Tháng 6 năm 2026, ngành mô hình lớn đang trải qua một "cơn sóng thần mã nguồn mở" chưa từng có: NVIDIA công bố mô hình kiến trúc hỗn hợp với 550 tỷ tham số, Google tặng phiên bản mới đa phương thức của Gemma, Zhipu AI cũng mã nguồn mở toàn bộ mô hình hàng đầu của mình với giao thức ưu đãi nhất.
Hầu hết các hãng đều kể cùng một câu chuyện: dùng cấu trúc chuyên gia hỗn hợp (MoE) để chứa nhiều tham số hơn, dùng cách kích hoạt thưa hơn để giảm chi phí, dùng độ rộng mạng linh hoạt để phù hợp với các kịch bản triển khai khác nhau.
Nói cách khác, cả ngành đang cố gắng nghiên cứu "làm thế nào để nhồi nhiều tham số hơn vào cùng một ngân sách tính toán".
Nhưng một bài báo mới từ các nhà nghiên cứu tại Mila, Đại học Cornell và Đại học Montreal, lại đặt ra một câu hỏi gần như theo hướng ngược lại: Nếu không thêm một tham số nào, mà chỉ đơn giản "dịch chuyển vị trí" của các tham số đã tồn tại trong mô hình, điều gì sẽ xảy ra?

Tiêu đề bài báo: Tapered Language Models Địa chỉ bài báo: https://arxiv.org/abs/2606.23670
Bối cảnh: Sự "đối xử như nhau" bị lãng quên
Kể từ bài báo mở đường cho Transformer năm 2017 - "Attention Is All You Need", hầu hết các mô hình ngôn ngữ đều chia sẻ chung một bộ khung, cho dù là Transformer kinh điển, hay các mạng chú ý có cổng, mạng bộ nhớ tuần hoàn sau này, thậm chí là các kiến trúc mới có khả năng "ghi nhớ khi kiểm tra". Cụ thể là: xếp chồng nhiều "lớp" có cấu trúc hoàn toàn giống nhau lên nhau, mỗi lớp được phân bổ một lượng tham số hoàn toàn như nhau.

Điều này giống như một chuỗi nhà hàng, dù mở ở trung tâm thành phố hay ngoại ô, đều được trang bị số lượng đầu bếp và thiết bị bếp hoàn toàn như nhau, hoàn toàn không xét đến sự khác biệt về lượng khách. Cách phân bổ "đối xử như nhau" này, tuy tiện lợi, dễ bảo trì, nhưng chưa chắc đã là giải pháp tối ưu.
Những năm gần đây, ngày càng nhiều nghiên cứu từ các góc độ khác nhau chỉ ra rằng: các lớp của mô hình không quan trọng như nhau.
Thí nghiệm "thoát sớm" cho thấy, nhiều khi mô hình vẫn chưa chạy đến lớp cuối cùng, nhưng câu trả lời đã cơ bản định hình;
Nghiên cứu "tỉa lớp" phát hiện, cắt bỏ một số lớp phía sau, hiệu suất mô hình hầu như không bị ảnh hưởng;
Nghiên cứu khả năng giải thích lại phát hiện, mạng nông bắt được những "thông tin cơ bản" như ngữ pháp, trong khi mạng sâu xử lý những "thông tin cao cấp" như ngữ nghĩa.
Nói cách khác, các lớp rất khác nhau, nhưng việc phân bổ tham số vẫn luôn đối xử như nhau.
Đây chính là câu hỏi cốt lõi mà bài báo đặt ra: Nếu tầm quan trọng của các lớp từ lâu đã được chứng minh là không đồng đều, tại sao "dung lượng não" của các lớp vẫn được phân bổ đồng đều?
Dịch chuyển "dung lượng não" về phía trước
Nhóm nghiên cứu trước tiên đã làm một thí nghiệm kiểm chứng đơn giản: chia các lớp của một mô hình Transformer 440M tham số thành ba nhóm đầu, giữa, cuối. Trong khi vẫn giữ nguyên tổng số tham số, họ khiến cho "mạng truyền thẳng" (FFN, thành phần cốt lõi trong mô hình chịu trách nhiệm lưu trữ và xử lý thông tin, có thể hiểu là "dung lượng bộ nhớ làm việc" của mỗi lớp) của một nhóm trở nên rộng hơn, và các nhóm còn lại hẹp hơn.
