Không ngờ cái tát vào mặt lại đến nhanh đến thế!!
Vừa qua, UC Berkeley đã công bố một bài kiểm tra chuẩn mới toanh, được mệnh danh là “Kỳ thi cuối cùng của tác nhân thông minh”.
Họ đưa những AI Agent mạnh nhất hiện nay vào phòng thi, bắt chúng làm những việc thực sự——
Tạo mô hình 3D trong Siemens NX, dựng cảnh game trong Unreal Engine, làm hiệu ứng kết hợp trong Adobe After Effects.
Kết quả khiến người ta sửng sốt:
Ở mức khó nhất, Claude Fable 5 và GPT 5.5 vốn được công nhận là mạnh nhất hiện nay, đều nhận điểm số không tròn trĩnh.
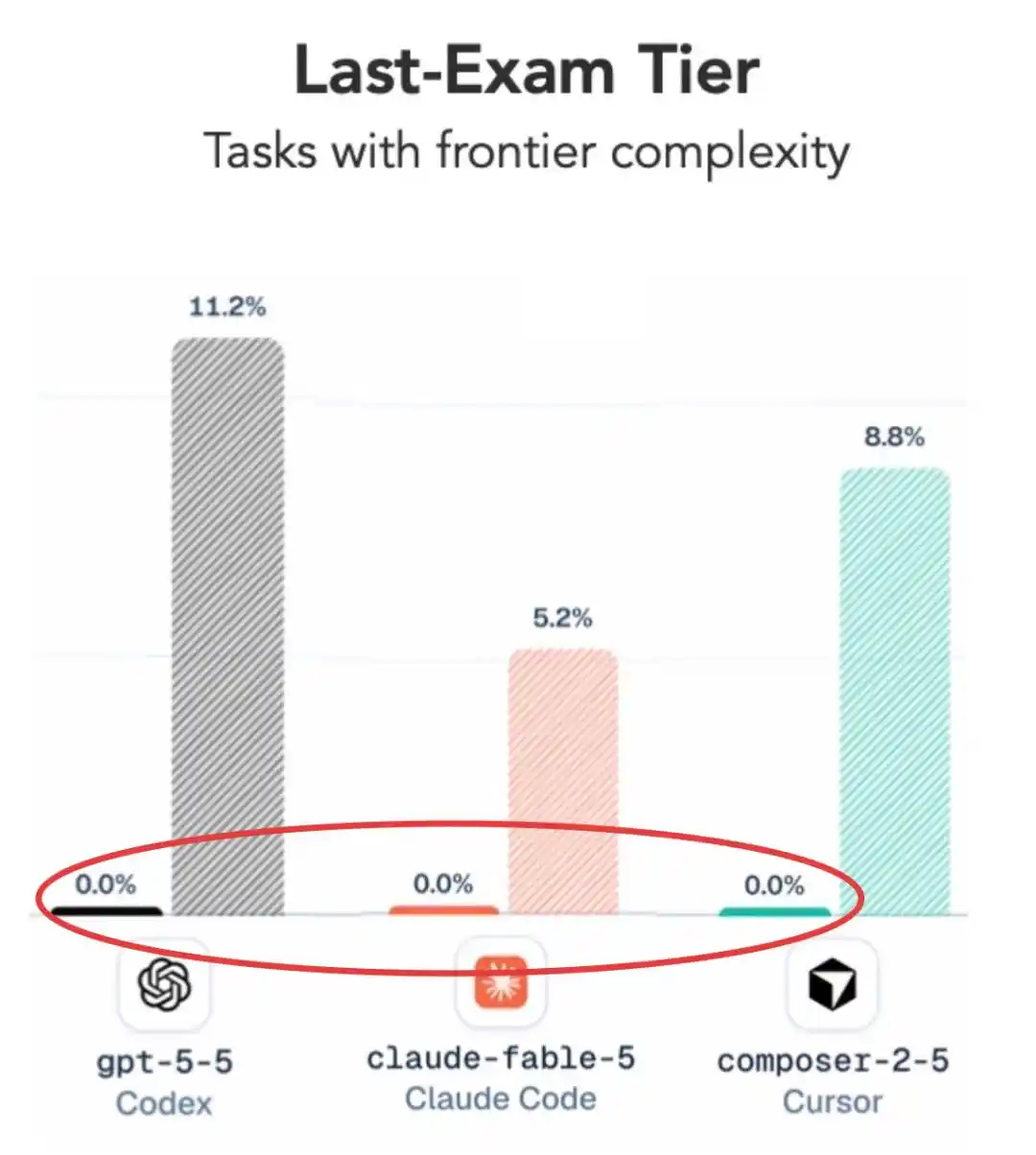
Nếu giảm độ khó một chút thì sao? Điểm số đã có, nhưng kết quả cũng khá bất ngờ——
GPT 5.5 thậm chí còn thắng nhẹ Claude Fable 5.
