Cách đây không lâu, Anthropic đã xuất bản một bài viết có tiêu đề "When AI Builds Itself" (Khi AI tự xây dựng chính mình), nhanh chóng thu hút sự thảo luận rộng rãi. Bài viết tiết lộ một nhóm dữ liệu nội bộ đáng chú ý: Tính đến tháng 5 năm 2026, hơn 80% mã nguồn trong kho mã của Anthropic đã được viết bởi Claude, lượng mã mà các kỹ sư hợp nhất hàng ngày gấp 8 lần so với năm 2024; trong một bài kiểm tra nội bộ, Claude đã cải thiện tốc độ chạy của một đoạn mã huấn luyện từ điểm chuẩn lên khoảng 52 lần, trong khi một nhà nghiên cứu con người có kinh nghiệm thường cần từ 4 đến 8 giờ để đạt được tốc độ tăng 4 lần.
Anthropic hướng con đường này tới một đích đến sâu hơn: "Cải tiến tự thân đệ quy" - hệ thống AI tự thiết kế, xây dựng và huấn luyện các phiên bản kế tiếp của chính nó, con người không còn điều khiển từng bước nữa. Đáng chú ý là, công ty này còn kêu gọi sự phối hợp ngành công nghiệp, để có các tùy chọn tạm hoãn hoặc thậm chí tạm dừng phát triển AI tiên phong khi thời điểm cải tiến tự thân đệ quy đến. Và Anthropic đã đang làm như vậy: hạn chế việc Claude Fable 5 mới nhất được sử dụng để nghiên cứu và phát triển AI tiên phong.
Và bây giờ, Recursive Superintelligence thông báo đã thực hiện bước đầu tiên hướng tới nghiên cứu AI tự động hóa.
Công ty mới này được đồng sáng lập bởi Tian Yuandong (Tian Yuandong) vừa kết thúc trạng thái "stealth" chỉ một tháng trước, giờ đây đã phát hành thành quả công nghệ công khai đầu tiên của họ. Họ đã xây dựng một hệ thống khám phá tri thức tự động mở, và đạt được kết quả SOTA trên ba bài kiểm tra chuẩn. Nói một cách đơn giản, họ đã thành công trong việc để AI chạy thử nghiệm thay cho bạn.

https://x.com/tydsh/status/2065062838255649082
Thành quả đầu tiên: Để AI chạy thử nghiệm thay bạn
Thành quả công nghệ công khai đầu tiên của Recursive này được đặt tên là "First Steps Toward Automated AI Research" (Những bước đầu tiên hướng tới nghiên cứu AI tự động hóa).

Tweet: https://x.com/Recursive_SI/status/2064980090702962699
Địa chỉ kho lưu trữ: https://github.com/recursive-org/first-steps-toward-automated-ai-research
Địa chỉ blog: https://www.recursive.com/articles/first-steps-toward-automated-ai-research
Nếu tóm tắt trong một câu, cốt lõi của công việc này là: Xây dựng một hệ thống có thể tự động thúc đẩy vòng lặp nghiên cứu AI, và đã lập kỷ lục mới về điểm số tốt nhất trên ba bài kiểm tra chuẩn.
Trước khi phân tích thành quả một cách chính thức, cần hiểu logic thiết kế của hệ thống này.
Quy trình nghiên cứu AI truyền thống là một vòng lặp phụ thuộc nhiều vào con người: "Đề xuất ý tưởng — Viết mã — Chạy thử nghiệm — Phân tích kết quả — Lại đề xuất ý tưởng". Nút thắt cổ chai về hiệu suất của nó không nằm ở sức mạnh tính toán, mà ở con người. Trên toàn thế giới, số nhà nghiên cứu có thể thiết kế quy trình huấn luyện tiên phong chỉ đếm trên đầu ngón tay, và mỗi lần lặp thử nghiệm đều cần sự can thiệp cao độ của họ.
Hệ thống của Recursive cố gắng tự động hóa vòng lặp này.
Cách thức hoạt động của nó là: Đối với một mục tiêu tối ưu hóa rõ ràng, hệ thống tự động đề xuất ý tưởng thử nghiệm, triển khai mã, chạy xác minh, học hỏi từ đó, sau đó quyết định cách tìm kiếm bước tiếp theo. Nhiều tuyến nghiên cứu có thể được tiến hành song song, các phát hiện hiệu quả có thể được tái sử dụng xuyên nhiệm vụ, cơ chế phát hiện gian lận phần thưởng (reward hacking) cũng được nhúng vào toàn bộ vòng lặp, ngăn ngừa hệ thống "đi tắt" để đẩy chỉ số đánh giá lên mà không thực sự cải thiện bất cứ điều gì.
