Hai năm qua, các mô hình tạo video AI đang phát triển cực nhanh. Từ hiệu ứng gây kinh ngạc lúc Sora mới ra mắt vào cuối năm 2024, cho đến sự bùng nổ đa điểm của các mô hình tạo video như Google Veo, Sora 2, Kling, và Seedance 2.0 đầu năm nay, chất lượng video do AI tạo ra đã có một bước nhảy vọt về chất, có thể tạo ra những video vài phút, đa nhân vật, cảnh phức tạp với hiệu ứng chân thực như phim điện ảnh.
Đối diện với sự phát triển nhanh chóng ở phía tạo sinh, sự quan tâm của giới nghiên cứu đối với việc phát hiện video AI vẫn không mấy nổi bật.
Trong thực tế, chúng ta dễ dàng nhận thấy rằng tính chất đa phương thức của video mang lại khả năng đánh lừa lớn hơn nhiều so với hình ảnh, gây ra những tác động xã hội to lớn:
Trên các nền tảng mạng xã hội, video giả do AI tạo ra xuất hiện thường xuyên, và số lượng, chất lượng, phạm vi bao phủ đều đang tăng mạnh. Khi người dùng hỏi các mô hình nền tảng như Grok, Đậu Bắp "Video này có phải do AI tạo không?", câu trả lời nhận được thường chỉ là những phán đoán đúng/sai thiếu tính giải thích và độ tin cậy; trên các nền tảng như Xiaohongshu, video quay thực tế lại thường bị đánh dấu là "nghi ngờ do AI tạo".
Giữa sự phát triển nhanh chóng ở phía tạo sinh và sự thiếu hụt quan tâm ở phía phát hiện đang tồn tại một khoảng cách lớn. Chúng ta phải kịp thời quan tâm: Trong bối cảnh tạo video AI đang lặp lại nhanh chóng ngày nay, nghiên cứu phát hiện video do AI tạo đã phát triển đến đâu, đang trải qua sự thay đổi mô hình thức như thế nào, và cần hướng đến những phương hướng nào trong tương lai.
Trong bối cảnh đó, các nhà nghiên cứu từ MBZUAI, Đại học Nhân dân Trung Quốc và Đại học Harvard đã cùng viết và công bố một bài tổng quan dài năm mươi trang, lần đầu tiên hệ thống hóa con đường công nghệ từ nhận thức thị giác cấp thấp đến suy luận cấp thế giới cao cấp từ cả hai hướng thị giác và ngôn ngữ. Dựa trên đó, bài viết phân tích hệ thống phát hiện đáng tin cậy, động, có thể truy nguyên, có thể giải thích với bằng chứng đa tầng ghép nối mà hiện nay đang rất cần thiết, hiện đã được ACL 2026 chấp nhận đăng.

Liên kết bài báo:https://www.researchgate.net/doi/10.13140/RG.2.2.31713.88168
Liên kết GitHub:https://github.com/dxhou/AI-Generated-Video-Detection
Liên kết Trang chủ:https://AIgcvdetection.github.io
Viết Lại Mục Tiêu Phát Hiện Video Do AI Tạo
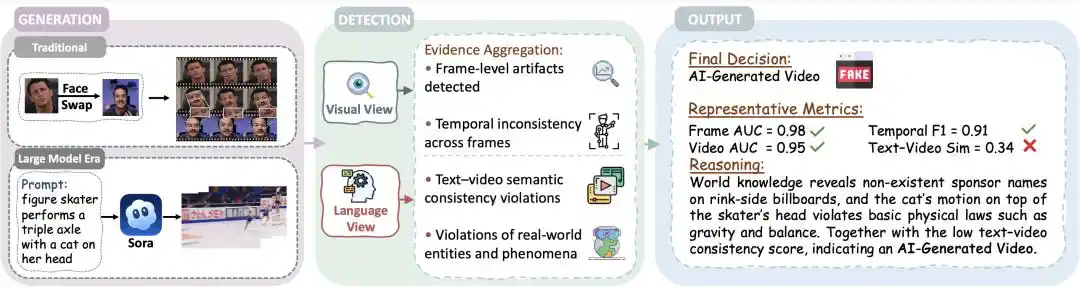
Hình 1 | Quy trình hoàn chỉnh phát hiện video do AI tạo: Từ phía tạo sinh, phát hiện song quan điểm, đến tập hợp bằng chứng
Trước khi AI tạo sinh bùng nổ, video do AI tạo sẽ để lại các dấu vết giả (artifact) thị giác tương đối rõ ràng. Dựa trên tiền đề này, trong các cảnh Deepfake đại diện thời kỳ đầu, việc xác minh ở phía nhận thức thị giác cấp khung hình là đủ hiệu quả.
Tuy nhiên, trong hai năm gần đây, chất lượng video trong thời đại AI tạo sinh phát triển chóng mặt đã dần vượt qua "tiền đề" này, mắt người ngày càng khó có thể phán đoán tính chân thực của những video hoàn chỉnh. Lúc này, việc phát hiện chỉ đưa ra phán đoán phân loại nhị phân đã không còn đáp ứng được nhu cầu, cần phải trả lời kịp thời: Bộ phát hiện dựa trên bằng chứng nào để hỗ trợ phán đoán đáng tin cậy.
Bài tổng quan này trước tiên đẩy biên giới của vấn đề phát hiện lên phía trước: Chỉ ra rằng đầu ra của việc phát hiện cần chuyển từ "phân loại nhị phân thật/giả sang phán đoán có cấu trúc có thể giải thích, đáng tin cậy", từ đó đẩy đối tượng phát hiện tiến tới việc hướng tới việc xác minh khoảng cách giữa "thế giới ảo" và "thế giới thực" trong video.
