KelpDAO 遭遇 2.92 亿美元跨链桥攻击,风险蔓延到 Aave,导致 DeFi 锁仓资产总值在 48 小时内蒸发 130 亿美元。
如果你在货币市场中存入 USDC 仅赚取 5% 收益,真正关键的问题不在于 DeFi 是否存在风险,而在于:你的收益是否匹配所承担的风险。
本文将借助债券定价逻辑拆解这一问题。
两周前,攻击者从 KelpDAO 窃取 2.92 亿美元,被盗的 rsETH 随后被重新存入 Aave V3 用作抵押品,直接造成 Aave 产生约 1.96 亿美元坏账。短短三天内,Aave 锁仓资产总值从 264 亿美元暴跌至 179 亿美元。
而在此之前两周,Solana 生态的 Drift Protocol 因管理员私钥遭到朝鲜黑客社会工程攻击,损失 2.85 亿美元,该攻击策划最早可追溯至 2025 年秋季。
两起重大安全事件间隔仅三周,合计造成 5.77 亿美元损失。受风险挤兑影响,Aave 的 USDC 借贷市场资金利用率连续四天高达 99.87%,存款利率飙升至 12.4%。Circle 首席经济学家 Gordon Liao 甚至发起治理提案,提议将借贷上限扩容四倍,以缓解提款需求。
一个月前,大量用户在 DeFi 货币市场存入稳定币,仅赚取 4%–6% 年化收益。
眼下所有人都需要直面一个核心问题:这类收益率定价本身是否合理?早在 KelpDAO 事件爆发前几周,Santiago R Santos 就在 Blockworks 播客中提出过质疑:在 DeFi 中,我们长期承担高风险,却从未获得足额风险补偿。未来,各类资产的合理风险利差理应被重新定义。
传统金融如何为信用风险定价
所有公司债券的收益率,都由多层风险补偿叠加构成。核心定价公式如下:
· 收益率 = Rf + [PD x LGD] + 风险溢价 + 流动性溢价
· Rf 是无风险利率,以久期匹配的美国国债收益率为基准。
PD × LGD 是预期损失=违约概率 × 违约损失率,其中违约损失率 = 1 - 资产回收率。风险溢价补偿预期损失之外的不确定性;即便两项资产 PD 和 LGD 完全一致,若风险结果波动区间不同,定价也会存在差异。流动性溢价指资产折价变现、退出持仓产生的额外成本。
结合穆迪 1920 年以来长期历史数据,参考基准如下:
· 美国投机级债券长期年均违约率 4.5%,近十二个月为 3.2%,预计 2026 年一季度升至 4.1%;
· 高级无抵押高收益债券历史平均回收率约 40%,对应违约损失率约 60%;
· 高收益债长期年化预期损失:4.5%×60%=2.7%;
· 私募信贷领域,KBRA 预测 2026 年直接借贷违约率 3.0%,2023–2024 违约案例平均回收率约 48%;
· 高级有抵押杠杆贷款历史回收率区间 65%–75%。
2026 年 4 月 传统金融收益率梯队
我们来看看当前的实际数据。10 年期美国国债上周三收盘收益率 4.29%。同时截取 2026 年 4 月 ICE 美银全信用品类期权调整利差。
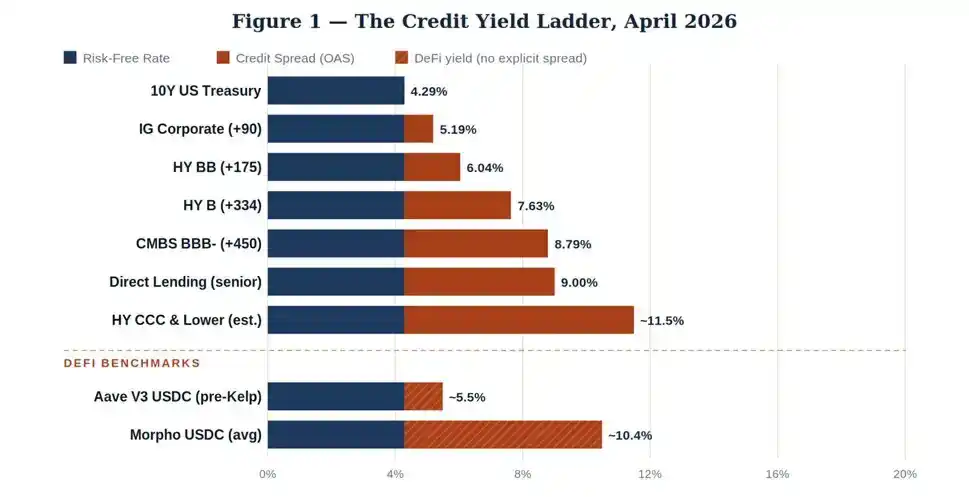
定价逻辑清晰且符合常识:沿着资本层级从国债、投资级债券、投机级债券,到次级商业地产资产逐级下行,收益率同步抬升,用以补偿不断走高的违约概率与亏损幅度。
私募直接借贷收益率维持在 9% 左右,并非借款人违约率更高,核心原因在于非标私募资产流动性极差,流动性溢价显著。
