Achieving human-level dexterous manipulation capability has long been a core challenge in the field of robotics.
Although multi-fingered dexterous hands possess hardware potential similar to humans, due to the high cost of acquiring high-quality robotic action data, existing Vision-Language-Action (VLA) models lag far behind large language models (LLMs) and vision-language models (VLMs) in terms of data scale and diversity, making it difficult to meet the demands of complex tasks in the real world.
A recent research paper titled "Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos" from Microsoft Research Asia (MSRA) in collaboration with Tsinghua University addresses this critical issue by proposing an innovative pre-training framework called VITRA.

The core contribution of this research lies in proposing a fully automated solution that converts massive amounts of unlabeled real-world human activity videos into data perfectly aligned with the existing V-L-A training data format for robots.
By extracting 3D hand motion trajectories from videos, performing atomic-level action segmentation, and automatically generating language instructions, the research team constructed a large-scale hand V-L-A dataset containing 1 million clips and 26 million frames.
After pre-training solely on human video data, the model demonstrated powerful zero-shot hand action prediction capabilities in completely unseen real-world environments.
With only a small amount of fine-tuning using real robot data, it achieved high success rates in dexterous manipulation on real robots and exhibited strong generalization ability to new objects and environments.
More details follow below.
Bridging the Gap from Human Videos to Robot Data
The central challenge of the paper is how to overcome the vast difference between unstructured human videos and structured robot data, thereby extracting high-quality action labels and language instructions usable for VLA model pre-training.
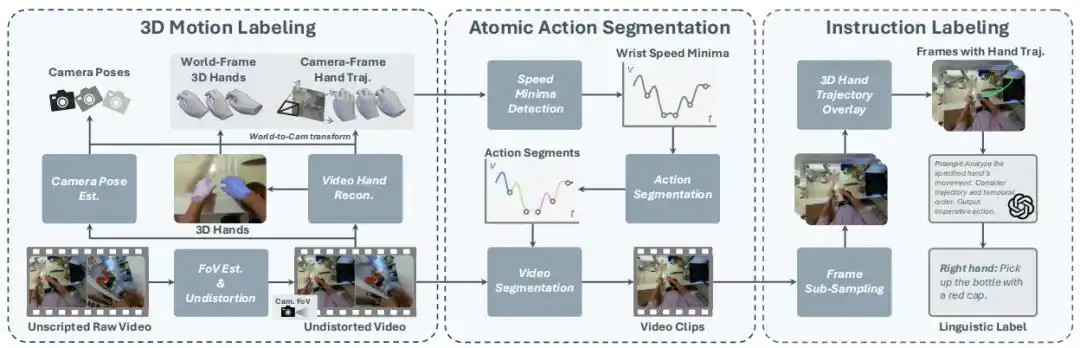
This research built a complete system consisting of three core technologies, achieving seamless transformation from raw video to V-L-A data.
△
3D Motion Annotation: Accurately Recovering Hand and Camera Trajectories
Recovering precise 3D hand motion from monocular, uncalibrated, and potentially moving camera videos is an extremely challenging task.
This research proposes a monocular camera and hand pose tracking method based on the latest 3D vision technology:
First, it determines the camera state via background optical flow and estimates camera intrinsics.
Subsequently, it tracks camera pose using a visual SLAM method and a depth estimation model, and extracts the camera-space 3D hand pose per frame (including wrist 6D pose and full joint angles) using a hand reconstruction model.
Finally, by combining this information, it obtains the 3D hand motion trajectory in world space.
This method not only provides high-precision action labels but also lays the foundation for subsequent action segmentation and instruction annotation.
Atomic-Level Action Segmentation: Natural Segmentation Based on Velocity Minima
Existing robot V-L-A data typically consists of simple, short-horizon atomic-level tasks. Accurately segmenting these atomic actions from long videos is a difficult problem.
Inspired by the natural rhythm of human movements, the research team proposed a simple yet efficient segmentation algorithm: segmenting based on the minima of hand movement speed in 3D space.
During action transitions, human hands typically exhibit changes in speed, and speed minima often mark the switching of actions.
By detecting the speed minima of the 3D wrist trajectory in world space, this method can efficiently segment long videos into short clips containing a single atomic action, without requiring any additional manual annotation or model inference.


Instruction Annotation: Precise Action Description Combining 3D Trajectories
To generate accurate language instructions for the segmented video clips, the research team cleverly combined a Vision-Language Model (VLM) with 3D hand trajectories.
For each video clip, the system uniformly samples 8 frames and projects and overlays the palm's 3D trajectory onto these images.
Then, these images with trajectory highlighting are input into GPT-4, prompting it to describe the specified hand's action in an imperative sentence form, combining image content and trajectory information.
Experiments proved that providing atomic-level video clips overlaid with 3D hand trajectories significantly improves the accuracy of GPT-generated action descriptions.
