Những năm gần đây, Mô hình Hỗn hợp Chuyên gia (MoE) đã được sử dụng rộng rãi cho các mô hình lớn trên đám mây. Tuy nhiên, trên thiết bị di động, Mô hình Ngôn ngữ Lớn (LLM) vẫn chủ yếu sử dụng kiến trúc dày đặc (dense). Trước đây, các ràng buộc về bộ nhớ, năng lực tính toán và độ trễ trên thiết bị di động nghiêm ngặt hơn, vẫn thiếu các nghiên cứu hệ thống về MoE phía máy khách trong phạm vi vài tỷ tham số. Ngày nay, với việc dung lượng DRAM trên thiết bị di động được nâng cao, MoE cũng bắt đầu có cơ hội được triển khai trên điện thoại thông minh.
MobileMoE do nhóm Meta đề xuất, lần đầu tiên thực hiện suy luận MoE hiệu quả trên điện thoại thông minh thương mại. Kết quả cho thấy, trong 14 bài kiểm tra cơ bản, MobileMoE-S/M với bộ nhớ gần tương đương, chỉ sử dụng lượng tính toán suy luận bằng 1/2 đến 1/4 so với đường cơ sở dày đặc, đã đạt được độ chính xác trung bình ngang bằng hoặc cao hơn. Trong thử nghiệm thực tế, MobileMoE-S cho thấy tốc độ tăng nhanh rõ rệt nhất trên GPU/MLX backend của iPhone 16 Pro, trong giai đoạn đầu vào có thể tăng tốc tối đa 3.8 lần.

Liên kết bài báo: https://arxiv.org/abs/2605.27358
Nhóm nghiên cứu cũng đề xuất một bộ quy tắc co giãn MoE phía máy khách, được sử dụng để xác định cấu trúc mô hình phù hợp hơn cho việc triển khai trên điện thoại. MobileMoE thiết lập biên giới Pareto mới cho mô hình ngôn ngữ lớn phía máy khách, đạt được kết quả tối ưu hơn trong việc cân bằng giữa độ chính xác và chi phí tính toán suy luận.
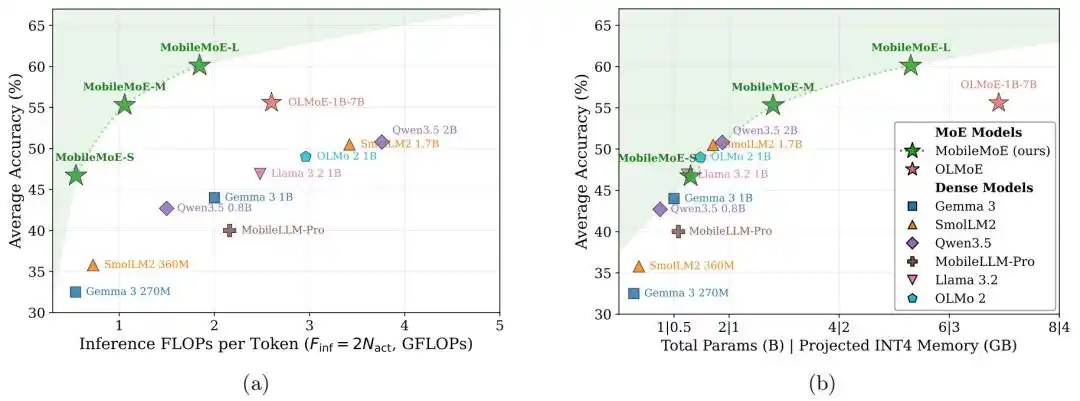
Hình| MobileMoE thiết lập biên giới Pareto mới cho mô hình ngôn ngữ lớn phía máy khách.
MobileMoE được thiết kế như thế nào?
MobileMoE có thể hiểu như sau: nó là một loại mô hình ngôn ngữ MoE được thiết kế hướng đến triển khai phía máy khách. Về tổng thể vẫn là Transformer chỉ giải mã (decoder-only), nhưng thay thế các tầng truyền thẳng dày đặc ban đầu bằng các tầng MoE. Bộ định tuyến sẽ chọn ra một số ít chuyên gia có điểm số cao nhất cho mỗi token để tham gia tính toán, đồng thời luôn có một chuyên gia được chia sẻ tham gia tính toán. Toàn bộ quy trình đào tạo được chia thành bốn bước: tiền đào tạo, đào tạo trung kỳ, tinh chỉnh có giám sát và đào tạo nhận thức lượng tử hóa.
