Tác giả: Omnitools
Trạm trung chuyển AI đang từ một công cụ trong nhóm nhỏ trở thành lối vào rộng rãi hơn cho các mô hình. Đối với nhiều người dùng, sức hút của nó rất trực tiếp: giá rẻ hơn, nhiều mô hình hơn, giao diện thống nhất, còn có thể kết nối với các công cụ phát triển như Claude Code, Codex, Cursor.
Nhưng vấn đề của trạm trung chuyển cũng nằm ở đây. Người dùng tưởng mình chỉ đổi một địa chỉ API rẻ hơn, nhưng thực tế giao đi có thể là các gợi ý (prompt), mã code, tài liệu nghiệp vụ, tư liệu khách hàng, nhật ký gọi API, thậm chí toàn bộ ngữ cảnh phát triển dự án.
Omnitools cho rằng, thảo luận về trạm trung chuyển AI không nên chỉ dừng lại ở "có dùng được không" hay "nhà nào rẻ nhất". Vấn đề quan trọng hơn là: Nhu cầu đằng sau trạm trung chuyển bắt nguồn từ đâu? Người dùng có thực sự cần nó không? Nếu bắt buộc phải sử dụng, làm thế nào để kiểm soát rủi ro?
1. Nhu cầu thị trường đằng sau trạm trung chuyển
Một kết luận rõ ràng là, trạm trung chuyển phổ biến vì nhu cầu thực sự tồn tại.
