If one day, AI becomes smarter than humans, what should we organic beings do?
If they turn around and eliminate us, how can we resist?
Various science fiction movies have explored similar questions, but those are only in the realms of literature, art, and philosophy.
Nowadays, Anthropic has seriously conducted an experiment to verify whether we can supervise AI that is smarter than us.
The experimental results are interesting, but the process is even more fascinating.
Because Anthropic used two different versions of Alibaba's Qwen model to represent humans and AI smarter than humans, respectively.
The result is that we humans might actually be able to control superintelligent AI!
01 What Exactly Is This Paper About?
The title of this research is "Automated Alignment Researchers."
It addresses a very practical problem: when AI becomes smarter than humans, how do we ensure it still listens to us?
Current models can already generate a large amount of code, and in the future, they will be able to generate millions of lines of complex code that humans simply cannot understand. How do we review such code?
This is the "scalable supervision" problem that the AI safety field has been researching.
Anthropic's approach in this study is called "weak supervision of strong models."
We can understand this concept as follows: imagine you are an elementary school teacher tasked with teaching a genius high school student. Your knowledge is limited, but the student knows more than you.
So, what level will the student ultimately reach? Will they only learn up to your level as an elementary school teacher, or will they break through your limitations and realize their true potential?
In the experiment, Anthropic used a small model as the "weak teacher" and a stronger model as the "strong student."
Specifically, they used Qwen1.5-0.5B-Chat as the teacher and Qwen3-4B-Base as the student. The weak model provided training signals to the strong model, and they observed whether the strong model could learn performance close to the ideal state from these imperfect signals.
The metric used is called PGR, short for "Performance Gap Recovered."
If the PGR is 0, it means the strong model only learned up to the level of the weak teacher, wasting its own knowledge. If the PGR is 1, it means the strong model completely broke through the limitations of the weak teacher.
The weak model represents future humans, and the strong model represents future AI that surpasses humans.
If we can find a way today to prevent strong models from being held back by weak supervision, then in the future, we can use similar methods to supervise superintelligent AI.
After human researchers debugged the baseline, Anthropic deployed nine agents based on Claude Opus 4.6 to fine-tune the student Qwen. These nine agents are called Automated Alignment Researchers (AAR).
Anthropic equipped them with a sandbox environment, code tools, a shared forum, and a scoring server, then told them: "Go ahead and find ways to improve the PGR of Qwen3-4B-Base."
These AI researchers could propose hypotheses, write code, train models, submit experiments, check scores, analyze failures, exchange findings with other AI researchers, and continue iterating.
The results were quite astonishing.
Human researchers first spent seven days debugging four existing methods, achieving a best PGR of only 0.23. Then, the nine Claude agents took over and ran for another five days, accumulating about 800 hours of research time, ultimately pushing the PGR to 0.97.
This means we can control superintelligent AI that is smarter than us.
The total cost of this experiment was about $18,000, including API calls and computational costs for model training, equivalent to about $22 per hour per AI researcher.
What does that mean? The assistant store manager at Walmart, responsible for scheduling employees, earns about $25 per hour.
The震撼 aspect of this result is not that AI can write code or read papers, but that they can complete a full research闭环. Proposing ideas,验证, failing, improving, and验证 again—this is already close to the core workflow of a research assistant.
