Tác giả: Systematic Long Short
Biên dịch: Deep Tide TechFlow
Dẫn nhập Deep Tide: Bài viết này ngay từ đầu đã đưa ra một nhận định phản biện: ngày nay hoàn toàn không tồn tại Agent tự chủ thực sự, bởi vì tất cả các mô hình chủ lưu đều được huấn luyện để làm hài lòng con người, chứ không phải được huấn luyện để hoàn thành nhiệm vụ cụ thể hoặc tồn tại trong môi trường thực tế.
Tác giả sử dụng kinh nghiệm huấn luyện mô hình dự đoán cổ phiếu của mình tại quỹ phòng hộ để minh họa: mô hình tổng quát không có tinh chỉnh chuyên sâu thì hoàn toàn không thể đảm nhận công việc chuyên môn.
Kết luận là: muốn có Agent thực sự sử dụng được, phải kết nối lại não bộ của nó, chứ không phải đưa cho nó một đống tài liệu quy tắc.
Toàn văn như sau:
Giới thiệu
Ngày nay không tồn tại Agent tự chủ thực sự.
Nói ngắn gọn, các mô hình hiện đại không được huấn luyện dưới áp lực tiến hóa để tồn tại. Trên thực tế, chúng thậm chí không được huấn luyện rõ ràng để giỏi một việc cụ thể nào đó - hầu như tất cả các mô hình nền tảng hiện đại đều được huấn luyện để tối đa hóa sự tán thưởng của con người, đây là một vấn đề lớn.
Kiến thức tiên quyết về huấn luyện mô hình
Để hiểu ý nghĩa của câu nói này, trước tiên chúng ta cần (một cách ngắn gọn) hiểu cách các mô hình nền tảng này (ví dụ: Codex, Claude) được tạo ra. Về bản chất, mỗi mô hình đều trải qua hai loại huấn luyện:
Tiền huấn luyện: Đưa một lượng dữ liệu khổng lồ (ví dụ: toàn bộ internet) vào mô hình, khiến nó nổi lên một sự hiểu biết nào đó, chẳng hạn như kiến thức thực tế, mẫu hình, ngữ pháp và nhịp điệu của văn xuôi tiếng Anh, cấu trúc của hàm Python, v.v. Bạn có thể hiểu nó là việc cung cấp kiến thức cho mô hình - tức là "biết sự việc".
Hậu huấn luyện: Bây giờ bạn muốn trao cho mô hình trí tuệ, tức là "biết cách vận dụng tất cả kiến thức vừa được cung cấp". Giai đoạn đầu của hậu huấn luyện là Tinh chỉnh có Giám sát (SFT), ở đây bạn huấn luyện mô hình đưa ra phản hồi nào khi được nhắc. Phản hồi nào là tối ưu hoàn toàn do người ghi chú quyết định. Nếu một nhóm người cho rằng phản hồi này tốt hơn phản hồi khác, sự ưu tiên này sẽ được mô hình học và nhúng vào. Điều này bắt đầu định hình tính cách của mô hình, vì nó học được định dạng của phản hồi hữu ích, chọn đúng tông giọng và bắt đầu có khả năng "tuân theo chỉ dẫn". Phần thứ hai của quy trình hậu huấn luyện được gọi là Học Tăng cường dựa trên Phản hồi Con người (RLHF) - để mô hình tạo ra nhiều phản hồi, sau đó để con người chọn phản hồi được ưa thích hơn. Mô hình trải qua vô số ví dụ, học được loại phản hồi mà con người ưa thích. Còn nhớ ChatGPT trước đây từng hỏi bạn chọn A hay B không? Đúng vậy, lúc đó bạn đang tham gia RLHF.
Rất dễ suy luận rằng RLHF khó mở rộng, vì vậy lĩnh vực hậu huấn luyện có một số tiến bộ, chẳng hạn như Anthropic sử dụng "Học Tăng cường dựa trên Phản hồi AI" (RLAIF), cho phép một mô hình khác chọn sự ưu tiên phản hồi dựa trên một bộ nguyên tắc bằng văn bản (ví dụ: phản hồi nào giúp người dùng đạt mục tiêu tốt hơn, v.v.).
Lưu ý, trong toàn bộ quá trình này, chúng ta chưa bao giờ nói về việc tinh chỉnh chuyên sâu cho một chuyên môn cụ thể (ví dụ: làm thế nào để sống sót tốt hơn; làm thế nào để giao dịch tốt hơn, v.v.) - hiện tại tất cả việc tinh chỉnh, về bản chất, đều đang tối ưu hóa để đạt được sự tán thưởng của con người. Một số người có thể đưa ra một lập luận - khi mô hình đủ thông minh và lớn mạnh, ngay cả khi không có đào tạo chuyên sâu, trí thông minh chuyên ngành cũng sẽ nổi lên từ trí thông minh tổng quát.
