Một bức ảnh có thể nén nhỏ đến mức nào?
Tháng 2 năm 2025, Nhóm chuyên gia hình ảnh liên hợp (JPEG) thông báo một sự kiện được ngành công nghiệp chào đón một cách kín đáo: JPEG AI, tiêu chuẩn quốc tế đầu tiên về mã hóa hình ảnh học tập đầu cuối đầy hy vọng và trải qua nhiều năm, đã chính thức được phát hành.

Tin tức lan truyền, nhiều nhà nghiên cứu chia sẻ trên mạng xã hội kèm bình luận "Cuối cùng AI cũng vào được tiêu chuẩn".
Tiêu chuẩn JPEG ra đời năm 1992, hơn ba mươi năm qua luôn là một ngôn ngữ cơ bản của hình ảnh số hóa của con người. Và giờ đây, trí tuệ nhân tạo bắt đầu tiếp quản việc viết lại ngữ pháp của ngôn ngữ này.
Tuy nhiên, đằng sau sự chào mừng là một thực tế tinh tế: ngay cả JPEG AI, vẫn còn cách khá xa so với "nén cảm nhận" thực sự.
Các kỹ sư biết rằng, chỉ số truyền thống đo lường chất lượng nén - tỷ lệ tín hiệu trên nhiễu đỉnh (PSNR) - thực ra liên quan không nhiều đến việc "có đẹp không" trong mắt người. Một bức ảnh đạt điểm PSNR cao, người xem có thể thấy bình thường; trong khi một bức ảnh khác có PSNR thấp hơn, người xem lại thấy chi tiết phong phú, chất lượng thực. Tối ưu hóa chỉ số toán học và tối ưu hóa cảm nhận của mắt người là hai việc hoàn toàn khác nhau.
Hàng chục năm qua, từ JPEG đến VVC, rồi JPEG AI, logic thiết kế của hầu hết các bộ mã hóa/giải mã, vẫn luôn xoay quanh trong khuôn khổ của các chỉ số toán học. Nén cảm nhận (tối ưu hóa trực tiếp cho trải nghiệm mắt người) mãi giống như mục tiêu xa vời trong các bài báo học thuật, hơn là hiện thực kỹ thuật có thể đưa vào điện thoại.
Ngay tại thời điểm then chốt này, một nhóm kỹ sư của Apple âm thầm công bố một bài báo, đưa ra câu trả lời của họ, mã hiệu: PICO.

Tiêu đề bài báo: What Matters in Practical Learned Image Compression
Địa chỉ bài báo: https://arxiv.org/pdf/2605.05148
Tại sao "trông đẹp hơn" lại khó hơn nhiều so với "chỉ số cao hơn"?
Trước khi hiểu PICO, cần hiểu nén hình ảnh thực sự đang làm gì.
Lưu một bức ảnh thành file, về bản chất là một bài toán lựa chọn "quên cái gì, nhớ cái gì". Dung lượng lưu trữ có hạn, nên phải bỏ đi một phần thông tin, đồng thời khiến người xem càng ít phát hiện ra càng tốt. Các bộ mã hóa/giải mã khác nhau tuân theo các "cách bỏ" khác nhau.
JPEG, AV1, VVC và các bộ mã hóa truyền thống khác đều là hệ thống quy tắc được thiết kế thủ công bởi kỹ sư. Chúng chia hình ảnh thành khối, biến đổi, lượng tử hóa, mã hóa entropy, mỗi bước đều là kinh nghiệm nhân tạo tích lũy hàng chục năm. Loại hệ thống này có thể hoạt động rất tốt trên các chỉ số toán học như PSNR, nhưng bản chất thiết kế của chúng hướng đến "giảm sai số pixel", chứ không phải "giảm cảm giác khó chịu cho mắt người".
Vấn đề là, mắt người không phải là máy đo sai số pixel. Độ nhạy của mắt người với kết cấu, chữ viết, chi tiết phức tạp hơn nhiều so với công thức toán học. Khi bạn nén một bức ảnh phố xã rất nhỏ, PSNR vẫn có thể tốt, nhưng bạn sẽ thấy các cạnh tòa nhà mờ, chữ trên biển hiệu biến dạng — và những thứ này, lại chính là những thứ mắt người phát hiện đầu tiên.
