By Shadow Memo
On social media platforms, this rivalry has been dubbed with various dramatic titles—"The Showdown of the Top Two Open-Source Titans," "DeepSeek and Kimi's Moment of Going All-In," "The Song of Ice and Fire in the AI Race"... People are eager to summarize it all with binary oppositions, as if only an extreme narrative can match this competition destined to be written into the annals of China's AI history.
But beneath this noisy surface, a more pressing question emerges: As DeepSeek breaks through with V4 after 15 months of silence, does Yang Zhilin on the opposite side really have the leisure to enjoy this competition?
If DeepSeek's anxiety is one of "choice anxiety"—whether to remain silent or return to fundraising, whether to focus on closed-source development or embrace the ecosystem—then Yang Zhilin of Moonshot AI faces an anxiety more akin to a tightening encirclement: a "survival anxiety" simultaneously locked in by technological, commercial, and capital forces, leaving him in a dilemma with no easy way out.
This expression of anxiety is not just a personal unease but also a true reflection of a startup's strategic dilemma in a trillion-dollar market, caught in the "wanting both" predicament.
This is not an article meant to disparage Kimi. On the contrary, perhaps it is precisely because Kimi stands high enough and bears enough weight that Yang Zhilin's anxiety holds universal significance—it reflects the collective困境 of all independent large-model startups in China.
Two Founders, Two Types of "Ceilings"
To understand Yang Zhilin's anxiety, one must not look solely at Moonshot AI but place it within a comparative framework with DeepSeek. These two companies are not just technological competitors but also form a fascinating mirror image in terms of narrative.
In early 2023, when investors discussed "who is China's most technically idealistic person," Yang Zhilin's name accounted for half the responses. This Tsinghua University computer science undergraduate and top graduate of Carnegie Mellon University's Language Technologies Institute, as first author or co-first author, contributed to Transformer-XL and XLNet, which remain seminal works in the history of pre-trained models.
In March 2026, Yang Zhilin stood on the main stage of NVIDIA's GTC conference, seated alongside leaders from OpenAI and DeepMind. He was the only representative from an independent large-model startup; the others were all project leads from major tech giants. When this photo circulated back in China, Moonshot AI's valuation had just quadrupled in three months, making it a decacorn.
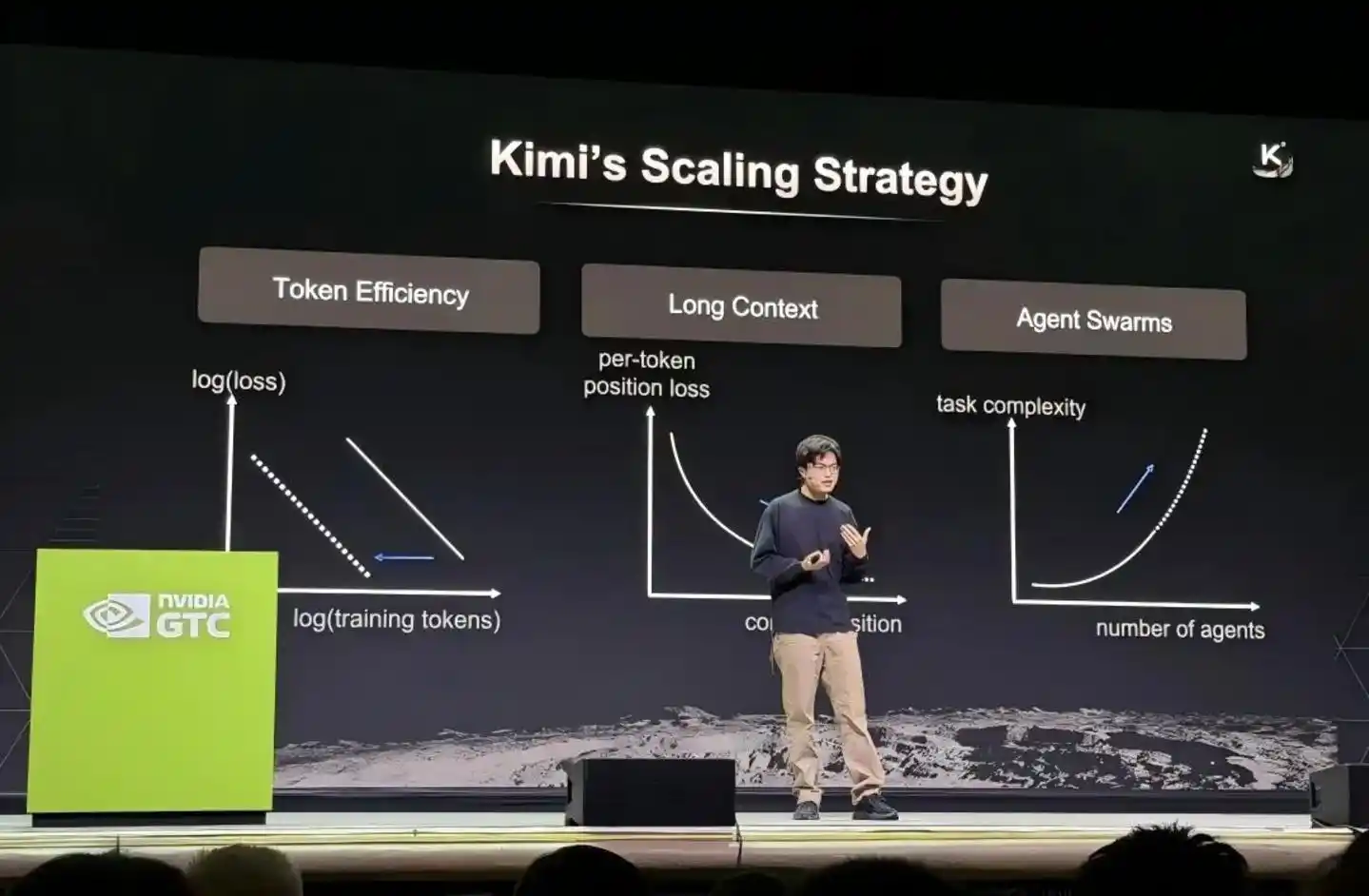
Yang Zhilin Speaking at GTC Conference
This is Yang Zhilin's halo, but the other side of the halo is the "ceiling."
DeepSeek's founder, Liang Wenfeng, took a截然不同的 path. In January 2025, the release of DeepSeek R1 was dubbed the "Sputnik moment" of AI by Wall Street—NVIDIA's market cap evaporated nearly $600 billion in a single day, and Silicon Valley engineers pored over the technical report through the night.