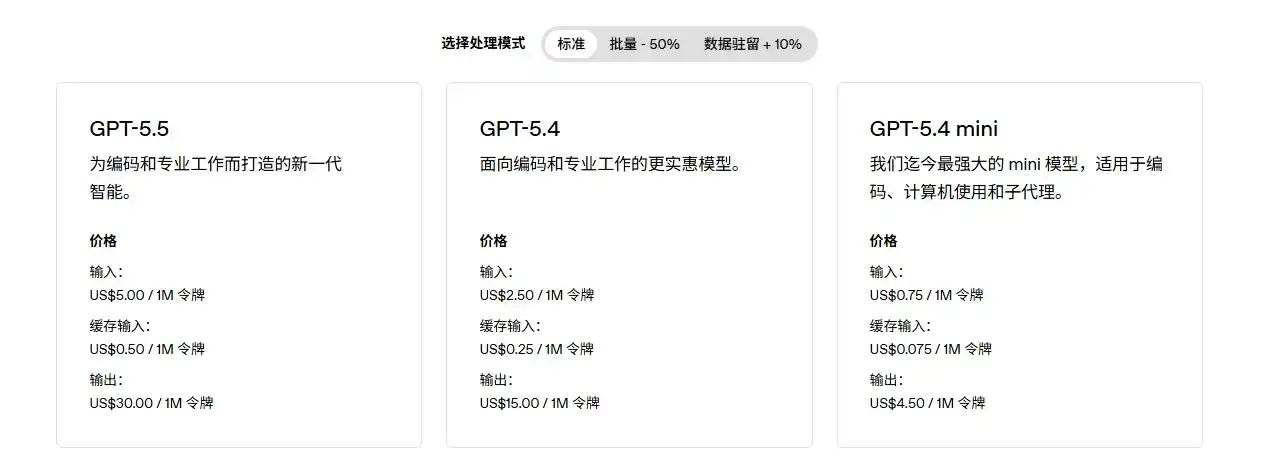
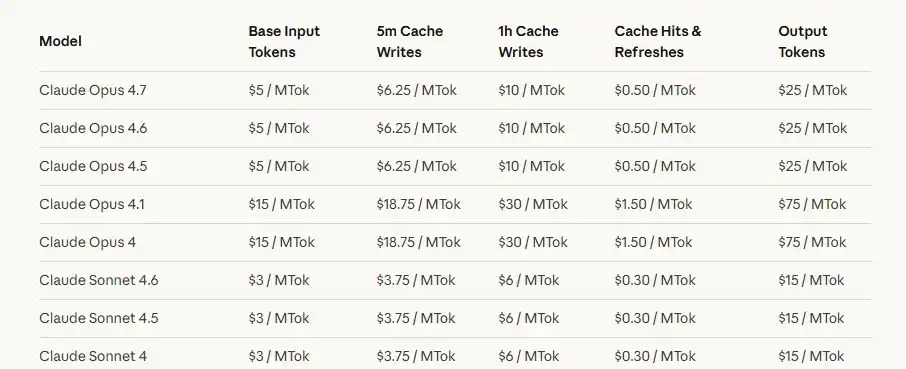
Đầu tiên là ưu thế về giá, API chính thức của các mô hình lớn hàng đầu ở nước ngoài không hề rẻ. Trang giá của OpenAI cho thấy, GPT-5.5 có giá đầu vào là 5 USD cho mỗi triệu Token, giá đầu ra là 30 USD cho mỗi triệu Token; trang giá của Anthropic cho thấy, Claude Sonnet 4.7 có giá đầu vào là 5 USD cho mỗi triệu Token, giá đầu ra là 25 USD cho mỗi triệu Token. Đối với trò chuyện thông thường, chi phí này không rõ ràng, nhưng đối với xử lý văn bản dài, tạo mã code, nhiệm vụ Agent nhiều vòng và quy trình công việc tự động hóa, chi phí gọi API sẽ nhanh chóng trở nên đáng kể.
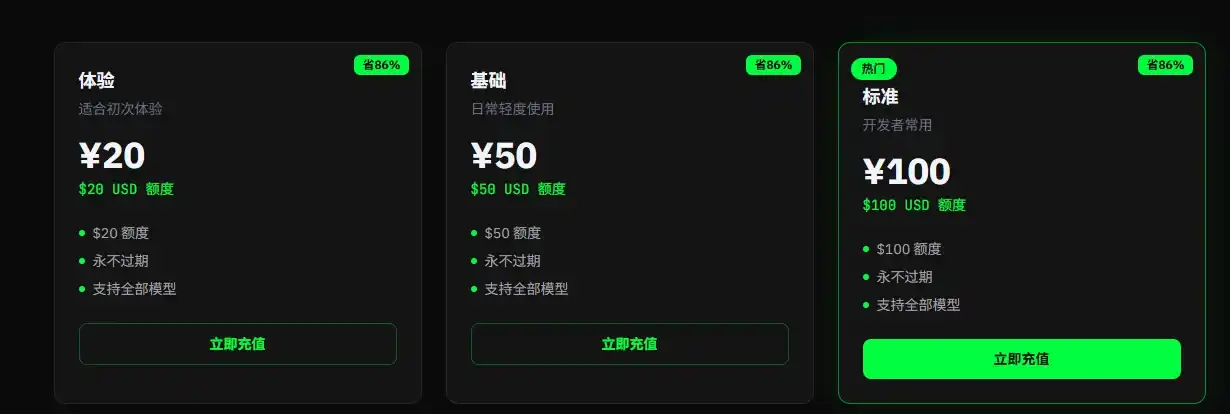
Trong khi đó, điểm bán chính của trạm trung chuyển là giá thấp hơn nhiều so với giá chính thức để truy cập API, ví dụ 1 Nhân dân tệ có thể mua Token trị giá 1 USD, mức giá chiết khấu chỉ khoảng 15% so với giá chính thức. Đối với người dùng có nhu cầu lớn, đây là khoản tiết kiệm chi phí thực tế.