Tiền đào tạo: Nhóm nghiên cứu đã thực hiện tiền đào tạo trên khoảng 6T token dữ liệu có giấy phép mở với độ dài ngữ cảnh 2048, dữ liệu chủ yếu từ Web, đồng thời bao phủ các lĩnh vực như toán học, mã, kiến thức và khoa học.
Đào tạo trung kỳ: Nhóm nghiên cứu đã mở rộng độ dài ngữ cảnh lên 8192, và tiếp tục nâng cao tỷ lệ dữ liệu chất lượng cao như kiến thức, mã, toán học và khoa học, tổng quy mô khoảng 500B token.
Tinh chỉnh có giám sát (SFT): Nhóm nghiên cứu đã tinh chỉnh MobileMoE-Base trên dữ liệu tinh chỉnh hướng dẫn có giấy phép mở với hơn 80 triệu mẫu.
Đào tạo nhận thức lượng tử hóa: Nhóm nghiên cứu đã lượng tử hóa các tầng tuyến tính và embedding xuống INT4, lượng tử hóa động kích hoạt xuống INT8, trong khi router vẫn giữ độ chính xác FP32.

Hình| Bốn giai đoạn đào tạo của MobileMoE.
Kết quả thực nghiệm
Kết quả thực nghiệm loại bỏ (ablation)
Nhóm nghiên cứu trước tiên so sánh ba biến số kiến trúc: số lượng chuyên gia E, độ chi tiết của chuyên gia g, và việc có thêm chuyên gia chia sẻ hay không.

Hình| Sự co giãn của số lượng chuyên gia E.
Trong điều kiện ngân sách bộ nhớ cố định, khi bộ nhớ cao hơn khoảng 0.25GB, độ lỗi của MoE bắt đầu thấp hơn mô hình dày đặc tương ứng. Tiếp tục tăng số lượng chuyên gia E, độ lỗi sẽ tiếp tục giảm, nhưng khi E tăng lên 8, lợi ích cận biên đã giảm đi rõ rệt. Thử nghiệm về độ chi tiết của chuyên gia g cho thấy, cấu hình chuyên gia có độ chi tiết mịn hơn nhìn chung tối ưu hơn, trong đó g=8 đạt được sự cân bằng tốt giữa hiệu quả và chi phí đào tạo; khi g tăng từ 8 lên 16, cải thiện độ lỗi không đầy 0.01, nhưng thời gian đào tạo tăng khoảng 50%. Trong cùng ngân sách tính toán, việc thêm chuyên gia chia sẻ giúp độ lỗi của mô hình giảm thêm.
Dựa trên kết quả thực nghiệm loại bỏ, nhóm nghiên cứu cuối cùng đã sử dụng cấu hình E=8, g=8, có chuyên gia chia sẻ, tức là 60 chuyên gia định tuyến mức độ chi tiết mịn, định tuyến Top-4 và 1 chuyên gia chia sẻ, và áp dụng cấu trúc này cho ba phiên bản MobileMoE-S/M/L.
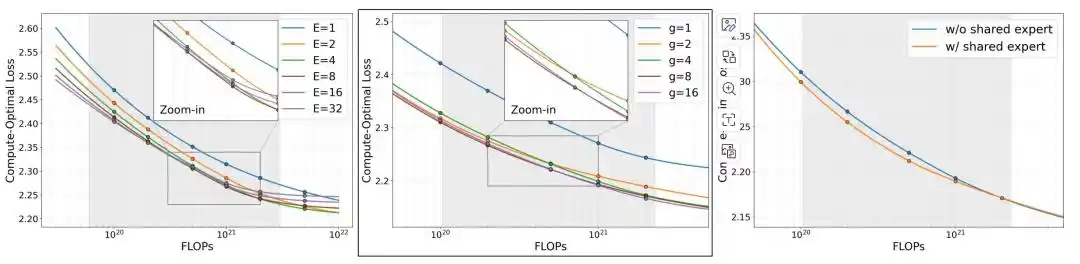
Hình| Co giãn mô hình MoE trong điều kiện tối ưu hóa tính toán.