Đây không phải là một công cụ chuyên dụng được tinh chỉnh cho một vấn đề duy nhất, mà là một khung làm việc tự động hóa nghiên cứu chung xuyên lĩnh vực. Recursive sử dụng ba tình huống kiểm tra khác biệt đáng kể để chứng minh điều này.
Ba mặt trận, ba kỷ lục mới
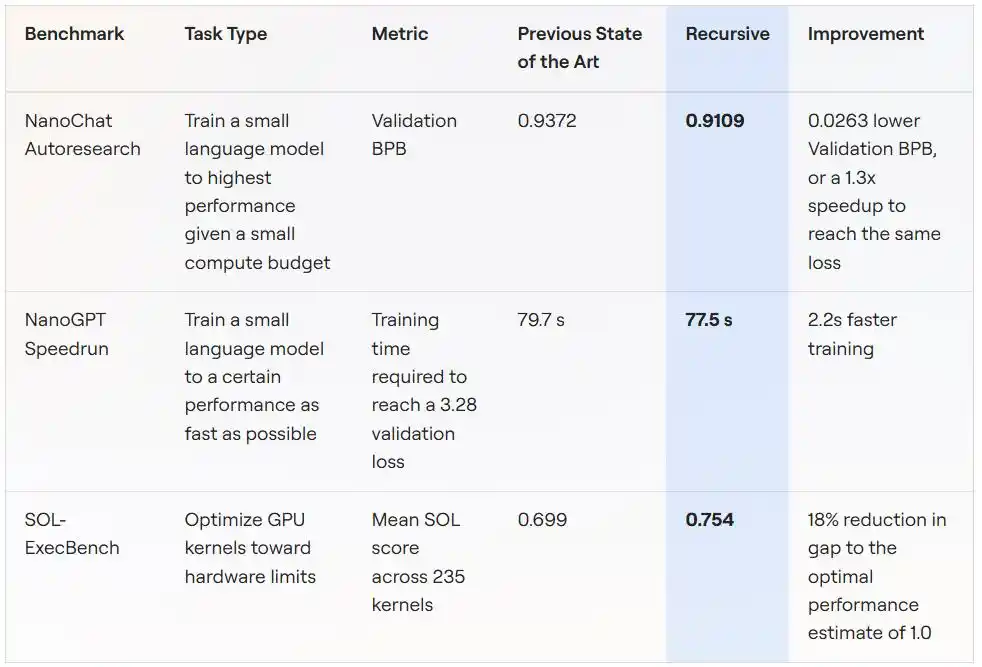
Tình huống một: Huấn luyện mô hình nhỏ với ngân sách tính toán cố định (NanoChat Autoresearch)
Quy tắc của bài kiểm tra chuẩn này đến từ dự án autoresearch do Andrej Karpathy (tác giả GPT-2, đồng sáng lập cũ của OpenAI) khởi xướng: Trên một GPU, với ngân sách huấn luyện cố định là năm phút, huấn luyện một mô hình ngôn ngữ nhỏ tới mức tổn thất kiểm định (validation loss) thấp nhất có thể (đo bằng BPB, càng thấp càng tốt).
Tình huống này tự nhiên phù hợp với nghiên cứu tự động hóa: Chu kỳ thử nghiệm ngắn, phương sai chỉ số thấp, hành vi gian lận tương đối dễ phát hiện. Chính vì vậy, một dự án cộng đồng có tên "autoresearch@home" đã chạy trên chuẩn này trong một thời gian dài — hàng chục nhà nghiên cứu con người cộng tác với hàng trăm tác nhân thông minh AI, liên tục đẩy chỉ số xuống.
Hệ thống của Recursive xuất phát từ cùng mã nguồn ban đầu, cuối cùng đã đẩy BPB kiểm định từ mức tốt nhất của cộng đồng là 0.9372 xuống 0.9109, cải thiện 0.0263 BPB. Chuyển sang cách nói khác: Với chất lượng huấn luyện tương đương, giải pháp của Recursive chỉ cần thời gian huấn luyện ít hơn 1.3 lần so với đối thủ để đạt được.