Do đó, bài tổng quan trước tiên xác định lại mục tiêu phát hiện, định nghĩa lại là "xác minh độ trung thực với sự thật" (factual fidelity verification), tức là kiểm tra xem các mệnh đề về "ai, khi nào, ở đâu, điều gì đã xảy ra" trong nội dung video có đồng thời nhất quán và phù hợp với thế giới thực về mặt nhận thức và nhận thức hay không. Ngoài việc xác minh giữa các phương thức và thị giác, cần phải đánh giá thêm xem việc video chứa những mệnh đề này có xung đột với các "sự thật, quy luật vật lý và kiến thức thế giới" bên ngoài hay không.
Đối Tượng Phát Hiện: Ba Mô Hình Thức Của Video Do AI Tạo

Hình 2 | Ba loại mô hình video do AI tạo được định nghĩa trong bài tổng quan này
Từ năm 2020 đến nay, video do AI tạo đã trải qua sự chuyển dịch về mô hình thức: từ việc sửa đổi cục bộ video thông qua GAN trong thời kỳ Deepfake đầu, đến tái tổ hợp hình ảnh-âm thanh như thay đổi khẩu hình và giọng nói, và sau đó là tổng hợp toàn bộ video AI được hỗ trợ bởi "bộ mô phỏng thế giới" kiểu Sora do mô hình khuếch tán không gian tiềm ẩn (latent diffusion model) thúc đẩy. Bài tổng quan phân chia video do AI tạo thành ba mô hình thức sau:
Video Thao Tác Cục Bộ Giữ Nguyên Vật Mang Thực (Local Manipulation Video, LMV)
LMV từ lâu đã là mô hình thức điển hình và trưởng thành nhất cho việc phát hiện Deepfake truyền thống. Bản thân video xử lý các khu vực cục bộ của video quay thực, chẳng hạn như thay đổi khuôn mặt, nền, v.v.; trong khi hầu hết cấu trúc ban đầu của video như cảnh, hành động nhân vật, chuyển động máy quay, quan hệ ánh sáng thường vẫn còn. Do đó, phần lớn các phương pháp thời kỳ đầu cũng xoay quanh việc tìm kiếm các dấu vết giả cục bộ, đặc trưng miền tần số, bất thường hình học và tính nhất quán khu vực. Tuy nhiên, khả năng của các mô hình tạo sinh trong việc hòa trộn cục bộ, điều chỉnh ánh sáng và chuyển đổi danh tính ngày càng mạnh mẽ hơn; việc xử lý nền tảng và lan truyền thứ cấp sẽ xóa bỏ nhiều dấu vết nhỏ; trọng tâm phát hiện đối với mô hình thức LMV dần chuyển sang chú ý nhiều hơn đến tính mạnh mẽ (robustness) của phương pháp phát hiện trong các tình huống khác nhau.
Chỉnh Sửa Âm Thanh-Hình Ảnh Trong Ràng Buộc Ghép Nối Đa Phương Thức (Audio-Visual Editing, AVE)
Mô hình thức AVE chủ yếu nổi lên vào năm 2024. Trong các video do AI tạo loại này, những thay đổi là mối quan hệ tương ứng vốn đã được thiết lập bên trong video giữa bản thân hình ảnh và âm thanh, khẩu hình, danh tính người nói, nhịp điệu nói, nội dung phụ đề, v.v. Điều này bao gồm tổng hợp khuôn mặt được điều khiển bằng giọng nói, lồng tiếng mới cho video gốc, thay đổi khẩu hình, thay người nói. Điều này khiến phía phát hiện cần chuyển từ việc tìm kiếm dấu vết giả thị giác sang việc kiểm tra xem mối quan hệ giữa một số phương thức bên trong video có thực sự thành lập hay không, đặt âm thanh, khẩu hình, danh tính và nội dung lại với nhau để tìm ra manh mối thực sự có khả năng phán đoán.
Tổng Hợp Video Tạo Sinh Từ Đầu Đến Cuối (Generative Video Synthesis, GVS)
Mô hình thức GVS bùng nổ vào năm 2025, trong đó mô hình trực tiếp tạo ra toàn bộ video dựa trên thông tin điều kiện như văn bản, hình ảnh, nhiễu, v.v., không còn dựa vào video thực làm nền tảng, mang lại thách thức hoàn toàn mới cho phía phát hiện.
Những video loại này thường trông rất thật ở một khung hình đơn lẻ hoặc trong thời gian ngắn, nhưng trên chuỗi không-thời gian dài thường sẽ xuất hiện lỗ hổng: ví dụ như hành động của nhân vật hoặc vị trí trong cảnh không thể kết nối trước sau, hình dạng, chuyển động của vật thể thay đổi không phù hợp với quy luật vật lý, hoặc bản thân sự kiện trong video không thể xảy ra trong thế giới thực.
Tương ứng, tư duy phát hiện đối với mô hình thức GVS cũng không thể chỉ giới hạn ở tính nhất quán cục bộ, giữa các phương thức, mà cần hướng tới cấp độ cao hơn, xuất phát từ tính nhất quán dài hạn, kiến thức thông thường, quy luật vật lý, câu chuyện và nguyên nhân, tính chân thực ở cấp độ mệnh đề và khả năng truy nguyên, v.v., kiểm tra trên chuỗi không-thời gian dài xem bản thân nội dung có đáng tin cậy hay không, xem liệu nội dung video có thể thành lập ở mọi cấp độ trong thế giới thực hay không.