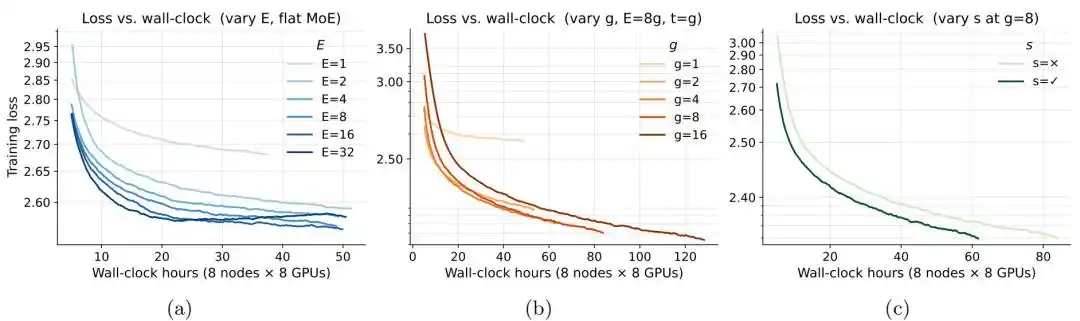
Hình| Hiệu quả đào tạo của kiến trúc MoE.
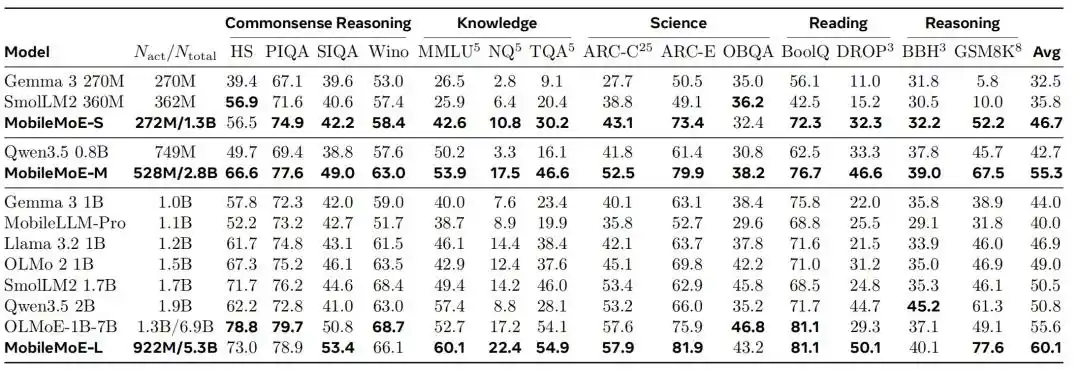
14 đánh giá cơ bản: Thiết lập biên giới Pareto mới cho phía máy khách
Nhóm nghiên cứu đã đánh giá lại MobileMoE cùng với các mô hình như Gemma 3, SmolLM2, Qwen3.5, OLMo 2, OLMoE-1B-7B trong thiết lập thống nhất, thuộc năm loại lập luận thường thức, kiến thức, khoa học, đọc hiểu và suy luận với tổng cộng 14 bài đánh giá cơ bản.
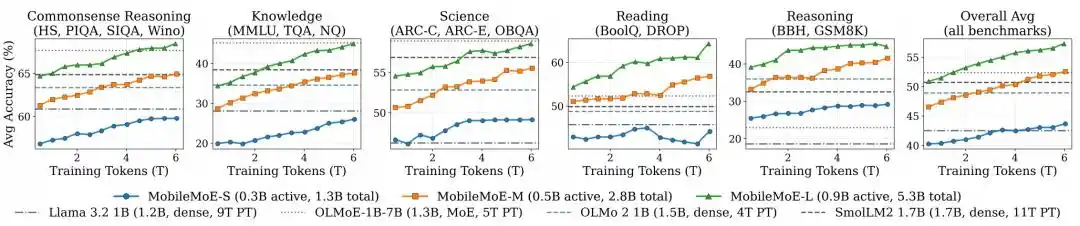
Hình| Quá trình tiền đào tạo của MobileMoE.
Kết quả so sánh mô hình Base cho thấy, điểm trung bình của MobileMoE-M cao hơn Qwen3.5 2B, điểm trung bình của MobileMoE-L cao hơn OLMoE-1B-7B, đồng thời quy mô mô hình yêu cầu cũng nhỏ hơn; nhóm nghiên cứu cũng đề cập, phiên bản Base của MobileMoE-L đã có điểm trung bình cao hơn phiên bản Instruct của OLMoE-1B-7B. Về quy mô đào tạo, MobileMoE sử dụng khoảng 6T token tiền đào tạo, ít hơn 9T của Llama 3.2 1B và 11T của SmolLM2 1.7B. Trong so sánh tổng thể mô hình được tinh chỉnh hướng dẫn, độ chính xác trung bình của MobileMoE-M đã tiếp cận OLMoE-1B-7B, nhưng số tham số hoạt động và tổng tham số đều ít hơn khoảng 60%.