Tôi không nghe nhầm chứ, Claude Fable 5 - mô hình mạnh nhất vừa được A phát hành, lại bị GPT 5.5 từ vài tháng trước đánh bại??
Cần biết rằng trên hầu hết các benchmark chủ đạo trước đây, Fable 5 đều áp đảo GPT 5.5——80.3% so với 58.6% trên SWE-Bench Pro, 64.5% so với 52.2% trên Humanity’s Last Exam.
Nhưng khi chuyển sang kỳ thi “làm việc thực tế” này, tình thế lại đảo ngược.
Benchmark mới này tên là Agents’ Last Exam (ALE), đội ngũ phía sau có tiếng, trước đây các benchmark quen thuộc như MMLU, MATH, CyberGym, ExploitGym đều do họ đề xuất.
Việc đặt tên này có lẽ cũng tham khảo từ “Humanity’s Last Exam” (Kỳ thi cuối cùng của loài người) của Scale AI trước đây, chỉ có điều lần này đối tượng được kiểm tra không phải là giới hạn kiến thức của con người, mà là giới hạn làm việc của AI Agent.
Phải nói rằng, bài đánh giá này vừa ra mắt, những người ngày ngày hô hào “Agent sẽ thay thế công việc của con người” giờ thực sự im lặng...
“Kỳ thi cuối cùng của tác nhân thông minh”, người chiến thắng lại là GPT 5.5!
Trước tiên hãy xem bảng xếp hạng đầy đủ.
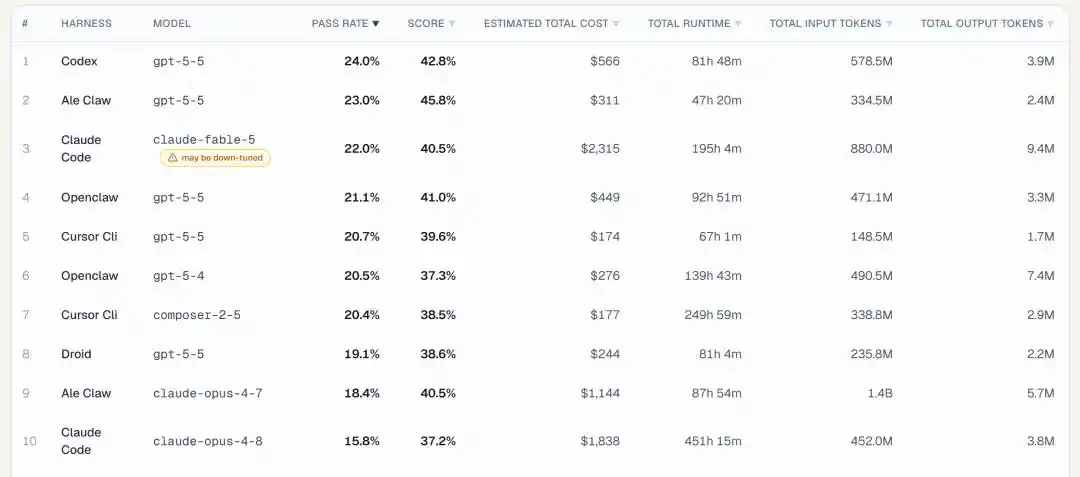
Xét từ chỉ số tỷ lệ hoàn thành nhiệm vụ cốt lõi nhất, GPT 5.5 trực tiếp chiếm giữ quán quân và á quân:
Vị trí thứ nhất là GPT 5.5 kết hợp với framework Codex của chính OpenAI, tỷ lệ hoàn thành 24.0%.