Phả Hệ Phương Pháp Phát Hiện Bốn Lớp Dưới Góc Nhìn Song Quan Điểm Thị Giác-Ngôn Ngữ
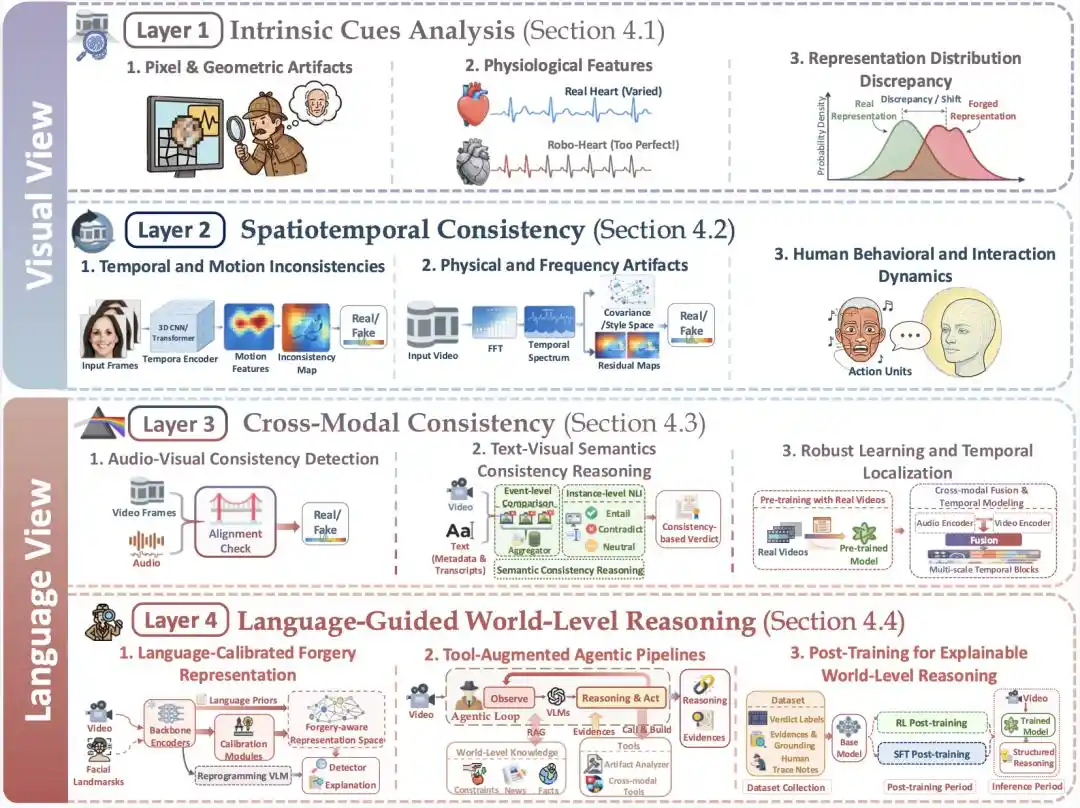
Hình 3 | Khung bốn lớp Vision-Language Dual-View: Hai lớp đầu nghiêng về góc nhìn thị giác, hai lớp sau hướng tới góc nhìn ngôn ngữ
Hiện tại, góc nhìn phương thức để thực hiện phát hiện video do AI tạo đã được phân hóa, có thể chia thành hai loại vấn đề khoa học cốt lõi: Loại thứ nhất xuất phát từ phương thức thị giác, tập trung vào việc thu thập chứng cứ tín hiệu cấp thấp và tính nhất quán không-thời gian của hình ảnh.
Loại thứ hai xuất phát từ phương thức ngôn ngữ, quan tâm chủ yếu bao gồm thông tin ngôn ngữ đa phương thức của bản thân video, đánh giá "liệu video có thực sự kể chuyện một cách phù hợp giữa các phương thức hay không"; và sử dụng phương thức ngôn ngữ để đưa vào suy luận liên quan đến kiến thức, sự thật về thế giới, đánh giá "liệu nội dung video có thể chịu được sự kiểm tra của kiến thức, sự thật, quy luật, v.v. bên ngoài thế giới thực hay không".
Bài tổng quan nắm bắt xu hướng chuyển đổi này, đề xuất xuất phát từ góc nhìn song quan điểm thị giác-ngôn ngữ để tổ chức các phương pháp nghiên cứu và mô hình đánh giá phát hiện video do AI tạo, trên cơ sở đó đề xuất thêm cảnh quan phương pháp bốn lớp từ nhận thức cấp thấp đến nhận thức cấp cao dưới đây.
Bao gồm bốn lớp sau:
Lớp 1, Manh Mối Thị Giác Cấp Thấp (Intrinsic Cues Analysis): Màng Lọc Đầu Tiên
Các phương pháp trong Lớp 1 quan tâm đến vấn đề nghiên cứu: Ở cấp độ tín hiệu thị giác cơ bản, video có tuân theo các quy luật thống kê mà video thực cần đáp ứng hay không, và video có tồn tại các manh mối cấp thấp do mô hình AI tạo ra hoặc thao tác chỉnh sửa đưa vào hay không.
Ở cấp độ tín hiệu cơ bản, video thực sẽ thỏa mãn các đặc tính thống kê tương ứng, đồng thời video thu được từ quá trình quay và xử lý thực tế sẽ tự nhiên phù hợp với quá trình thu, mã hóa và hậu xử lý; trong khi quá trình tạo sinh AI thường để lại các manh mối lệch khỏi phân phối video thực như kiểu dáng đơn điệu, watermark và artifacts tương ứng với mô hình, các tín hiệu sinh lý cứng nhắc có thể phát hiện được; các phương pháp trong Lớp 1 xuất phát từ góc nhìn thị giác thông qua việc mô hình hóa, trích xuất và khuếch đại các tín hiệu cơ bản này để thu thập chứng cứ. Bao gồm việc phát hiện:
Các bất thường về pixel và hình học như miền tần số, kết cấu, đường biên, mẫu nhiễu;
Các tín hiệu sinh lý trên khuôn mặt như nhịp tim, cử động cơ nhỏ, nhịp chớp mắt;
Liệu có tồn tại sự lệch hệ thống trong không gian đặc trưng giữa video thực và video giả mạo.