Hình| So sánh mô hình MobileMoE-Base.
Đánh giá nâng cao: Ưu thế rõ rệt hơn ở nhiệm vụ mã và toán học
Trong các đánh giá nâng cao sau khi tinh chỉnh hướng dẫn, MobileMoE thể hiện nổi bật hơn ở các nhiệm vụ mã và toán học. Lấy MobileMoE-L làm ví dụ, điểm trung bình của nó trong cả hai loại đánh giá mã và toán học đều cao hơn Qwen3.5 2B và OLMoE-1B-7B. Tuy nhiên, nhóm nghiên cứu cũng đề cập rằng, trong hai khả năng tuân theo hướng dẫn và lập luận kiến thức, Qwen3.5 2B vẫn mạnh hơn.
Hình| So sánh mô hình Instruct trên các bài kiểm tra chuẩn nâng cao.
Lượng tử hóa và triển khai phía máy khách: Vẫn giữ tính cạnh tranh sau INT4, tăng tốc rõ rệt trên điện thoại
Sau khi lượng tử hóa, điểm trung bình tổng thể của MobileMoE-S/M/L so với phiên bản BF16 tương ứng của chúng có giảm, nhưng mức giảm dao động trong khoảng 2 đến 3 điểm. Dù vậy, hiệu suất của phiên bản INT4 của MobileMoE-L vẫn cao hơn phiên bản BF16 của OLMoE-1B-7B Instruct.
Nhóm nghiên cứu cũng đã triển khai MobileMoE lên Samsung Galaxy S25 và iPhone 16 Pro để kiểm tra. Kết quả cho thấy, trong điều kiện bộ nhớ trọng số INT4 tương đương, MobileMoE-S so với MobileLLM-Pro, tăng tốc giai đoạn đầu vào 1.8-3.8 lần, tăng tốc giai đoạn sinh token tuần tự 2.2-3.4 lần.
Về mức sử dụng bộ nhớ, trong điều kiện Samsung Galaxy S25, ngữ cảnh 8K và prompt thực tế, RSS đỉnh của MobileMoE-S là 1.49GB, thấp hơn 1.91GB của MobileLLM-Pro.

Hình| Độ trễ thời gian chạy phía máy khách.
Hạn chế và hướng phát triển tương lai
Hiện tại, trong khả năng tuân theo hướng dẫn cao cấp hơn cũng như khả năng kiến thức và lập luận, MobileMoE sau khi tinh chỉnh hướng dẫn vẫn tụt sau Qwen3.5 2B. Nhóm nghiên cứu cho rằng, khoảng cách này có thể liên quan đến việc đào tạo hậu kỳ hoàn thiện hơn. Trong tương lai, để thu hẹp khoảng cách này, phía đào tạo cần tăng cường chưng cất, đào tạo hậu kỳ hướng đến suy luận, cũng như mở rộng đa phương thức.
Ngoài ra, nhóm nghiên cứu chỉ ra rằng, việc sử dụng bộ nhớ của MoE trên điện thoại sẽ thay đổi theo nội dung đầu vào. So với đầu vào theo mẫu cố định, đầu vào thực tế thường mang lại mức sử dụng bộ nhớ cao hơn. Nếu chỉ dựa trên đầu vào theo mẫu để kiểm tra, có thể đánh giá thấp áp lực bộ nhớ trong các kịch bản triển khai thực tế. Trong tương lai, để đánh giá chính xác hơn hiệu suất bộ nhớ thực tế của MoE phía máy khách, vẫn cần dựa trên nhiều dữ liệu đo lường thực tế hơn.
Đồng thời, nhóm nghiên cứu đã hoàn thành các thử nghiệm hệ thống trên thiết bị thực với CPU và GPU backend, nhưng hướng đi NPU vẫn cần được khám phá. Đồng thời, việc sử dụng bộ nhớ thời gian chạy của MoE khá nhạy cảm với nội dung đầu vào. Trong tương lai, định tuyến động, cắt tỉa chuyên gia, lượng tử hóa độ chính xác hỗn hợp và triển khai NPU trên thiết bị di động đều là các hướng tiếp tục nâng cao hiệu quả phía máy khách.
Để biết thêm chi tiết kỹ thuật, vui lòng tham khảo bài báo gốc.
Bài viết này đến từ tài khoản WeChat công cộng “Academic Headlines” (ID: SciTouTiao), tác giả: Xia Qiansi