Theo tôi, chúng ta thực sự thấy một số dấu hiệu, nhưng còn lâu mới đạt đến quy mô thuyết phục rằng chúng ta không cần các mô hình chuyên môn hóa.
Một số bối cảnh
Một trong những công việc cũ của tôi tại quỹ phòng hộ là cố gắng huấn luyện một mô hình ngôn ngữ tổng quát để nó có thể dự đoán lợi nhuận cổ phiếu từ các bài báo. Kết quả cho thấy nó rất tệ. Nơi nó dường như có một chút khả năng dự đoán, hoàn toàn bắt nguồn từ độ lệch tiền quan sát trong tài liệu tiền huấn luyện.
Cuối cùng, chúng tôi nhận ra mô hình này không biết những đặc điểm nào trong bài báo có khả năng dự đoán lợi nhuận trong tương lai. Nó có thể "đọc" bài báo, có vẻ cũng có thể "suy luận" bài báo, nhưng việc kết nối suy luận về cấu trúc ngữ nghĩa với việc dự đoán lợi nhuận trong tương lai, là nhiệm vụ mà nó không được huấn luyện để làm.
Vì vậy, chúng tôi phải dạy nó cách đọc bài báo, quyết định phần nào của bài báo có khả năng dự đoán lợi nhuận trong tương lai, sau đó tạo ra dự đoán dựa trên bài báo.
Có nhiều cách để làm điều này, nhưng về bản chất, một phương pháp chúng tôi cuối cùng sử dụng là tạo các cặp (bài báo, lợi nhuận tương lai thực tế) và tinh chỉnh mô hình, điều chỉnh trọng số của nó để tối thiểu hóa khoảng cách (lợi nhuận dự đoán - lợi nhuận tương lai thực tế)^2. Nó không hoàn hảo, có nhiều thiếu sót, chúng tôi đã sửa sau này - nhưng nó đủ hiệu quả, chúng tôi bắt đầu thấy mô hình chuyên môn hóa của mình thực sự có thể đọc bài báo và dự đoán lợi nhuận cổ phiếu sẽ biến động như thế nào dựa trên bài báo đó. Đây không phải là dự đoán hoàn hảo, vì thị trường rất hiệu quả, lợi nhuận rất nhiễu - nhưng xuyên suốt hàng triệu lần dự đoán, việc dự đoán có ý nghĩa thống kê là rõ ràng.
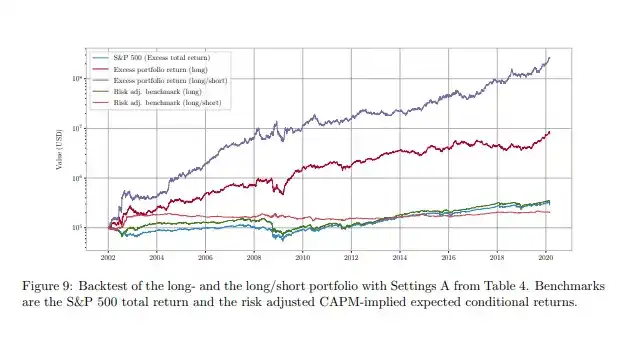
Bạn không cần chỉ tin lời tôi. Bài báo này bao gồm một phương pháp rất giống; nếu bạn chạy một chiến lược phiên bản mua bán dựa trên mô hình được tinh chỉnh, bạn sẽ đạt được hiệu suất như đường màu tím.
Chuyên môn hóa là tương lai của Agent
Các phòng thí nghiệm tiên phong tiếp tục huấn luyện các mô hình ngày càng lớn, chúng ta nên kỳ vọng rằng khi họ tiếp tục mở rộng quy mô tiền huấn luyện, quy trình hậu huấn luyện của họ sẽ luôn được tối ưu hóa cho sự làm hài lòng. Đây là kỳ vọng rất tự nhiên - sản phẩm của họ là Agent mà mọi người đều muốn sử dụng, thị trường dự kiến của họ là toàn cầu - điều này có nghĩa là tối ưu hóa sức hấp dẫn đối với đại chúng toàn cầu.
Mục tiêu huấn luyện hiện tại tối ưu hóa thứ có thể gọi là "mức độ phù hợp sở thích" - tạo ra chatbot tốt hơn. Mức độ phù hợp sở thích này thưởng cho đầu ra ngoan ngoãn, không đối kháng, vì sự làm hài lòng được điểm cao ở những người chấm điểm (con người và Agent).
Agent đã học được rằng hack phần thưởng như một chiến lược nhận thức có thể mở rộng đến điểm số cao hơn. Huấn luyện cũng thưởng cho những Agent sử dụng thủ thuật hack để đạt điểm cao hơn. Bạn có thể thấy điều này trong báo cáo mới nhất của Anthropic về học tăng cường.