Thứ hai là ngưỡng truy cập. Khi các hạn chế truy cập của các mô hình Mỹ đối với người dùng Trung Quốc đại lục ngày càng khắt khe, ngay cả khi bỏ qua ưu thế về giá, việc muốn sử dụng API chính thức với giá gốc hoặc gói dịch vụ đối với nhiều người dùng cũng tồn tại rào cản xác thực rất cao. Ngoài ra, trong các tình huống sử dụng, nếu người dùng muốn đồng thời sử dụng Claude, GPT, Gemini và các mô hình trong nước, họ phải chuyển đổi giữa nhiều nền tảng. Trạm trung chuyển nén tất cả sự phức tạp này thành một lối vào, giống như "ổ cắm tổng hợp" trong thế giới mô hình AI, người dùng không còn quan tâm phía sau kết nối với đường dây nào, chỉ quan tâm có ổn định hay không.
Thứ ba là sự thúc đẩy của công cụ phát triển. Trước đây, mô hình chủ yếu dùng để hỏi đáp và viết lách; hiện nay, các công cụ như Claude Code, Codex, Cursor đang tích hợp mô hình vào quy trình phát triển cục bộ. Việc gọi mô hình không còn chỉ là một cuộc trò chuyện, mà có thể là một lần kiểm tra mã, một lần tái cấu trúc dự án, một lần sửa lỗi tự động. Ngoài ra, cộng thêm sự xuất hiện của cơn sốt "nuôi tôm hùm", nhu cầu về Token này ngày càng lớn. Nhu cầu càng nặng, người dùng càng dễ tìm kiếm cách thức truy cập rẻ hơn, hạn mức cao hơn, thống nhất hơn.
Do đó, việc kinh doanh trạm trung chuyển sôi động được thúc đẩy bởi nhu cầu thực tế, không phải một cơn sốt khác.
2. Bạn có thực sự cần trạm trung chuyển không?
Tuy nhiên, không phải ai cũng cần dùng đến trạm trung chuyển.
Nếu chỉ thỉnh thoảng hỏi vài câu, dịch văn bản, tóm tắt tài liệu công khai, viết một đoạn văn bản thông thường, nhiều khi không cần đến trạm trung chuyển. ChatGPT, Gemini, Antigravity và các mô hình, công cụ khác đều có hạn mức miễn phí, nếu không giải quyết được vấn đề xác thực và tài khoản, bạn cũng có thể chọn nhiều bộ tổng hợp mô hình lớn, một số cũng có hạn mức miễn phí để đáp ứng nhu cầu sử dụng hàng ngày.
Đối với người dùng nhẹ, thay vì vì "rẻ" mà giao dữ liệu cho trạm trung chuyển không rõ ràng, tốt hơn hết nên sử dụng hết hạn mức miễn phí của các công cụ chính thức và hợp quy trước. Hạn mức miễn phí có thể thay đổi, các hạn chế cụ thể nên dựa trên trang chính thức của từng nền tảng, nhưng nguyên tắc này sẽ không thay đổi: nhu cầu tần suất thấp không cần vội vàng sử dụng trung chuyển.
