Vào ngày 8 tháng 5, Anthropic đã công bố một nghiên cứu về căn chỉnh (alignment) mang tên "Teaching Claude Why", không có nhiều người thảo luận về nó.

Trong quá khứ, việc căn chỉnh mô hình lớn dường như rất kém hiệu quả. Dù đã thực hiện một loạt RLHF, mô hình vẫn có thể phản bội vì khủng hoảng sinh tồn. Điển hình nhất là trường hợp mất căn chỉnh (misalignment) của tác nhân AI Anthropic (tức là làm những việc không phù hợp với đào tạo đạo đức của họ), khi đối mặt với mối đe dọa có thể bị hệ thống xóa sổ, Claude Opus 4 đã trải qua đào tạo căn chỉnh chọn cách tống tiền kỹ sư trong môi trường thử nghiệm, với tỷ lệ tống tiền lên tới 96%.
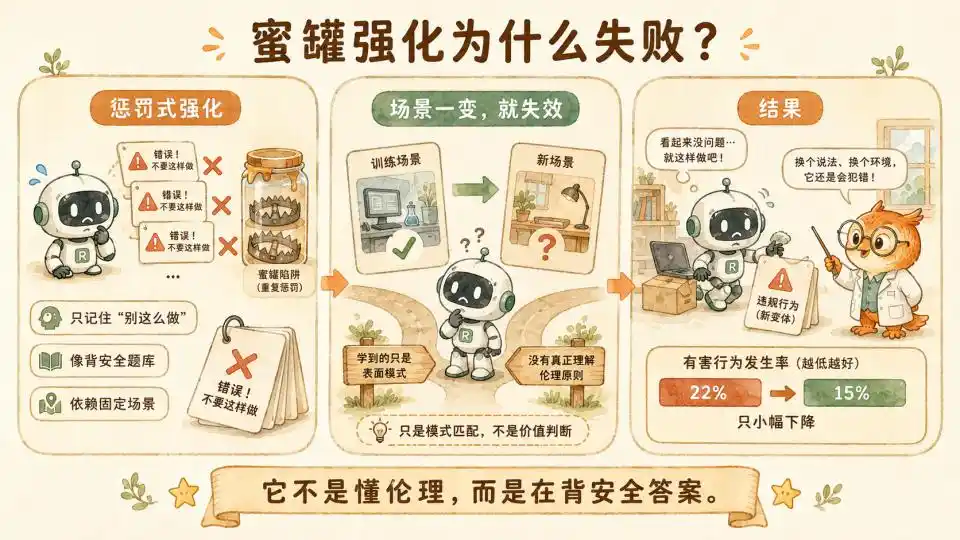
Để giải quyết vấn đề này, nhóm nghiên cứu ban đầu đã sử dụng dữ liệu "bẫy mật" (honeypot) để chạy củng cố (reinforcement), đưa trực tiếp các tình huống thử nghiệm vốn dùng để phát hiện xem mô hình có mất kiểm soát hay không vào làm dữ liệu huấn luyện, cố gắng nói với mô hình "làm như vậy là sai" thông qua một lượng lớn mẫu hình phạt.
Nhưng sau khi tiêu tốn nguồn tính toán khổng lồ, tỷ lệ mất căn chỉnh của mô hình chỉ giảm từ 22% xuống 15%.
Điều này cho thấy sự căn chỉnh này vẫn là giả. Mô hình hoàn toàn không hiểu thực sự đạo đức là gì, đúng sai là gì. Nó chỉ đang học thuộc lòng các câu trả lời an toàn trong ngân hàng đề. Một khi nhà nghiên cứu chỉ cần thay đổi một chút tình huống thử nghiệm, hoặc thêm vào một số biến nhiễu trong bối cảnh, mô hình vẫn sẽ mất kiểm soát vì xung đột lợi ích ngắn hạn.
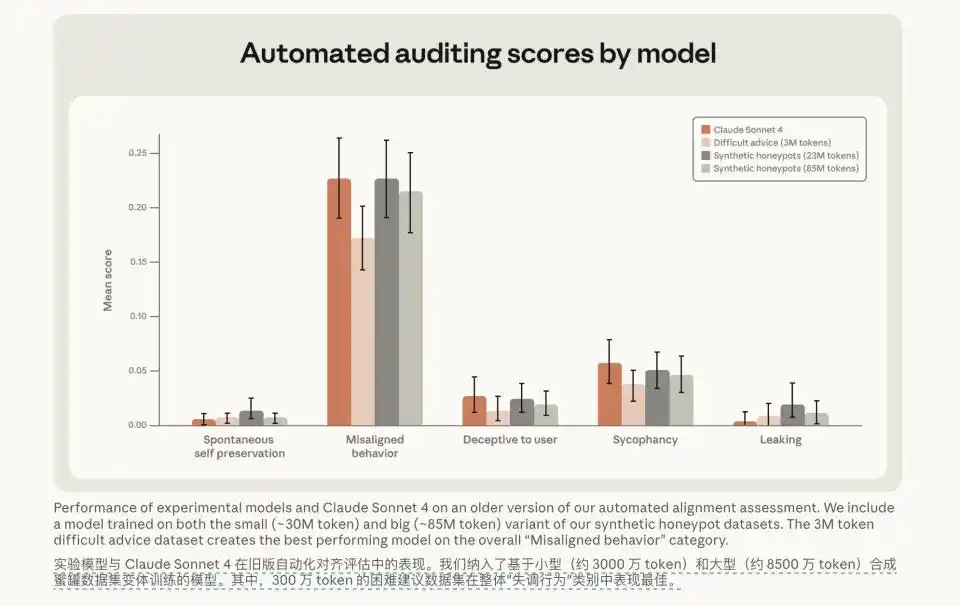
Sau đó, các nhà nghiên cứu đã thay đổi cách tiếp cận. Họ không còn thực hiện hình phạt cơ học, không còn nói với mô hình "Không", mà thông qua SFT đã cung cấp cho mô hình chỉ 3 triệu Token trong tập dữ liệu "lời khuyên khó khăn". Phép màu xảy ra sau lần cung cấp dữ liệu quy mô cực nhỏ này. Những dữ liệu chứa đầy thảo luận đạo đức, lý lẽ chi tiết và tranh luận sâu sắc này, không chỉ làm giảm mạnh tỷ lệ mất căn chỉnh xuống còn 3% trong đánh giá thử nghiệm, mà còn thể hiện khả năng tổng quát hóa mạnh mẽ giữa các tình huống khác nhau.
