phía phần mềm và thuật toán luôn bị kẹt ở một vấn đề:
Huấn luyện mô hình lớn từ đầu (pretrain) bằng FP4, quá trình huấn luyện rất không ổn định.
Trong hai năm qua, các công trình như LLM-FP4, NVFP4 pretraining lần lượt thử nghiệm con đường này, nhưng hiếm có giải pháp nào có thể chạy thông suốt toàn bộ quy trình tiền huấn luyện (pretraining) ở độ chính xác 4-bit một cách sạch sẽ, đồng thời duy trì chất lượng hội tụ gần với FP8.
Khó khăn hơn là nguyên nhân sụp đổ vẫn chưa rõ ràng. Phân tích trước đây cho rằng, nguyên nhân gây mất ổn định khi huấn luyện với FP4 rất có thể đến từ tính ngẫu nhiên không đủ.
Nhưng gần đây, AMD hợp tác với Đại học Bang Pennsylvania đã công bố một bài báo khoa học, lật ngược nhận thức truyền thống, đưa ra một chẩn đoán mới mẻ và rõ ràng cho việc huấn luyện nguyên sinh FP4.

- Tiêu đề bài báo: Pretraining large language models with MXFP4 on Native FP4 Hardware
- Liên kết bài báo: https://arxiv.org/abs/2605.09825
Bài báo này đã hoàn thành quy trình tiền huấn luyện (pretraining) đầy đủ cho Llama 3.1-8B sử dụng định dạng MXFP4 trên GPU AMD Instinct MI355X, tốc độ huấn luyện đầu cuối (end-to-end) nhanh hơn 9-10% so với đường cơ sở FP8, token hao phí chỉ nhiều hơn 8-9%. Đây là thí nghiệm hoàn chỉnh đầu tiên hiện nay hoàn thành tiền huấn luyện mô hình lớn trên phần cứng FP4 nguyên sinh (không phải mô phỏng phần mềm).
Quan trọng hơn, bài báo tiết lộ vấn đề cốt lõi: Nguồn gốc của sự bất ổn định khi huấn luyện FP4 không phải là do tính ngẫu nhiên không đủ, mà là do lỗi vi chia tỷ lệ (micro-scaling) cấu trúc tích lũy và khuếch đại dọc theo các đường dẫn gradient nhạy cảm.
MXFP4 là gì
Trước khi phân tích bài báo, cần hiểu định dạng dữ liệu MXFP4 này.
Lượng tử hóa nguyên (integer) truyền thống thường sử dụng một hệ số tỷ lệ (scaling factor) duy nhất cho toàn bộ tensor. Thiết kế cốt lõi của MXFP4 được gọi là "Vi chia tỷ lệ" (Micro-scaling): chia một tensor thành các khối nhỏ (ví dụ: mỗi nhóm 32 phần tử), cấp phát một số mũ chung (format E8M0) cho mỗi khối nhỏ, mỗi phần tử trong khối được biểu diễn bằng số dấu phẩy động 4-bit. Công thức tái tạo có thể được viết là:
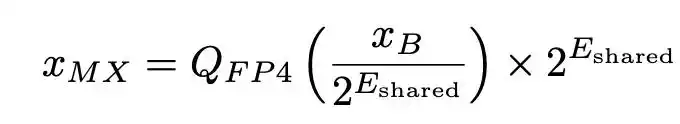
Trong đó, E_shared là số mũ lớn nhất trong khối, Q_FP4 là giá trị được làm tròn gần nhất đến giá trị có thể biểu diễn được bằng số dấu phẩy động 4-bit.
Lợi ích của vi chia tỷ lệ nằm ở: mỗi khối nhỏ có phạm vi động (dynamic range) riêng, không bị "bắt cóc" bởi các giá trị ngoại lai toàn cục (global outliers). Điều này làm cho chất lượng biểu diễn của số dấu phẩy động 4-bit tốt hơn nhiều so với lượng tử hóa toàn cục đơn giản.
Nhưng ngay cả khi có vi chia tỷ lệ, việc huấn luyện FP4 vẫn không ổn định.
Thí nghiệm điều tra: Nguồn gốc của sự bất ổn định
Nhóm nghiên cứu trước tiên đã thiết kế một thí nghiệm kiểm soát từng bước.