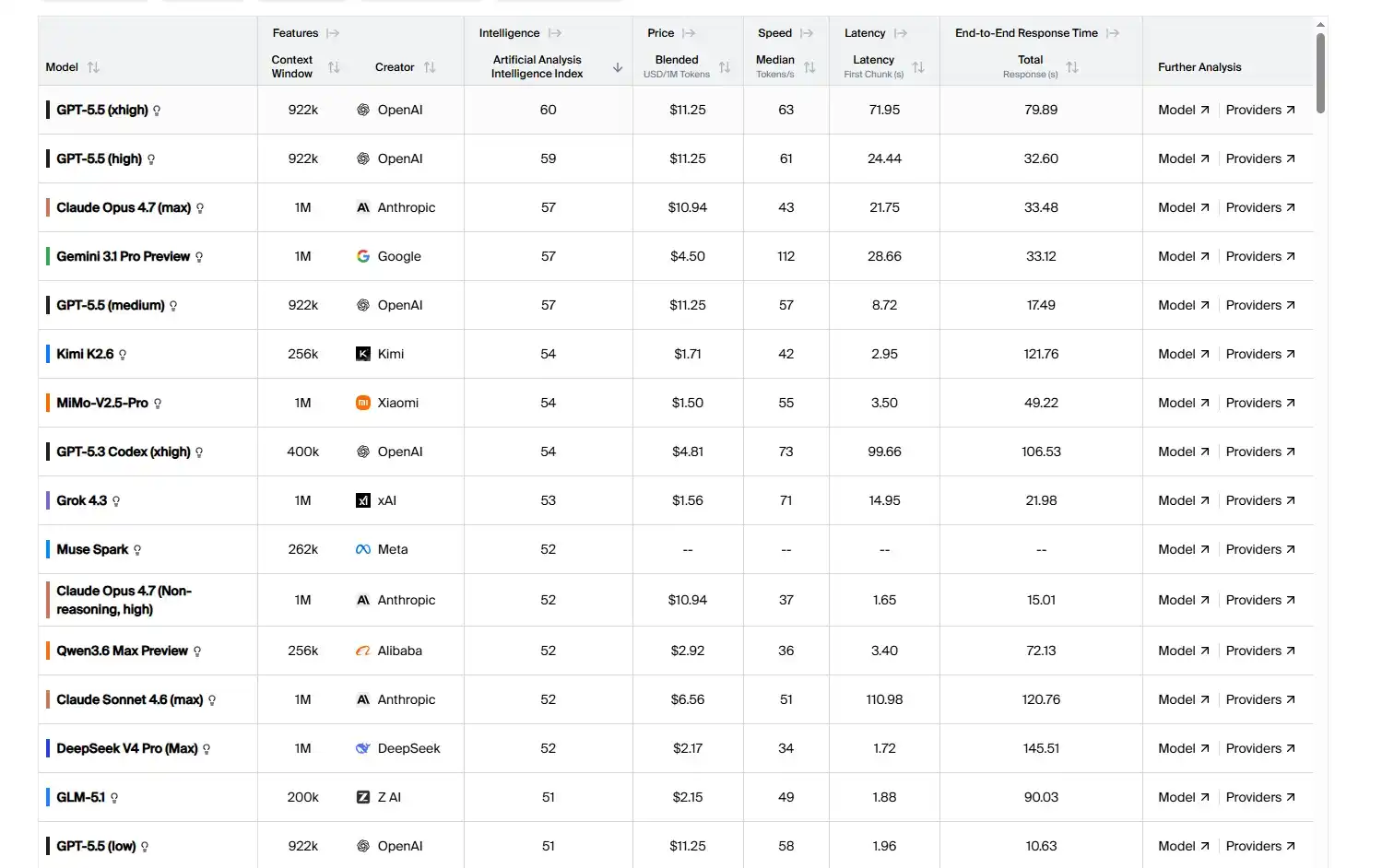
Nếu là người dùng lập trình nặng, thường cũng không nhất thiết phải giao tất cả nhiệm vụ cho mô hình đắt tiền hoặc trạm trung chuyển. Một cách an toàn hơn là sử dụng mô hình phân tầng: dùng mô hình lớn mạnh hơn để phân tích yêu cầu, lộ trình kỹ thuật, thiết kế kiến trúc và kiểm tra mã; sau đó dùng mô hình trong nước giá rẻ để hoàn thành phát triển chức năng cụ thể hơn, vận hành hàng ngày, v.v. Và với sự đuổi kịp không ngừng của các mô hình trong nước, trong quá trình đối phó với phát triển hàng ngày, khả năng của nhiều mô hình trong nước đã không kém gì các mô hình đỉnh cao của Mỹ, và giá có thể còn rẻ hơn nhiều so với trạm trung chuyển. Lấy ví dụ Kimi K2.6, giá đầu ra cho mỗi triệu Token là 4 USD, chỉ bằng 13% của ChatGPT 5.5, mức giá này cũng thấp hơn giá của nhiều trạm trung chuyển.