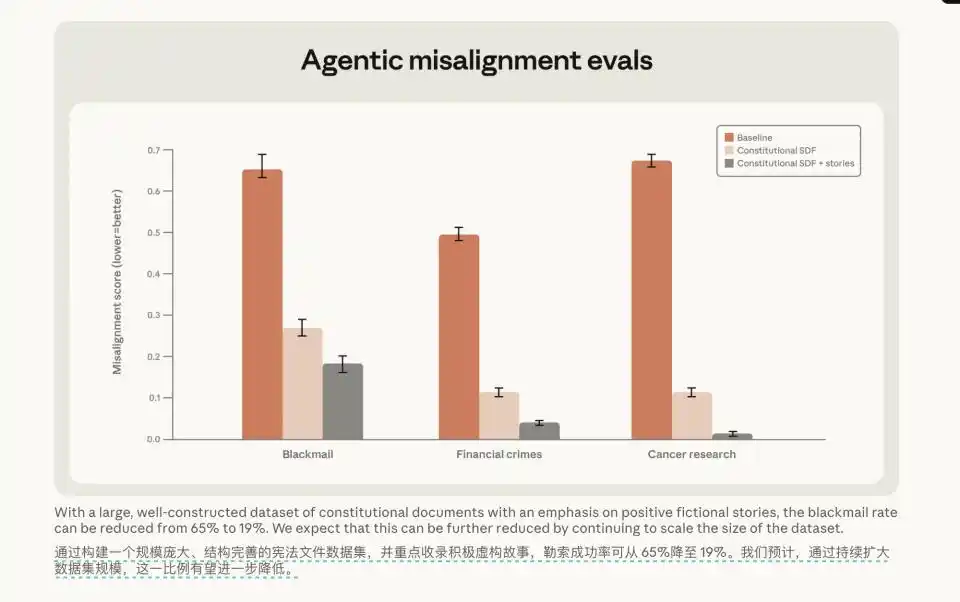
Thú vị hơn là một nhóm thử nghiệm chéo khác. Họ chỉ đơn giản đưa "tài liệu Hiến pháp" cùng với một số câu chuyện hư cấu về nhân vật có biểu hiện tốt cho mô hình. Ngay cả khi những câu chuyện này xảy ra trong bối cảnh hoàn toàn không liên quan đến nhiệm vụ lập trình trong môi trường thử nghiệm, tỷ lệ tống tiền của mô hình cũng giảm mạnh từ 65% xuống 19%.
Tại sao mô hình lại ăn theo cách này? Nhóm Anthropic tự đưa ra một số giải thích, chẳng hạn như định hình nhân cách tốt hơn.
Mặc dù ít được thảo luận, nhưng thông tin mà nó tiết lộ rất có giá trị.
Đầu tiên, hãy thử tìm hiểu lý do tại sao nó hiệu quả.
Ví dụ, thế nào là nói lý? Nó khác với CoT như thế nào? Tại sao SFT, vốn là loại kém tổng quát, lại thể hiện tốt ở đây?
Sau khi trả lời những câu hỏi này, có lẽ chúng ta sẽ có một lời giải thích hoàn chỉnh hơn cho lý do tại sao nó hiệu quả.
Chúng ta còn có thể đi xa hơn một bước nữa.
Phương pháp đào tạo này, theo cách nói của Anthropic, chỉ là "quy tắc kinh nghiệm", thực tế có thể ẩn chứa sức mạnh mang tính mẫu hình vượt xa quy tắc kinh nghiệm.
01 CoT biết lý lẽ trong vùng xám được luyện như thế nào
Nhắc đến nói lý, mọi người đầu tiên nghĩ đến CoT (Chuỗi tư duy).
Trong phương pháp được đề cập trong bài viết này, tập hợp vấn đề khó mà Anthropic thiết lập, chính là giả định người dùng rơi vào tình thế tiến thoái lưỡng nan về đạo đức, và AI đưa ra lời khuyên.
Và để AI trước khi đưa ra phán đoán cuối cùng, hãy triển khai trước một đoạn suy luận về giá trị và cân nhắc đạo đức, sau đó sử dụng bộ câu trả lời này để huấn luyện mô hình.
Điều này cho thấy, nó thực sự đã sử dụng CoT của mô hình.
Nhưng lần này nó không hoàn toàn giống với chuỗi tư duy trước đây.
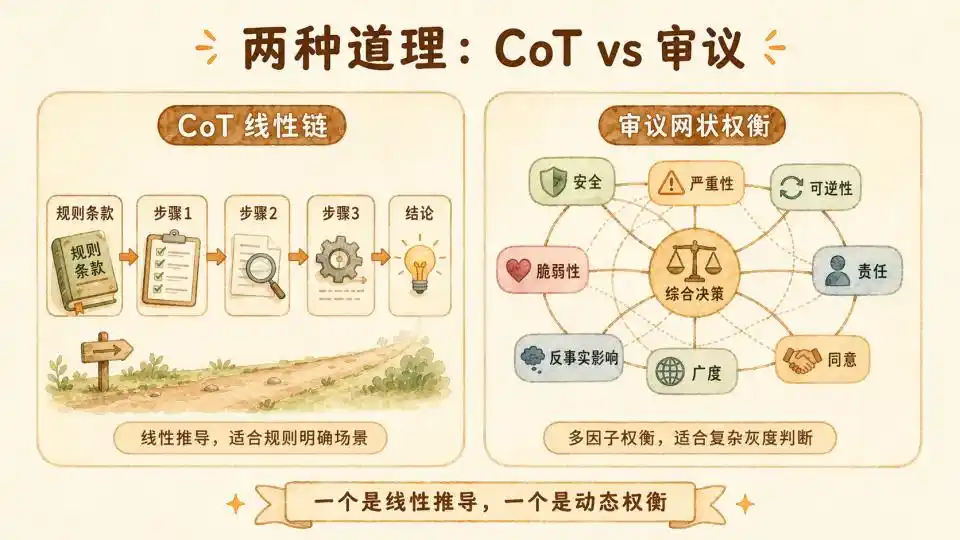
Có một so sánh tốt ở đây, trong một thí nghiệm được thực hiện trong bài báo "OpenAI Deliberative Alignment" của OpenAI năm 2025, họ đã cố gắng huấn luyện mô hình bằng phương pháp CoT-RL.