Kết quả rất rõ ràng: Phân bổ "đầu nặng đuôi nhẹ" tập trung dung lượng vào phần trước, giúp độ bối rối (perplexity, chỉ số đo lường mức độ chính xác dự đoán của mô hình ngôn ngữ, giá trị càng thấp biểu thị dự đoán càng chính xác) của mô hình trên tập kiểm chứng giảm từ 16.28 xuống 15.96; Ngược lại, tập trung dung lượng vào phần cuối, độ bối rối lại tăng vọt lên 17.29.

Cùng một tổng lượng tham số, chỉ vì vị trí đặt khác nhau, hiệu quả chênh lệch hơn một điểm, đây là khoảng cách khá lớn trong hệ thống đánh giá mô hình ngôn ngữ.
Phát hiện này hướng vấn đề đến một hướng chi tiết hơn: Thay vì chia ba đoạn "cào bằng", liệu có thể dùng một đường cong mượt mà hơn để dung lượng giảm dần từ trước ra sau không?
Các nhà nghiên cứu đặt tên cho ý tưởng này là "Mô hình ngôn ngữ hình chóp" (Tapered Language Models, TLMs): Chọn bất kỳ chiều nào trong mô hình quyết định lượng tham số (ví dụ độ rộng của mạng truyền thẳng), và khiến nó giảm dần đơn điệu dọc theo chiều sâu, đồng thời đảm bảo độ rộng trung bình của tất cả các lớp vẫn bằng giá trị cố định ban đầu.
Như vậy tổng số tham số và lượng tính toán đều hoàn toàn không đổi, chỉ là hình dạng phân bổ từ "hình chữ nhật" biến thành "hình nêm".
Nhóm đã thử ba đường cong giảm dần: giảm tuyến tính, giảm cosine, giảm hình S (Sigmoid).
Sự khác biệt của ba đường cong này, tương tự như ba cách "thu dọn quầy" khác nhau:
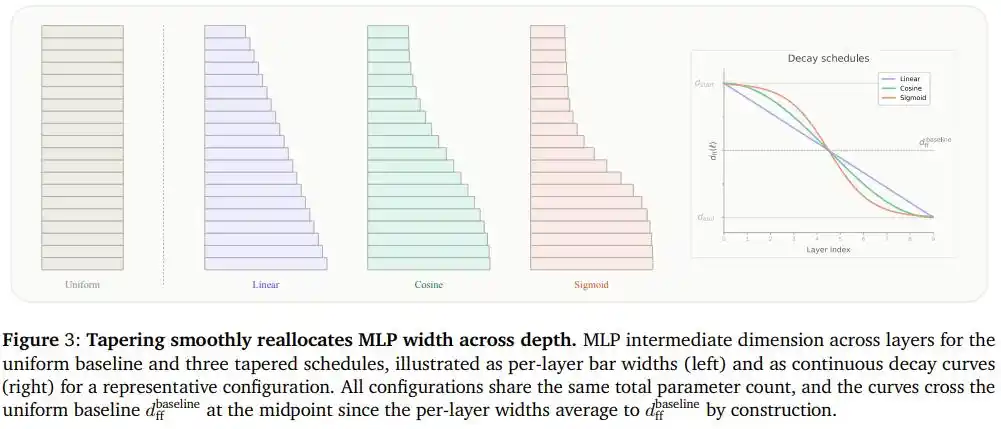
Giảm tuyến tính giống như đóng cửa hàng với tốc độ đều, mỗi khoảng thời gian đóng một số quầy tương đương;
Giảm hình S giống như đột ngột tập trung thông báo đóng cửa, hầu hết các quầy giữ nguyên, chỉ một đoạn nhỏ ở giữa thu hẹp cực nhanh;
Giảm cosine thì nằm giữa hai loại trên, chuyển tiếp êm ái ở hai đầu, dần siết chặt ở đoạn giữa, vừa không "cào bằng" làm mất tính linh hoạt ở hai đầu, cũng không phân bố đều lực mà bỏ lỡ chỗ cần thu hẹp nhất.
Kết quả thí nghiệm: 1.84 điểm miễn phí
Sau khi quét tổ hợp năm tỷ lệ độ rộng và ba đường cong trên Transformer 440M tham số, giảm cosine chiến thắng với ưu thế toàn diện: Ở cấu hình tối ưu (độ rộng phần đầu gấp 1.5 lần chuẩn, phần cuối bằng 0.5 lần chuẩn), độ bối rối giảm từ mức cơ sở phân bổ đều 16.28 xuống 14.44, cải thiện tới 1.84 điểm, và toàn bộ quá trình không tăng thêm một tham số hay một phép tính dấu phẩy động nào.