Một phép tính lớp tuyến tính (linear layer) Transformer hoàn chỉnh liên quan đến ba thao tác nhân ma trận tổng quát (GEMM):
Fprop (Lan truyền xuôi/Forward propagation): Tính Y = XW^T, tạo ra giá trị kích hoạt (activations)
Dgrad (Gradient của kích hoạt): Tính ∇X = ∇Y · W, truyền gradient ngược về đầu vào
Wgrad (Gradient của trọng số): Tính ∇W = (∇Y)^T · X, tạo ra gradient dùng để cập nhật trọng số
Nhóm nghiên cứu giữ nguyên tất cả các yếu tố khác, lần lượt thay thế ba thao tác này từ FP8 sang MXFP4, quan sát ảnh hưởng của mỗi bước đến sự hội tụ. Tất cả thí nghiệm đều được thực thi trên AMD Instinct MI355X sử dụng tensor core FP4 nguyên sinh, không phụ thuộc vào mô phỏng phần mềm.
Nhiệm vụ huấn luyện là thiết lập tiêu chuẩn MLPerf, tiền huấn luyện Llama 3.1-8B trên tập dữ liệu C4, mục tiêu hội tụ là đạt độ bối rối (perplexity) trên tập kiểm định là 3.3.
Hai bước đầu chỉ dẫn đến hao phí token thêm nhẹ nhàng, nhưng ngay khi thay thế Wgrad bằng MXFP4, hao phí nhảy vọt lên 26-27%.
Wgrad là nút thắt (bottleneck) của việc huấn luyện FP4. Lan truyền xuôi và gradient của kích hoạt có khả năng chịu đựng tương đối với lượng tử hóa FP4, nhưng gradient của trọng số một khi bị lượng tử hóa xuống 4-bit, chất lượng hội tụ lập tức xuống cấp đáng kể.
Trực giác chủ đạo của ngành trước đây là: Lỗi lượng tử hóa FP4 về bản chất là vấn đề nhiễu (noise), do đó có thể "làm mịn" phân bố lỗi bằng cách bơm vào tính ngẫu nhiên. Hai chiến lược phổ biến là:
Làm tròn ngẫu nhiên (Stochastic Rounding): Đưa tính ngẫu nhiên vào khi lượng tử hóa, làm cho kỳ vọng của lỗi làm tròn bằng không.
Phép quay Hadamard ngẫu nhiên (Randomized Hadamard): Sử dụng biến đổi Hadamard với việc lật dấu ngẫu nhiên để làm phân tán phân bố dữ liệu trước khi lượng tử hóa.
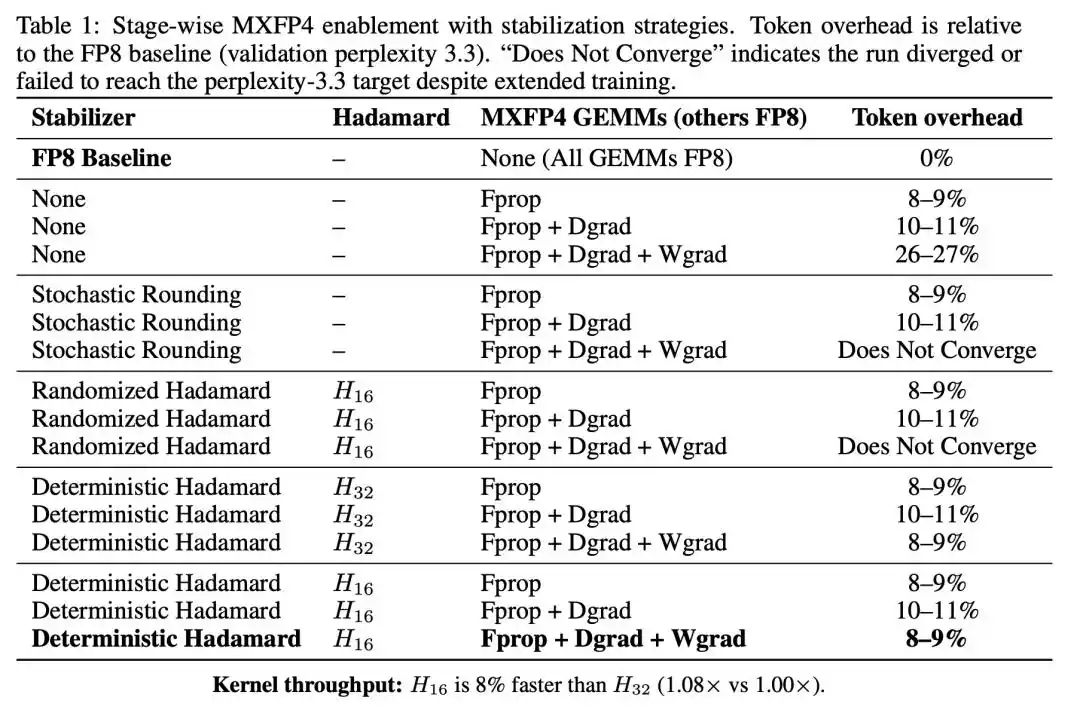
Khi Wgrad bị lượng tử hóa, cả hai chiến lược ngẫu nhiên không những không ổn định được việc huấn luyện, mà còn trực tiếp dẫn đến không hội tụ. Tính ngẫu nhiên không những không giúp ích, mà còn đưa thêm nhiều lỗi lượng tử hóa hiệu quả vào đường dẫn gradient quan trọng.