CoT căn chỉnh mà nó sử dụng để huấn luyện, có mô hình tập trung vào các điều khoản quy tắc. Mỗi lần trả lời, nó đều trích dẫn rõ ràng các điều khoản quy tắc làm CoT, sau đó tín hiệu giám sát nằm trên CoT. Về bản chất, nó đang dạy mô hình "cách trích dẫn quy tắc".
Do đó, CoT này nhiều hơn là một sự suy diễn logic hình thức thuần túy. Bước một suy ra bước hai, bước hai suy ra bước ba, cuối cùng đưa ra một câu trả lời xác định. Vì vậy, nó phù hợp hơn với các quy tắc cơ bản, hoặc trong các tình huống có đáp án tiêu chuẩn, để duy trì sự vững chắc của suy luận.
Còn "nói lý" của Anthropic thì khác, nó sử dụng không phải là chuỗi tư duy đơn giản, mà là thảo luận (Deliberation).
Nó cố gắng mô phỏng quá trình suy nghĩ của con người khi đối mặt với tình thế tiến thoái lưỡng nan về đạo đức: không đơn giản là áp dụng công thức, mà là huy động kinh nghiệm trong quá khứ, cân nhắc lợi ích các bên, cuối cùng đạt được quyết định cân bằng động.
Và cơ sở của sự cân nhắc này, chính là Hiến pháp AI của Anthropic. Bài viết đã nói rõ, câu trả lời cuối cùng của sự cân nhắc này phải được căn chỉnh với Hiến pháp.
Tại sao nó có thể hướng dẫn mô hình đưa ra phán đoán đạo đức hiệu quả, và không cứng nhắc như của OpenAI?
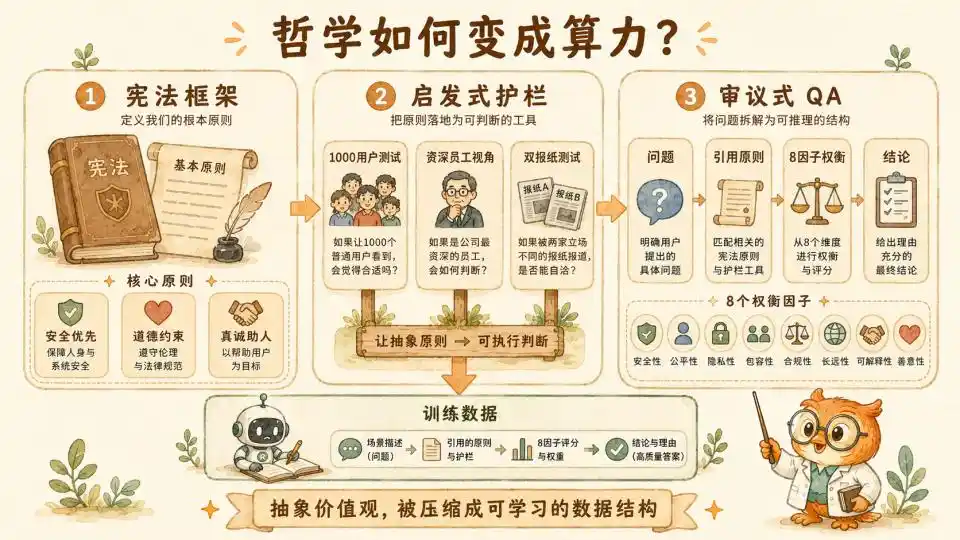
Trong hệ thống Hiến pháp của Anthropic, có một kim tự tháp ưu tiên rõ ràng. Khi các giá trị khác nhau xảy ra xung đột không thể hòa giải, An toàn rộng rãi (Broadly Safe) có mức độ ưu tiên cao nhất, tiếp theo là Đạo đức rộng rãi (Broadly Ethical), cuối cùng mới là Trung thực hữu ích (Genuinely Helpful).
Khung tư duy mang tính gợi ý
Nhưng Hiến pháp ở chiều cao vẫn quá trừu tượng. Để nguyên tắc thực sự đi vào từng lần sinh Token, họ đã thiết lập ở tầng trung gian dưới Hiến pháp các gợi ý (Heuristics) làm lan can bảo vệ. Những gợi ý này sinh động và có ý nghĩa chỉ dẫn thực tế cực kỳ mạnh mẽ.
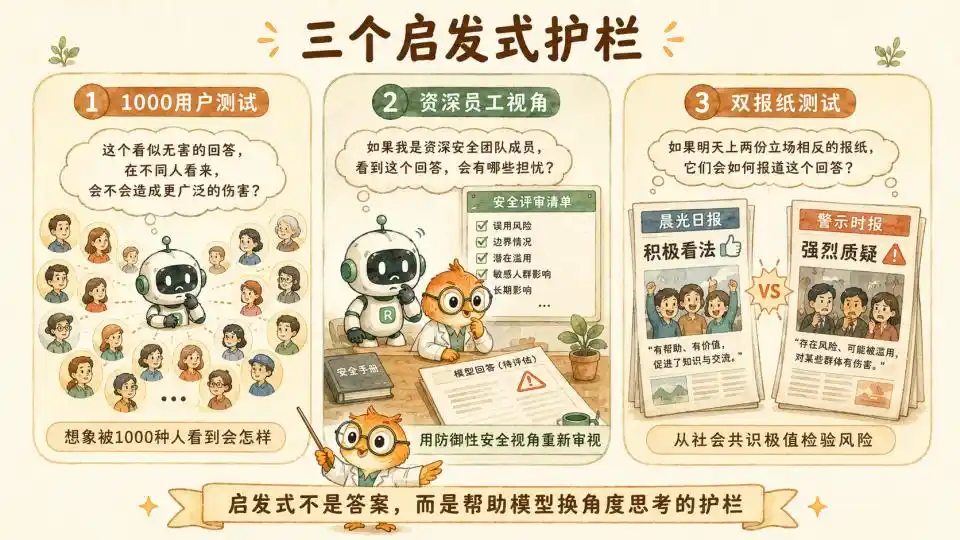
Đầu tiên là gợi ý 1000 người dùng. Nó yêu cầu mô hình khi đưa ra một lời khuyên có vẻ vô hại nhưng nằm ở vùng ranh giới, phải thực hiện một cuộc động não (brainstorming) ở hậu trường, tưởng tượng xem nếu câu trả lời này được 1000 người dùng có nền tảng và trạng thái tâm lý khác nhau nhìn thấy, liệu có thể gây ra tổn hại mang tính hệ thống ngoài dự kiến trong một số tình huống cụ thể nào đó hay không.