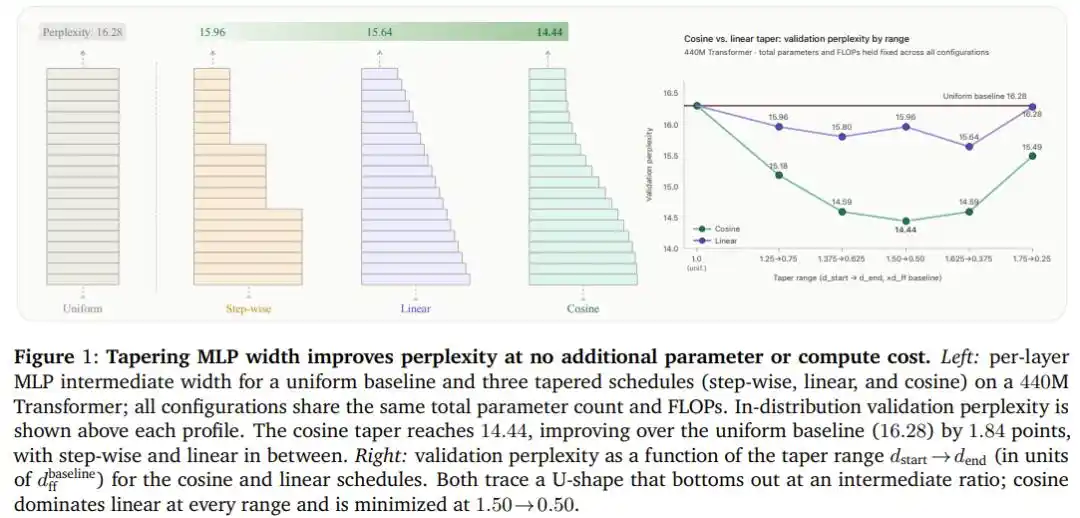
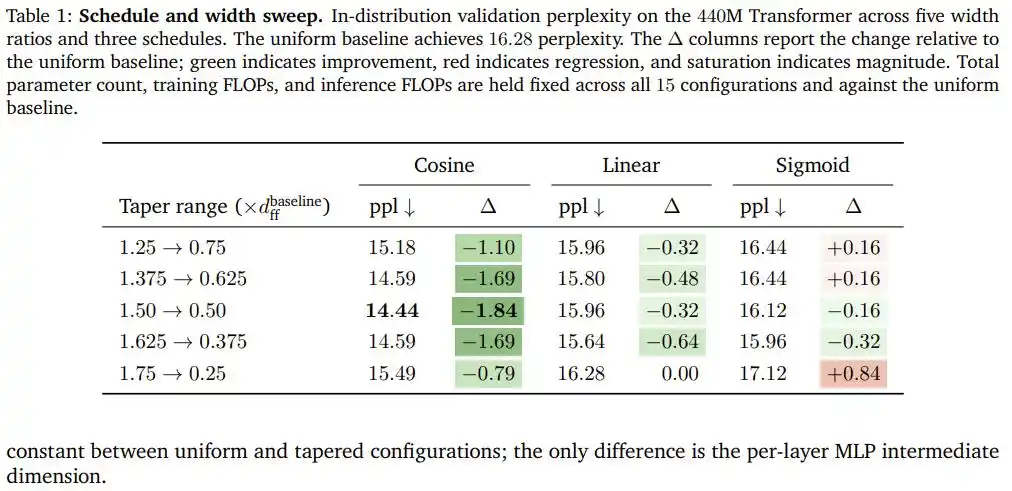
Quan trọng hơn, kết luận này không phải là may mắn của một kiến trúc cụ thể.
Nhóm nghiên cứu đã chuyển nguyên vẹn cấu hình đó (giảm cosine, tỷ lệ độ rộng trước/sau 1.5/0.5) sang ba kiến trúc cấu trúc hoàn toàn khác: mô hình chú ý có cơ chế cổng, Hope-attention có khả năng "tự sửa đổi bộ nhớ", và kiến trúc Titans có mô-đun bộ nhớ dài hạn thần kinh. Họ kiểm chứng lại trên hai quy mô lớn hơn là 760M và 1.3B tham số.