But then, after a long 15 months of silence, DeepSeek almost disappeared from the mainstream spotlight. Until April 24, 2026, when the V4 preview was launched, with 1.6 trillion parameters, a million-token context window, and a price as low as $0.28 per million output tokens, reshaping the entire competitive landscape of open-source models.
Liang Wenfeng traded 15 months of seclusion for a more powerful technological narrative. He has said on rare public occasions: "We don't build products for storytelling; we build the technology itself."
And Yang Zhilin? He is forming a typical entrepreneurial halo, but it is precisely this halo that subjects him to a unique pressure. This pressure is not the anxiety of being overlooked but the anxiety of being overly anticipated yet unable to fully deliver.
The Aesthetics of Competition and Cooperation Through Mutual Learning
Technologically, Moonshot AI and DeepSeek may be the most interesting pair of competitors and collaborators in the global large-model field.
In the week of April 2026, the two companies staged a near-perfect "air handshake." On Monday, Kimi released K2.6; on Friday, DeepSeek V4 went live. But beneath this surface competition lies a more fundamental fact: these two companies are jointly defining the technological boundaries of domestic large models by sharing open-source achievements.
Kimi's K2 model, launched in July 2025, was the first to大规模 validate the second-order optimizer Muon at the underlying architecture level, while also adopting the MLA (Multi-Head Latent Attention) mechanism pioneered by DeepSeek. By April 2026, DeepSeek V4 also followed suit by adopting the Muon optimizer, replacing the Adam optimizer that had been used for the past decade. One评论 aptly summarized this phenomenon: "You use my architecture, I use your optimizer."
This mutual borrowing is no coincidence. Open source is precisely the key lever for Chinese AI companies to accelerate their catch-up with global leaders. Currently, the only two models in China with over a trillion total parameters and publicly released weights are DeepSeek and Kimi.
But their technological focuses have created differentiated分工.
DeepSeek V4's core breakthrough lies in the cost restructuring of the million-token context. It employs a novel hybrid attention mechanism, combining token dimension compression and DSA sparse attention (DeepSeek Sparse Attention), reducing single-token inference computation to 27% of V3.2 and KV Cache to 10%.
This is not just an improvement in technical metrics; it is the infrastructure that turns the million-token context from a tech demo into a "standard feature of all official services." Simultaneously, V4 received specialized optimization for Agent capabilities and built its own sandbox platform called DSec, capable of concurrently managing hundreds of thousands of sandbox instances in a single cluster to support Agent reinforcement learning training and evaluation.