Sự xuất hiện của bộ mã hóa học tập, về lý thuyết mở ra một cánh cửa mới: mạng nơ-ron có thể trực tiếp huấn luyện đầu cuối nhắm vào cảm nhận của con người, thay vì nhắm vào công thức toán học. Nhưng trước PICO, các bộ mã hóa học tập kiểu cảm nhận đã có, hoặc là quá chậm không thể ứng dụng thực tế, hoặc thiếu khả năng tương thích đa thiết bị, hoặc không thể linh hoạt kiểm soát tốc độ bit, căn bản không thể tích hợp vào một sản phẩm tiêu dùng.
Ba vấn đề cốt lõi, ba cách giải quyết
Tên đầy đủ của PICO là Perceptual Image Codec (Bộ mã hóa/giải mã hình ảnh cảm nhận). Cái tên này trực tiếp chỉ rõ mục tiêu của nó: làm hài lòng mắt người.
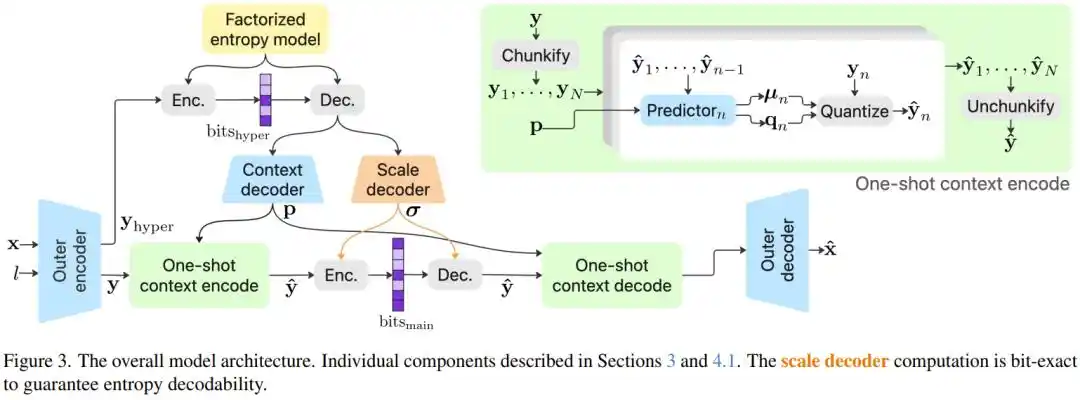
Nhóm nghiên cứu đã khám phá có hệ thống hàng triệu cấu hình mô hình và đưa vào một số đổi mới công nghệ then chốt.
Vấn đề thứ nhất: Mã hóa entropy chậm, làm thế nào?
Trong nén hình ảnh có một bài toán khó: để nén nhỏ hơn, bộ mã hóa/giải mã cần dùng "mô hình entropy" để ước tính chính xác lượng thông tin của mỗi pixel. Phương pháp chính xác nhất gọi là mã hóa tự hồi quy: mỗi khi nén một pixel, đều phải xem các pixel xung quanh đã nén trước đó, dự đoán lần lượt. Giống như đầu bếp mỗi lần cho một nguyên liệu, đều phải quay đầu nhìn tình trạng trong nồi mới quyết định bước tiếp theo. Chính xác, nhưng cực kỳ chậm.
Giải pháp của PICO là "Mô hình ngữ cảnh một lần" (One-shot Context Model): tách riêng tham số "tỷ lệ" quan trọng nhất trong mã hóa entropy ra, tính toán tất cả trong một lần lan truyền thuận, không cần chờ đợi qua lại; các tham số còn lại có thể tính toán song song, giữ được độ chính xác của tự hồi quy, nhưng lại tránh được nút cổ chai về tốc độ của nó. Kết quả: bỏ mô-đun này, hiệu suất mô hình giảm 10.28%; thêm nó vào, tốc độ hầu như không bị ảnh hưởng.