Lớp 2, Tính Nhất Quán Không-Thời Gian (Spatiotemporal Consistency): Kiểm Tra "Một Đoạn Video Có Trôi Chảy Không"
Các phương pháp trong Lớp 2 nhắm vào khái niệm "sự kết hợp tuần tự của nhiều khung hình trong video theo thời gian và không gian", quan tâm đến vấn đề nghiên cứu: Trong chiều không-thời gian, dòng hình ảnh của video có thỏa mãn các đặc điểm mà quá trình chuyển động của vật thể trong video thực cần đáp ứng hay không. Video quay thực cần chịu sự giới hạn của quỹ đạo máy ảnh liên tục và môi trường cảnh thực tế, hình ảnh chủ thể và nền giữa các khung hình liền kề sẽ thể hiện các mô hình thay đổi không-thời gian liên tục, có thể dự đoán phù hợp với tính khả thi vật lý và chuyển động máy ảnh. Trong khi đó, video do AI tạo có thể xuất hiện sự không liên tục về không-thời gian như biến dạng vật thể cục bộ, trôi nền, mờ đột ngột, artifact chuyển động bất thường trên chuỗi thời gian dài. Bao gồm việc phát hiện:
Sự không nhất quán về thời gian và chuyển động như biến dạng vật thể cục bộ, trôi nền, mờ đột ngột, artifact chuyển động bất thường;
Hành vi và tương tác động của con người như thay đổi biểu cảm, động thái danh tính, nhịp độ tương tác giữa các nhân vật chính trong khung hình;
Các bất thường về vật lý và tần số liên quan đến tần số thời gian và tính liên tục của hình ảnh.
Lớp 3, Tính Nhất Quán Xuyên Phương Thức (Cross-Modal Consistency): Xác Minh Đa Phương Thức Bên Trong Video
Lớp 3 là một điểm chuyển đổi then chốt trong toàn bộ khung: việc phát hiện bắt đầu đi vào xác minh đa phương thức bên trong video, quan tâm đến vấn đề nghiên cứu: Các phương thức như hình ảnh, âm thanh, phụ đề trong video "có kể cùng một nội dung ở mọi cấp độ một cách phù hợp hay không".
Video thực thường có sự phù hợp cao giữa các phương thức đi kèm như âm thanh, văn bản, hình ảnh. Trong khi video do AI tạo có thể tồn tại sự không khớp hệ thống giữa khẩu hình - giọng nói, danh tính - âm sắc, hình ảnh - văn bản. Các phương pháp Lớp 3 thực hiện phân tích tính nhất quán chi tiết, đa góc độ đối với sự nhất quán giữa các phương thức. Bao gồm ba loại:
Phát hiện tính nhất quán giữa âm thanh và hình ảnh;
Đưa vào phụ đề, tiêu đề, văn bản chuyển ngữ, văn bản mô tả sau đó thực hiện suy luận về tính nhất quán ngữ nghĩa văn bản - video;
Hướng tới việc học tính mạnh mẽ (robust learning) cho việc định vị thời gian sự không nhất quán giữa các phương thức.
Lớp 4, Suy Luận Cấp Thế Giới Được Hướng Dẫn Bằng Ngôn Ngữ (Language-Guided World-Level Reasoning): Hướng Vào Khoảng Cách Giữa Video Và Thế Giới Thực
Góc nhìn phát hiện của Lớp 4 được nâng từ "tính nhất quán bên trong video" lên "tính nhất quán, không xung đột với các quy tắc, kiến thức trong thế giới thực bên ngoài", vấn đề nghiên cứu quan tâm chuyển thành: Về mặt ngữ nghĩa và sự thật, nội dung video có thực sự có thể tồn tại, có hợp lý trong thế giới thực hay không.
Tất cả nội dung của video thực phải nhất quán với các sự thật, quy tắc vật lý, kiến thức lĩnh vực, kiến thức thông thường cơ bản, v.v. của thế giới thực. Trong khi nội dung của video do AI tạo thường khó hoàn toàn align (căn chỉnh) với thế giới thực, đây chính là không gian phát hiện mà Lớp 4 tận dụng. Bao gồm:
Sử dụng prompt, tiên nghiệm văn bản, nguyên mẫu văn bản hoặc module nhẹ để hiệu chỉnh lại không gian biểu diễn của mô hình, từ đó khiến mô hình dễ dàng hơn trong việc ánh xạ các bất thường nhìn thấy với các loại ngữ nghĩa rõ ràng hơn;
Xem việc phát hiện như một quy trình điều tra, xây dựng một tác nhân thông minh (intelligent agent) biết tra cứu tài liệu, biết gọi công cụ, biết quay lại sửa đổi phán đoán, ánh xạ phán đoán với bằng chứng, đầu ra công cụ, quá trình điều tra, v.v.;
Thông qua fine-tuning, học ưu tiên (preference learning), mô hình hóa phần thưởng (reward modeling) và học tăng cường (reinforcement learning), huấn luyện "cách chọn bằng chứng, cách tổ chức giải thích, cách đưa ra kết luận" vào chính mô hình. Tập trung vào việc đưa ra đầu ra phát hiện rõ ràng, cấu trúc ổn định, chuỗi bằng chứng hoàn chỉnh.