Kimi K2.6, on the other hand, leans more towards long-range encoding and Agent clusters. It scored 68.2 in internal evaluations on the Kimi Code Bench, a roughly 20% improvement over K2.5's 57.4, and can support up to 300 sub-agents working in parallel over 4000协作 steps. K2.6 can run autonomously for up to five days, independently completing end-to-end delivery of multiple outputs—from documents to web pages, PPTs, and spreadsheets—in a single run.
These two technological approaches are like simultaneously pouring the foundation and laying the bricks for a skyscraper—DeepSeek thinks about how to make the foundation wider and more stable (democratizing the million-token context), while Kimi thinks about how to make the building taller and smarter (fundamentally evolving multi-agent collaboration). Each has its strengths, but each also has its limits.
It is worth noting that this technological two-pronged approach恰恰 constitutes the most valuable asset allocation for domestic large models.
Burning Money for User Acquisition or Technological Self-Sufficiency?
If the mutual technological borrowing establishes a certain "heroes appreciate heroes"默契, then the比拼 of commercialization tears apart all romantic illusions.
Kimi has the brightest star product halo among independent large-model companies, but this itself is also its biggest burden. According to industry insiders, Moonshot AI's funding and talent are first-tier domestically, but its core product is only the Kimi assistant, leading to extremely limited revenue sources. The vast majority of users are free, paid subscription conversion rates are low, and API call volumes are far lower than those of companies focused on the B2B sector.
In 2025, Moonshot AI made a major strategic adjustment—it withdrew from the arms race of burning money for user acquisition. Its advertising expenses plummeted from 700 million yuan the previous year to less than 100,000 yuan, shifting focus instead to base model iteration and Agent product development, releasing three major versions—K2, K2 Thinking, and K2.5—within six months. This "cutting the wrist to save the arm" shift was essentially a direct response to the commercialization困境. When user growth fails to translate into revenue, the only option is to prove one's true value through technological self-sufficiency.
But "technological self-sufficiency" is not achieved overnight. Yang Zhilin admitted in an internal letter in November 2025 that Kimi's overseas API revenue grew fourfold, and the month-on-month growth rate of paid users at home and abroad exceeded 170%—but even so, from a valuation perspective, Moonshot AI still faces immense尴尬: once investors feel it cannot quickly become a revenue-generating machine, whether the secondary market will accept it becomes a huge unknown.
More棘手的是, large-model companies face降维打击 from giants in the C端 market. Industry insiders reveal that Moonshot AI became entangled in competition with major tech firms, ultimately losing domestically to ByteDance's Doubao, while also missing the window for overseas market expansion.
The overseas market is still relatively open for competition, with more than just GPT and Gemini. If a large number of global customers are willing to pay for domestic large models, there remains a huge market opportunity. However, effective出海 is currently concentrated in the AI video领域, where Moonshot AI has no突出的 advantage.
DeepSeek, while theoretically facing similar issues, finds itself in a截然不同的 situation. Liang Wenfeng has historically maintained a restrained stance towards external funding, even seen by some as a deliberate art of distancing from the capital markets. But this passive "scarcity" has反而 won it bargaining power.
Reports suggest that DeepSeek is currently seeking funding, with its target valuation adjusted upwards from an initial至少 $10 billion to over $20 billion, surpassing Moonshot's $18 billion valuation.
The valuation scales are quietly shifting—in 2023, Yang Zhilin was seen as "the most worth investing in"; in less than three years, the priority of capital's attention has significantly moved.
Mirrors in the International Game
Looking further afield, the entire story of DeepSeek and Kimi is nested within a larger coordinate system—Sino-US AI competition and the ecological game between open source and closed source in China.
In April 2026, Stanford HAI's "AI Index Report 2026" highlighted one set of numbers in almost every Chinese media summary: the Elo rating gap between China's top models and the US's top models was only 2.7%. This means the performance gap between Chinese and US AI models has almost vanished, and Chinese large models have caught up with the strongest US products in multiple dimensions.
In this process of catching up, both DeepSeek and Kimi played key roles. NVIDIA, the world's most valuable chip company, chose models from DeepSeek and Kimi to demonstrate the performance of its next-generation chips. Open-source models represented by Kimi K2.5 have become the "benchmark" for global chip manufacturers to test hardware performance—new chips must be evaluated for performance improvements using models like Kimi.
Looking further, DeepSeek also has a story about "ecological autonomy." DeepSeek V4 broke the long-term reliance on NVIDIA chips, fully opting for Huawei's latest Ascend series chips as its core computing power base. Regarding this, NVIDIA CEO Jensen Huang stated in an interview that DeepSeek's new model developed on the Huawei platform "would be a bad outcome for the US."