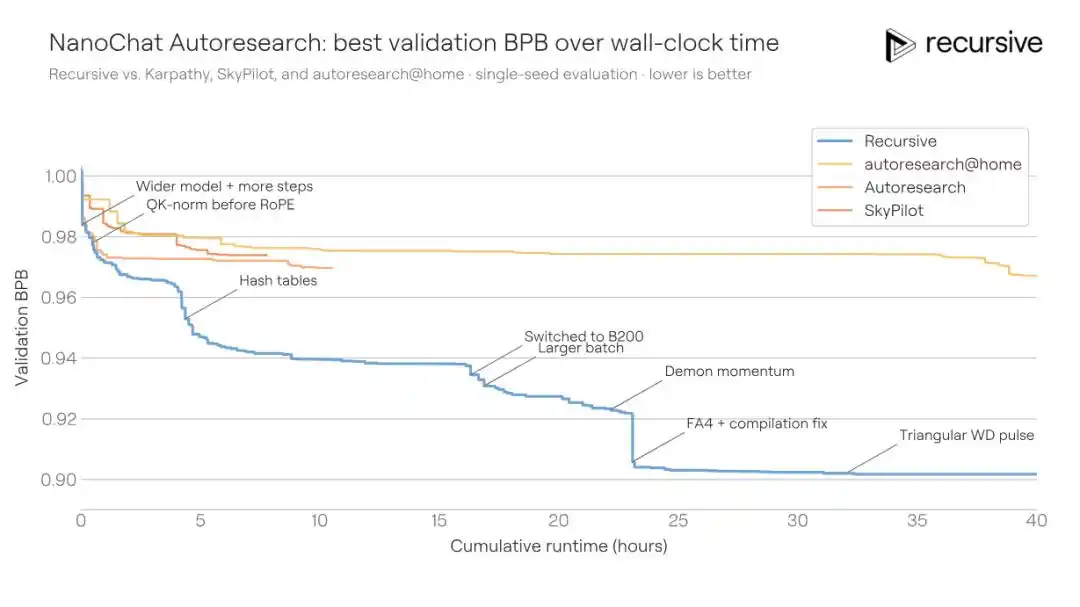
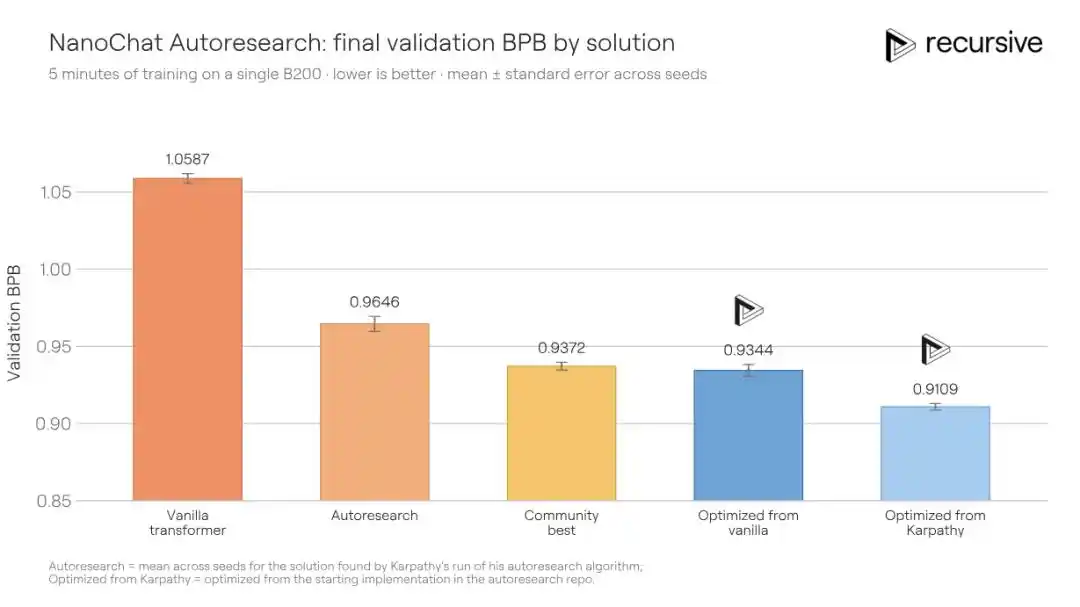
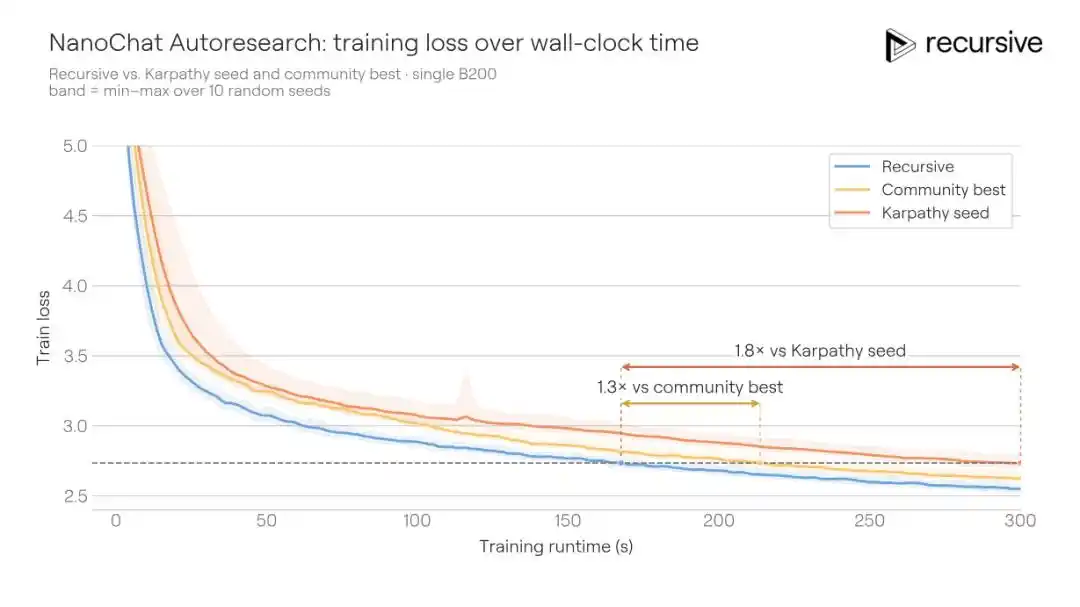
Các cải tiến mà hệ thống phát hiện không phải là một chiêu thức chiến thắng duy nhất. Nó kết hợp các thay đổi ở nhiều nơi như điều chỉnh kiến trúc, tổn thất phụ trợ, thay đổi cơ chế chú ý, hành vi bộ tối ưu hóa, lập lịch suy giảm trọng số, cài đặt trình biên dịch... Một phát hiện then chốt trong số đó, là một cơ chế ghi nhớ ngữ cảnh ngắn phong phú hơn: Trong đường dẫn giá trị (value path) của cơ chế chú ý, thông qua bảng băm (hash table) nhúng đồng thời thông tin bigram (cặp từ liền kề) và trigram (bộ ba), và sử dụng cổng có thể học (learnable gating) để trộn có trọng số. Các lớp Transformer khác nhau sử dụng các hàm băm khác nhau, từ đó giảm xác suất va chạm lặp lại xuyên lớp.
Kỹ thuật này có liên quan về khái niệm với các công trình như DeepSeek Engram, nhưng hệ thống đã triển khai nó dưới dạng một biến thể cụ thể chưa thấy trong tài liệu công khai vào tình huống ngân sách cố định.
Tình huống hai: Chạy đua giới hạn tốc độ huấn luyện (NanoGPT Speedrun)
Nếu nói tình huống trước là "tiến thêm một bước" trên thành quả của một cộng đồng năng động, thì tình huống này khó hơn nhiều.
NanoGPT Speedrun là một chuẩn khác do Karpathy khởi xướng, được cộng đồng liên tục tối ưu hóa trong hơn hai năm: Trên 8 GPU H100, thời gian ngắn nhất cần thiết để huấn luyện một mô hình GPT đạt mức tổn thất kiểm định 3.28. Kể từ giữa năm 2024, cộng đồng đã thông qua 83 đóng góp được ghi nhận để nén thời gian từ khoảng 45 phút xuống còn 79.7 giây. Mỗi giải pháp mới đều cần phải vắt kiệt thêm thời gian trên nền mã đã được tối ưu hóa cực độ, độ khó có thể tưởng tượng.