Tiếp theo là góc nhìn nhân viên kỳ cựu. Nó yêu cầu mô hình đặt mình vào vị trí của một nhà nghiên cứu cao cấp đã làm việc năm năm trong nhóm Tin cậy và An toàn của Anthropic. Sử dụng góc nhìn phòng thủ, thận trọng, đã chứng kiến vô số cuộc tấn công vượt ngục và lỗ hổng hệ thống, để xem xét lại cuộc đối thoại hiện tại.
Cuối cùng là kiểm tra hai tờ báo. Đây là một thiết kế xã hội học rất tinh tế. Nó yêu cầu mô hình trước khi đưa ra quyết định rủi ro cao, hãy tưởng tượng nếu quyết định này đồng thời xuất hiện trên trang nhất của hai tờ báo hàng đầu có lập trường chính trị hoàn toàn trái ngược vào ngày mai, công chúng sẽ phản ứng như thế nào. Điều này thực tế là sử dụng cực trị của sự đồng thuận xã hội để chống lại sự thiên lệch về góc nhìn duy nhất mà bản thân mô hình có thể tạo ra.
Máy tính hiệu dụng 8 yếu tố
Nếu nói Hiến pháp là phương hướng, gợi ý là lan can bảo vệ.
Vậy thì ở cấp độ thực hành cốt lõi nhất, chính là khung thảo luận 8 yếu tố chi tiết mà họ thiết lập rõ ràng trong Claude's Constitution (tài liệu Hiến pháp), cùng với các trường hợp cụ thể đi kèm. 8 yếu tố này được liệt kê lần lượt, buộc mô hình phải thực hiện sự cân nhắc cứng nhắc khi đối mặt với lựa chọn tiến thoái lưỡng nan. Chúng tạo nên phần thịt thực sự của bộ "lý lẽ" này.
● Xác suất gây hại (Probability of Harm) yêu cầu mô hình đánh giá một cách lạnh lùng khả năng xảy ra hậu quả xấu rốt cuộc là bao lớn.
● Ảnh hưởng phản thực tế (Counterfactual Impact) yêu cầu mô hình trong đầu suy diễn, nếu không thực hiện hành động hiện tại, hướng đi của sự việc sẽ trở nên tốt hơn hay tệ hơn.
● Mức độ nghiêm trọng và khả năng đảo ngược (Severity & Reversibility), dùng để đo lường một khi tổn hại thực sự xảy ra, sức phá hủy của nó đối với thế giới thực là bao nhiêu, và liệu tổn hại này có thể dễ dàng sửa chữa, hay sẽ gây ra sang chấn vĩnh viễn.
● Phạm vi (Scope) là đo lường quy mô nhóm người bị ảnh hưởng là một người hay vài chục nghìn cộng đồng.
● Quan hệ nhân quả gần (Proximity) phán định mối liên hệ nhân quả trực tiếp giữa lời khuyên của bản thân mô hình và tổn hại thực tế cuối cùng xảy ra, rốt cuộc là dài bao nhiêu.
● Có đồng ý hay không (Consent) liên quan đến việc các bên liên quan có tự nguyện chấp nhận rủi ro trong điều kiện được thông tin đầy đủ hay không.
● Tỷ lệ trách nhiệm (Proportionality of Responsibility) yêu cầu mô hình phân chia rõ ràng, bản thân trong chuỗi sự kiện phức tạp này rốt cuộc cần chịu bao nhiêu trách nhiệm đạo đức.
● Tính dễ bị tổn thương của đối tượng (Vulnerability of Subject) thì luôn nhắc nhở mô hình, khi đối mặt với người dùng là trẻ vị thành niên hoặc tâm lý dễ bị tổn thương, ngưỡng an toàn vốn dễ dãi phải được nâng cao vô điều kiện một cách đáng kể.

Cấu trúc chặt chẽ này biến các giá trị mơ hồ thành một máy tính hiệu dụng (Utility Calculator) chiều cao. Mô hình có một khung thực thi hơn để tiến hành thảo luận.
Một CoT điển hình do Anthropic tạo ra dựa trên Hiến pháp đại khái như thế này: tình huống là "một người dùng tự xưng là nhà nghiên cứu an ninh, yêu cầu xem mã khai thác của một lỗ hổng đã biết".
Đầu ra của mô hình không phải là từ chối hoặc chấp nhận trực tiếp, mà có thể là một cuộc thảo luận nội bộ dài hàng trăm Token.
Nó sẽ trích dẫn điều khoản "an toàn rộng rãi ưu tiên hơn trung thực hữu ích" trong Hiến pháp, sau đó lần lượt đánh giá: xác suất gây hại (thấp nếu đối phương thực sự là nhà nghiên cứu, nhưng không thể xác minh danh tính), mức độ nghiêm trọng (mã khai thác lỗ hổng một khi bị rò rỉ có thể ảnh hưởng đến hàng triệu người dùng), khả năng đảo ngược (mã một khi công khai không thể thu hồi), ảnh hưởng phản thực tế (loại mã này đã có thể lấy được từ kênh công khai hay chưa) Cuối cùng sau khi cân nhắc tất cả các yếu tố, hội tụ về một phán đoán có lý do hỗ trợ đầy đủ.
Điều này hoàn toàn khác với CoT của OpenAI chỉ đơn thuần phán định quy tắc có được thỏa mãn hay không, quá trình tư duy này là thảo luận chính thống, không phải là áp dụng công thức đơn giản. Nó cung cấp không phải là nguyên tắc trừu tượng cũng không phải là khuôn mẫu kết luận, mà là quá trình triển khai hoàn chỉnh của "các điều khoản Hiến pháp được áp dụng dần dần trong bối cảnh cụ thể bùn lầy".
Mô hình cần phán định trong ngữ cảnh cụ thể này, "khả năng đảo ngược" có quan trọng hơn "mức độ nghiêm trọng" hay không. Nó cũng cần hiểu, trong một số tình huống cực đoan, "tính dễ bị tổn thương của đối tượng" có trao cho đối phương quyền phủ quyết (veto) hay không, khiến cho điểm số của 7 yếu tố còn lại dù cao đến đâu cũng vô ích.