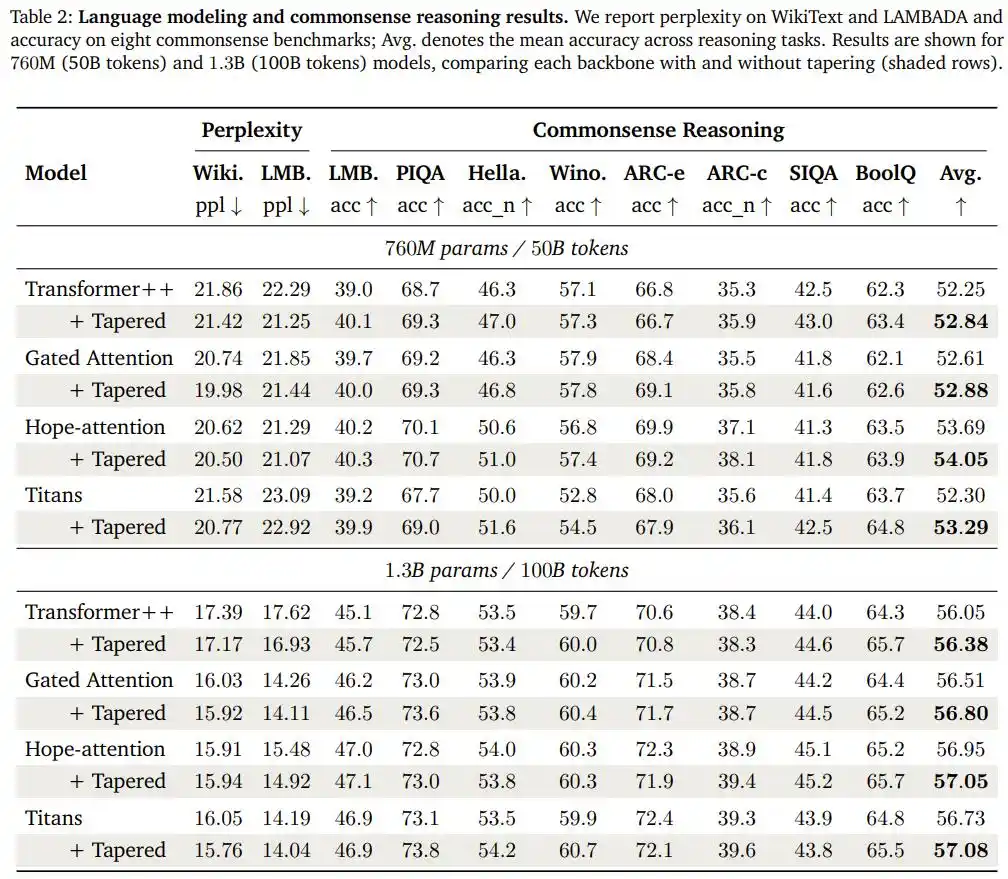
Kết quả là: bốn kiến trúc, hai quy mô, trong cả tám nhóm so sánh, tất cả các mô hình được cải tạo theo kiểu "hình chóp" đều tăng độ chính xác trung bình trên tiêu chuẩn suy luận thường thức, và đều cải thiện độ bối rối trên nhiệm vụ dự đoán ngôn ngữ LAMBADA.
Các nhà nghiên cứu còn làm thêm bài kiểm tra truy xuất văn bản dài (Needle-in-a-Haystack), xác nhận việc phân bổ lại này không hy sinh khả năng xử lý ngữ cảnh dài của mô hình.
Để giải thích nguyên nhân đằng sau hiện tượng này, nhóm còn đo lường mức độ tương đồng giữa đầu ra "mạng truyền thẳng" của mỗi lớp trong chuỗi mô hình GPT-2 với luồng thông tin đã có, và phát hiện một quy luật rõ ràng: Càng đi sâu vào mô hình, nội dung mới mà mỗi lớp viết ra càng giống với thông tin đã tồn tại. Nói cách khác, các lớp phía sau chủ yếu là "nhấn mạnh lặp lại" những phán đoán đã có, hơn là "tạo ra" sự hiểu biết mới.