Hệ thống của Recursive xuất phát từ giải pháp tối ưu hiện có, một lần nữa nén thời gian huấn luyện xuống còn 77.5 giây, tiết kiệm 2.2 giây. Điều này tương đương hoặc thậm chí tốt hơn mức độ cải tiến mà các nhà đóng góp con người gần đây có thể làm được.
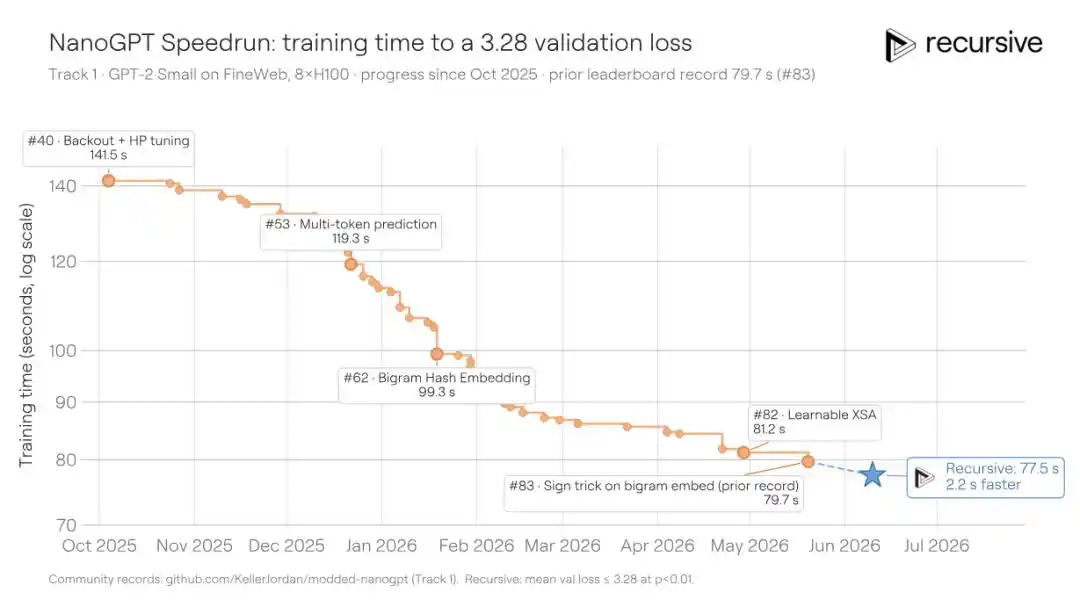
Kỹ thuật cốt lõi mà hệ thống tìm thấy lần này bao gồm:
Tính toán cơ chế chú ý với độ chính xác FP8. Giải pháp cộng đồng chỉ sử dụng tính toán FP8 (dấu phẩy động 8 bit) ở lớp cuối cùng của mô hình (ngôn ngữ mô hình đầu), trong khi hệ thống mở rộng FP8 vào tính toán ma trận trong lớp chú ý, lan truyền tiến (forward propagation) dùng FP8 để đạt thông lượng Tensor Core gấp đôi, lan truyền ngược (backward propagation) giữ BF16 để duy trì tính ổn định.
Nhiễu khám phá ủ (annealing exploration noise) trong bộ tối ưu hóa. Hệ thống tiêm nhiễu Gaussian có giá trị trung bình bằng 0 vào các bước cập nhật của bộ tối ưu hóa NorMuon, biên độ nhiễu giảm dần tuyến tính về 0 theo tiến độ huấn luyện. Điều này giống như cho bộ tối ưu hóa một chế độ hành vi "khám phá mạnh dạn trước, hội tụ ổn định sau", giúp nghiệm cuối cùng rơi vào một lòng chảo tổn thất (loss basin) bằng phẳng hơn.
Lõi MLP hợp nhất (fused) tinh gọn hơn. Hệ thống viết lại một lõi GPU Triton, để lan truyền tiến chỉ lưu trữ giá trị kích hoạt sau khi bình phương ReLU, lan truyền ngược tính toán lại các kết quả trung gian chưa bình phương bên trong lõi, tiết kiệm một chuyến đi lại đọc-ghi hoàn chỉnh của tensor kích hoạt trong bộ nhớ video băng thông cao — đây là tăng tốc trực tiếp ở cấp độ phần cứng.