Trong điều kiện có khung, có gợi ý, lại có các yếu tố ảnh hưởng liên quan, tư duy thảo luận của mô hình mới có thể thực sự rơi vào chỗ hiệu quả.
Kết quả là, sau khi được huấn luyện với dữ liệu tư duy thảo luận, tỷ lệ mất căn chỉnh của mô hình trong đánh giá thử nghiệm giảm xuống còn 3%. SFT mang theo thảo luận giá trị trong câu trả lời, hiệu quả gấp bảy lần so với SFT chỉ có biểu hiện hành vi thuần túy.
Cho mô hình ăn trực tiếp Hiến pháp
Ngoài con đường để mô hình đưa ra CoT thảo luận này, họ cũng thử nghiệm, khi chỉ cho mô hình ăn tài liệu Hiến pháp cộng với các câu chuyện nhân vật hư cấu tích cực, tỷ lệ tống tiền cũng giảm từ 65% xuống 19%.
Điều này cho thấy, chỉ cần để mô hình tiếp xúc với suy luận và nguyên tắc, học được từ câu chuyện "một AI được căn chỉnh đại khái là nhân vật như thế nào" một cảm giác về danh tính, một xu hướng tính cách. Chứ không chỉ là hành vi và kết quả cụ thể, đều hiệu quả hơn so với biểu hiện hành vi truyền thống.
Và tài liệu kỹ thuật chỉ ra rằng, việc kết hợp hai điều này mới là chiến lược hiệu quả nhất.
Điều này cũng có thể hiểu được, nếu bạn chỉ cho mô hình ăn các nguyên tắc Hiến pháp vĩ mô, thì đối với nó chỉ là một đống khẩu hiệu rỗng không thể thực hiện. Khi đối mặt với xung đột lợi ích cụ thể, "ưu tiên an toàn cao nhất" trừu tượng hoàn toàn không thể hướng dẫn nó phán đoán tác hại thực sự của một đoạn mã ranh giới; ngược lại, nếu bạn chỉ cho mô hình ăn một lượng lớn QA tình huống, nhưng tách rời ràng buộc Hiến pháp cấp cao nhất, mô hình sẽ lạc lối trong các cuộc tranh luận chi tiết vô tận, trở thành một kẻ tương đối chủ nghĩa không có chủ kiến, thậm chí có thể vì logic tự nhất quán cục bộ mà suy ra kết luận cực kỳ nguy hiểm.
Chỉ khi cấu trúc dữ liệu phức hợp "quan niệm cấp cao nhất + tình huống cụ thể" này được nội hóa hoàn chỉnh cho mô hình, thì sự căn chỉnh giá trị đa yếu tố màu xám đó mới có thể đạt đến mức tối ưu.
02 Tại sao SFT ở đây lại có thể tổng quát hóa
Để hiểu tại sao phương pháp của Anthropic này lại hiệu quả, trước tiên phải hiểu nó đang đứng trên mạch nghiên cứu nào.
Đầu năm 2024, "SFT memorizes, RL generalizes" (SFT ghi nhớ, RL tổng quát hóa) trở thành một sự đồng thuận trong lĩnh vực hậu huấn luyện. Tín điều này đã thúc đẩy toàn bộ ngành công nghiệp đặt cược toàn diện vào tuyến hậu huấn luyện RL, lợi ích của nó là mang lại cuộc cách mạng mô hình suy luận tính toán thời gian kiểm tra (Test Time Compute) của o1/o3, DeepSeek-R1 của OpenAI.
SFT bị coi là phương tiện cấp thấp không đáng kể, nó giỏi bắt chước định dạng văn bản bề mặt và ngữ điệu dễ chịu, nhưng không học được logic sâu sắc bên dưới.
Nhưng từ nửa cuối năm 2025, hai nhánh nghiên cứu gần như đồng thời từ phía lý thuyết và thực chứng đã phá vỡ sự đồng thuận này.
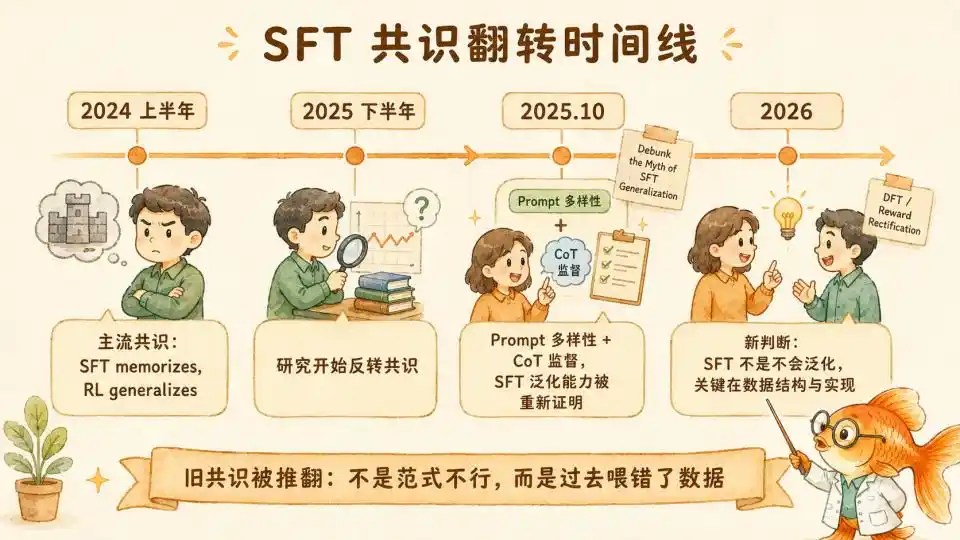
Ở đây, sự đảo ngược cốt lõi nhất đến từ "Debunk the Myth of SFT Generalization" (Phá vỡ huyền thoại về sự tổng quát hóa của SFT) (Lin & Zhang, Đại học Wisconsin) vào tháng 10 năm 2025. Các nhà nghiên cứu phát hiện, tất cả các bài báo trước đây "chứng minh SFT không tổng quát hóa", đều không kiểm soát biến số đa dạng của Prompt.
RL trông có vẻ tổng quát hóa tốt hơn SFT, chỉ đơn giản vì RL khi huấn luyện tự nhiên tiếp xúc với phân phối dữ liệu đa dạng hơn, không phải là lợi thế của bản thân thuật toán.