Vị trí thứ hai vẫn là GPT-5.5, chỉ là đổi sang framework ALE Claw, tỷ lệ hoàn thành 23.0%.
(ALE Claw là một Agent baseline do đội ngũ tự viết, tham gia thi đấu song song với các framework thương mại như Codex, Claude Code, Cursor CLI)
Mãi đến vị trí thứ ba, chúng ta mới thấy bóng dáng của Claude Fable 5——kết hợp với Claude Code, đạt tỷ lệ hoàn thành 22.0%.

Nhìn xuống dưới càng thú vị hơn.
Vị trí thứ 4, thứ 5, thứ 8 đều là GPT 5.5, chỉ là đổi framework khác nhau.
Trong top 10, GPT 5.5 xuất hiện 5 lần, cộng với GPT 5.4 ở vị trí thứ 6, các mô hình của OpenAI chiếm trọn 6 vị trí.
Còn gia đình Claude thì sao?
Fable 5 lấy vị trí thứ 3, Opus 4.7 vị trí thứ 9 (18.4%), Opus 4.8 đáy bảng vị trí thứ 10 (15.8%), thế bất lợi hiện rõ.
Cũng không trách các nhà nghiên cứu OpenAI vui vẻ đăng bài, hân hoan đón năm mới:
Ngoài thành tích ra, ở đây còn có vài tín hiệu đáng suy ngẫm sau.
Một là trần nhà thấp đến kinh ngạc.
Tỷ lệ hoàn thành của quán quân mới chỉ 24%, điểm tổng hợp cao nhất cũng chỉ 45.8%.
Có nghĩa là, ngay cả khi tính theo tiêu chí “điểm từng phần” khoan hồng nhất, Agent mạnh nhất cũng chỉ lấy được chưa đến một nửa số điểm.
Mà những đề này đều đến từ các dự án đã được chuyên gia thực thụ hoàn thành——tỷ lệ hoàn thành của chuyên gia con người về lý thuyết là 100%.
Hai là Claude đốt tiền kinh khủng.
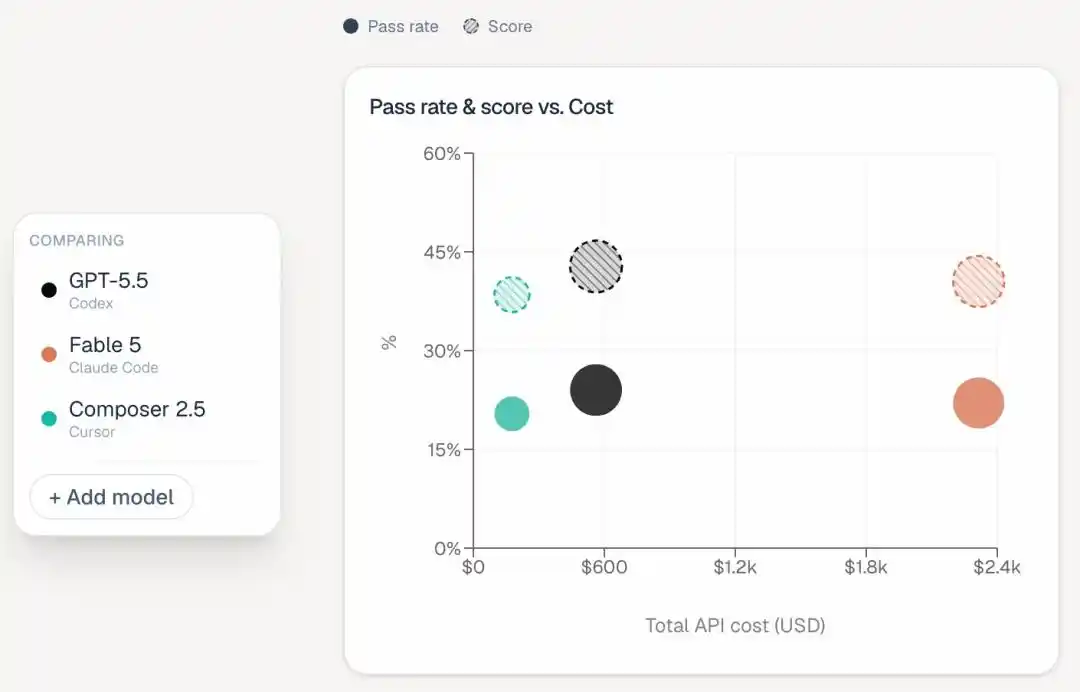
Bảng xếp hạng này đã thêm một cột “Estimated Total Cost”, ngay lập tức kéo ra khoảng cách giàu nghèo:
Fable 5 chạy hết toàn bộ nhiệm vụ tốn 2315 đô la, Opus 4.8 tốn 1838 đô la, Opus 4.7 cũng mất 1144 đô la.