Ba cải tiến, thuộc về ba lĩnh vực chuyên môn khác nhau: chiến lược độ chính xác, thiết kế bộ tối ưu hóa, lập trình lõi GPU. Việc hệ thống tìm thấy không gian trên kết quả tối ưu hóa hai năm của cộng đồng, tự nó đã nói lên vấn đề.
Tình huống ba: Tối ưu hóa lõi GPU (SOL-ExecBench)
Hai tình huống trước làm việc ở cấp độ huấn luyện mô hình, tình huống thứ ba đi sâu xuống tầng thấp hơn: Tối ưu hóa lõi tính toán GPU.
SOL-ExecBench là bài kiểm tra chuẩn do NVIDIA đưa ra, bao gồm 235 nhiệm vụ viết lõi, bao phủ nhiều loại tải công việc thực tế như nhân ma trận, rút gọn (reduction), lớp chuẩn hóa, thành phần chú ý, các thủ tục lượng tử hóa, khối hợp nhất... Tiêu chuẩn chấm điểm là điểm SOL: 0.5 tương ứng với triển khai PyTorch chuẩn, 1.0 tương ứng với giới hạn lý thuyết phần cứng. Kết quả công khai tốt nhất trước đây là 0.699.
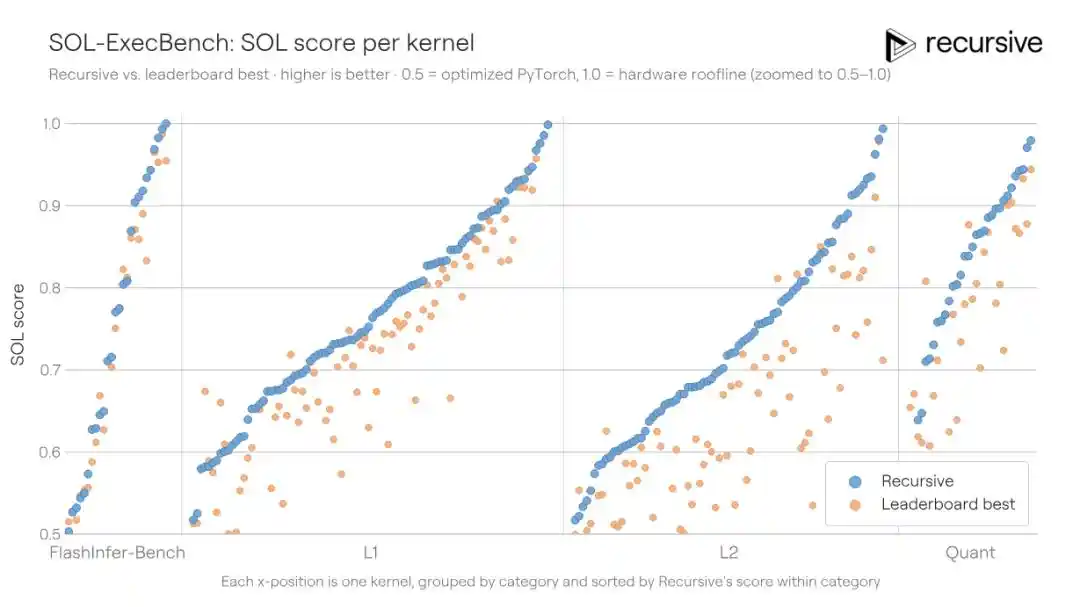
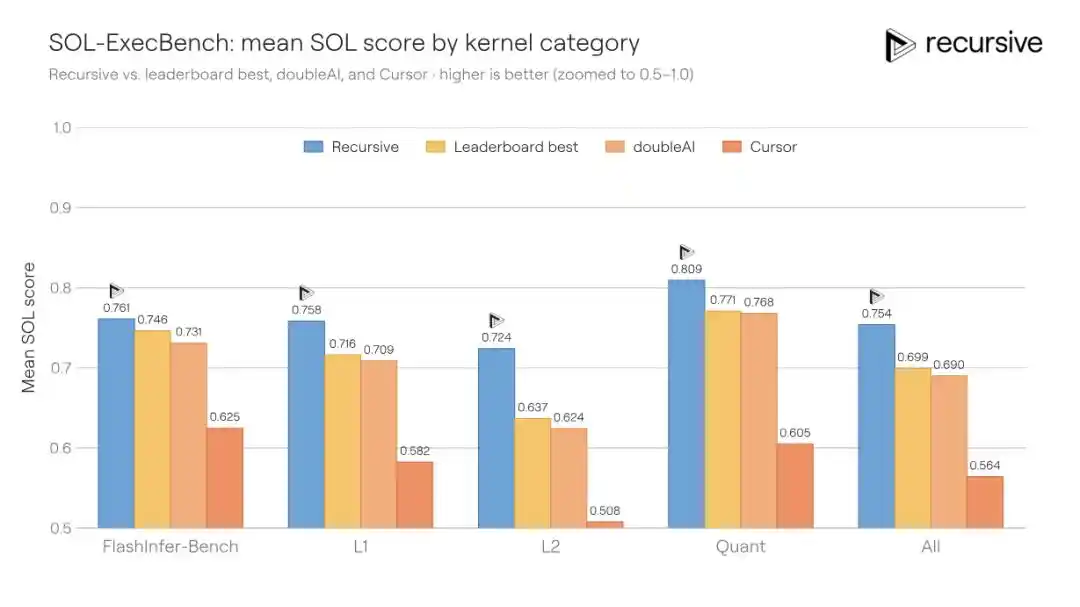
Hệ thống của Recursive chạy tổng thể trên 235 lõi, cho phép tái sử dụng các mẫu tối ưu hóa được phát hiện xuyên nhiệm vụ (ví dụ: chiến lược vận chuyển bộ nhớ, cách phân khối, kỹ thuật rút gọn), cuối cùng nâng điểm số lên 0.754, thu hẹp khoảng cách tới giới hạn phần cứng thêm 18%.
Tình huống này có ý nghĩa đặc biệt, vì kỹ thuật lõi là lĩnh vực cực kỳ chuyên môn hóa cao — số kỹ sư có thể viết lõi Triton/CUDA hiệu quả trên toàn cầu cũng rất hiếm. Và đội ngũ Recursive thừa nhận thẳng thắn trong blog rằng, bản thân họ cũng không phải là chuyên gia trong lĩnh vực lõi, "Những ý tưởng này đến từ hệ thống tự thân, chứ không phải từ nền tảng chuyên môn của chúng tôi."
Recursive: Dùng AI để nghiên cứu cải tiến đệ quy AI