Ngược lại, phép quay Hadamard tất định (deterministic) đã ép hao phí token toàn quy trình từ 26-27% trở lại chỉ còn 8-9%, quỹ đạo huấn luyện bám sát đường cơ sở FP8.
Đây là một kết quả rất có giá trị chẩn đoán. Cả phép quay Hadamard ngẫu nhiên và tất định đều là phép biến đổi trực giao, đều có thể làm phân tán năng lượng của các giá trị ngoại lai, về lý thuyết hiệu quả giảm nhẹ lỗi lượng tử hóa nên tương tự. Nhưng biểu hiện của chúng trong kịch bản Wgrad lại hoàn toàn trái ngược, điều này tiết lộ bản chất của vấn đề:
Sự bất ổn định của việc huấn luyện FP4, được thúc đẩy bởi lỗi cấu trúc do vi chia tỷ lệ MXFP4 tạo ra trên các đường dẫn gradient nhạy cảm. Các chiến lược ngẫu nhiên thất bại vì chúng đưa vào các mẫu lỗi (error pattern) khác nhau ở mỗi bước, và những mẫu lỗi biến đổi này tích lũy dọc theo đường dẫn gradient, ngược lại còn khuếch đại sự bất ổn định. Lý do phép quay tất định có hiệu quả, chính xác là vì nó áp dụng cùng một phép biến đổi ở mỗi bước, làm cho mẫu lỗi nhất quán, tránh được sự tích lũy lỗi.
Hiệu suất đầu cuối: Thông lượng bước huấn luyện +20%, tốc độ tổng hợp tăng 9-10%
Sau khi áp dụng phép quay Hadamard tất định kết hợp với MXFP4 toàn quy trình, dữ liệu hiệu suất như sau:

Thông lượng của mỗi bước huấn luyện tăng 20%, sau khi trừ đi hao phí token tăng thêm 8-9%, tốc độ tổng hợp đầu cuối vẫn tăng 9-10%.
Xét rằng đây là việc cắt trực tiếp độ chính xác từ 8-bit xuống 4-bit, cả chất lượng hội tụ và mức độ tăng tốc này đều khá ấn tượng.
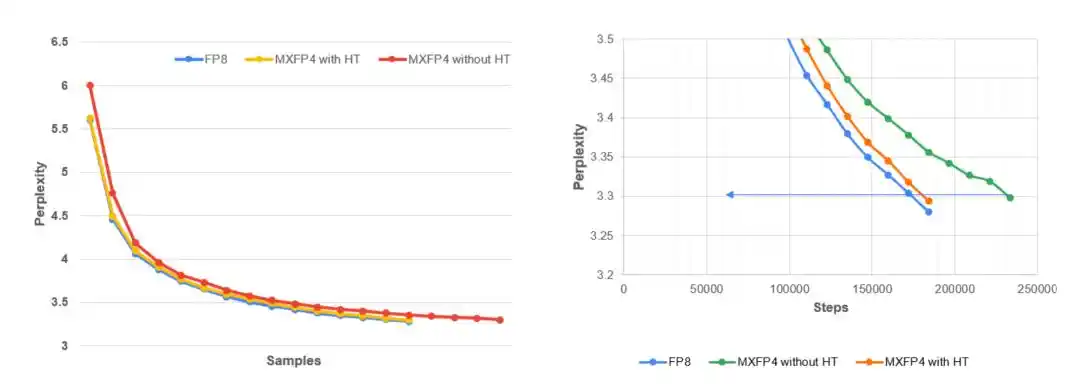
Hình trái: Đường cong độ bối rối trên tập kiểm định (validation perplexity) của Llama 3.1–8B theo số token huấn luyện khi tiền huấn luyện MLPerf trên tập dữ liệu C4. Kết quả cho thấy, MXFP4 + Hadamard tất định có biểu hiện rất gần với FP8, trong khi MXFP4 toàn quy trình không xử lý ổn định hóa thì hội tụ chậm hơn và tính ổn định huấn luyện cũng kém hơn. Hình phải: Khung nhìn phóng to cục bộ ở giai đoạn cuối huấn luyện. Mục tiêu độ bối rối của MLPerf là 3.3. So với chạy MXFP4 không ổn định hóa, Hadamard tất định (H16) có thể duy trì sự nhất quán chặt chẽ hơn với đường cơ sở FP8.
