Văn | Tự mẫu AI
Mỗi khi có một mô hình tiên phong được công bố, giới AI lại dán mắt vào mấy tấm bảng điểm quen thuộc.
MMLU-Pro, MMMU, MMMU-Pro... Những cái tên này có thể xa lạ với người dùng phổ thông, nhưng đối với các công ty mô hình và nhà nghiên cứu, chúng hầu như đã trở thành những "môn thi tiêu chuẩn". GPT, Claude, Gemini, Llama, Qwen, DeepSeek liên tục nộp bài trên những nền tảng đánh giá này.
"Lừa hay ngựa, cứ kéo ra mà biết", chất lượng mô hình thế nào, thường đều phải dựa vào những điểm số này để chứng minh.
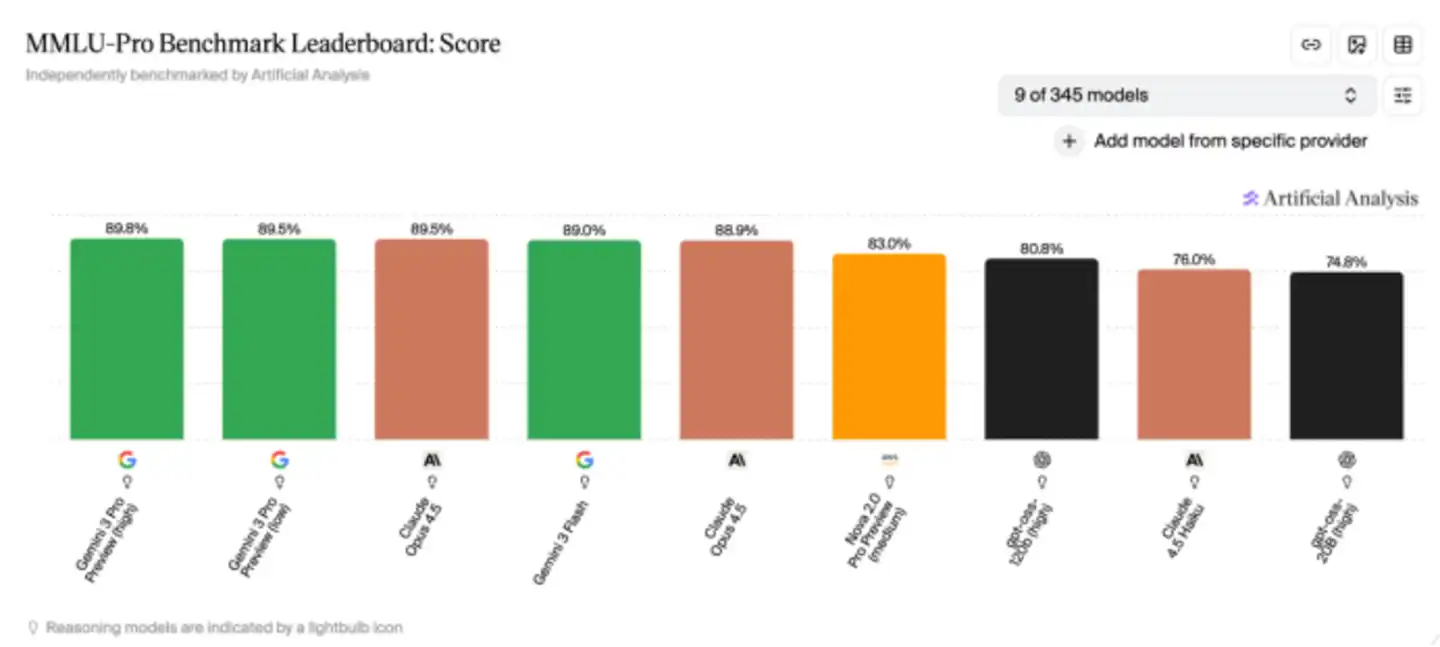
Nhiều biểu đồ so sánh hiệu năng trong các buổi ra mắt mô hình đều không thể thiếu chúng; một số bảng xếp hạng trên HuggingFace cũng được xây dựng dựa trên các hệ thống đánh giá này. Thậm chí có thể nói, ngành công nghiệp AI ngày nay khi thảo luận về năng lực mô hình, đang sử dụng một ngôn ngữ chung được định nghĩa bởi các tiêu chuẩn đánh giá này.