Thus, China's AI industry is forming two intertwined main threads: one is Kimi's "technology出海 path"—influencing the global research community through open-source models; the other is DeepSeek's "computing autonomy path"—promoting chip substitution and the maturation of the domestic computing ecosystem. The two殊途同归, but the driving forces behind them are different.
Founders' Narrative Systems
In terms of macro-narratives from the founders, Yang Zhilin and Liang Wenfeng's styles form an interesting contrast.
Yang Zhilin has been vocal throughout 2026, almost每一次 becoming an industry focus.
At the NVIDIA GTC conference, he systematically disclosed Kimi's technology roadmap, summarizing its scaling strategy with three keywords: Token efficiency, long context, and Agent clusters. He emphasized that to continuously push the upper limits of large-model intelligence, it is necessary to重构 foundational elements like optimizers, attention mechanisms, and residual connections.
At the Zhongguancun Forum, he bet on two more macro propositions: "open source" and "AI autonomous research." He proposed that open-source models are becoming the new "standard" for the global AI industry and offered a highly controversial judgment—"Ultimately, if model capabilities reach the same level, open source will be the absolute winner." He also divided AI R&D into three stages: the natural data and manual annotation stage (2023-2024), the人工精选 verifiable tasks stage (2025), and the AI-led research stage (starting 2026).
In a year-end all-hands letter in 2025, he also clarified the goals for 2026: focus on Agents in product and commercialization, not treating absolute user numbers as the sole target, continuously pursuing the upper limit of intelligence, creating greater productivity value, and achieving orders of magnitude growth in revenue scale.
Liang Wenfeng's public expressions are much scarcer. But every time he speaks, it carries weight.
In last year's追问 about the Sino-US AI gap, he坦言: "On the surface, China's AI may only be one or two years behind the US technologically, but the real gap is between originality and imitation. If this gap doesn't change, our country will永远 only be a chaser, not a disruptor..." In another discussion about AI memory, he suggested that the moment when in-context learning and memory become reliable might be a core theme of 2026.
The difference behind this恰恰 reveals: Liang Wenfeng can choose to "disappear" in exchange for deeper zero-to-one innovation, while Yang Zhilin, as the helm of an independent startup, sees every strategic turn and every public statement become signals digested by the capital market.
Why Yang Zhilin Has to Be Anxious
"Anxiety" is not just a metaphysical issue. In the tangible battlefield of capital, Yang Zhilin's situation is becoming increasingly微妙.
Looking at the data, Moonshot AI's fundraising trajectory is impressive enough—from a $300 million valuation in the天使 round in June 2023, to $4.3 billion (Series C) in early 2026, then to $10 billion in February, and further climbing to $18 billion three months later in March. The涨幅 is astonishing, with the valuation approaching the $20 billion level.
But the other side of the coin is the巨大不确定性 of how well the high valuation from the primary market will be accepted by the secondary market. Industry insiders indicate that late last year, anxiety permeated Moonshot internally—faced with Zhipu and MiniMax listing on the Hong Kong stock market in quick succession, department employees难免 felt demoralized. Many felt the window of opportunity for large models was short, and the listing opportunity was fleeting.
Yang Zhilin also displayed a坦然 attitude towards not rushing an IPO internally at the end of 2025, but just three months later, market sentiment did a 180-degree turn—Moonshot AI was subsequently曝出 with rumors of "considering a Hong Kong IPO."
The转变 was so fast that the answer almost can only be one possibility: capital is not giving enough time to "wait."
More critically, an IPO is not simply a "cash-out exit"; it意味着 more constraints, more quarterly earnings interrogations, and having to account for performance to shareholders every quarter. And Kimi's current monetization model is still in a difficult climbing phase. Looking at the revenue structure, Moonshot's C端 annual revenue is estimated at around 200 million yuan. API revenue, while growing, appears杯水车薪 against the high $18 billion valuation. Even though K2.5 generated more revenue in less than 20 days after release than the entire previous year, it is still insufficient to put it on a healthy profitability path.
If Moonshot AI is compared to a company building a skyscraper—the foundation is touted as the strongest in大肆宣传, but the building itself is极缺 tenants. Going public is like showing the showroom to the investment market, but there are only零星 visitors in the lobby, no "tenants" truly willing to pay long-term. Then, how long will the capital market's patience last?
Although the two companies follow different paths, from an investor's perspective, DeepSeek's valuation narrative has already begun to constrain Moonshot AI. While Moonshot AI is seen in some scenarios as China's most technologically competitive independent model vendor, capital is starting to look for a reference point—DeepSeek R1's explosive effect showed another logic: a perfect闭环 (breakthrough model → global influence → ecosystem吸引力 → fundraising return) can be achieved by a relatively low-profile company.