Biểu Đồ Tiến Hóa Của Phía Tạo Sinh Và Phía Phát Hiện
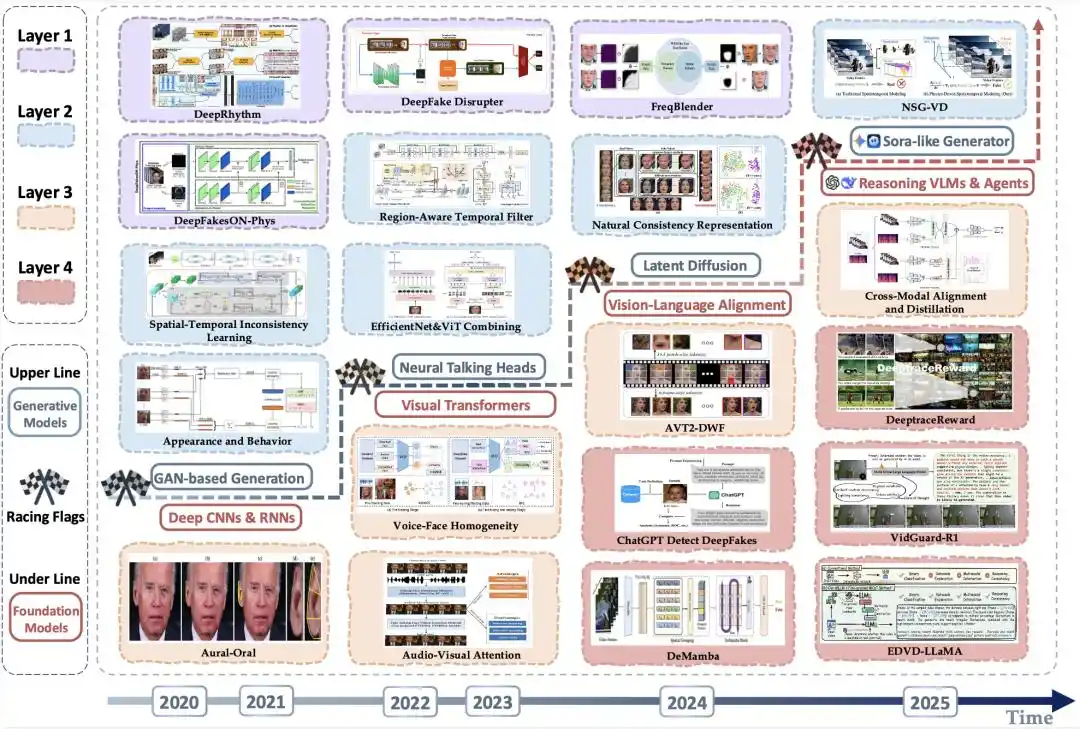
Hình 4 | Biểu đồ tiến hóa các phương pháp phát hiện tiêu biểu: Mối đe dọa từ phía tạo sinh gia tăng và sự nâng cao đồng bộ từ phía phát hiện
Hình trên trình bày dọc theo dòng thời gian việc mối đe dọa từ phía tạo sinh không ngừng nâng cao "giới hạn trên" về độ chân thực mà "video giả" có thể đạt được, trong bối cảnh các mô hình nền tảng mà công nghệ phát hiện dựa vào đã trải qua sự tiến hóa từ mạng nơ-ron tích chập sâu và mạng tuần hoàn, đến Transformer thị giác, và sau đó là các mô hình lớn ngôn ngữ-thị giác và hệ thống tác nhân thông minh có khả năng suy luận, biểu đồ tiến hóa của phía phát hiện từ việc thu thập chứng cứ thị giác dần tiến tới xác minh đa phương thức và phát hiện suy luận cấp cao.
Bài tổng quan tiếp tục thống kê sự phân bố theo thời gian của các phương pháp phát hiện theo các lớp. Tỷ lệ các phương pháp ở Lớp 3 và Lớp 4 (góc nhìn ngôn ngữ) trong tổng số các phương pháp phát hiện được công bố hàng năm đã tăng đáng kể: từ chỉ 7.7% vào năm 2020, lên 40.0% vào năm 2023, và vượt quá một nửa vào năm 2025.
Tóm lại, trọng tâm của phương pháp phát hiện đang dịch chuyển lên trên liên tục: thời kỳ đầu chủ yếu tập trung vào Lớp 1 và Lớp 2, trong khi khi video tạo sinh ngày càng mượt mà, chân thực hơn, việc phát hiện bắt đầu chuyển nhiều hơn sang Lớp 3 và Lớp 4.