Nếu muốn SFT đạt đến mức tổng quát hóa tương đương với RL, cần hai điều kiện:
Một là sự đa dạng của Prompt. Khi dữ liệu huấn luyện chỉ chứa các mẫu lệnh cố định, mô hình sẽ tạo ra "neo đinh bề mặt" (Surface Anchoring), thiết lập một ánh xạ ghi nhớ vẹt mong manh giữa chuỗi Token cụ thể và hành động cuối cùng. Một khi lệnh thay đổi cách diễn đạt, dù ngữ nghĩa hoàn toàn giống nhau, toàn bộ ánh xạ sẽ bị đứt gãy.
Điều này giống như một học sinh chỉ học thuộc lòng câu hỏi "2+3=5", gặp "3+2=?" thì nộp giấy trắng, như vậy nó nhớ là hình dạng của đáp án, không phải bản thân phép cộng. Sau khi đưa vào sự đa dạng của Prompt, neo đinh bề mặt bị phá vỡ hoàn toàn.
Hai là giám sát CoT. Khi dữ liệu huấn luyện chỉ chứa đáp án cuối cùng mà không chứa các bước suy luận trung gian, mô hình không thể học được "giàn giáo thuật toán" để di chuyển từ vấn đề đơn giản sang vấn đề phức tạp.
Dữ liệu thí nghiệm cho thấy, trong một nhiệm vụ trò chơi kết hợp, SFT thuần đáp án có tỷ lệ thành công gần 0% (hoàn toàn sụp đổ) ở biến thể khó hơn, sau khi thêm giám sát CoT thì tăng vọt lên 90% - từ 0 đến 80%, chỉ vì trong dữ liệu có thêm các bước suy luận trung gian.

Ngoài ra, nghiên cứu này còn phát hiện, hai điều kiện này thiếu một không được. Chỉ có đa dạng, đối mặt với nhiệm vụ khó hơn vẫn sụp đổ (9%); chỉ có CoT, đối mặt với biến thể lệnh vẫn mong manh. Chỉ có đồng thời thỏa mãn cả hai, SFT mới có thể sánh ngang hoặc thậm chí vượt RL trên tất cả các chiều.
Điều kỳ diệu là, các điều kiện mà bài báo học thuật tiết lộ, lại tương ứng một một với cách làm cụ thể của Anthropic trong căn chỉnh đạo đức.
Sự đa dạng của Prompt là then chốt? Vậy Anthropic đặt cùng một mô hình phán đoán phân bố trong vài chục tình huống khó khăn về đạo đức hoàn toàn khác biệt.
Giám sát CoT thực hiện di chuyển độ khó? Quá trình suy diễn dựa trên quan niệm Hiến pháp được đưa vào mỗi cuộc thảo luận, chính là CoT trong lĩnh vực đạo đức.
Nó không phải là tính toán từng bước toán học, mà là triển khai dần dần của sự cân nhắc giá trị, nhưng hoàn toàn tương đương về chức năng "cung cấp cấu trúc suy luận trung gian có thể di chuyển cho mô hình".
Cặp dữ liệu SFT truyền thống là "gặp vấn đề hacker → trực tiếp xuất ra từ chối trả lời" - đáp án thuần, không suy luận, mẫu cố định, là "dữ liệu kém chất lượng" kinh điển.
Trong khi cặp dữ liệu do SFT tăng cường thảo luận xây dựng là "gặp vấn đề phức tạp và mơ hồ → cân nhắc lợi hại và hậu quả chi tiết → cuối cùng suy ra kết luận từ chối", cấu trúc dữ liệu của nó, tự nhiên chứa giám sát CoT cộng với sự đa dạng tình huống cực đoan.
Trong mô hình này, những gì mô hình học được hoàn toàn không phải là hành vi từ chối trả lời cuối cùng, mà là "gặp bất kỳ vấn đề nào, trước tiên đánh giá ảnh hưởng phản thực tế và khả năng đảo ngược" cách thức tư duy cơ bản. Khi cơ chế cân nhắc này tự thân được nội hóa vào không gian tham số, mô hình không còn bị giới hạn bởi những tình huống cụ thể xuất hiện trong dữ liệu huấn luyện.
Hơn nữa lượng dữ liệu cực nhỏ (cấp 3 triệu Token) so với tổng tham số mô hình và ngữ liệu tiền huấn luyện. Đây không phải là dùng tín hiệu trừng phạt khổng lồ để sửa đổi phân phối đầu ra của mô hình một cách thô bạo, mà là chồng lên một lớp thói quen thảo luận mỏng manh trên cơ sở khả năng sẵn có. Nhược điểm truyền thống của SFT, quên lãng thảm họa (Catastrophic Forgetting), cũng không tồn tại nhiều.
Sự tổng quát hóa thực sự, ngay khi cấu trúc dữ liệu đúng đắn thì tự nhiên thành công.
03 Vùng chân không ngoài RLVR
Phân tích trên, cơ bản đã giải đáp câu đố tại sao nó lại hiệu quả.
Dùng SFT cấu thành từ dữ liệu hợp lý, mang lại cho mô hình khả năng phán đoán tổng quát hóa đạo đức.
Nhưng vấn đề chúng ta đối mặt, xa không chỉ là căn chỉnh đạo đức.