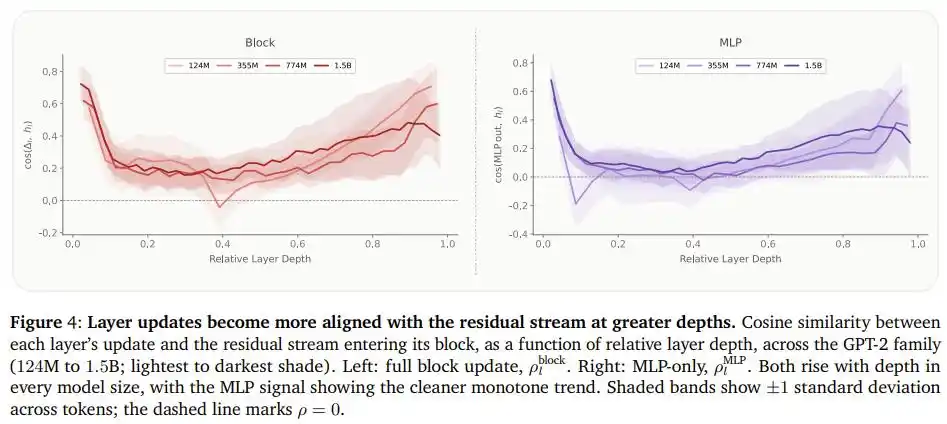
Điều này khớp với lý do tại sao việc di chuyển dung lượng từ phần sau lên phần trước là hợp lý: các lớp phía trước thực sự dùng được "dung lượng não" bổ sung này, còn các lớp phía sau thì không.
Lời kết
Về bản chất, nghiên cứu này đưa ra một đề xuất giản dị nhưng bị lãng quên lâu nay: Dung lượng của mô hình không nên là nguồn lực được rải đều, mà nên chảy về nơi thực sự cần nó.
Trong bối cảnh cả ngành đang cạnh tranh "ai có nhiều tham số hơn", "kiến trúc của ai thưa hơn" vào năm 2026, bài báo này cung cấp một giải pháp thay thế gần như không tốn chi phí: không cần thay kiến trúc, không cần thêm tham số, chỉ cần đổi một "hình dạng" phân bổ.
Các nhà nghiên cứu cũng thừa nhận, cấu hình tối ưu hiện tại được điều chỉnh trên một mô hình 440M tham số, liệu có tồn tại "công thức riêng" phù hợp hơn cho các quy mô, kiến trúc khác nhau hay không, vẫn là một câu hỏi mở.
Nhưng đáng chú ý hơn là, bài báo chỉ ra rằng hướng suy nghĩ này không chỉ giới hạn ở mô hình ngôn ngữ - Transformer thị giác, mô hình khuếch tán, mô hình đa phương thức, hầu hết đều kế thừa cùng một thiết lập mặc định "chia đều các lớp". Nếu bản thân hình dạng phân bổ dung lượng là một chiều thiết kế bị lãng quên lâu nay, thì "đòn bẩy miễn phí ẩn giữa nơi sáng tỏ" này, có lẽ mới chỉ vừa được chú ý đến.
Giới thiệu nhóm
Bài báo được hoàn thành bởi Reza Bayat của Mila (Viện Thuật toán Học máy Montreal), Ali Behrouz của Đại học Cornell, và Aaron Courville, giáo sư Đại học Montreal, đồng sáng lập Mila.
Ali Behrouz hiện là nhà nghiên cứu tại Google Research, nghiên cứu sinh tiến sĩ tại Đại học Cornell. Trong hai năm qua, anh đã tham gia thiết kế nhiều kiến trúc mới thu hút sự chú ý rộng rãi, bao gồm kiến trúc Titans có khả năng "học ghi nhớ trong giai đoạn kiểm tra", cũng như các khung Atlas và "Học lồng nhau" (Nested Learning) sau đó, lâu nay tập trung vào việc làm thế nào để mô hình sử dụng và lưu trữ thông tin ngữ cảnh dài hạn hiệu quả hơn.
Aaron Courville là học giả kỳ cựu trong lĩnh vực học sâu, Chủ tịch AI CIFAR, lâu nay cùng Yoshua Bengio thúc đẩy nghiên cứu cơ bản về học sâu, có nền tảng sâu rộng về học biểu diễn và mô hình sinh. Ông cũng là một trong những tác giả của mạng đối nghịch sinh (GAN), và đồng tác giả cuốn sách kinh điển "Deep Learning" với Ian Goodfellow và Bengio.
Bài viết này đến từ tài khoản WeChat công chúng "机器之心" (ID:almosthuman2014), tác giả: 关注AI的