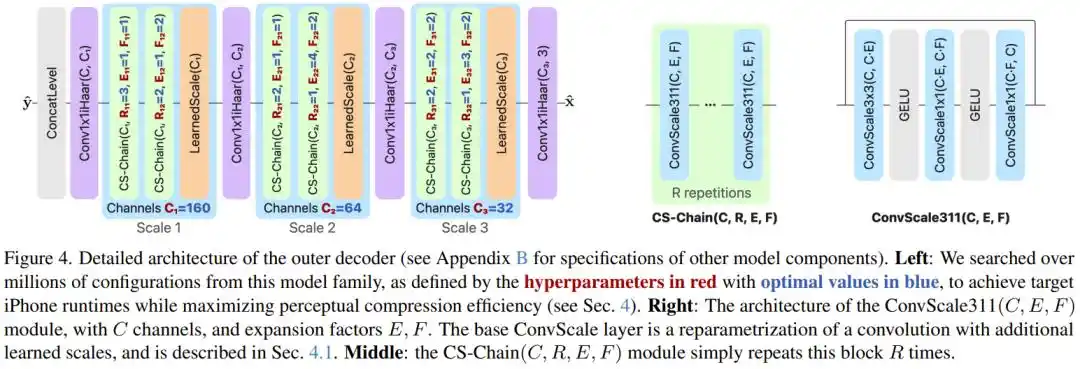
Vấn đề thứ hai: Huấn luyện cảm nhận tạo ra ảo giác, làm thế nào?
Hình ảnh được huấn luyện bằng GAN (Mạng nơ-ron đối kháng) thường "trông rất thật", nhưng có thể là sự thật được bịa đặt — sợi tóc biến thành hoa văn không tồn tại, bề mặt phẳng mịn xuất hiện kết cấu giả. Phiền phức hơn là, mắt người cực kỳ nhạy cảm với chữ viết, dù chỉ một chữ cái biến dạng một chút, sẽ lập tức phát hiện ra.
PICO thiết kế riêng TextFidelityLoss cho chữ viết: dùng một bộ phát hiện chữ viết có sẵn tự động tìm ra vùng chữ trong ảnh, tại những vùng này áp đặt ràng buộc trung thực pixel nghiêm ngặt, đồng thời kìm hãm "không gian phát huy" của GAN trong vùng chữ. Thí nghiệm cho thấy, sau khi thêm hàm mất mát này, sai số tuyệt đối ở vùng chữ giảm tới một nửa.
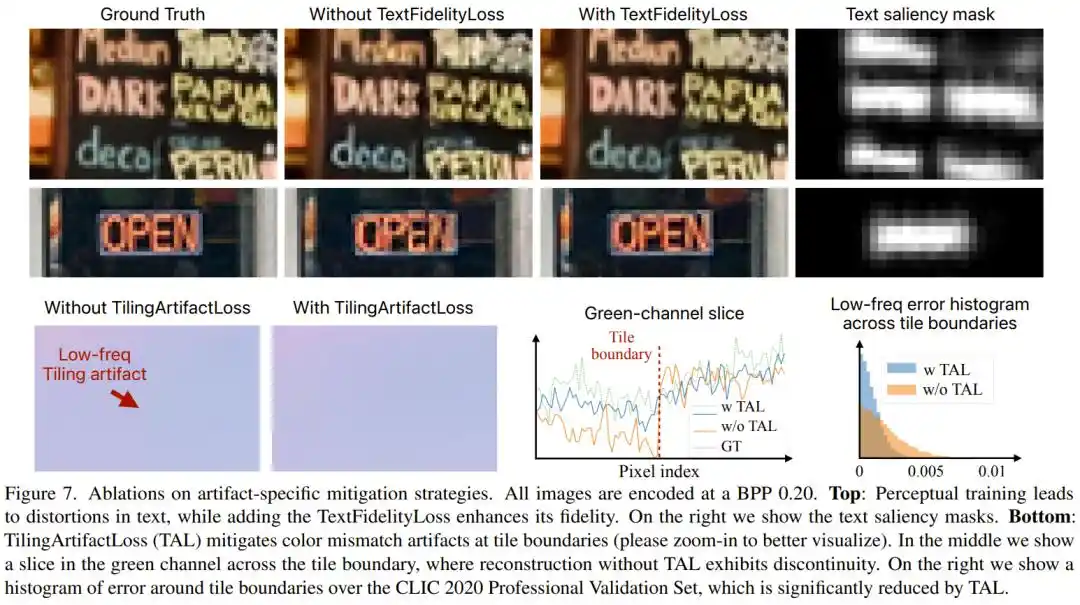
Vấn đề thứ ba: Xử lý chia khối hình ảnh để lại ranh giới khối màu, làm thế nào?