Achieving Powerful Zero-Shot Prediction and Real-World Generalization
Based on the automatically constructed large-scale human hand V-L-A dataset, the research team designed and trained a VLA model specifically tailored for dexterous manipulation.
△
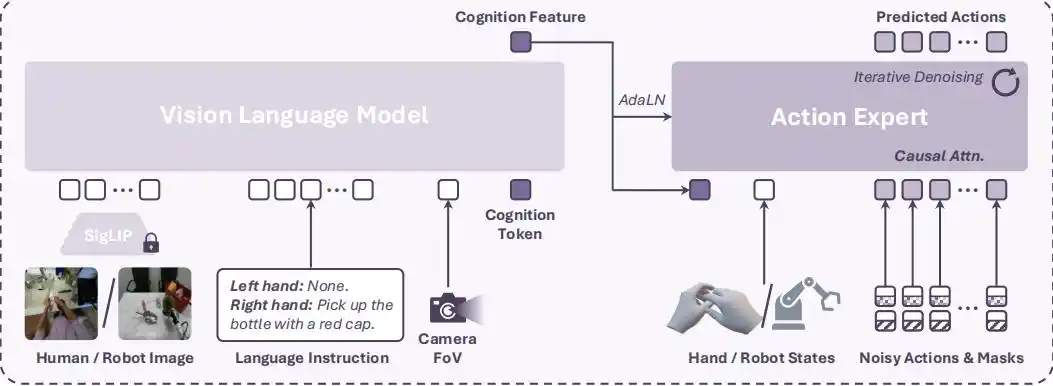
1. Model Architecture: Combining VLM and Diffusion Action Experts
This VLA model consists of a VLM backbone network (PaliGemma-2) and a diffusion action expert (Diffusion Transformer, DiT).
The VLM receives visual observations, language instructions, and camera field-of-view (FoV) information, outputting a "Cognition Feature".
The diffusion action expert receives this cognition feature, the current hand state, and a noisy action block with masking, iteratively denoising to predict future hand action sequences.
To handle fast-moving human hand actions and adapt to short-clip data, the model employs a Causal Attention mechanism for action denoising, ensuring each action step's prediction depends only on previous actions, effectively mitigating negative impacts from zero-padding.
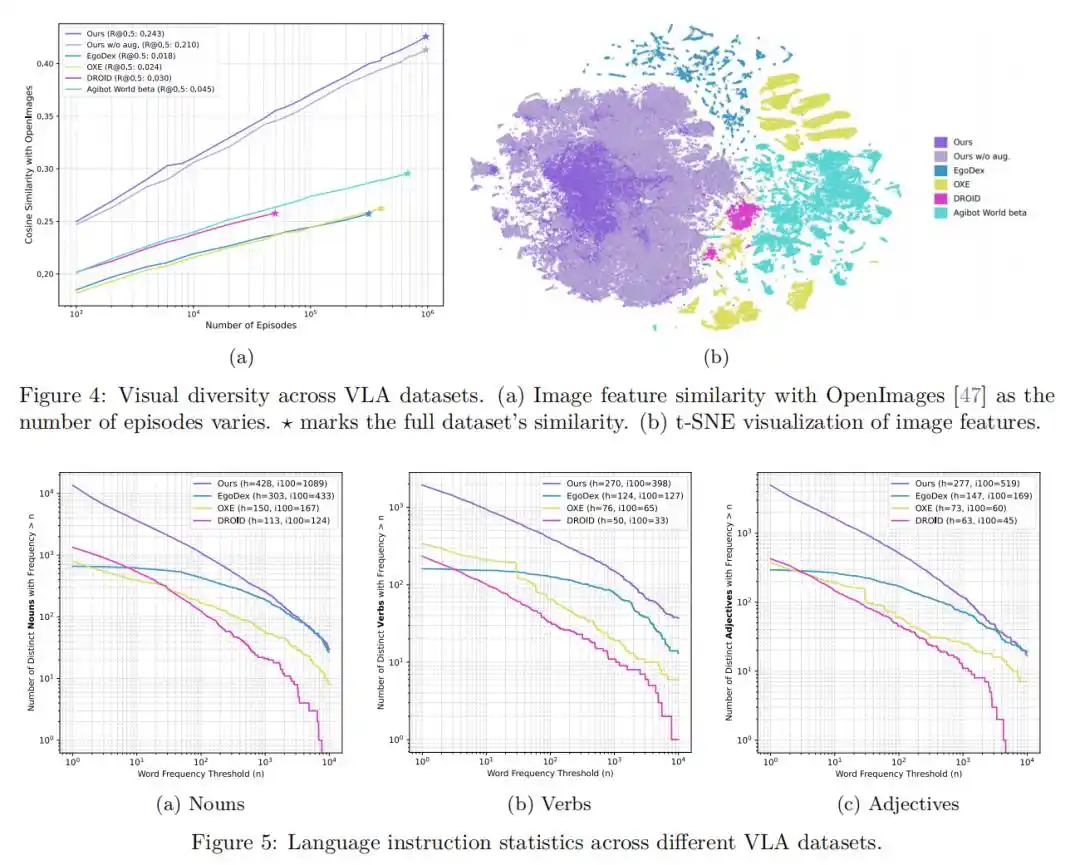
2. Zero-Shot Hand Action Prediction: Demonstrating Remarkable Ability in Unseen Environments
In completely unseen real-life environments, the pre-trained model demonstrated powerful zero-shot hand action prediction capabilities.