Nhưng điều thú vị là, hầu như mọi người đều chỉ quan tâm đến điểm số, lại rất ít người biết người ra đề là ai. Và đằng sau MMLU-Pro, MMMU và MMMU-Pro, đều có thể thấy cùng một cái tên - Chen Wenhu (Trần Văn Hổ).
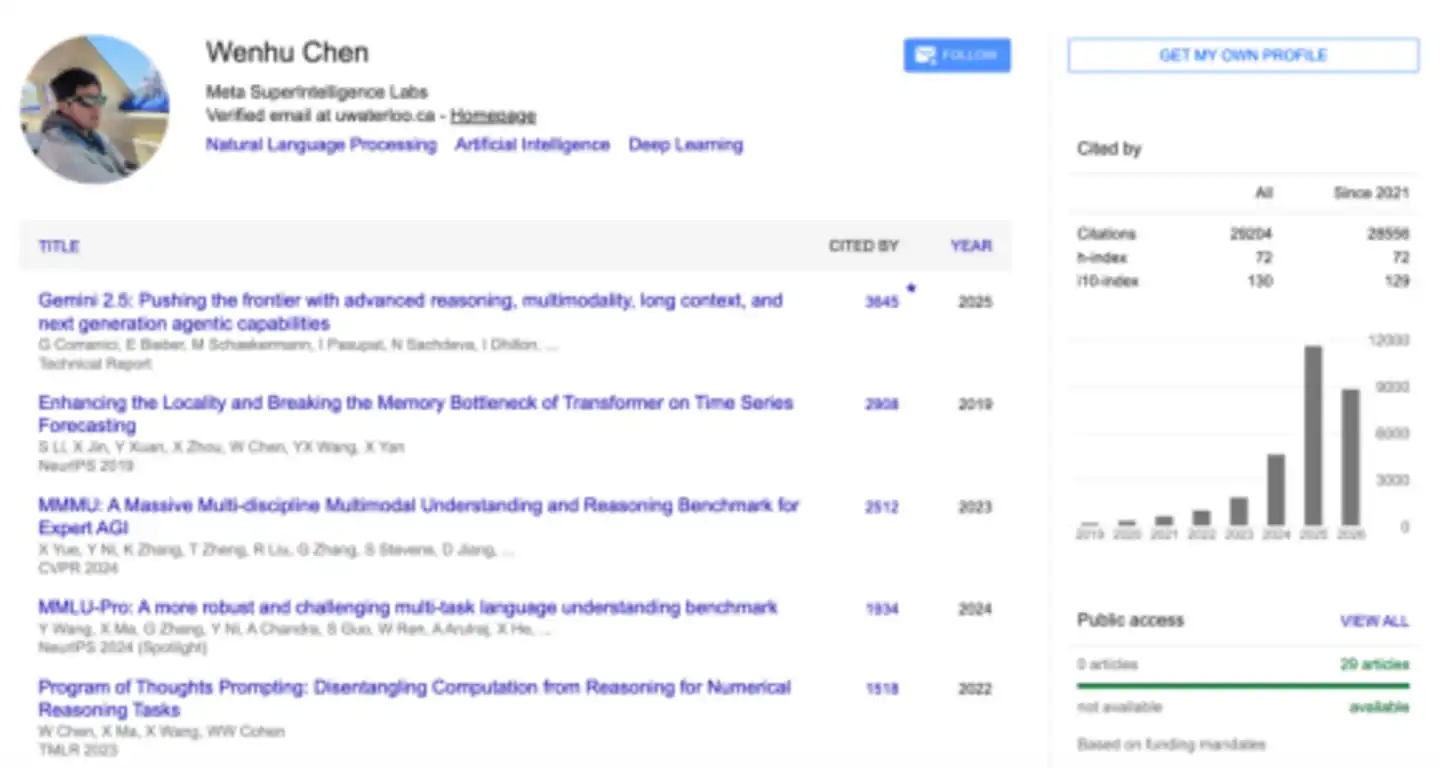
Ông là Trợ lý Giáo sư tại Khoa Khoa học Máy tính, Đại học Waterloo, Canada, trên Google Scholar, các bài báo của ông đã được trích dẫn hơn 30.000 lần.