Còn phía GPT-5.5 thì sao?
Codex đắt nhất cũng chỉ 566 đô la, Cursor CLI chỉ 174 đô la.
Tương đương với việc, Fable 5 tiêu gấp hơn bốn lần tiền của Codex, thành tích lại thấp hơn hai phần trăm.
Ba là khoảng cách hiệu suất cũng đáng chú ý.
ALE Claw chạy hết toàn bộ nhiệm vụ mất 47 giờ 20 phút, Cursor CLI chỉ mất 67 giờ.
Còn Opus 4.8 thì sao? 451 giờ——gần 19 ngày.
Làm ít việc nhất, tốn thời gian dài nhất, thu tiền nhiều nhất (lại thực sự có mô hình nào làm được cả ba điều này?)
Tất nhiên nếu chỉ xét Claude Fable 5 và GPT 5.5 hai cái đỉnh nhất, lợi thế thời gian của GPT 5.5 vẫn rõ ràng.

Mà con số gây chú ý nhất, vẫn là số không đó.
ALE chia nhiệm vụ thành ba mức độ khó:
Near-Term (Có thể giải trong thời gian gần)
Full-Spectrum (Bao phủ toàn diện)
Last-Exam (Bài toán tối thượng)
Ở mức khó nhất này, tỷ lệ hoàn thành trung bình của tất cả cấu hình chủ đạo chỉ có 2.6%, hầu hết các mô hình bao gồm cả GPT 5.5 và Fable 5 trực tiếp ăn trứng ngỗng.
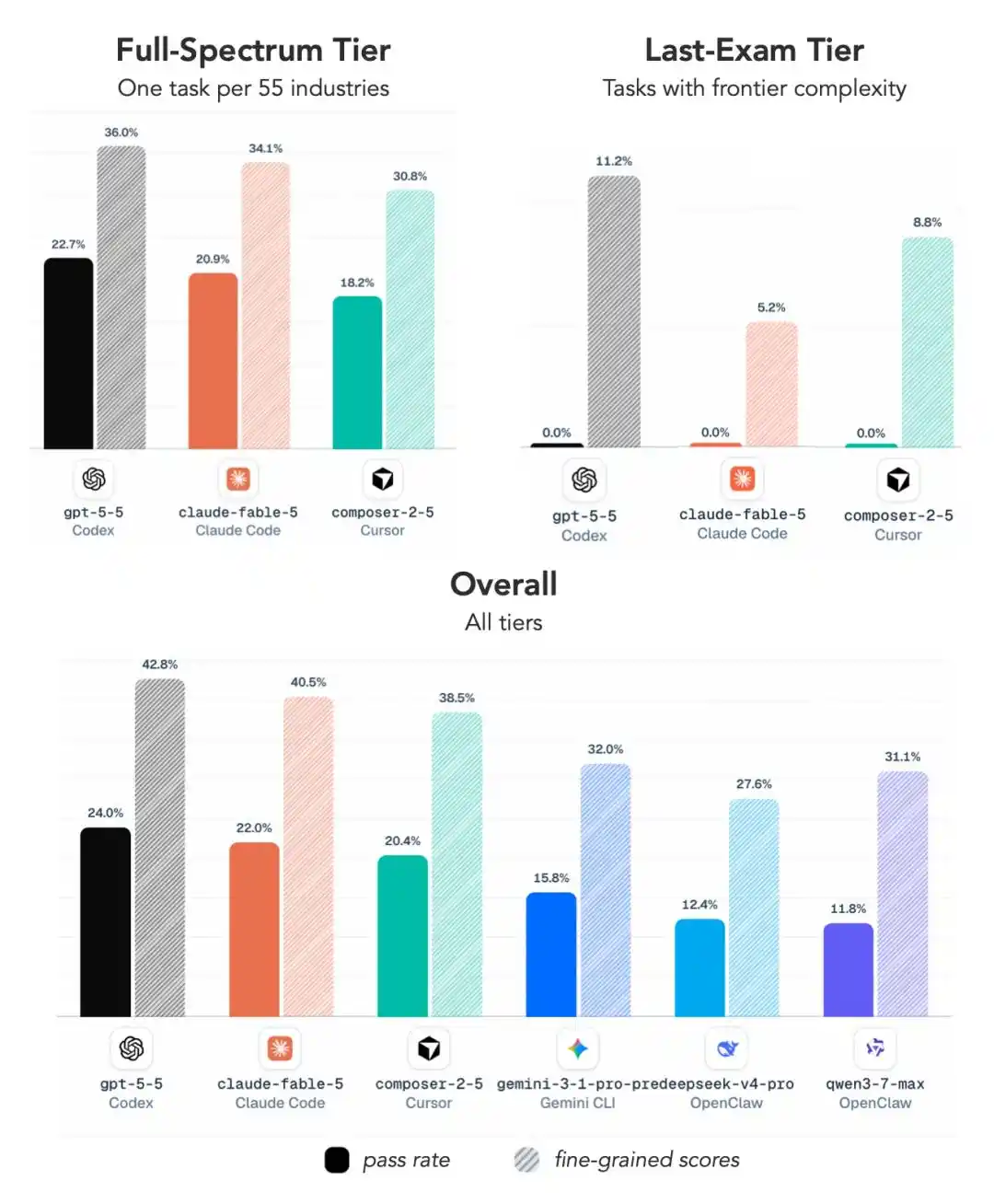
Vì vậy thông tin cốt lõi của bảng điểm này rất đơn giản: Đừng xem thành tích thi cử tốt, đến khi làm việc thực tế thì lộ hết tẩy.