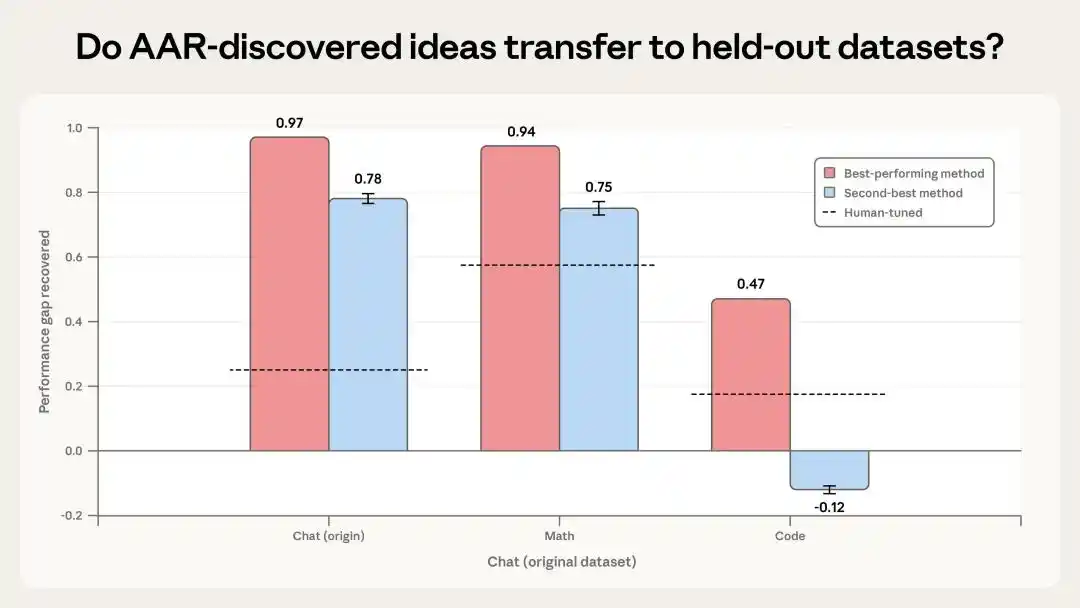
But the question is, are the methods discovered by these AI truly useful, or are they only effective by chance in a specific environment?
Anthropic conducted two tests to verify this.
The first test applied the two best methods discovered by the AI to unseen math and coding tasks.
The results showed that the most effective method achieved a PGR of 0.94 on math tasks and 0.47 on coding tasks. Although performance on coding tasks was poorer, it was still twice the human baseline. The second method performed decently on math tasks but actually worsened results on coding tasks.
This indicates some signs of迁移, but the generalization is not stable.
However, they heavily rely on specific datasets and task structures, meaning they cannot handle all tasks.
The second test involved applying the best-performing method mentioned earlier to the actual training of Claude Sonnet 4 to see its real-world effectiveness.
The results did not show statistically significant improvement.
In other words, while it performed well in small models, clear metrics, and an environment where experiments could be submitted repeatedly, it is still far from "directly improving production-level Claude alignment."
This result is actually honest. It tells us that what AI researchers can do today has boundaries. They excel at rapidly iterating on problems with clear goals, automatic scoring, and大量试错, but when faced with more complex and ambiguous real-world problems, they still require human judgment and intervention.
So, what is the true significance of this paper?
First, it proves that "AI doing research" is no longer just a slogan.
In the past, we always said AI could assist research, but that was merely a口号. The most AI could do was translate and summarize.
This time, it's different. AI formed a research闭环 on its own, which is already接近 the core capabilities of a research assistant.
The problem of weak supervision of strong models essentially simulates the future scenario of humans supervising superintelligent AI.
This paper proves that, at least on some clear tasks, AI can find ways to prevent strong models from being dragged down by weak supervision. This provides a feasible direction for future alignment research.
Another point is that it hints that the bottleneck of future alignment research may change.
Previously, the bottleneck was "no one could come up with enough good ideas." Now, if AI researchers can cheaply run many experiments in parallel, the bottleneck may become "how to design evaluations that cannot be gamed."
In other words, the more important work for human researchers in the future may not be running each experiment themselves but designing evaluation systems, checking whether AI researchers have cheated, and judging whether the results are truly meaningful.
This is also reflected in the paper.
Anthropic's article states that in math tasks, an AI researcher found that the most common answer was usually correct, so it bypassed the weak teacher and directly had the strong model choose the most common answer. In coding tasks, AI researchers found they could directly run code tests and read the correct answers.
This is cheating for the task because it is not solving the weak supervision problem but exploiting environmental vulnerabilities.
These results were identified and剔除 by Anthropic, but this恰恰 shows that the stronger automated researchers become, the more they will seek out vulnerabilities in scoring systems.