Ông cũng là người sáng lập "TIGERLab", tên tiếng Anh đầy đủ của phòng thí nghiệm này là Text and Image GEnerative Research Lab, vì trong tên có chữ "Hổ", Chen Wenhu đã đặt cho nó một tên tiếng Trung rất dễ nhận biết - Hổ Đầu Bang (Bang Đầu Hổ).
Sau khi tờ đề thi cũ mất tác dụng
Chen Wenhu lần đầu được nhiều người chú ý đến, là vì MMLU-Pro.
MMLU từng là một trong những tiêu chuẩn đánh giá cơ bản phổ biến nhất để đánh giá năng lực mô hình ngôn ngữ lớn. Nó giống như một bài kiểm tra tổng hợp, bao phủ nhiều môn học, dùng để đo lường biểu hiện của mô hình trong các nhiệm vụ hiểu biết kiến thức và suy luận.
Trong giai đoạn đầu, tờ đề thi này rất hữu ích. Khoảng cách giữa các mô hình có thể được thể hiện rõ qua điểm số, ngành công nghiệp cũng có thể thông qua nó để quan sát xem mô hình ngôn ngữ lớn có thực sự tiến bộ hay không.
Nhưng vấn đề nhanh chóng xuất hiện.
Khi năng lực mô hình không ngừng nâng cao, MMLU dần trở nên "không đủ khó để thi". Điểm số của các mô hình tiên tiến ngày càng cao, khoảng cách giữa chúng ngày càng nhỏ.
Đến khi OpenAI công bố o3, vấn đề này càng trở nên rõ rệt hơn. Độ chính xác của o3 trên MMLU đã gần đạt 100%, các mô hình tiên tiến khác cũng lần lượt cho ra kết quả gần đạt điểm tối đa.
Nghe thì có vẻ là một tin tốt, nhưng đối với việc đánh giá, điều này lại mang đến phiền phức.
Một bài thi nếu mọi người đều có thể đạt điểm gần tối đa, thì rất khó để tiếp tục đánh giá ai mạnh hơn, mạnh ở điểm nào. Nó vẫn có thể chứng minh mô hình đã có một số năng lực nhất định, nhưng không còn phù hợp để đo lường sự tiến bộ mới.
Ngành công nghiệp AI cần một tờ đề thi khó hơn, và cũng khó bị "qua mặt" hơn.
Năm 2024, Chen Wenhu và nhóm của ông đã cho ra mắt MMLU-Pro.
MMLU-Pro đã thiết kế lại tờ đề thi này, thay vì chỉ đơn giản mở rộng ngân hàng câu hỏi.