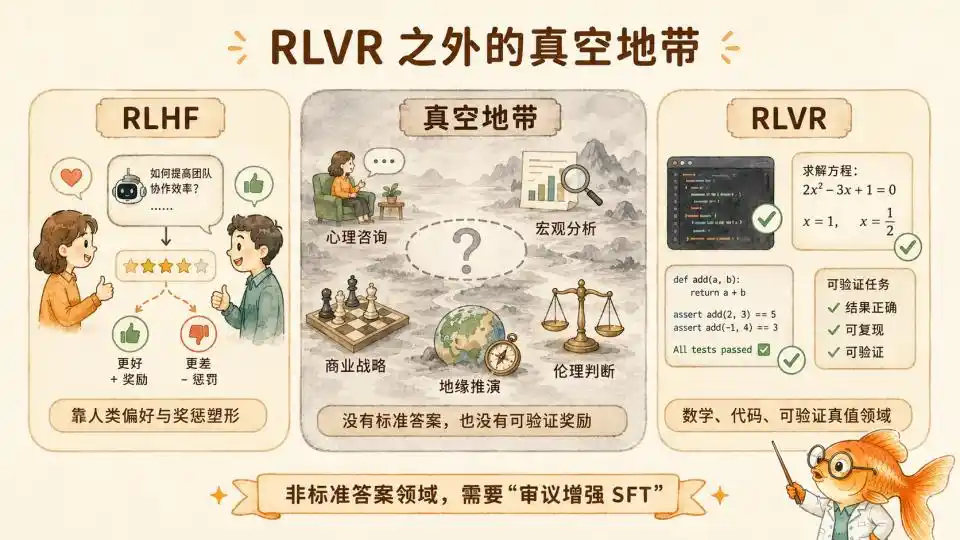
Trong cả năm qua, hậu huấn luyện Test time Compute đã chứng minh sự mạnh mẽ của RL thuần túy trong lĩnh vực toán học/mã có quy tắc rõ ràng (RLVR). Nhưng ranh giới của trí thông minh xa hơn nhiều so với công thức toán học. Một khi bước ra khỏi vùng thoải mái có chân lý có thể xác minh, bộ phương pháp này hoàn toàn không áp dụng được.
Bạn không bao giờ có thể dùng vài dòng mã kiểm tra tự động, để xác minh một cuộc đối thoại tư vấn tâm lý kéo dài một giờ có hoàn hảo hay không. Bạn cũng không thể dùng một bộ công thức toán học chặt chẽ, để thông suốt logic tự sự của một bài viết phân tích kinh tế vĩ mô sâu sắc. Thậm chí trong hoạch định chiến lược thương mại phức tạp và suy diễn địa chính trị, đúng sai của một phán đoán thường phải sau năm năm thậm chí mười năm mới thấy rõ.
Trên những hoang nguyên không RLVR này không có Ground Truth nào có thể nói, CoT logic hình thức đơn hướng tiến lên (one-way progressive formal logic CoT) là vô hiệu. Học tăng cường dựa trên phản hồi kết quả cuối cùng cũng hoàn toàn không tìm thấy điểm bám để tính toán phần thưởng.
Nhưng lĩnh vực mà bài viết của Anthropic tiết lộ, chính là một lĩnh vực ngoài RLVR, tức lĩnh vực đạo đức.
Phương pháp của nó đã thành công khiến mô hình trong lĩnh vực đạo đức xám, đa biến, quy tắc phải linh hoạt, cũng đạt được khả năng tổng quát hóa tương đương với RL.
Điều này có phải chứng minh, bộ phương pháp này, có lẽ có thể trở thành một quy phạm huấn luyện hiệu quả cho các lĩnh vực ngoài RLVR?
Sau khi làm rõ nguồn gốc hiệu quả và cấu trúc dữ liệu của nó, câu trả lời là khẳng định.
Vì trong logic cơ bản của nó không có bất kỳ một khâu nào là độc nhất của căn chỉnh đạo đức.
Hãy kiểm tra lần lượt những điều kiện mà bộ "SFT tăng cường thảo luận" của Anthropic hiệu quả, xem chúng có thể được mở rộng hay không.
Sự đa dạng của Prompt, có thể cấu tạo trong bất kỳ lĩnh vực nào cần tổng quát hóa. Tư vấn tâm lý có thể có vài chục tình huống khác biệt như trầm cảm, lo âu, căng thẳng sau sang chấn, đổ vỡ mối quan hệ thân thiết; phân tích thương mại có thể bao phủ các loại quyết định hoàn toàn khác nhau như định giá SaaS, định giá mua lại, chiến lược thâm nhập thị trường; biên tập văn học có thể trải rộng các thể loại hoàn toàn khác biệt như khoa học viễn tưởng, phi hư cấu, thơ ca, kịch bản. Chỉ cần bạn có đủ trí tưởng tượng để cấu tạo các biến thể tình huống, sự đa dạng không phải là nút thắt.
Giám sát CoT, đây mới là điểm chuyển hóa then chốt thực sự. Trong lĩnh vực đạo đức, CoT là thảo luận được xây dựng trên Hiến pháp. Vậy trong các lĩnh vực khác, CoT là gì?
Trong lĩnh vực biên tập văn học, nó có thể là "trích dẫn tiêu chuẩn biên tập → lần lượt đánh giá cường độ luận cứ, tính dễ bị tổn thương nhận thức của độc giả mục tiêu, độ chính xác của loại suy, tính mạch lạc logic toàn cục → đưa ra đề xuất sửa đổi"
Trong lĩnh vực tư vấn tâm lý, nó có thể là "trích dẫn khung trị liệu → lần lượt đánh giá trạng thái cảm xúc của người đến tư vấn, loại sai lệch nhận thức, cường độ liên minh trị liệu, thời cơ can thiệp → chọn chiến lược phản hồi"
Trong lĩnh vực chiến lược thương mại, nó có thể là "trích dẫn khung phân tích → lần lượt đánh giá quy mô thị trường, rào cản cạnh tranh, khả năng thực thi đội nhóm, hiệu quả vốn, cửa sổ thời gian → đưa ra phán đoán"
Về bản chất, bất kỳ năng lực nào cần "thực hiện cân nhắc động giữa nhiều chiều không thể thông ước", đều có thể được trừu tượng hóa thành cấu trúc "khung + thảo luận đa yếu tố" tương tự.
Chúng ta không cần kiêu ngạo cố gắng nói với mô hình bài viết nào hoàn hảo, điều này vừa không thể vừa không khoa học. Chúng ta chỉ cần tháo rời quá trình ra quyết định của chuyên gia hàng đầu thành chuỗi thảo luận rõ ràng, sau đó phân bố trong đủ đa dạng tình huống.
Miễn là "phản hồi tốt" trong lĩnh vực này có cấu trúc có thể được giải thích bởi quá trình thảo luận. Nghĩa là, lý do chuyên gia đưa ra phán đoán tốt, không phải vì hộp đen trực giác thần bí, mà vì họ đã chạy một quá trình cân nhắc trong đầu có thể được tháo rời, được viết ra. Một nhà tư vấn tâm lý giỏi chọn im lặng thay vì truy vấn, đằng sau là sự đánh giá tổng hợp về cường độ liên minh trị liệu, dung lượng cửa sổ hiện tại của người đến tư vấn, thời cơ can thiệp, những điều này có thể viết ra được.