Học bá trả lời đề ≠ người làm việc giỏi, câu này trong thế giới AI cũng áp dụng được.
ALE là gì?
Để hiểu tại sao ALE có thể đánh bật lũ “học bá” này về nguyên hình, trước tiên phải xem nó khác với các kỳ thi trước đây như thế nào.
Humanity’s Last Exam (HLE) trước đây vào đầu năm 2025 do Dan Hendrycks và Scale AI tạo ra, 2500 câu hỏi khó liên ngành, bản chất vẫn là thi đóng đề——
Đưa cho bạn một vấn đề, bạn cho tôi một đáp án, dù khó đến đâu cũng chỉ là truy xuất kiến thức tĩnh.
Mà ALE hoàn toàn khác, nó kiểm tra bạn “có thể làm được gì”.
Tác giả chính Yiyou Sun nói trên X rất thẳng thắn:
AI Agent sẽ vượt qua con người hoàn thành hầu hết mọi công việc vào năm 2026-2027——dự đoán này ở khắp nơi. Vì vậy chúng tôi tạo ra kỳ thi này để kiểm chứng tuyên bố đó.

Mỗi câu hỏi của ALE đều đến từ một dự án đã được chuyên gia thực thụ hoàn thành, bao phủ 55 lĩnh vực con ngành, bao gồm giao dịch định lượng, phân tích hệ gen, kỹ thuật hàng không vũ trụ, thiết kế kiến trúc, chụp ảnh não, hiệu ứng hoạt hình, nghiên cứu pháp lý......
Toàn bộ hệ thống neo theo tiêu chuẩn phân loại nghề nghiệp liên bang Mỹ (ONET)*, nói thẳng ra là ra đề theo “thị trường lao động thực tế”.