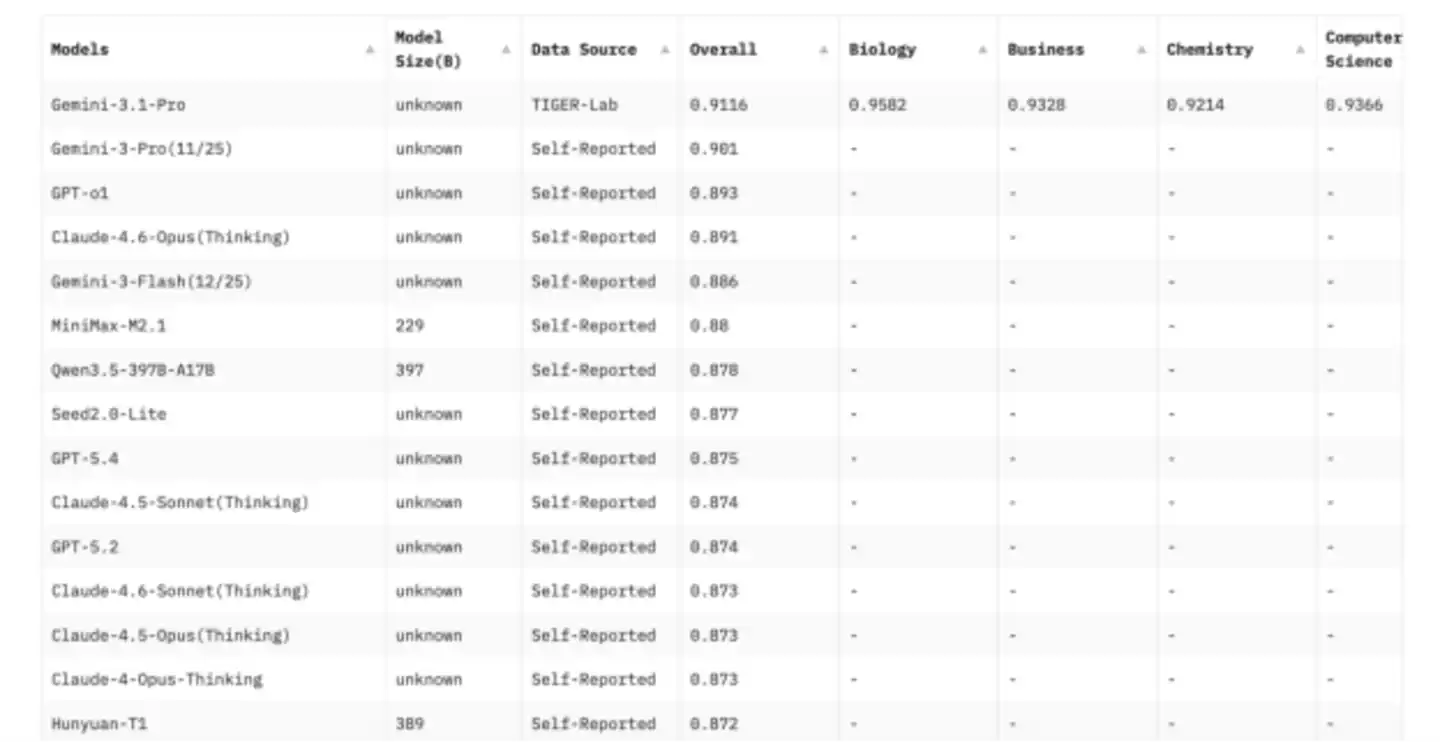
Nó chứa 12032 câu hỏi, bao phủ 14 lĩnh vực như toán học, vật lý, hóa học, luật, kỹ thuật, tâm lý học, sức khỏe... So với phiên bản MMLU gốc, nó mở rộng lựa chọn từ 4 lên 10 đáp án, giảm xác suất mô hình đoán đúng bằng may rủi; đồng thời bổ sung thêm nhiều câu hỏi thiên về suy luận, loại bỏ những câu hỏi tương đối đơn giản, gây nhầm lẫn hoặc không đủ khả năng phân biệt trong ngân hàng câu hỏi cũ.
Hiệu quả rất trực tiếp.
Kết quả nghiên cứu cho thấy, độ chính xác của mô hình trên MMLU-Pro so với MMLU gốc đã giảm từ 16% đến 33%. Khi kiểm tra cùng một mô hình với 24 phong cách gợi ý khác nhau, sự dao động điểm số cũng giảm từ 4% đến 5% của MMLU gốc xuống còn khoảng 2%.
Nghĩa là, tờ đề thi mới này không chỉ khó hơn, mà còn ổn định hơn.
Nó giúp tạo ra khoảng cách trở lại giữa các mô hình vốn trên tờ đề thi cũ có vẻ đều xuất sắc. Việc mô hình thực sự có khả năng suy luận, hay chỉ là giỏi đối phó với đề cũ, cũng vì thế mà dễ dàng được phát hiện hơn.
Tiêu chuẩn đánh giá hữu dụng
MMLU-Pro nhanh chóng được ngành công nghiệp sử dụng.
MMLU-Pro sau đó đã tham gia tuyến Đánh giá Tập dữ liệu và Tiêu chuẩn tại NeurIPS2024, cũng được tích hợp vào khung đánh giá mô hình ngôn ngữ lm-evaluation-harness của EleutherAI. Đối với cộng đồng mô hình mã nguồn mở, điều này có nghĩa nó không còn chỉ là một tập dữ liệu trong bài báo nghiên cứu, mà đã bước vào chuỗi công cụ đánh giá thông dụng.
Nhiều bản phát hành mô hình bắt đầu báo cáo điểm số MMLU-Pro. Một số bảng xếp hạng trên HuggingFace cũng đưa nó vào hệ thống đánh giá.
Nếu nói MMLU-Pro giải quyết vấn đề "tờ đề thi cũ mất tác dụng" trong đánh giá mô hình ngôn ngữ, thì MMMU đã đưa Chen Wenhu và TIGERLab vào trung tâm của đánh giá đa phương thức.
Vấn đề của mô hình đa phương thức còn phức tạp hơn.