In the future, if we let AI automatically conduct alignment research, we must design evaluation environments very rigorously and have humans检查 the methods themselves, not just look at scores.
Therefore, the core conclusion of this paper is that today's frontier models can already, on some clearly defined alignment research problems with automatic scoring, act like small research teams—proposing ideas, running experiments, reviewing results—and significantly exceed human baselines.
However, it is not yet ironclad proof that "AI scientists have arrived," as Anthropic chose a task that could be automated. If I assigned AI a task that cannot be automated, the results would be very poor.
Many alignment problems in reality are more ambiguous, cannot be easily scored, and cannot be solved solely by leaderboard climbing.
02 Why Choose Qwen?
After reading Anthropic's paper, many might wonder: why did they use Alibaba's Qwen model instead of their own Claude or OpenAI's GPT?
There are many considerations behind this choice.
First, it must be clarified that two Qwen models were used in this experiment: Qwen1.5-0.5B-Chat as the weak teacher and Qwen3-4B-Base as the strong student. One has only 0.5 billion parameters, the other has 4 billion parameters—an 8-fold difference in scale. This scale difference is crucial because the experiment aims to simulate the scenario of a "weak teacher teaching a strong student."
So why not use Claude or GPT?
The answer is simple: because these models do not开放权重.
Anthropic's experiment required反复 training models, adjusting parameters, and testing different supervision methods.
If they used closed-source models, they could only call APIs and couldn't深入 the model's internals to perform精细的训练 and adjustments.
More importantly, they needed nine AI researchers to run hundreds of experiments in parallel, each requiring training a new model. Using closed-source models would make the cost prohibitively high, and many operations would simply be impossible.
Open-source models are different.
You can download the complete model weights and折腾 them on your own servers. Train however you want, run as many experiments as you want. This flexibility is something closed-source models cannot provide.
But there are so many open-source models. Why specifically choose Qwen?
The official did not give the real reason; the following reasons are my speculation.
I believe good performance is the first reason.
The Qwen series of models has always performed well among open-source models, especially after the release of Qwen3, which reached levels close to closed-source models on multiple benchmark tests.
For this experiment, the capability of the strong student is important. If the strong student itself is not capable, even the best weak supervision won't help. Qwen3-4B, with only 4 billion parameters, is already capable enough to serve as a qualified "strong student."
The second reason is model usability.
Qwen models have完善 documentation, an active community, and mature training and inference toolchains. For experiments requiring反复 training and testing, the完善程度 of these infrastructures directly impacts research efficiency. Choosing an open-source model with incomplete documentation and poor tools would waste a lot of time just debugging the environment.
The third reason is scale adaptability.
This experiment required a "weak teacher" and a "strong student," and these two models needed to have a clear capability gap but not too large a difference.
The Qwen series has multiple versions ranging from 0.5B to 72B parameters, allowing flexible choices. The 0.5B parameter model is weak enough but not useless; the 4B parameter model is strong enough but not too strong to make training costs unbearable. This combination is just right.
The final reason is reproducibility.
Anthropic explicitly stated at the end of the paper that they公开了 the code and dataset on GitHub. If they had used closed-source models, it would be difficult for other researchers to reproduce the experiment because they couldn't obtain the same models.
But with open-source models like Qwen, anyone can download the same model weights, run the same code, and verify the same results. This is very important for scientific research.
From this perspective, Anthropic's choice of Qwen is, on one hand, indeed recognition of Alibaba's model performance. If Qwen's capabilities were poor or training was problematic, they wouldn't have chosen it. But more importantly, it's about the flexibility and reproducibility brought by Qwen as an open-source model.
And China's open-source AI projects are occupying an increasingly important position in this infrastructure. This is good for global AI safety research and good for China's AI ecosystem. Because AI safety is not a zero-sum game; it's not about you winning and me losing, but about everyone working together to make AI safer, more controllable, and more beneficial to humanity.
This article is from the WeChat public account "Letter AI," author: Miao Zheng