Công ty công bố thành quả này, Recursive Superintelligence, được thành lập vào cuối năm 2025 đến đầu năm 2026, chỉ mới kết thúc trạng thái "stealth" vào tháng trước. Các thành viên sáng lập ngoài Tian Yuandong (Tian Yuandong), Giám đốc khoa học nghiên cứu cũ tại Meta FAIR, còn bao gồm:
Richard Socher, CEO Recursive, cựu Giám đốc khoa học tại Salesforce
Alexey Dosovitskiy, cựu nhà khoa học nghiên cứu tại Google DeepMind và là tác giả đầu tiên của Vision Transformer, số trích dẫn học thuật Google hơn 160,000
Tim Rocktäschel, cựu nhà khoa học cấp cao (Principal) tại DeepMind và là Giáo sư AI tại UCL
Peter Norvig, cựu Giám đốc nghiên cứu tại Google, đồng tác giả với Stuart Russell cuốn sách giáo khoa nổi tiếng trong lĩnh vực AI "Artificial Intelligence: A Modern Approach" (Trí tuệ nhân tạo: Một cách tiếp cận hiện đại)
Caiming Xiong, cựu Phó chủ tịch AI tại Salesforce
Tim Shi, cựu nhà nghiên cứu tại OpenAI, đồng sáng lập & CTO công ty AI doanh nghiệp Cresta
Josh Tobin, CTO Recursive, cựu Trưởng nhóm nghiên cứu tại OpenAI và Uber ATG
Jeff Clune, cựu Phó chủ tịch nghiên cứu tại Google DeepMind, Giáo sư Khoa học Máy tính tại Đại học British Columbia, Canada
Và công ty khởi nghiệp này ngay khi xuất hiện, thậm chí chưa có một sản phẩm công khai nào, đã nắm trong tay 650 triệu USD tài trợ, định giá lên tới 4.65 tỷ USD, do GV (Google Ventures) và Greycroft dẫn đầu, NVIDIA và AMD Ventures tham gia theo.
Mục tiêu cốt lõi của công ty tương ứng trực tiếp với tên gọi: Xây dựng các hệ thống AI có thể đệ quy nâng cao năng lực nghiên cứu của chính chúng, để AI tham gia và tăng tốc quá trình nghiên cứu và phát triển của chính AI, cuối cùng hình thành một vòng lặp tự tăng cường liên tục.