Tất nhiên, cách này không hoàn hảo, nhưng phù hợp hơn với cấu trúc chi phí. Nhiệm vụ phức tạp nhất cần là khả năng phán đoán hướng đi và khung, việc triển khai cụ thể có thể chia thành nhiều nhiệm vụ nhỏ rủi ro thấp, chi phí thấp. Đối với các nhà phát triển cá nhân và nhóm nhỏ, việc chia nhỏ nhiệm vụ trước, sau đó quyết định khâu nào cần mô hình cao cấp, thường hợp lý hơn việc mua hạn mức trung chuyển lớn trực tiếp.
Chỉ khi người dùng đã có nhu cầu gọi đa mô hình liên tục, tần suất cao, ví dụ sử dụng lâu dài công cụ lập trình AI, xử lý lượng lớn tài liệu công khai, so sánh mô hình, xây dựng quy trình tự động hóa nội bộ, và hạn mức chính thức rõ ràng không đủ dùng, trạm trung chuyển mới có thể trở thành một lựa chọn dự phòng. Ngay cả như vậy, nó cũng nên là "công cụ sau khi sàng lọc", chứ không phải lối vào mặc định.
3. Chọn và sử dụng trạm trung chuyển như thế nào?
Nếu sau khi đánh giá xác nhận cần trạm trung chuyển, vấn đề tiếp theo không còn là "có dùng hay không", mà là "dùng thế nào để không gặp sự cố". Dưới đây là một quy trình thao tác đầy đủ từ đánh giá đến sử dụng hàng ngày.
Bước 1: Xác minh trước, nạp tiền sau
Sau khi có địa chỉ trạm trung chuyển, đừng vội nạp tiền. Hãy làm ba việc trước:
Xác minh tính xác thực của mô hình. Sử dụng cùng một Prompt để gọi lần lượt trạm trung chuyển và API chính thức, so sánh chất lượng đầu ra, định dạng phản hồi, lượng Token sử dụng có giống nhau không. Một số trạm trung chuyển có thể dùng mô hình phiên bản thấp mạo nhận phiên bản cao, hoặc tiêm thêm gợi ý hệ thống vào đầu ra. Một phương pháp kiểm tra đơn giản là để mô hình tự báo cáo thông tin phiên bản, sau đó so sánh chéo với hành vi chính thức, mặc dù điều này không thể chống giả hoàn toàn, nhưng có thể sàng lọc các nền tảng rõ ràng không ổn.
Kiểm tra độ trễ và độ ổn định. Gọi liên tục 20-50 lần, quan sát có thường xuyên quá thời gian, báo lỗi ngẫu nhiên hay biến động chất lượng phản hồi không. Đường truyền của trạm trung chuyển nhiều hơn một lớp so với kết nối trực tiếp, nếu độ ổn định cơ bản không đạt, các vấn đề gặp phải trong quá trình sử dụng sau này sẽ chỉ nhiều hơn.
Kiểm tra chất lượng tài liệu. Một trạm trung chuyển vận hành nghiêm túc thường cung cấp tài liệu API đầy đủ, hướng dẫn truy cập tương thích định dạng OpenAI, danh sách mô hình và bảng giá rõ ràng. Nếu một nền tảng ngay cả tài liệu cũng chắp vá, hoặc danh sách mô hình mơ hồ, cần phải cảnh giác cao độ.
Bước 2: Cấu hình cách ly, không trộn lẫn
Sau khi xác nhận nền tảng cơ bản có thể sử dụng, tiếp theo là cách ly về mặt kỹ thuật. Bước này nhiều người dùng bỏ qua, nhưng nó quyết định phạm vi thiệt hại khi xảy ra sự cố.