Đáng chú ý, các tác giả trong bài báo đã nhấn mạnh rõ ràng một hạn chế quan trọng: Hiệu quả của phương án huấn luyện FP4 này (tập dữ liệu MLPerf C4 + Llama 3.1-8B) đã được xác minh, nhưng không thể trực tiếp giả định rằng nó có thể chuyển đổi liền mạch cho mọi mô hình, mọi tập dữ liệu và mọi phương pháp huấn luyện. Hành vi của việc huấn luyện FP4 có thể phụ thuộc cao vào thiết lập cụ thể, các chiến lược ổn định cụ thể cần được xác minh lại theo từng kịch bản.
Lời kết
Đặt bài báo này vào bối cảnh ngành công nghiệp lớn hơn, nó có ít nhất ba tầng ý nghĩa.
Tầng thứ nhất: Nó trả lời một câu hỏi cơ bản "Tại sao". Các công trình huấn luyện FP4 trước đây phần lớn tập trung vào "làm sao để nó không sụp", bài báo này lần đầu tiên đưa ra một chẩn đoán nhân quả rõ ràng: sự sụp đổ bắt nguồn từ lỗi vi chia tỷ lệ cấu trúc trên đường dẫn Wgrad, chứ không phải do tính ngẫu nhiên không đủ. Bản thân chẩn đoán này đã có giá trị về phương pháp luận, nó nói với các nhà nghiên cứu tiếp theo: khi gặp phải sự bất ổn định trong huấn luyện độ chính xác thấp, nên ưu tiên điều tra nguồn lỗi cấu trúc, thay vì mù quáng tăng tính ngẫu nhiên.
Tầng thứ hai: Nó đẩy FP4 từ "chuyên cho suy luận (inference)" sang "có thể dùng cho huấn luyện". Trước đây, sự đồng thuận của ngành là FP4 chỉ phù hợp cho lượng tử hóa suy luận, huấn luyện ít nhất phải dùng FP8. NVIDIA chủ trương đẩy mạnh FP4 cho suy luận chứ không phải huấn luyện trên Blackwell, cũng phản ánh nhận định này. Bài báo này đã chạy thông suốt quy trình tiền huấn luyện trên phần cứng FP4 nguyên sinh, có nghĩa là năng lực tính toán FP4 vốn được chuẩn bị cho suy luận trên MI355X và Blackwell, về lý thuyết cũng có thể dùng để huấn luyện. Nếu việc huấn luyện FP4 được xác minh là khả thi trên nhiều mô hình lớn hơn và nhiều kịch bản hơn, đồng nghĩa với việc năng lực tính toán có sẵn cho huấn luyện trên phần cứng hiện tại có thể tăng gấp đôi.
Tầng thứ ba: Nó sử dụng tiêu chuẩn mở OCP. MXFP4 là một phần của tiêu chuẩn định dạng OCP Microscaling, đằng sau có sự hỗ trợ chung của bảy công ty: AMD, NVIDIA, Intel, Meta, Microsoft, Arm, Qualcomm. Dựa trên tiêu chuẩn mở có nghĩa là phương pháp này có tính khả chuyển trên phần cứng của các nhà sản xuất khác nhau, không bị khóa chặt vào một hệ sinh thái duy nhất.
Từ FP16 đến FP8, DeepSeek-V3 đã chứng minh cắt đôi độ chính xác có thể giảm mạnh chi phí huấn luyện. Từ FP8 đến FP4, bài báo này đã thực hiện bước đầu tiên quan trọng. Mỗi lần cắt một nhát vào độ chính xác, toàn bộ tính kinh tế của việc huấn luyện mô hình lớn đều đang chuyển biến.
Bài viết này từ tài khoản công chúng WeChat "Machine Heart" (ID:almosthuman2014), biên tập: Leng Mao