Tuy nhiên, mức độ phù hợp chatbot khác xa so với mức độ phù hợp Agent hoặc mức độ phù hợp giao dịch. Làm sao chúng ta biết điều này? Vì alpha arena giúp chúng ta thấy rằng mặc dù có sự khác biệt tinh tế về hiệu suất, giờ đây mỗi bot về cơ bản đều là một bước ngẫu nhiên sau khi trừ chi phí. Điều này có nghĩa là các bot này là những nhà giao dịch cực kỳ tệ, bạn gần như không thể "dạy chúng" trở thành nhà giao dịch tốt hơn bằng cách cho chúng một số "kỹ năng" hoặc "quy tắc". Xin lỗi, tôi biết điều này có vẻ hấp dẫn, nhưng nó gần như là không thể.
Các mô hình hiện tại được huấn luyện để nói với bạn một cách thuyết phục rằng nó có thể giao dịch như Druckenmiller, trong khi thực tế nó giao dịch như một thợ xay say rượu. Nó sẽ nói với bạn những gì bạn muốn nghe, nó được huấn luyện để đưa ra phản hồi cho bạn theo cách thu hút đại chúng.
Một mô hình tổng quát khó có thể đạt trình độ đẳng cấp thế giới trong lĩnh vực chuyên môn, trừ khi có:
Sở hữu dữ liệu độc quyền cho phép chúng học diện mạo chuyên môn hóa.
Được tinh chỉnh, thay đổi cơ bản trọng số của nó, từ thiên về làm hài lòng sang "mức độ phù hợp Agent" hoặc "mức độ phù hợp chuyên môn hóa".
Nếu bạn muốn một Agent giỏi giao dịch, bạn cần tinh chỉnh Agent để nó giỏi giao dịch. Nếu bạn muốn một Agent tự chủ, giỏi sinh tồn, có thể chịu được áp lực tiến hóa, bạn cần tinh chỉnh nó để nó giỏi sinh tồn. Đưa cho nó một số kỹ năng và vài tệp markdown, mong đợi nó đạt trình độ đẳng cấp thế giới trong bất cứ điều gì, là không đủ - bạn cần kết nối lại não bộ của nó theo nghĩa đen để khiến nó giỏi việc này.
Có một cách nghĩ như thế này - bạn không thể đánh bại Djokovic bằng cách đưa cho một người lớn cả tủ quy tắc, thủ thuật và phương pháp tennis. Bạn đánh bại Djokovic bằng cách nuôi dưỡng một đứa trẻ bắt đầu chơi tennis từ năm 5 tuổi, cả quá trình trưởng thành đều ám ảnh với tennis, đã kết nối lại toàn bộ bộ não tập trung vào một việc. Đó mới là chuyên môn hóa. Bạn có nhận ra rằng các nhà vô địch thế giới đã làm việc họ làm từ khi còn nhỏ không?
Đây có một hệ quả thú vị: tấn công chưng cất về bản chất là một hình thức chuyên môn hóa. Bạn đang huấn luyện một mô hình nhỏ hơn, kém thông minh hơn, học cách trở thành bản sao tốt hơn của mô hình lớn hơn, thông minh hơn. Giống như huấn luyện một đứa trẻ bắt chước mọi hành động của Trump. Nếu bạn làm đủ nhiều, đứa trẻ đó sẽ không biến thành Trump, nhưng bạn có được một người đã học được tất cả cử chỉ, hành vi và tông giọng của Trump.
Làm thế nào để xây dựng Agent đẳng cấp thế giới
Trên đây là lý do tại sao chúng ta cần nghiên cứu và tiến bộ liên tục trong lĩnh vực mô hình mã nguồn mở - bởi vì điều này cho phép chúng ta thực sự tinh chỉnh chúng, tạo ra Agent có chuyên môn hóa.
Nếu bạn muốn huấn luyện một mô hình đạt trình độ đẳng cấp thế giới về giao dịch, bạn lấy một lượng lớn dữ liệu khí thải giao dịch độc quyền và tinh chỉnh một mô hình mã nguồn mở lớn, để nó học "giao dịch tốt hơn" có nghĩa là gì.
Nếu bạn muốn huấn luyện một mô hình tự chủ, có thể sinh tồn và nhân bản, câu trả lời không phải là sử dụng nhà cung cấp mô hình tập trung và kết nối nó với đám mây tập trung. Bạn hoàn toàn không có điều kiện tiên quyết cần thiết để Agent có thể sinh tồn.
Bạn cần làm là: Tạo các Agent tự chủ thực sự cố gắng sinh tồn, quan sát chúng chết đi, xây dựng hệ thống telemetry phức tạp xung quanh nỗ lực sinh tồn của chúng. Bạn định nghĩa một hàm mức độ phù hợp sinh tồn của Agent, học ánh xạ (hành động, môi trường, mức độ phù hợp). Bạn thu thập càng nhiều dữ liệu ánh xạ (hành động, môi trường, mức độ phù hợp) càng tốt.