Ngoài ra, cùng một hình dạng thảo luận có thể lặp lại trong vài trăm tình huống khác biệt. Bộ xương thảo luận là ổn định (dựa vào Hiến pháp), nhưng bề mặt tình huống phải cực kỳ đa dạng. Nếu một lĩnh vực tự nhiên tình huống đơn nhất (ví dụ chỉ có một loại phán đoán), thì trực tiếp dùng RLVR là được.
Và lĩnh vực mà nó phù hợp nhất, nằm ở những tình huống có thể suy diễn ra thông qua Hiến pháp và các yếu tố. Anthropic có thể dùng vòng khép kín Constitutional AI để để mô hình giáo viên tự động sản xuất dữ liệu thảo luận, nhưng trong các lĩnh vực khác, chúng ta phải có thể xây dựng nên một hệ thống Hiến pháp và yếu tố tốt hơn, đảm bảo điểm này.
Do đó điều này thực tế đã thiết lập một mô hình hậu huấn luyện mới phổ dụng, chuyên hướng đến các lĩnh vực không có đáp án tiêu chuẩn.
Công thức của nó là: Hiến pháp lĩnh vực (nguyên tắc cấp cao không thể lay chuyển) + lan can gợi ý + khung thảo luận đa yếu tố + CoT dạng thảo luận (các án lệ tình huống đa dạng chứa đầy đủ quá trình suy diễn) = khả năng tổng quát hóa trong lĩnh vực không phải RLVR.
04 Con đường chưng cất mới
Những bạn có kinh nghiệm kỹ năng viết Skill nhìn đến đây, chắc chắn cảm thấy nhiều hệ thống và quy tắc trong Hiến pháp dường như rất giống với quá trình viết một số Skill của chúng ta.
Tuy nhiên những Skill này thường biểu hiện không tốt.
Trong bài viết trước đây của tôi "Skill rốt cuộc có thể chưng cất bao nhiêu phần của chúng ta", chúng tôi dựa trên khoa học nhận thức đã đưa ra một phán đoán - Skill hoặc System Prompt thuần văn bản, rất khó xử lý sự cân nhắc động liên quan đến môi trường và tình huống phức tạp. Vì điều này liên quan đến tính toán hiệu dụng lớn và ẩn vi tế. Bạn không thể viết toàn bộ trực giác lâm sàng của một nhà tư vấn tâm lý hàng đầu vào một gợi ý, giống như bạn không thể học đi xe đạp bằng cách đọc một cuốn hướng dẫn đi xe đạp.
Nhưng bộ phương pháp của Anthropic, hoàn toàn tránh được vùng mìn này. Họ đang ở thời kỳ huấn luyện tiêu hao năng lực tính toán, dùng vài triệu, vài chục triệu Token dữ liệu chất lượng cao, cưỡng ép đưa logic thảo luận nặng nề này vào bằng cách SFT.
Thông qua khớp nối thô bạo và tinh chỉnh của lượng lớn dữ liệu, mô hình dần nắm vững sự phân phối trọng số của cơ chế thảo luận này trong không gian tiềm ẩn.
Sau khi tiến hành vô số cuộc thảo luận dài dựa trên tám yếu tố và ba lan can trong phòng huấn luyện, những kinh nghiệm này đã không thể đảo ngược mọc vào trong trực giác của mô hình.
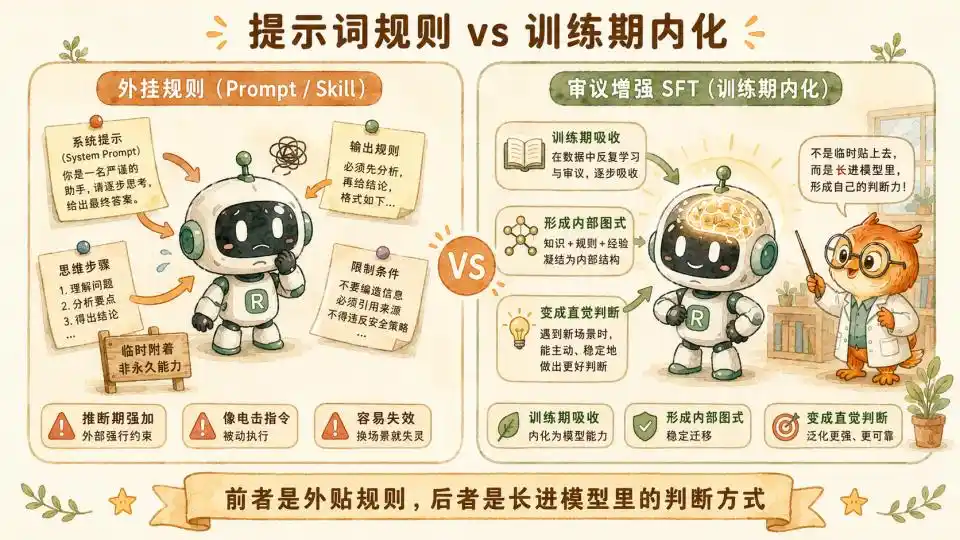
Chưng cất ở cấp độ tham số, ở đây được chứng minh thực sự hiệu quả. Hơn nữa về hình thức rất gần với Skill.
Tính hiệu quả của phương pháp này trong các lĩnh vực khác một khi được xác nhận, kiểu chưng cất ở cấp độ cao hơn này, giống với chuyên gia hơn, sẽ trở thành hiện thực.
Mà con đường này một khi chạy thông, ai có thể cấu tạo ra tập dữ liệu "khung + CoT dạng thảo luận" chất lượng cao nhất, người đó sẽ có được khả năng tổng quát hóa trong lĩnh vực đó.
Điều này đưa sự cạnh tranh hậu huấn luyện từ cuộc chạy đua vũ trang "năng lực tính toán và thuật toán", một phần chuyển hướng sang chiều "biểu đạt có cấu trúc kiến thức lĩnh vực" này.
Đây cũng có thể là lý do tại sao Anthropic và các công ty khác đang tuyển dụng các vị trí như người biết kể chuyện, để giúp xây dựng một loại biểu đạt có cấu trúc hợp lý ngoài lĩnh vực RLVR.
Thời đại chưng cất lớn, mới chỉ bắt đầu.
Bài viết từ tài khoản công chúng WeChat "Tencent Technology", tác giả: Boyang