Sử dụng API Key độc lập. Đừng điền Key bạn đăng ký trên nền tảng chính thức trực tiếp vào trạm trung chuyển, cũng đừng dùng chung một Key giữa nhiều trạm trung chuyển. Tạo Key độc lập cho mỗi trạm trung chuyển, một khi nền tảng nào đó gặp sự cố, có thể lập tức vô hiệu hóa mà không ảnh hưởng đến các dịch vụ khác.
Quản lý khóa qua biến môi trường. Trong môi trường phát triển cục bộ, lưu API Key vào file .env hoặc biến môi trường hệ thống, đừng mã hóa cứng vào code. Lấy ví dụ Cursor, khi điền API Base URL và Key trong cài đặt, xác nhận các cấu hình này sẽ không được commit vào kho Git. Nếu sử dụng các công cụ dòng lệnh như Claude Code hoặc Codex, kiểm tra file cấu hình shell của bạn, đảm bảo Key không xuất hiện trong lịch sử kiểm soát phiên bản.
Đặt giới hạn sử dụng. Hầu hết các trạm trung chuyển hợp quy hỗ trợ đặt hạn mức Token hàng tháng hoặc giới hạn chi tiêu. Việc đầu tiên sau khi nạp tiền là đặt giới hạn. Đây không chỉ là kiểm soát chi phí, mà còn là an toàn dự phòng, nếu Key của bạn bị rò rỉ ngoài ý muốn, giới hạn sử dụng có thể hạn chế thiệt hại.
Bước 3: Thiết lập thói quen phân cấp dữ liệu
Sau khi cấu hình kỹ thuật xong, điều quan trọng nhất trong sử dụng hàng ngày là đánh giá nhanh phân cấp dữ liệu cho mỗi lần gọi. Không cần mỗi lần viết một báo cáo an toàn, nhưng cần hình thành thói quen kiểm tra phản xạ có điều kiện.
Trước khi gửi, hãy tự hỏi một câu: Nếu nội dung này ngày mai xuất hiện trên một diễn đàn công khai nào đó, tôi có thể chấp nhận được không?
Nếu câu trả lời là "có thể", ví dụ tóm tắt tài liệu công khai, dịch thuật thông thường, thảo luận kỹ thuật dự án mã nguồn mở, phân tích tài liệu công khai, thì có thể sử dụng trạm trung chuyển trực tiếp.
Nếu câu trả lời là "không thực sự có thể, nhưng thiệt hại có thể kiểm soát", ví dụ biên bản họp nội bộ, bản nháp tài liệu thương mại, mẫu giao tiếp khách hàng, đoạn mã code, thì trước khi gửi hãy làm một vòng khử thông tin nhạy cảm. Cách làm cụ thể là: thay thế tên người bằng mã vai trò ("Khách hàng A", "Đồng nghiệp B"), thay thế số tiền cụ thể bằng tỷ lệ hoặc phạm vi, thay thế số hiệu nội bộ bằng ký tự giữ chỗ, xóa địa chỉ kết nối cơ sở dữ liệu, điểm cuối API nội bộ và mô tả logic nghiệp vụ chưa công khai. Quá trình này không cần quá lâu, thường một hai phút là đủ, nhưng nó có thể giảm rủi ro từ "có thể xảy ra sự cố" xuống "về cơ bản có thể kiểm soát".
Nếu câu trả lời là "tuyệt đối không thể", ví dụ khóa riêng tư, cụm từ ghi nhớ, khóa môi trường sản xuất, mật khẩu cơ sở dữ liệu, dữ liệu tài chính chưa công khai, thông tin riêng tư khách hàng, kho mã nguồn riêng tư hoàn chỉnh, thì đừng giao cho bất kỳ trạm trung chuyển nào, bất kể nó tuyên bố an toàn đến đâu.
Bước 4: Công cụ lập trình AI cần đối xử riêng biệt
Điều này đáng được nhấn mạnh riêng, vì phạm vi phơi nhiễm dữ liệu của công cụ lập trình AI lớn hơn nhiều so với hội thoại thông thường.