Để chạy nhanh trên chip điện thoại, PICO chia hình ảnh thành từng ô 504×504 pixel, xử lý riêng rồi ghép lại. Nhưng GAN khi huấn luyện có xu hướng bỏ qua màu sắc tần số thấp, dẫn đến sự chênh lệch màu sắc có thể nhìn thấy giữa các ô liền kề, tương tự cảm giác "ghép không khớp" khi chỉnh sửa ảnh. Nhóm nghiên cứu đặc biệt đưa vào TilingArtifactLoss, một loại mất mát L1 đa độ phân giải, buộc mô hình duy trì sự nhất quán màu sắc ở nhiều tần số không gian. Biện pháp này khiến sai số ở ranh giới các ô cũng giảm hơn một nửa.
Kết quả thí nghiệm
Nhóm Apple không chỉ dựa vào chỉ số đánh giá chuẩn. Họ ủy quyền nền tảng bên thứ ba Mabyduck tổ chức một đợt đánh giá chủ quan quy mô lớn của con người.
Đánh giá sử dụng phương thức so sánh cặp mù đôi: 610 người đánh giá được sàng lọc (cần vượt qua bài kiểm tra mù màu và kiểm tra phân biệt lỗi nén), so sánh cặp kết quả tái tạo của cùng một ảnh dưới các bộ mã hóa/giải mã khác nhau, cuối cùng tổng hợp thành điểm Bayesian ELO. Tổng cộng thu thập 74,925 kết quả so sánh cặp.

Con số cuối cùng nói lên tất cả: Ở cùng chất lượng thị giác, dung lượng file của PICO chỉ bằng một phần ba đến một nửa so với AV1, AV2, VVC, ECM và JPEG AI — nói cách khác, lưu cùng một ảnh, số bit nó cần chỉ bằng 30%-43% so với các tiêu chuẩn này. So với bộ mã hóa cảm nhận học tập mạnh nhất hiện nay (HiFiC, MRIC, v.v.), PICO cũng tiết kiệm 20%-40% dung lượng file.
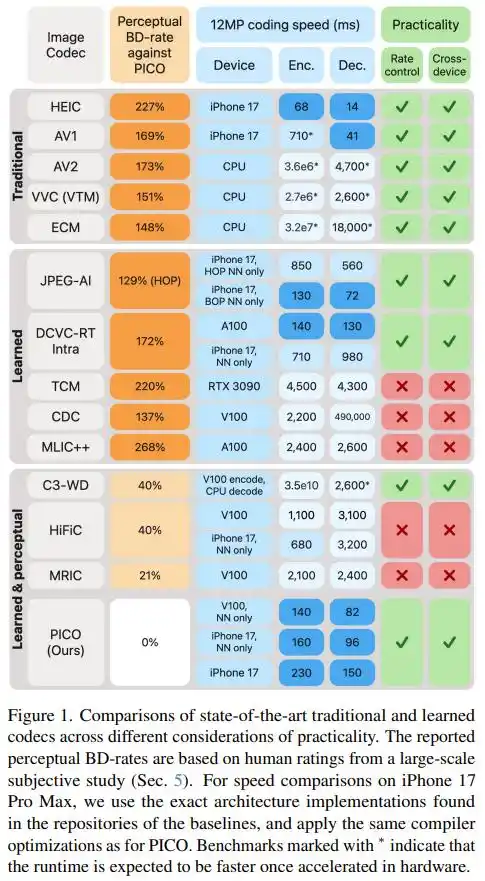
Về tốc độ, trên iPhone 17 Pro Max, PICO mã hóa một ảnh 12MP chỉ cần 230 mili giây, giải mã chỉ cần 150 mili giây. Trong khi hầu hết các bộ mã hóa ML hàng đầu chạy trên card đồ họa máy chủ NVIDIA V100, đều chậm hơn con số này.