反观 DeFi 市场:KelpDAO 事件爆发前,Aave 的 USDC 存款利率约 5.5%,定价水平介于投资级债券与单 B 级高收益债之间。而依托精选金库与主动管理筛选的 Morpho,收益率约 10.4%。这两个数字不可能同时正确反映相同的潜在风险。
DeFi 三类特有违约模式,传统金融完全不存在
传统的信用违约程序枯燥乏味。借款人无法兑付利息、债券持有人触发债务加速条款、企业重组、资产清算处置、协商资产回收,流程漫长且可协商。
但 DeFi 不存在债务重组机制,威胁主要来自协议攻击,且分为三种完全不同的失效模式,每一类都具备独特的亏损特征。
模式一:智能合约漏洞攻击
代码漏洞引发盗币,例如重入攻击、参数校验失效、权限管控缺失等。攻击者直接掏空资金池。历史数据显示:白帽黑客介入的协议攻击,资金平均回收率仅 5%–15%;若涉及朝鲜国家级黑客组织,回收率基本趋近于零。
2021 年 Poly Network 6.11 亿美元被盗资金全数返还,属于极端个案;Ronin 6.25 亿美元、Wormhole 3.25 亿美元被盗事件,最终挽回损失,完全依赖项目方与做市商自行兜底,并非市场化资产回收,本质是股东代偿。
模式二:预言机操控与治理攻击
借助低流动性去中心化交易池恶意操纵喂价数据,人为制造坏账;或攻击者囤积治理代币、恶意提案通过,掏空国库资金。2022 年 Beanstalk 因治理攻击损失 1.82 亿美元即为典型案例。这类风险虽可通过协议干预部分挽回损失,但贷方持有的资产债权,往往会沦为毫无价值的代币持仓。
模式三:可组合性连锁崩盘
本次 KelpDAO 事件就属于此类,也是最危险、最难审计预判的风险模式。协议 A 发行流动质押 / 再质押衍生品,协议 B 接纳该资产作为抵押品,协议 C 负责跨链资产桥接流转。
整条链路中任意一环遭遇攻击,都会导致下游所有持仓连锁爆雷。攻击者无需攻破 Aave 本身,只需击穿上游 rsETH 底层协议,就会直接让 Aave 贷方承接巨额坏账。
三类风险拥有统一特征,也是 DeFi 与传统信贷市场的核心区别:风险爆发以分钟为单位,而非季度。无契约协商、无破产融资兜底,智能合约自动执行、代码即规则。一旦代码出现漏洞,亏损近乎全额无法挽回。Aave V3 的 rsETH 坏账从零飙升至 1.96 亿美元,耗时仅约四小时。对比来看,BB 级传统高收益债从风险预警到债务重组,中位周期长达 14 个月。
真实亏损数据揭示的真相
Chainalysis 2025 年 12 月中期报告,揭示了一组矛盾数据:2024 年初至 2025 年 10 月,DeFi 整体锁仓资产总值从 400 亿美元回升至 1750 亿美元阶段峰值,但 DeFi 专属黑客攻击亏损,维持在 2023 年低位区间。
2025 年全年加密资产被盗总额 34 亿美元,风险高度集中于中心化交易平台被盗与个人钱包失窃。
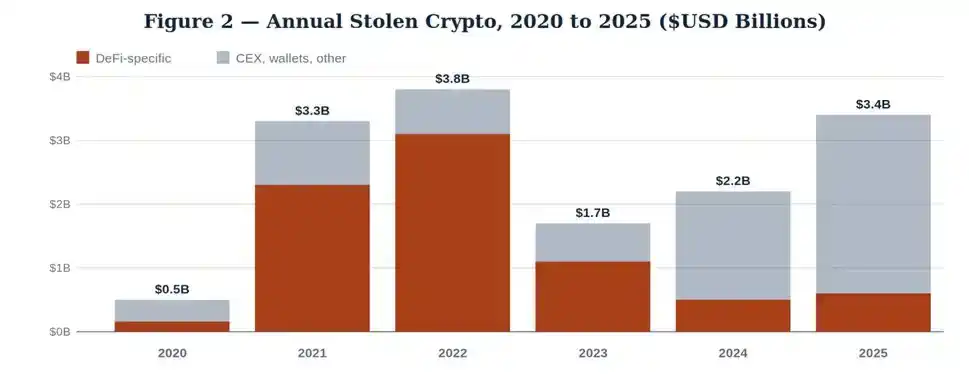
单看这份数据,很容易误判 DeFi 安全水平持续提升。客观事实确实存在:合约审计行业成熟、Immunefi 等漏洞赏金平台保障超千亿美元用户资产、跨链桥逐步引入时间锁与多方验证机制。