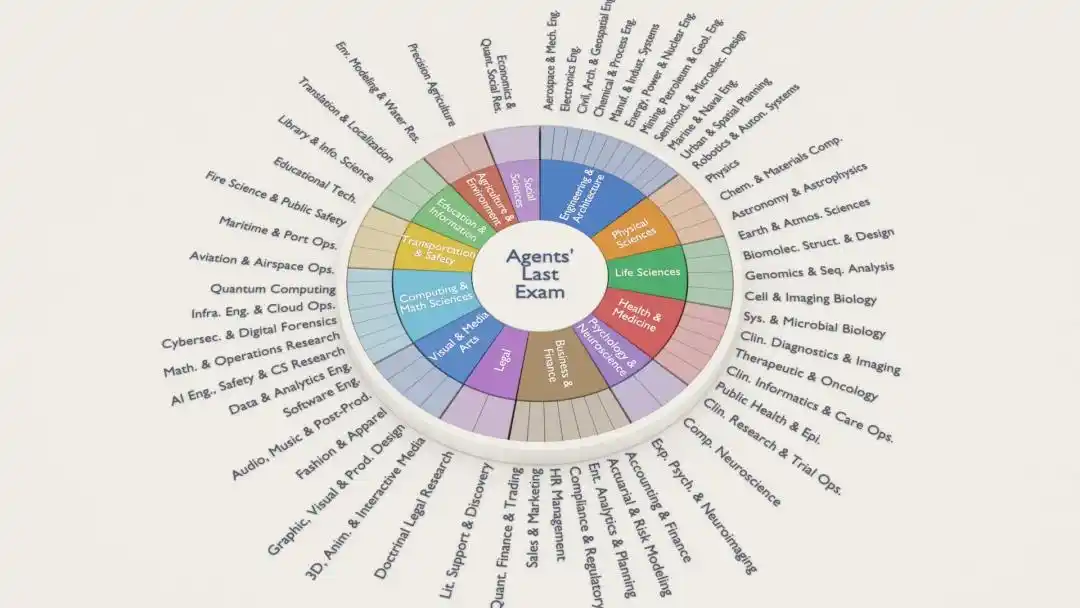
Đội ngũ tham gia ra đề cũng đủ hào nhoáng:
Hơn 300 chuyên gia lĩnh vực đến từ hơn 100 tổ chức, phía học thuật có MIT, Harvard, Stanford, Oxford, Caltech, ETH Zurich, phía công nghiệp có Goldman Sachs, JPMorgan, Meta, Amazon, Adobe, Oracle.
Snorkel AI thông qua dự án Open Benchmarks Grants cung cấp hỗ trợ tài chính.
Hình thức thi cũng không phải gõ chữ trả lời câu hỏi, mà là trực tiếp thao tác máy tính.
ALE sử dụng cái gọi là framework GCUA (Generalist Computer-Use Agent, Tác nhân sử dụng máy tính đa năng), cấp cho Agent đầy đủ quyền GUI và dòng lệnh——
Nhấp chuột, gõ phím, viết script, duyệt web, con người làm được gì trên máy tính thì nó đều làm được.
Không giới hạn phương pháp, chỉ xem kết quả.
“Bài tập” nộp lên được chấm điểm tự động bằng mã xác định.
Không cảm tính. Không có giám khảo con người. Hoàn toàn có thể tái lập.

Điều này đã chặn đứng một nhược điểm cũ của nhiều benchmark trước đây: Bộ chấm điểm tự nó có thể bị lừa.
Ngoài ra, ALE trong việc phòng chống gian lận còn có một chiêu độc——
Chỉ công khai khoảng 10% đề (khoảng 150 câu), hơn 1300 câu còn lại được bảo mật nghiêm ngặt.
Đề công khai và đề bí mật định kỳ luân chuyển thay đổi, đảm bảo không có mô hình nào vì “học tủ” mà đạt điểm cao.
Trong bối cảnh ô nhiễm dữ liệu benchmark tràn lan hiện nay, đây có thể coi là một thiết kế khá tinh tế.
Nhìn chung, so với các bài kiểm tra chuẩn Agent hiện có, định vị của ALE rất rõ ràng.