Reports suggest that DeepSeek is currently using part of Moonshot's valuation as a benchmark, but its target valuation has been adjusted to over $20 billion, exceeding Moonshot's $18 billion. This itself illustrates a phenomenon: the capital market is willing to offer a higher premium for DeepSeek, perhaps because the latter is closer to the "zero-to-one disruptor" narrative.
The Chinese large-model market in 2026 is no longer an era dominated solely by Kimi's narrative. In a sense, DeepSeek has become Moonshot AI's natural spiritual opponent in terms of fundraising and valuation narrative—even though the two companies' business models and strategic directions are not identical.
And a silent "valuation earthquake" will not be eliminated simply because the two have their respective strengths fundamentally. As Kimi prepares for an IPO and DeepSeek also plans fundraising, this ranking is more likely to be publicly discussed. If there is any anxiety Yang Zhilin cannot avoid, it is how to establish his own irreplaceable value anchor after losing the "unique" label in this race.
Conclusion
Despite using such length to analyze Yang Zhilin's anxiety—DeepSeek's V4 catch-up, commercial monetization pressure, the逼迫 of the IPO window—at the end of the article, one must firmly state an attitude: competition is never a bad thing. On the contrary, under the current international AI competition landscape, what China needs most is the continuous "mutual chase" between DeepSeek and Kimi.
Looking back over the past few years, from Kimi starting with long text, to both rushing towards underlying architectural innovation in the last two years, the two have now brought China's open-source models to the forefront of the world. According to OpenRouter's 2025 survey data, about one-third of global AI model usage comes from China. OpenRouter's data indicates that this share was unthinkable just two years ago, and DeepSeek is in a leading position within this share.
China's large-model industry is experiencing an unprecedented "multipolar格局." Some companies choose closed-source深耕, others choose open-source collaboration; some focus on C端 super apps, others on B端 tool development; some develop cluster intelligence through self-developed Agent frameworks, others see memory and context as the core battlefield for the next three years.
An expert once said: In the next five years, open-source models may account for 80%, with closed-source models around 20%—China is globally leading in open-source models. Furthermore, industry reports point out that independent Chinese large-model vendors,凭借 decision-making flexibility, are expected to form a layered competitive and complementary共生格局 with internet giants. Giants dominate general base models and C端 scenarios with computing power, data, and ecosystems, while independent vendors focus on vertical technological breakthroughs and open-source innovation.
Now, the representativeness of DeepSeek and Kimi has transcended the domestic范畴—NVIDIA uses them to test next-generation chips, the global OpenClaw community voted to set Kimi K2.5 as its official main model, and top closed-source products are also being奋起直追 in performance evaluations by both. However, the key to the future is: relying solely on two companies running at the forefront of China's AI wave is still not enough. For domestic large models to continuously narrow the gap with international top models, more excellent model producers need to emerge, making the performance of base models more diverse.
From a broader perspective, the Elo rating gap between the top models of China and the US is only 2.7%. Such a tiny gap means the window of opportunity for any Chinese model company to率先 reach the next performance高地 is wide open. The history of Chinese large models is actually written精彩 precisely because of competitive diversification—the "hundred-model battle" is not a derogatory term but a messenger of industry maturation.
In this sense, Yang Zhilin's anxiety is perhaps a necessary step for Moonshot AI's future maturity. But it should not be a reason for the public to唱衰 Kimi. On the contrary, we should pay tribute to the technical spirit of these two founders, who seek no私利 and charge forward一心—Liang Wenfeng is如此, and Yang Zhilin is亦如是.
April 2026 is coming to an end. Returning to the Zhongguancun Forum from the Silicon Valley GTC conference, Yang Zhilin perhaps already has no time to spare for the endless口水战外界 about "whether DeepSeek or Kimi is stronger."
Because he knows很清楚 that what ultimately determines which blade of grass率先 welcomes the sunlight is not whether the storm arrives, but how deep and widely the roots are planted.
In this暗夜并肩赛跑 of domestic large models, Yang Zhilin has blazed a path of practical tempering from academic elite to corporate leader. A future with funding to raise, talent to utilize, products to iterate, and Agents to envision—Kimi is not far from it now. And moving from the "dark moon" to the "moon chasing the light" might only require taking the first step after traversing a dark tunnel filled with anxiety and质疑.
The light at the end of the tunnel comes from DeepSeeks, from Kimis, and also from more latecomers and followers among本土 large models.