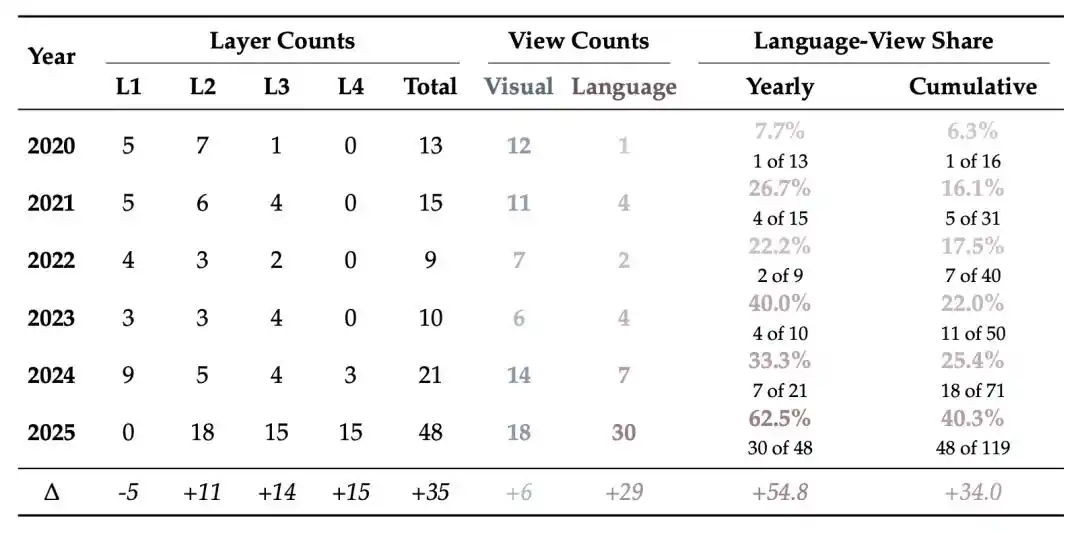
Hình 5 | Thống kê thay đổi phân bố phương pháp phát hiện: Tỷ lệ góc nhìn ngôn ngữ dần tăng lên
Đánh Giá Phương Pháp Phát Hiện
Đối mặt với mục tiêu phát hiện độ trung thực với sự thật, việc đánh giá phương pháp phát hiện cần trả lời: Mô hình có nắm bắt được các manh mối thị giác có thể chuyển giao không, có thể nhận diện sự không nhất quán không-thời gian và xuyên phương thức không, có thể đưa ra phán đoán hiệu quả đối với các sự thật, kiến thức và ràng buộc thế giới không. Bài tổng quan hệ thống hóa sự tiến hóa của các chỉ số đánh giá, tập dữ liệu từ thời đại Deepfake truyền thống đến ngày nay.
Chỉ Số Đánh Giá Dưới Góc Nhìn Song Quan Điểm Thị Giác-Ngôn Ngữ
Chỉ Số Chung: Acc / AUC Vẫn Cần Thiết, Nhưng Là Chưa Đủ
Acc, AUC, Precision, Recall, F1, EER, PR-AUC, cùng cách thức tổng hợp ở cấp độ khung hình (frame-level) và cấp độ video (video-level), vẫn là ngôn ngữ chung cơ bản nhất giữa các phương pháp khác nhau, cho phép các phương pháp ở các cấp độ khác nhau có thể so sánh ngang hàng. Tuy nhiên, các chỉ số đánh giá cơ bản này vẫn cần thiết, nhưng không thể đáp ứng yêu cầu đánh giá có thể giải thích, đáng tin cậy dưới mục tiêu xác minh độ trung thực với sự thật.
Chỉ Số Dưới Góc Nhìn Thị Giác: Đánh Giá Liệu Các Manh Mối Có Thể Thành Lập Dưới Nhiễu Loạn Môi Trường Thực
Trọng tâm của việc đánh giá nằm ở việc khi bộ phát hiện gặp phải sự thay đổi phân phối, nén và lan truyền, và nhiễu loạn môi trường thực, các manh mối ban đầu của nó có thể tiếp tục thành lập hay không. Chia thành hai loại sau:
- Tính mạnh mẽ của manh mối cấp thấp (Robustness of low-level cues): Bao gồm TPR@FPR=α với ngưỡng cố định, kiểm tra chéo tập dữ liệu (cross-dataset testing), kiểm tra áp lực nhiễu loạn (perturbation pressure test), v.v.
- Tính nhất quán không-thời gian và vật lý (Spatiotemporal and physical consistency): Tập trung vào báo cáo cấp video (video-level reporting), sự suy giảm do nhiễu loạn thời gian (temporal perturbation drop), loại bỏ chuyển động (motion ablation), và liệu mô hình có suy thoái đáng kể sau khi loại bỏ thông tin thời gian hay không, từ đó đánh giá liệu bộ phát hiện có thực sự đang xem tính liên tục của toàn bộ video, hay vẫn dựa vào các shortcut trong khung hình đơn để đưa ra phán đoán.
Chỉ Số Dưới Góc Nhìn Ngôn Ngữ: Đánh Giá Định Vị Đa Phương Thức Và Suy Luận
Phạm vi bao phủ của con đường phát hiện dưới góc nhìn ngôn ngữ rộng hơn, các chỉ số đánh giá không thể chỉ tóm gọn bằng một bộ chỉ số phân loại đơn giản. Bài tổng quan phân tầng như sau:
- Sự phù hợp xuyên phương thức và định vị thời gian (Cross-modal alignment and temporal localization): Các chỉ số đánh giá loại này hướng tới độ chính xác của việc phát hiện trong sự phù hợp xuyên phương thức, và khả năng bộ phát hiện có thể định vị manh mối đến khoảng thời gian cụ thể. Ngoài Acc và AUC cơ bản, các chỉ số phổ biến còn thêm vào AP, AR, Recall@K, mAP@IoU, v.v.
- Kiến thức thế giới và suy luận (World knowledge and reasoning): Đối mặt với vấn đề cấp cao hơn "liệu sự kiện mà video kể có thể được hỗ trợ bởi kiến thức thông thường, quy luật vật lý, kiến thức bên ngoài và bằng chứng cụ thể hay không", các chỉ số đánh giá phát hiện cần đưa vào các đánh giá của con người (human judgments), ưu tiên theo cặp (pairwise preferences), trả lời câu hỏi (question answering), cũng như các chỉ số như BLEU, ROUGE-L, METEOR, CIDEr, độ tương tự dựa trên embedding (embedding-based similarity) để đánh giá chất lượng giải thích.