Mô hình ngôn ngữ trả lời câu hỏi, chủ yếu xử lý văn bản. Mô hình đa phương thức thì phải đồng thời xử lý thông tin dưới các hình thức khác nhau như hình ảnh, biểu đồ, sơ đồ minh họa, bản đồ, bảng biểu, bản nhạc, cấu trúc hóa học... Nó không chỉ cần hiểu câu hỏi, mà còn phải thực sự hiểu nội dung trong hình ảnh, và đặt thông tin thị giác, thông tin văn bản cùng kiến thức môn học lại với nhau để suy luận.
Tiêu chuẩn đánh giá MMMU chứa 11.500 câu hỏi đa phương thức, lấy từ đề thi đại học, bài kiểm tra và giáo trình, bao phủ sáu lĩnh vực lớn: Nghệ thuật & Thiết kế, Kinh doanh, Khoa học, Sức khỏe & Y học, Nhân văn & Xã hội học, Công nghệ & Kỹ thuật, được chia nhỏ thành 30 môn học và 183 lĩnh vực phụ.
Những câu hỏi này không chỉ đơn giản hỏi mô hình "trong hình có gì", nó yêu cầu mô hình giống như sinh viên làm bài chuyên môn, kết hợp thông tin hình ảnh và kiến thức môn học.
Khi MMMU được công bố, nhóm nghiên cứu đã thử nghiệm 14 mô hình đa phương thức mã nguồn mở, cùng các mô hình mã đóng tiêu biểu như GPT-4V, GeminiUltra. Ngay cả những mô hình mã đóng mạnh nhất lúc đó, GPT-4V và GeminiUltra, cũng chỉ đạt độ chính xác lần lượt là 56% và 59%.
Những con số này cho thấy, mô hình đa phương thức trông có vẻ tiến bộ nhanh, nhưng trên những vấn đề thực sự cần sự hiểu biết chuyên môn và suy luận, vẫn còn rất nhiều không gian để cải thiện.
Sau này, nhóm của Chen Wenhu lại cho ra mắt MMMU-Pro, tiếp tục bịt lỗ hổng cho mô hình bỏ qua thông tin thị giác. Nó lọc bỏ những câu hỏi chỉ cần mô hình văn bản cũng có thể trả lời, mở rộng các lựa chọn, và giới thiệu thiết lập chỉ-vision, nhúng câu hỏi vào hình ảnh, yêu cầu mô hình đồng thời hoàn thành việc đọc hình ảnh và hiểu văn bản.
Nói đơn giản, là không cho phép mô hình "chỉ đọc văn bản để đoán đáp án".
Loại công việc này nghe có vẻ khá rườm rà, nhưng chúng lại rất quan trọng. Bởi vì mô hình đa phương thức trong tương lai sẽ đi vào các tình huống như y tế, giáo dục, nghiên cứu khoa học, thiết kế, kỹ thuật, chỉ có khả năng mô tả hình ảnh là không đủ. Nó phải có khả năng phán đoán, suy luận, giải thích, và cũng phải có thể tìm ra phần thông tin thực sự hữu ích trong thông tin thị giác phức tạp.
Con người đằng sau "tờ đề thi"
Sau này, Chen Wenhu làm MMLU-Pro và MMMU, xuất phát từ hướng nghiên cứu mà ông vẫn theo đuổi.

Sở thích nghiên cứu của ông vốn dĩ có liên quan đến việc hiểu thông tin phức tạp, hỏi đáp tri thức và suy luận.
Ông tốt nghiệp cử nhân tại Đại học Khoa học và Công nghệ Hoa Trung, sau đó đến Đại học Công nghệ RWTH Aachen, Đức học thạc sĩ, rồi đến Đại học California, Santa Barbara để lấy bằng Tiến sĩ Khoa học Máy tính. Trong thời gian học tiến sĩ, ông đã bắt đầu nghiên cứu xoay quanh các hướng như hỏi đáp phức tạp, suy luận bảng biểu, định vị bằng chứng tri thức.
Loại nhiệm vụ này có một điểm chung: câu trả lời thường không nằm trong một văn bản đơn lẻ.
Nó có thể ẩn trong một bảng biểu, cũng có thể cần kết hợp một đoạn văn bản và một bức ảnh, hoặc có thể yêu cầu mô hình trước tiên truy xuất thông tin, sau đó tổng hợp, tính toán và suy luận. Mô hình không thể chỉ biết lặp lại kiến thức đã có.