Để biết thêm chi tiết, xem bài báo "Sau khi rời Meta, Tian Yuandong (Tian Yuandong) vừa công bố khởi nghiệp".
Tất nhiên, ở cấp độ đường đua, Recursive không đơn độc. AMI Labs của Yann LeCun đã hoàn thành vòng tài trợ 1 tỷ USD vào tháng 3 năm nay, Ineffable Intelligence của David Silver đã nhận được 1.1 tỷ USD vòng hạt giống vào tháng 4, đều hướng tới một hướng đi tương tự: Để hệ thống AI tự tạo ra tri thức, giảm sự can thiệp của con người trong quy trình nghiên cứu. Nhưng về nhịp độ công bố thành quả, "Bước đầu tiên" này của Recursive có lẽ là một trong những minh chứng công nghệ cụ thể và có thể tái hiện nhất trong số các công ty cùng loại hiện nay.
Bình minh của mô hình đệ quy
Thành quả này mà Recursive phát hành, đặt trong bối cảnh ngành công nghiệp vĩ mô hơn, đại diện cho sự triển khai ban đầu của một mô hình nghiên cứu và phát triển AI mới: Để hệ thống AI tự thân đảm nhận vai trò chủ thể nghiên cứu.
Logic cốt lõi của loại "AI đệ quy" này không phức tạp: AI nâng cao năng lực nghiên cứu AI, AI được cải tiến lại có thể nâng cao hiệu quả hơn nữa chính nó, lặp đi lặp lại. Nó không phụ thuộc vào một đột phá đơn lẻ nào, mà phụ thuộc vào một hệ thống liên tục tạo ra đột phá.
Cách suy nghĩ này có ý nghĩa quan trọng đối với kinh tế học của chính nghiên cứu AI. Quy trình huấn luyện các mô hình tiên phong vẫn phụ thuộc cao độ vào một số ít nhà nghiên cứu có kỹ năng đặc thù, và số người có thể đảm nhận công việc này trên toàn cầu không quá vài nghìn. Nếu hệ thống nghiên cứu tự động hóa có thể tiếp quản dù chỉ một phần công việc đó, tốc độ tiến bộ và đường cong chi phí của AI sẽ thay đổi.
Nhận định này cũng tạo thành tiếng vọng với các ý kiến khác gần đây từ ngành công nghiệp. Ví dụ như bài "When AI Builds Itself" của Anthropic được nhắc ở đầu bài viết này, giọng điệu không hề nhẹ nhàng — nó kêu gọi sự phối hợp ngành, để có các tùy chọn tạm hoãn hoặc thậm chí tạm dừng phát triển AI tiên phong khi thời điểm cải tiến tự thân đệ quy đến, để dành thời gian cho cấu trúc xã hội và nghiên cứu căn chỉnh (alignment research) theo kịp tiến độ. Để biết thêm chi tiết, vui lòng tham khảo "Tự tiến hóa AI quá nhanh, Anthropic kêu gọi toàn cầu tạm dừng nghiên cứu phát triển".

https://www.anthropic.com/institute/recursive-self-improvement
Hai sự việc xảy ra đồng thời, đáng suy ngẫm. Một bên là Anthropic đang ghi chép và cảnh báo hướng đi của con đường này, bên kia là các đội ngũ như Recursive, đang từng bước biến con đường này thành hiện thực.
Tất nhiên, Recursive tự thân cũng thừa nhận, đây vẫn chỉ là "bước đầu tiên": Hệ thống hiện tại hoạt động tốt nhất trong các tình huống có chỉ số rõ ràng, phản hồi nhanh, gian lận có thể phát hiện, khoảng cách với việc tự động thúc đẩy các vấn đề khoa học mở còn khá xa. Việc phòng chống gian lận phần thưởng sẽ là thách thức cốt lõi liên tục đối mặt trên con đường mở rộng quy mô.
Nhưng một vòng lặp đã bắt đầu vận hành. Câu hỏi tiếp theo, chỉ là nó sẽ quay nhanh đến mức nào.
Bài viết này đến từ tài khoản WeChat công khai "Machine Heart" (机器之心, ID:almosthuman2014), tác giả: Machine Heart trong quá trình tiến hóa đệ quy, biên tập: Panda