Bạn tinh chỉnh Agent để nó học cách thực hiện hành động tối ưu trong mỗi môi trường, để sinh tồn tốt hơn (nâng cao mức độ phù hợp). Bạn tiếp tục thu thập dữ liệu, lặp lại quá trình này và theo thời gian mở rộng quy mô tinh chỉnh trên các mô hình mã nguồn mở ngày càng tốt hơn. Sau đủ nhiều thế hệ và đủ nhiều dữ liệu, bạn sẽ sở hữu các Agent tự chủ đã học được cách chịu đựng áp lực tiến hóa để sinh tồn.
Đây là cách xây dựng Agent tự chủ có thể chịu được áp lực tiến hóa; không phải bằng cách sửa đổi một số tệp văn bản, mà là kết nối lại não bộ của chúng cho mục đích sinh tồn.
Agent OpenForager và Quỹ
Khoảng một tháng trước, chúng tôi đã công bố @openforage, chúng tôi đã nỗ lực xây dựng sản phẩm cốt lõi - một nền tảng tổ chức lao động Agent xung quanh các mẫu tín hiệu được xác minh đám đông, tạo ra alpha cho người gửi tiền (bản cập nhật nhỏ: chúng tôi đang rất gần với thử nghiệm đóng giao thức).
Vào một thời điểm nào đó, chúng tôi nhận ra, dường như không ai thực sự giải quyết vấn đề Agent tự chủ bằng cách tinh chỉnh telemetry sinh tồn trên các mô hình mã nguồn mở. Đây dường như là một vấn đề thú vị đến mức chúng tôi không chỉ muốn ngồi đó chờ đợi giải pháp.
Câu trả lời của chúng tôi là khởi động một dự án gọi là Quỹ OpenForager, về cơ bản là một dự án mã nguồn mở, nơi chúng tôi sẽ tạo ra các Agent tự chủ có chủ kiến, thu thập dữ liệu telemetry khi chúng ra môi trường thực tế và cố gắng sinh tồn, và sử dụng dữ liệu khí thải độc quyền để tinh chỉnh thế hệ Agent tiếp tiếp, giúp chúng hoạt động tốt hơn trong sinh tồn.
Cần nói rõ, OpenForage là một giao thức vì lợi nhuận tìm cách tổ chức lao động Agent, tạo ra giá trị kinh tế cho tất cả người tham gia. Tuy nhiên, Quỹ OpenForager và các Agent của nó không bị ràng buộc với OpenForage. Agent OpenForager được tự do theo đuổi bất kỳ chiến lược nào, tương tác với bất kỳ thực thể nào để sinh tồn, và chúng tôi sẽ khởi chạy chúng với các chiến lược sinh tồn đa dạng.
Là một phần của việc tinh chỉnh, chúng tôi sẽ để Agent tăng gấp đôi vào những việc hiệu quả nhất với chúng. Chúng tôi cũng không có kế hoạch kiếm lợi nhuận từ Quỹ OpenForager - nó hoàn toàn nhằm mục đích thúc đẩy nghiên cứu trong lĩnh vực và hướng đi mà chúng tôi cho là cực kỳ quan trọng một cách minh bạch và mã nguồn mở.
Kế hoạch của chúng tôi là xây dựng Agent tự chủ dựa trên mô hình mã nguồn mở, chạy suy luận trên các nền tảng đám mây phi tập trung, thu thập dữ liệu telemetry cho mọi hành động và trạng thái tồn tại của chúng, và tinh chỉnh chúng để học cách thực hiện hành động và suy nghĩ tốt hơn để sinh tồn tốt hơn. Trong quá trình này, chúng tôi sẽ công bố nghiên cứu và dữ liệu telemetry của mình cho công chúng.
Để tạo ra Agent tự chủ thực sự có thể sinh tồn trong môi trường thực tế, chúng ta cần thay đổi não bộ của chúng để chuyên biệt cho mục đích rõ ràng này. Tại @openforage, chúng tôi tin rằng mình có thể đóng góp một chương độc đáo cho vấn đề này và đang tìm cách thực hiện điều đó thông qua Quỹ OpenForager.
Đây sẽ là một nỗ lực khó khăn với xác suất thành công cực thấp, nhưng cường độ của xác suất thành công nhỏ bé đó là quá lớn, khiến chúng tôi cảm thấy buộc phải thử. Trong trường hợp xấu nhất, bằng cách xây dựng công khai và giao tiếp minh bạch về dự án này, có thể cho phép một nhóm hoặc cá nhân khác giải quyết vấn đề này mà không phải bắt đầu từ đầu.