但 2026 年的现实完全相反:4 月 1 日 Drift 损失 2.85 亿美元,4 月 18 日 KelpDAO 损失 2.92 亿美元。18 天内两起亿元级暴雷,攻击目标均瞄准可组合性架构漏洞,而非借贷协议本身。
结合年均锁仓资产规模,测算近年 DeFi 年化亏损率:
· 2024 年:DeFi 专项损失约 5 亿美元,平均锁仓 750 亿美元 → 年化亏损率 0.67%
· 2025 年:损失约 6 亿美元,平均锁仓 1200 亿美元 → 年化亏损率 0.50%
· 2026 年年内(年化测算):仅二季度两起事件损失就达 5.77 亿美元,平均锁仓 950 亿美元 → 若风险节奏延续,年化亏损率将达 2.0%–2.5%
据此测算,头部 DeFi 借贷业务远期年化违约概率约 1.5%–2.0%。结合极端攻击下 90% 违约损失率(无外部主体兜底时,常规盗币回收率仅 5%–15%),年化预期损失为 1.35%–1.80%。该数值已超越传统高收益债,且尚未计入不确定性溢价、流动性折价、监管风险、跨链组合性传染风险。
DeFi 合理风险溢价模型
基于债券定价逻辑,我们测算头部 DeFi 稳定币存款的公允收益率:对标以太坊主网头部协议(Aave、Compound)、足额超额抵押、面向散户与量化借款人的 USDC 借贷产品。
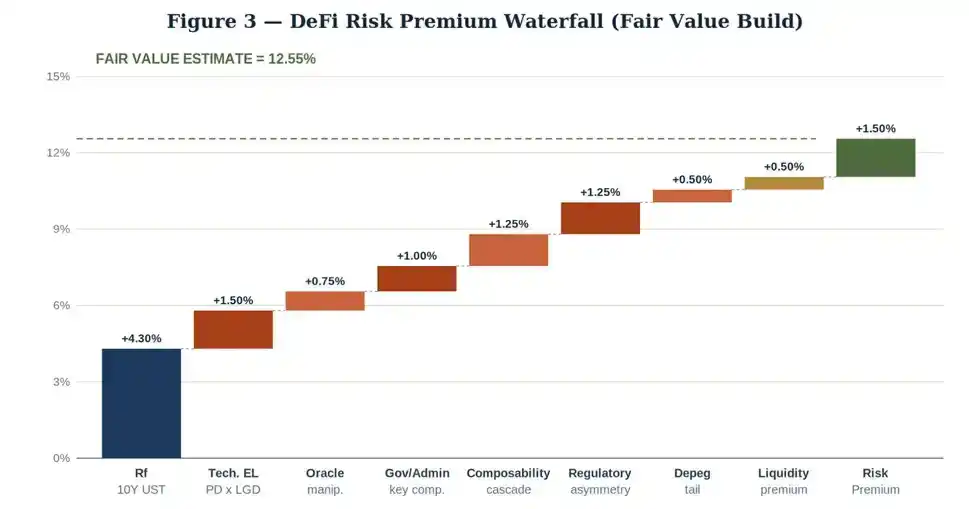
以 10 年期美债为基准,逐层叠加溢价:
· 无风险基准(10 年期美债):+4.30%
· 预期固定损失:+1.50%
· 预言机操控风险溢价:+0.75%
· 治理 / 管理员私钥风险溢价:+1.00%
· 跨协议组合性连锁风险(Kelp 同类风险):+1.25%
· 监管不对称风险溢价:+1.25%
· 稳定币脱锚尾部风险:+0.50%
· 资产流动性溢价:+0.50%
· 风险溢价:+1.50%
最终得到公允合理年化收益率:12.55%。
因此,理想情况下,头部合规 DeFi 稳定币存款,合理利率不应低于 13%。具备保险覆盖、协议储备金兜底的资产,利率可适度下调;长尾协议、新上线市场、涉及再质押与跨链底层资产的标的,需要更高风险溢价。
结论
首先,要争取公平的补偿。如果你以 5% 的收益率向 DeFi 提供 USDC,那么你实际上是在接受 BB 级信用风险定价,而其技术和可组合性风险实际上比 CCC 级还要高。Morpho 式的精选金库市场,利率在 9% 到 12% 之间,更接近公平收益率,但它也带来了管理人选择和透明度方面的问题。
其次,要提升资本结构。以优质抵押品(ETH、wBTC、久经考验的 LST)为抵押的超额贷款,辅以预言机冗余、协议级保险层,且不涉及跨链风险,其风险溢价远低于上述框架。这些属于 DeFi 领域的「投资级资产」。
第三,要正确评估尾部风险。KelpDAO 漏洞并非黑天鹅事件,而是连接在日益脆弱的多链架构上的再质押原语的可预见故障模式。Drift 的情况也类似,只是参与者不同。
2026 年二季度已录得 5.77 亿美元永久亏损。一个收益率为 5.5% 的 DeFi 投资组合,完全无法覆盖极端暴跌与连环爆雷风险。
DeFi 并非不可投资,只是目前被错误定价。机构级配置机会真实存在,但前提是资方要么要求匹配风险的合理溢价,要么以私募信贷的严谨标准,深度尽调单一协议。
单纯无脑存入头部货币币市场、被动接受挂牌低收益的躺平策略,只是伪装成无风险理财的高风险利差交易。