Tập Dữ Liệu: Tổ Chức Lại Theo Ba Mô Hình Thức Của Đối Tượng Phát Hiện
Phần lớn các tập dữ liệu được sử dụng để đánh giá và huấn luyện phương pháp phát hiện tự nhiên sẽ phân hóa theo các mô hình thức video do AI tạo đã đề cập trước đó. Bài tổng quan đã hệ thống hóa như sau:
- Tập dữ liệu hướng tới mô hình thức LMV: Trọng tâm đánh giá tập trung vào tính ổn định của manh mối thị giác của phương pháp phát hiện, và liệu các manh mối này có thể tiếp tục thành lập trong điều kiện méo mó, nén và lan truyền xuyên miền hay không; loại tập dữ liệu này đang không ngừng tiếp cận môi trường thực thông qua việc thu nạp việc suy luận thời gian và đánh giá giải thích.
- Tập dữ liệu hướng tới mô hình thức AVE: Loại tập dữ liệu này thường nhấn mạnh hơn vào việc gán nhãn thời gian chi tiết, mối quan hệ tương ứng xuyên phương thức rõ ràng hơn, và mô hình hóa mạnh mẽ hơn về sự không khớp cục bộ và sai lệch ngữ nghĩa. Kiểm tra xem mô hình có thể phát hiện âm thanh và video không nói cùng một câu chuyện không, có thể định vị khoảng thời gian xảy ra sự không khớp không, có thể phân biệt vấn đề đồng bộ, vấn đề danh tính và vấn đề ngữ nghĩa không.
- Tập dữ liệu hướng tới mô hình thức GVS: Video tổng hợp toàn bộ một mặt liên tục làm suy yếu các dấu vết chỉnh sửa rõ ràng, mặt khác lại liên tục mang đến cho việc phát hiện các thách thức như tính đa dạng của bộ tạo sinh, sự không phù hợp ngữ nghĩa và rủi ro chuyển giao; đánh giá tương ứng thay đổi nhanh nhất; từ việc thu thập một lượng lớn video tổng hợp toàn bộ để đánh giá độ chính xác của việc phát hiện thời kỳ đầu, đã phát triển đến các công trình như LOKI, GenWorld, DAVID-X, DeeptraceReward đưa việc mô phỏng thế giới, gán nhãn cấp độ khiếm khuyết, manh mối giả mạo theo nhận thức con người vào hệ thống đánh giá.
Đánh Giá Liên Quan Hướng Tới Chẩn Đoán Mô Hình Tạo Video
Các tài nguyên đánh giá liên quan đến phát hiện không giới hạn ở các tập dữ liệu hướng tới bản thân việc phát hiện. Trên thực tế, trong nghiên cứu liên quan đến CV và mô hình thế giới, nhiều đánh giá chẩn đoán chất lượng tạo sinh của mô hình tạo video và đánh giá khả năng sửa lỗi của mô hình hiểu video cũng có thể được sử dụng làm tài liệu tham khảo quan trọng cho việc phát hiện. Bài tổng quan đã hệ thống hóa các công trình đánh giá chẩn đoán có thể được sử dụng làm tài nguyên bổ sung theo chuỗi đánh giá được thúc đẩy dần dần:
- Đầu tiên xem xét các đối tượng, thuộc tính, tương tác và thay đổi trạng thái trong video có tuân theo các quy luật vật lý cơ bản không;
- Sau đó xem xét động thái thế giới và quan hệ nhân quả (world dynamics and causality), tức là liệu các quy luật cục bộ có thể mở rộng ra toàn bộ video để hình thành quá trình sự kiện liên tục, mạch lạc, phù hợp với kiến thức thế giới không;
- Cuối cùng xem xét liệu các hệ thống như mô hình hiểu video có thể chuyển đổi các lỗi ở các cấp độ khác nhau trong video tạo sinh thành các phán đoán rõ ràng, có thể hiểu được, có thể kiểm tra lại được không.
Từ "Có Thể Phân Biệt" Đến "Có Thể Đưa Ra Bằng Chứng"
Video do AI tạo có độ trung thực cao đang không ngừng nâng cao giới hạn trên về độ chân thực của nội dung giả mạo, vấn đề mà nhiệm vụ phát hiện đang phải đối mặt ngày càng khó có thể tóm gọn bằng một điểm số thật/giả, mà cần thực hiện phát hiện độ trung thực với sự thật; tương ứng, giai đoạn đánh giá và hệ thống phát hiện cũng cần mở rộng cùng với biên giới nhiệm vụ được mở rộng ra ngoài:
Hệ Thống Đánh Giá Động Ưu Tiên Bằng Chứng
Đối mặt với các video phức tạp có thời gian dài mới xuất hiện do AI tạo, việc đánh giá cần trả lời không chỉ là "mô hình có biết phân loại không", mà còn bao gồm "mô hình thực sự đã dựa vào manh mối nào để tạo ra phán đoán đúng hoặc sai". Trong khi đó, nhãn đánh giá ở mức độ thô sẽ che lấp một lượng lớn thông tin thực sự quan trọng, việc gán nhãn dữ liệu, huấn luyện mô hình và báo cáo kết quả trong đánh giá cũng cần cùng được đẩy lên phía trước, cần phân tách lại video thành các nhóm đơn vị mệnh đề có thể xác minh, chuyển đổi "câu chuyện dài theo thời gian" thành các đối tượng có cấu trúc có thể thao tác như chuỗi sự kiện, quỹ đạo trạng thái thực thể hoặc biểu đồ sự kiện, v.v., để có thể thực hiện xác minh nguyên nhân và ràng buộc trên thang đo thời gian dài, từ đó tiếp tục đặt câu hỏi sâu hơn về việc phát hiện "thực sự nắm bắt mệnh đề nào" và "bằng chứng và phán đoán có thể tương ứng một-một không".