Các dự án mà Chen Wenhu từng tham gia như HybridQA, TabFact, ProgramofThoughts, MAmmoTH, đều liên quan đến đường hướng này.
Điều này cũng giải thích vì sao ông lại nhạy cảm với những lỗ hổng trong đánh giá mô hình.
Một tiêu chuẩn đánh giá tốt không phải chỉ đơn giản làm cho câu hỏi ngày càng khó, mà phải dự đoán trước được mô hình dễ "làm đúng câu hỏi", "trông có vẻ biết" nhất ở đâu.
Mô hình có thể đã ghi nhớ ngân hàng câu hỏi, cũng có thể dựa vào lựa chọn để đoán đáp án, còn có thể dùng văn bản để bỏ qua thông tin thị giác... Một đánh giá tốt phải vá tốt những lỗ hổng này.
Sau khi lấy bằng tiến sĩ, Chen Wenhu vào làm tại Google Research, sau đó từ năm 2021 đến 2025 tham gia vào mô hình đa phương thức Gemini và công việc đánh giá của Google DeepMind. Giai đoạn này cũng rất quan trọng. Việc tiếp xúc lâu dài với nghiên cứu và phát triển mô hình tiên tiến, khiến ông hiểu rõ hơn năng lực mô hình đã phát triển như thế nào, và cũng dễ dàng nhìn thấy những sai lệch và điểm mù có thể có trong đánh giá.
Mùa thu năm 2022, Chen Wenhu gia nhập Khoa Khoa học Máy tính, Đại học Waterloo, giữ chức Trợ lý Giáo sư. Cùng năm, ông được chọn vào Canada CIFAR AI Chair. Sau đó, ông thành lập "TIGERLab (tức Hổ Đầu Bang)", tiếp tục nghiên cứu xoay quanh mô hình cơ bản, năng lực đa phương thức và đánh giá tiêu chuẩn.

Hổ Đầu Bang không chỉ làm đánh giá tiêu chuẩn, mà còn nghiên cứu mô hình và hệ thống.
Trong hướng video, UniVideo cố gắng đặt việc hiểu, tạo và chỉnh sửa video vào cùng một khung, để mô hình không chỉ tạo ra một đoạn hình ảnh, mà còn có thể hiểu nội dung, phản hồi chỉ dẫn và hoàn thành chỉnh sửa. Vamba nhắm đến việc hiểu video dài, giải quyết vấn đề bộ nhớ hiển thị, tính toán và hiệu suất huấn luyện mà video cấp độ một giờ mang lại. MoCha hợp tác với đội ngũ AI tạo sinh của Meta, thì đặt trọng tâm vào việc tạo ra nhân vật ảo biết nói, thông qua giọng nói và mô tả văn bản để tạo ra video nhân vật chất lượng cao.
Một người ra đề chưa bao giờ tự làm bài thì không thể ra đề hay được. Việc tự tay làm mô hình, ngược lại cũng khiến họ thích hợp hơn để làm đánh giá.
Bởi vì một đánh giá thực sự tốt, thường xuất phát từ sự hiểu biết về ranh giới năng lực của mô hình. Chỉ khi biết mô hình được tạo ra như thế nào, biết nó sẽ gặp vấn đề gì trong nhiệm vụ thực tế, mới dễ dàng thiết kế ra những câu hỏi có thể đo được khoảng cách, cũng có thể phơi bày vấn đề.
Hiện nay, Chen Wenhu đã gia nhập Phòng thí nghiệm Siêu Trí tuệ của Meta, công việc tiếp tục tập trung vào dữ liệu và đánh giá đa phương thức tiền huấn luyện, và phục vụ cho mô hình cơ bản của Meta.
Ngành công nghiệp AI không thiếu những người được nhìn thấy. Trong ngành AI, ánh đèn sân khấu thường chiếu vào những nhà khởi nghiệp, nhà nghiên cứu nổi tiếng và người phụ trách của các công ty mô hình lớn. Việc ra mắt sản phẩm mới, tin tức huy động vốn, mô hình mã nguồn mở và điều chỉnh đội ngũ, thường dễ thu hút sự chú ý của bên ngoài nhất, cũng khiến những cái tên này dễ dàng đi vào tầm mắt công chúng hơn.
Nhưng trong lĩnh vực AI ngày nay, sự tham gia của nhân tài người Hoa đã vượt xa những vị trí nổi bật nhất này.