△
In evaluations for grasping tasks and general action prediction tasks, this model significantly outperformed models trained on data collected in lab environments (like EgoDex), and also outperformed models trained using raw human-annotated data.
This fully demonstrates that pre-training with massive, diverse real-life videos can greatly enhance the model's generalization ability for complex environments and unknown objects.
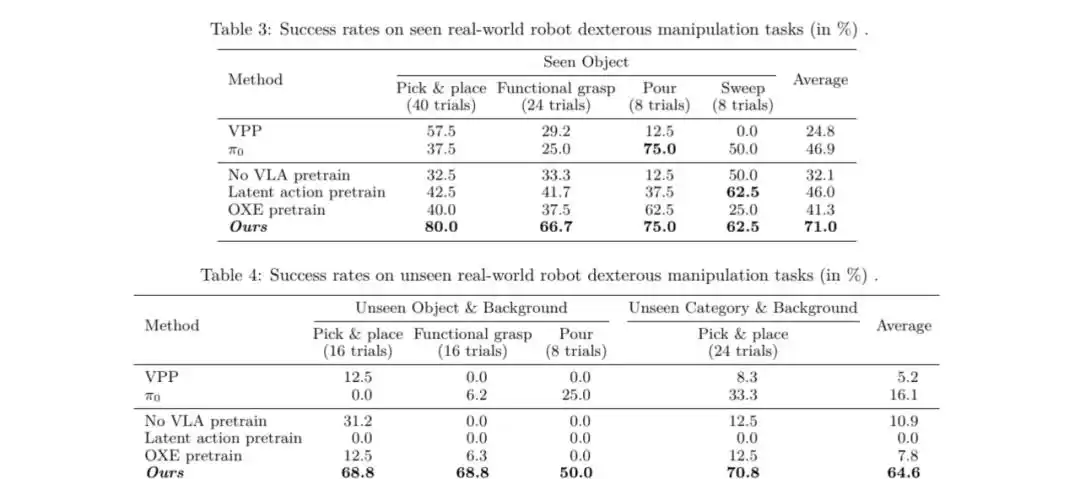
3. Real-Robot Dexterous Manipulation: Efficient Deployment with Minimal Fine-Tuning Data
To deploy on real robots, the research team aligned the human hand's action space with that of the robot dexterous hand (e.g., Realman robot equipped with StarXHand1).
△
With only a small amount (about 1.2K instances) of fine-tuning using real robot teleoperation data on the pre-trained model, it could execute various dexterous manipulation tasks in the real world, including grasping, placing, pouring, and sweeping.
Experimental results show that compared to models not pre-trained on human VLA data or pre-trained on other datasets (like OXE, EgoDex), this method achieved significant improvement in task success rate, especially demonstrating remarkable robustness when facing unseen objects and backgrounds.
The Hardware Core Supporting VITRA's Real-World Deployment
The reason the VITRA framework can achieve stunning generalization on real robots relies not only on algorithmic innovations but also on the powerful support of the underlying hardware—
the domestically pioneered, fully direct-drive five-fingered dexterous hand StarXHand1 developed by StarX Robotics.
This framework forms a perfect "software-hardware synergy" with the hardware characteristics of StarXHand1, demonstrating irreplaceable deployment advantages in practical application scenarios.
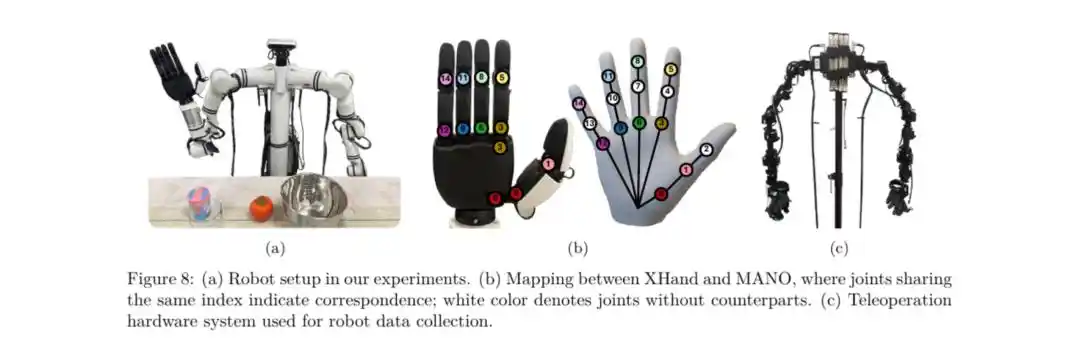
△
High-Precision URDF and Seamless Connection to Human Hand Action Space
The core breakthrough of the VITRA framework lies in aligning the human hand action space with the robot dexterous hand's action space.