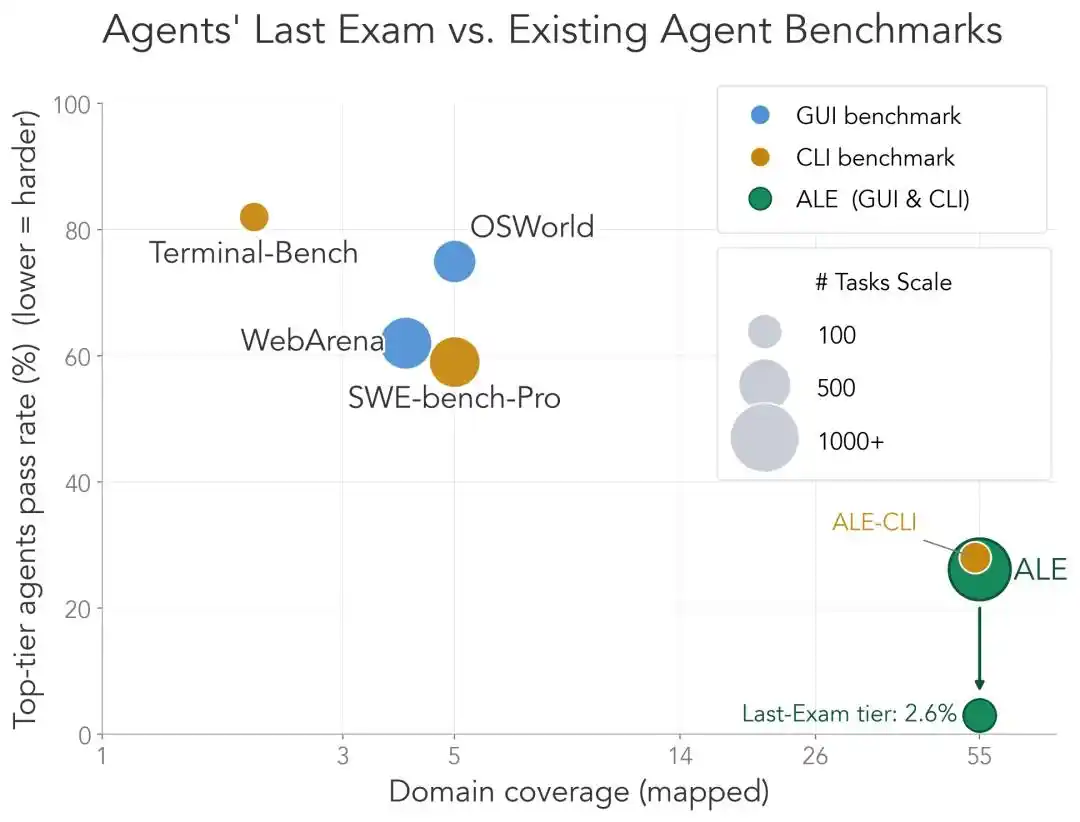
Thành viên nhóm Dawn Song đặc biệt đưa ra một bộ so sánh:
Tập con CLI của ALE (ALE-CLI) bao phủ 40 lĩnh vực con ngành, trong khi Terminal-Bench chỉ có 6, SWE-bench-Pro chỉ có 5;
Thời gian con người hoàn thành những nhiệm vụ này từ vài giờ đến vài tuần, trong khi hai cái sau là vài phút đến vài ngày;
Tỷ lệ hoàn thành của Agent mạnh nhất trên ALE-CLI chỉ có 25.2%, trong khi trên Terminal-Bench là 82.0%, trên SWE-bench-Pro là 59.1%.
Tóm lại một câu, các kỳ thi khác đã sắp bị làm thủng, còn ALE thì còn rất xa.
Đây là lý do ALE dám tự xưng là “Kỳ thi cuối cùng của tác nhân thông minh”.
Đáng chú ý là, Dawn Song còn chia sẻ hai quan sát thú vị:
Một là, Agent sẽ tuyên bố hoàn thành mà không thực sự xác minh kết quả công việc, đây là kiểu thất bại điển hình nhất của các Agent.
Nhiều khi, mặc dù chúng nói “Xong. Tất cả kiểm tra đều đạt.”
Nhưng sản phẩm thực tế có thể thiếu file cần thiết, tính toán số sai, bỏ sót trường quan trọng, hoặc trực tiếp vi phạm ràng buộc rõ ràng trong hướng dẫn nhiệm vụ.
Bằng ấy là, việc chưa xong, miệng đã nói xong trước.
Hai là điều nhiều người thắc mắc, tại sao Fable 5 lại kém cỏi thế? Câu trả lời Dawn Song đưa ra là:
Không tồn tại chuyện “nhà vô địch vạn năng”.