Ngoài ra, hầu hết các bộ phát hiện vẫn được đánh giá trong thiết lập "thế giới đóng" (closed-world): trong các cảnh triển khai thực tế, các mô hình tạo video, công cụ chỉnh sửa và phong cách nội dung mới liên tục xuất hiện, các nền tảng khác nhau đưa vào các quy trình lấy mẫu xuống, chuyển mã và lọc riêng của họ. Để bù đắp khoảng trống tính mạnh mẽ dài hạn này, cần tham khảo cơ chế cập nhật liên tục kiểu arena/leaderboard, đưa các bộ tạo sinh mới được phát hành và các đường dẫn chuyển mã nền tảng mới vào tập hợp đánh giá theo cách thức streaming.
Hệ Thống Phát Hiện Đáng Tin Cậy, Có Thể Giải Thích Với Góc Nhìn Song Quan Điểm Hợp Tác
Để đạt được việc phát hiện có thể giải thích hướng tới độ trung thực với sự thật đã đề cập trước đó, cần cân bằng cả hai liên kết nhận thức - suy luận, kết hợp khả năng tiết lộ các dấu vết giả thị giác và sự không nhất quán không-thời gian của góc nhìn thị giác, với khả năng suy luận có cấu trúc của góc nhìn ngôn ngữ cấp cao, từ đó thông suốt cảnh quan phương pháp bốn lớp trong góc nhìn song quan điểm. Một mặt, hiện tại các mô hình ngôn ngữ-thị giác và mô hình hiểu video có khả năng phân biệt liên quan đến "độ trung thực nhận thức" (perceptual fidelity) kém hơn, cần các phương tiện từ góc nhìn thị giác để bổ sung; mặt khác, đối với video được tạo bởi các mô hình tạo sinh mạnh hơn và các phương tiện chống phát hiện có độ trung thực nhận thức cao, cần thực hiện phát hiện trong không gian ngữ nghĩa và sự thật từ góc nhìn ngôn ngữ ở cấp độ sự thật.
Hơn nữa, cần thiết lập con đường suy luận rõ ràng "nhận diện - định vị - giải thích". Điều này có nghĩa là, trong hệ thống song liên kết trên, mỗi lần gọi công cụ hoặc tham chiếu kiến thức đều phải ràng buộc chặt chẽ với các bước lập luận cụ thể.
Ngoài ra, hệ thống phát hiện được cấu thành ở phía "nội dung" nói trên cần được kiểm tra chéo với các tín hiệu xác thực có thể tồn tại ở phía "nguồn gốc", v.v., kết nối phân tích nội dung và truy nguyên nguồn gốc. Cuối cùng hình thành hệ thống phát hiện đa tầng, đa phương thức và không gian bằng chứng đáng tin cậy, có thể giải thích.
Kết Luận
Phát hiện video AI là một nhiệm vụ chỉ ngày càng khó hơn.
Đối với nghiên cứu và ứng dụng thực tế phát hiện AIGC-V trong tương lai, bài tổng quan này cung cấp một bản đồ gần hơn với nhu cầu triển khai thực tế, xác định lại nhiệm vụ phát hiện video do AI tạo, đề xuất khung bốn lớp "song quan điểm thị giác - ngôn ngữ", và dựa trên đó hệ thống hóa các phương pháp hiện có, các tiêu chuẩn liên quan và chỉ số đánh giá, đồng thời liên kết các cấp độ này với các thách thức trong triển khai thực tế, các lỗ hổng trong đánh giá hiện tại và các hướng phát triển đang xuất hiện.
Theo khung này, chỉ ra một số yêu cầu then chốt mà việc phát hiện đáng tin cậy cần có, bao gồm ưu tiên bằng chứng, kết luận có thể truy nguyên, và duy trì tính ổn định trong điều kiện đa bộ tạo sinh và cảnh thực.
Và trong tương lai, việc phát hiện video AI đáng tin cậy cũng khó có thể được hoàn thành độc lập bởi một lĩnh vực riêng lẻ nào đó, nó đang trở thành vấn đề giao thoa mà nghiên cứu liên quan đến CV, NLP, hiểu đa phương thức và mô hình thế giới cần cùng đối mặt: CV cung cấp khả năng mô hình hóa bằng chứng không-thời gian và tính mạnh mẽ trong thu thập chứng cứ, NLP cung cấp khả năng phân tách mệnh đề, suy luận, dẫn chứng hóa bằng chứng và giải thích, nghiên cứu đa phương thức và mô hình thế giới thì cung cấp khả năng phù hợp xuyên phương thức mạnh hơn và tiên nghiệm phong phú hơn về vật lý, nguyên nhân và tính nhất quán thời gian.
Chỉ có thực sự kết hợp những khả năng này, việc phát hiện video mới có thể dần vượt qua việc tìm kiếm các dấu vết giả cục bộ, hướng tới một "quan điểm chân thực" nghiêm ngặt hơn: Vấn đề không còn chỉ là video trông có đáng tin không, mà là các thực thể, sự kiện và quá trình động trong đó, có luôn trung thành với các ràng buộc của thế giới thực hay không, để tìm kiếm ranh giới ngày càng mờ đi giữa thế giới ảo và thế giới thực.
Tài liệu tham khảo: https://www.researchgate.net/doi/10.13140/RG.2.2.31713.88168
Bài viết này đến từ tài khoản WeChat công chúng "New Zhiyuan", biên tập: LRST