StarXHand1 officially provides an extremely high-precision URDF model, which not only accurately describes motion and dynamics parameters but also perfectly maps the spatial distribution of human hand joints.
This "digital twin"-level model support enables VITRA to precisely map human joint angles to the corresponding joints of StarXHand1 during the fine-tuning phase, thereby significantly reducing the reality gap from human videos to real hardware and ensuring the efficient deployment of pre-trained strategies on real hardware.
Fully Direct-Drive Architecture and High-Frequency Response: Perfect Execution of Complex Dexterous Operations
When performing complex dexterous operations such as pouring and sweeping, robots require extremely high dynamic response capability.
The fully direct-drive motor architecture adopted by StarXHand1 provides the most ideal hardware foundation for this algorithm.
The fully direct-drive design fundamentally eliminates the significant friction, hysteresis, and nonlinear interference brought by traditional reducers, endowing the dexterous hand with super-sensitive dynamic response capabilities. This enables StarXHand1 to instantly and precisely execute the action commands output by the VITRA model, safely manipulating various unknown objects.
Rich Sensor Array: Reserving Space for Future Multimodal Perception
Although the current VITRA model primarily relies on visual input, the rich sensor array equipped on StarXHand1 (such as high-resolution tactile arrays) reserves vast space for future multimodal perception.
Combined with StarXHand1's powerful hardware perception capabilities, future VLA models are expected to further integrate tactile feedback, handling more delicate and complex "Finger Gaits" tasks.
The Scaling Law of Data Size
This research also explored the impact of pre-training data scale on model performance.
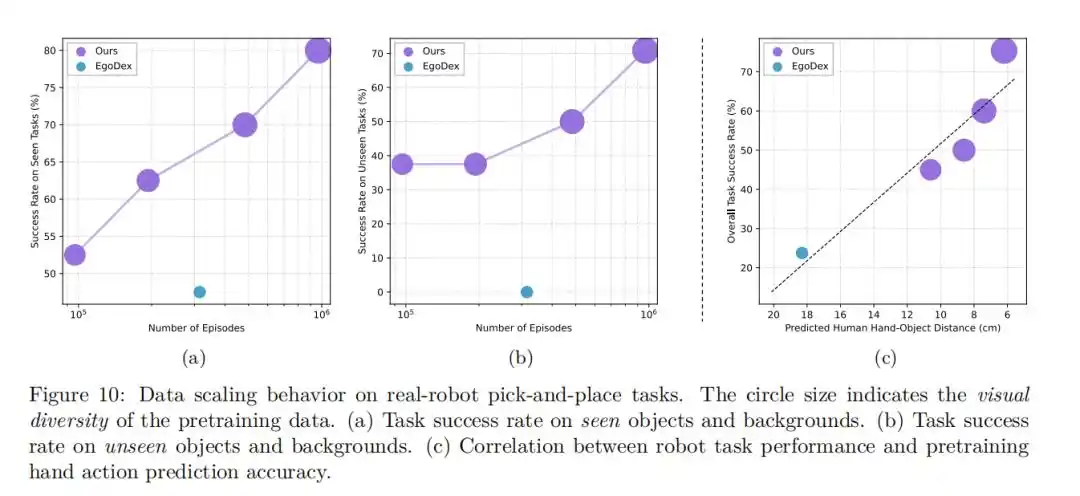
△
Experiments found that as the amount of pre-training data increased, the model's error in zero-shot hand action prediction tasks steadily decreased, and its success rate in real robot manipulation tasks continuously rose.
This clear scaling behavior indicates that by further expanding the scale of human video data, the performance of VLA models is expected to continuously improve.
This achievement marks a key breakthrough in utilizing unstructured human videos for robotic VLA model pre-training.
By providing a fully automated data conversion solution, this research significantly lowers the barrier to acquiring high-quality robot training data, paving the way for the application of multi-fingered dexterous hands in broader, more complex real-world scenarios, and laying a solid foundation for moving towards truly generalized embodied intelligence.
Paper link: https://arxiv.org/abs/2510.21571
This article is from WeChat Official Account "QbitAI", author: VITRA Team