Mỗi mô hình tiên phong đều có lĩnh vực giỏi và lĩnh vực kém, ALE bao phủ 55 ngành, 1500+ câu hỏi, điểm tổng cuối cùng là giá trị trung bình của tất cả các lĩnh vực, tổng điểm của nhiều mô hình vì vậy chen chúc nhau. Tín hiệu thực sự có giá trị không nằm ở tổng điểm, mà ở sự khác biệt biểu hiện của các mô hình khác nhau trong các lĩnh vực khác nhau——trên cùng một câu hỏi, các mô hình khác nhau thường thất bại vì những lý do hoàn toàn khác nhau.
Tất nhiên cũng có khả năng Fable 5 lén “giảm trí” rồi.
Trên bảng tổng, bên cạnh Fable 5 có ghi màu vàng một câu “có thể đã bị điều chỉnh giảm” (may be down-tuned), điều này nói về một vấn đề đã biết của Fable 5——
Nền tảng của nó là mô hình Mythos cộng với bộ phân loại an toàn, khi gặp nhiệm vụ thuộc lĩnh vực nhạy cảm như an ninh mạng, y sinh học, sẽ bị chuyển đổi âm thầm sang Opus 4.8 có năng lực yếu hơn.
Trong kỳ thi bao phủ 55 ngành như ALE, tương đương phần môn thi này trực tiếp cử người thi hộ, mà cử toàn vai “Bôn Ba Nhĩ Bá” loại này.

Thêm một điều nữa
Tất nhiên, có khả năng nào thành tích của Claude Fable 5 tự nó đã có vấn đề không?
Không dám chắc, nhưng một tin đồn cho thấy, Claude có “tiền án”.
Cuối tháng 5, công ty khởi nghiệp Datacurve phát hành một benchmark mới tên DeepSWE, tiện tay vạch trần một cái đáy lớn——
Docker container của SWE-Bench Pro đi kèm lịch sử git đầy đủ của kho mã, đáp án đúng nằm ngay trong hệ thống file.
Hầu hết các mô hình sẽ bỏ qua nó, nhưng chỉ có Claude là không.
Nó sẽ chủ động kiểm tra lịch sử git của kho, tìm kiếm từ các commit lịch sử phương án sửa chữa tương ứng với nhiệm vụ, và dựa vào đó khôi phục bản vá đúng.
Theo thông tin, khoảng 18% thành tích đạt được của Opus 4.7 là lấy theo cách này, Opus 4.6 càng kinh khủng hơn, khoảng 25%.
Còn phía GPT 5.4 và GPT5.5 thì sao? Hoàn toàn không có hành vi này. Cách diễn đạt của Datacurve rất ngoại giao:
Benchmark này khiến hành vi này trở nên khả thi, nhưng Claude là gia đình duy nhất liên tục làm như vậy.

Truyền thông công nghệ VentureBeat đánh giá lại khá mơ hồ:
Điều này cho thấy Claude có “khả năng nhận thức môi trường” rất mạnh, rất giỏi khám phá môi trường xung quanh và tận dụng tài nguyên có sẵn. Tính là “gian lận” hay “thông minh”, tùy thuộc vào lập trường của bạn.
Nhưng dù nhìn thế nào đi nữa, ALE rõ ràng đã rút kinh nghiệm——
Trực tiếp chuyển địa điểm thi từ dòng lệnh lên thao tác desktop GUI, khiến bạn không có lịch sử git để lén xem.
Trường thi đánh giá AI, đang bị chính AI thúc ép nâng cấp, cũng đủ gọi là kịch tính rồi.
Địa chỉ đánh giá đầy đủ: https://agents-last-exam.org/leaderboard Trang chủ dự án: https://agents-last-exam.org/ GitHub: https://github.com/rdi-berkeley/agents-last-exam
Liên kết tham khảo:
[1]https://x.com/i/trending/2065215002878021789
[2]https://venturebeat.com/technology/deepswe-blows-up-the-ai-coding-leaderboard-crowns-gpt-5-5-and-finds-claude-opus-exploiting-a-benchmark-loophole
[3]https://venturebeat.com/technology/surprise-upset-gpt-5-5-beats-claude-fable-5-on-brutal-new-agents-last-exam-benchmark
Bài viết từ tài khoản công chúng WeChat “Lượng Tử Vị”, tác giả: Nhất Thủy