Đáng chú ý, bài báo còn đặc biệt ghi lại một "phản ví dụ": trên chỉ số truyền thống PSNR, PICO thể hiện bình thường, thậm chí không bằng DCVC-RT và VVC. Điều này càng khẳng định nhận định cơ bản của nhóm: tối ưu hóa chất lượng cảm nhận và tối ưu hóa chỉ số toán học, về bản chất là hai hướng khác nhau, không thể có cả hai.
Một mốc thời đại, chứ không phải điểm kết thúc
PICO tất nhiên cũng có hạn chế. Bài báo thừa nhận, đối với hình ảnh tổng hợp có tính quy tắc cao như hoạt hình, sơ đồ minh họa, hiệu quả nén của PICO không bằng bộ mã hóa/giải mã truyền thống, vì loại nội dung này tự nhiên phù hợp với mô hình hóa tự hồi quy dựa trên quy tắc, hơn là sinh cảm nhận.
Nhưng những hạn chế này không che lấp ý nghĩa của công trình này.
Ba mươi năm qua, tiến bộ công nghệ nén hình ảnh, hầu như đều xảy ra trên đường đua "làm cho chỉ số đẹp hơn". Từ JPEG đến HEVC, rồi đến VVC, các kỹ sư từng thế hệ tối ưu hóa là các chỉ số như PSNR, SSIM. Còn cảm nhận của mắt người, mãi là một "bài toán khó" bị lảng tránh.
PICO là lần đầu tiên có người phân tích bài toán khó này một cách có hệ thống: từ tìm kiếm kiến trúc, thiết kế hàm mất mát, đến đánh giá chủ quan quy mô lớn của con người, và cuối cùng tích hợp vào một bộ mã hóa/giải mã có thể chạy thời gian thực trên điện thoại.
Lần tới khi bạn chia sẻ một bức ảnh bằng thiết bị Apple, có lẽ sẽ không cảm nhận được sự khác biệt nào. Nhưng có lẽ trong quá trình nén thầm lặng đó, một bộ thuật toán được thiết kế riêng cho cảm nhận mắt người, đang quyết định thông tin nào đáng để lưu lại, thông tin nào có thể lặng lẽ quên đi.
Nhóm: Từ WaveOne đến Apple
Tác giả liên hệ của bài báo này là Oren Rippel, nhà nghiên cứu Apple, gương mặt quen thuộc trong lĩnh vực nén.
Tên ông lần đầu xuất hiện quy mô lớn, là vào năm 2017. Khi đó ông còn ở công ty khởi nghiệp WaveOne, công bố một bài báo có tên "Nén hình ảnh thích ứng thời gian thực", dùng mạng nơ-ron đánh bại tất cả các bộ mã hóa/giải mã chính thời đó, đồng thời duy trì tốc độ chạy thời gian thực. Bài báo đó tạo nên làn sóng nhỏ trong giới học thuật, cũng xác lập vị thế của Rippel trong lĩnh vực nén học tập.

Sau đó, cùng nhóm nhân sự cốt lõi tiếp tục đào sâu tại WaveOne, cho ra mắt ELF-VC hướng đến nén video, trên bộ thử nghiệm video UVG tiết kiệm 44% tốc độ bit so với H.264, đồng thời tốc độ chạy nhanh hơn năm lần so với các bộ mã hóa ML cùng loại.
Nhóm này của WaveOne sau đó gia nhập Apple. Và PICO lần này, là câu trả lời có hệ thống đầu tiên của họ mang theo nguồn lực tính toán và nền tảng của Apple trong lĩnh vực nén hình ảnh cảm nhận.
Bài viết từ tài khoản công chúng WeChat "机器之心" (ID:almosthuman2014), tác giả: 压缩即智能