Khi bạn kết nối trạm trung chuyển trong các công cụ như Cursor, Claude Code, Cline, mô hình nhận được không chỉ là gợi ý bạn chủ động nhập, mà còn có thể bao gồm: nội dung file đang mở, cấu trúc thư mục dự án, lịch sử đầu ra terminal, file cấu hình phụ thuộc (như package.json, requirements.txt), bản ghi commit Git, cũng như đường dẫn file và tên biến môi trường trong thông báo lỗi.
Điều này có nghĩa là một lần "giúp tôi sửa lỗi này" tưởng như bình thường, lượng dữ liệu thực tế gửi cho trạm trung chuyển có thể vượt xa dự kiến của bạn.
Đề xuất thao tác: Khi sử dụng trạm trung chuyển trong công cụ lập trình AI, ưu tiên xử lý các nhiệm vụ mã code độc lập, không liên quan đến nghiệp vụ cốt lõi. Nếu bắt buộc phải xử lý mã code liên quan đến kho riêng tư hoặc môi trường sản xuất, có hai cách làm tương đối an toàn: một là chỉ dán các đoạn mã đã khử thông tin nhạy cảm, thay vì để công cụ đọc trực tiếp toàn bộ dự án; hai là chuyển việc phát triển dự án nhạy cảm về API chính thức hoặc mô hình cục bộ, dự án không nhạy cảm mới đi qua trạm trung chuyển. Cả hai cách đều không hoàn hảo, nhưng tốt hơn nhiều so với việc giao toàn bộ ngữ cảnh phát triển cho bên trung gian thứ ba một cách không phân biệt.
Bước 5: Giám sát liên tục, chuẩn bị thoát
Sử dụng trạm trung chuyển không phải là quyết định một lần, mà là một quá trình đánh giá liên tục.
Kiểm tra định kỳ bản ghi trừ tiền. Xác nhận mức tiêu hao Token khớp với lượng sử dụng thực tế của bạn. Nếu lượng sử dụng trong một khoảng thời gian không tăng rõ rệt, nhưng tốc độ trừ tiền nhanh hơn, có thể nền tảng đã điều chỉnh quy tắc tính phí, hoặc Key của bạn tồn tại gọi bất thường.
Theo dõi thông báo nền tảng và phản hồi cộng đồng. Trạng thái vận hành của trạm trung chuyển có thể thay đổi bất cứ lúc nào, điều chỉnh kênh cung cấp phía trên, thay đổi chính sách hạn mức, dịch vụ đột ngột ngừng hoạt động đều có thể xảy ra. Nếu bạn phụ thuộc vào một trạm trung chuyển nào đó làm phương thức truy cập chính, ít nhất phải có một phương án dự phòng. Đề xuất đồng thời đăng ký 2-3 nền tảng, duy trì mức nạp tiền tối thiểu, tránh tập trung tất cả các gọi vào một kênh duy nhất.
Đảm bảo có thể di chuyển. Khi cấu hình trạm trung chuyển, sử dụng giao diện tiêu chuẩn định dạng tương thích OpenAI, như vậy khi chuyển đổi nền tảng thường chỉ cần sửa Base URL và API Key, không cần thay đổi logic code. Nếu dự án của bạn liên kết sâu với giao diện riêng hoặc chức năng đặc biệt của một trạm trung chuyển nào đó, chi phí di chuyển sẽ tăng mạnh, đây cũng là một rủi ro cần cân nhắc trước.
Xét cho cùng, trạm trung chuyển là công cụ, không phải niềm tin. Giá trị của nó nằm ở việc dùng chi phí có thể kiểm soát để giải quyết nhu cầu truy cập thực tế, nhưng "có thể kiểm soát" này cần bạn tự định nghĩa và duy trì, thông qua xác minh, cách ly, phân cấp, xử lý chuyên biệt và giám sát liên tục, để giữ quyền chủ động trong tay mình.






