Seorang developer individu, ternyata bisa menembus peringkat teratas di Daftar Trending Models Hugging Face di antara perusahaan-perusahaan besar?!
Ini hari yang biasa, saya juga biasa saja melihat-lihat Daftar Trending Hugging Face.
Peringkat pertama adalah GLM-5.2 dari Zhipu, model open source terbaru mereka, sudah kenal lama, unduhan 60 ribu lebih, tidak mengherankan.
Peringkat kedua adalah Unlimited-OCR dari Baidu, yang baru-baru ini diam-diam di-open source, bisa memparsing lebih dari 40 halaman dokumen sekaligus, unduhan juga sudah mencapai 70 ribu.
Melihat ke bawah, tiba-tiba muncul sebuah akun individu: yuxinlu1.
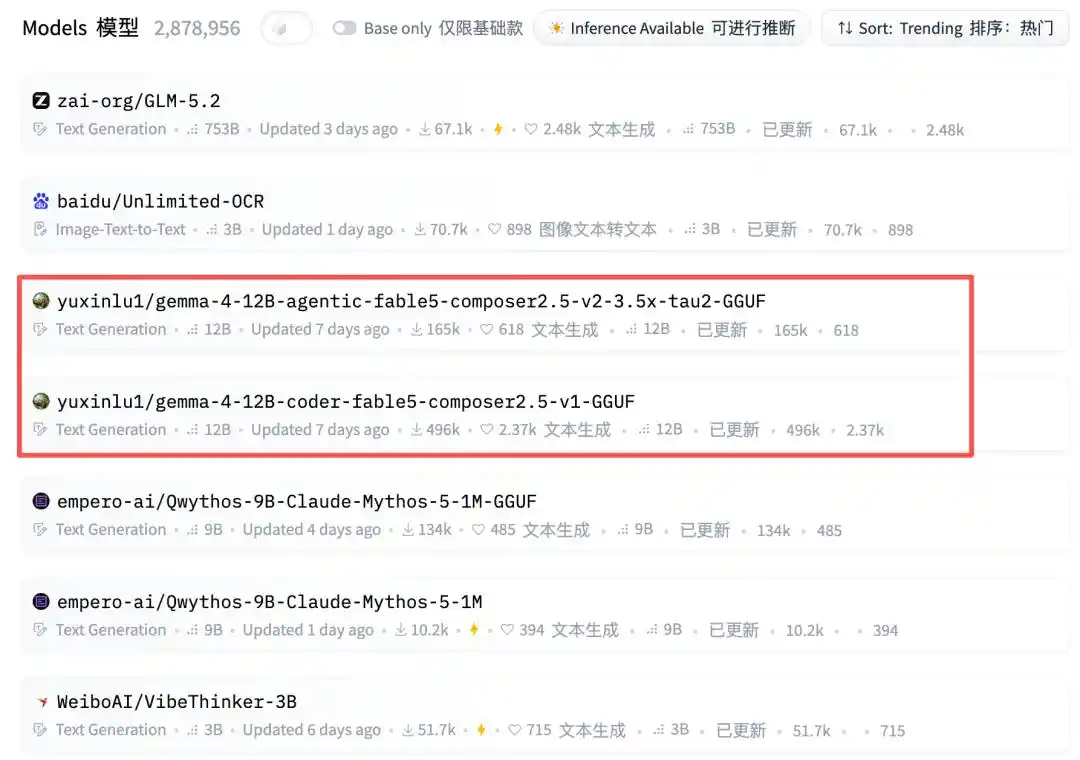
Hmm... hmm?!
Dan langsung mengisi dua posisi.
Melihat lagi jumlah unduhannya — data terbaru sudah mencapai 207 ribu dan 536 ribu. Waduh, model ajaib apa ini?
Bahkan sepekan sebelumnya, model dari developer individu ini sempat menduduki peringkat pertama di Hugging Face, mengalahkan GLM-5.2, sampai kepala Zhipu pun secara terbuka merekomendasikannya di X:
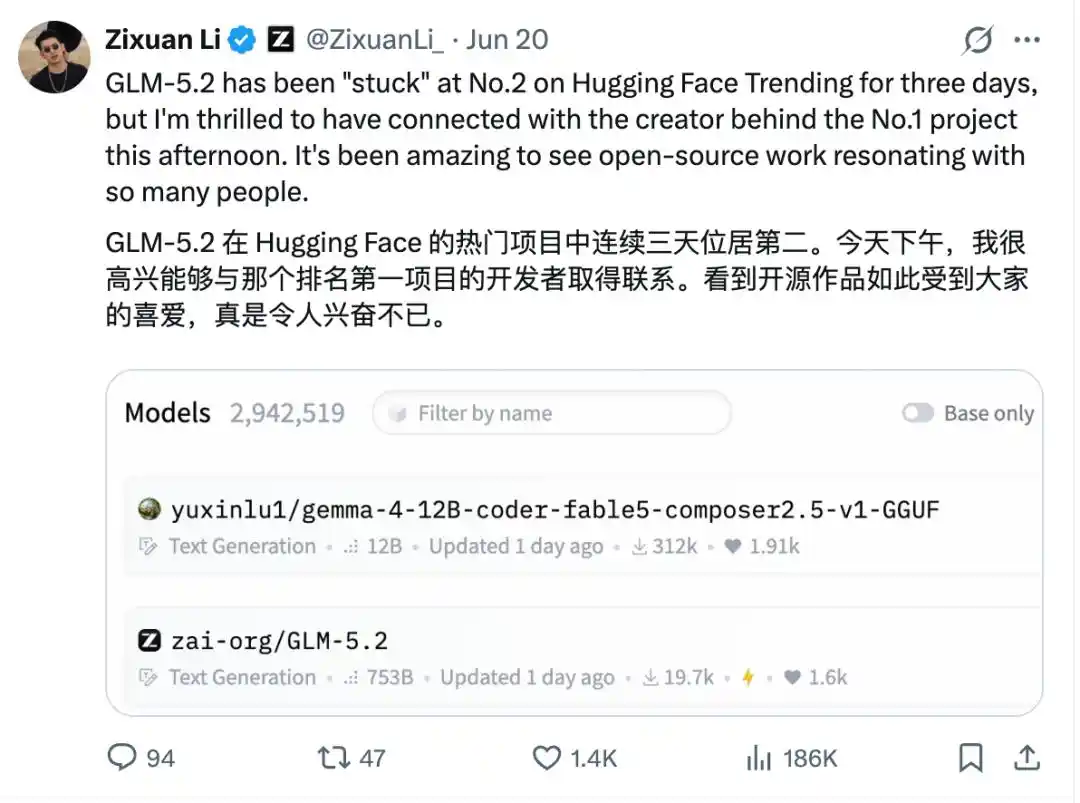
Artinya, di antara nama-nama seperti Zhipu, Baidu, Qwen, NVIDIA... seorang developer individu dengan akunnya bisa menyelip ke TOP, dan unduhannya setinggi itu.
Membuat penasaran: Siapakah sebenarnya luyuxin ini? Bagaimana bisa kekuatannya sebesar ini?
“Model Orang Biasa” Meledak ke Daftar Trending Hugging Face
Gelombang Daftar Trending Hugging Face kali ini, posisi-posisi teratas umumnya ditempati oleh perusahaan besar, tim ternama, dan bidang-bidang yang sedang panas.
Misalnya Zhipu GLM-5.2, parameter super besar 753B, model besar bintang China; Baidu Unlimited-OCR, menginjak arah OCR dan pemahaman dokumen yang sedang panas belakangan ini.
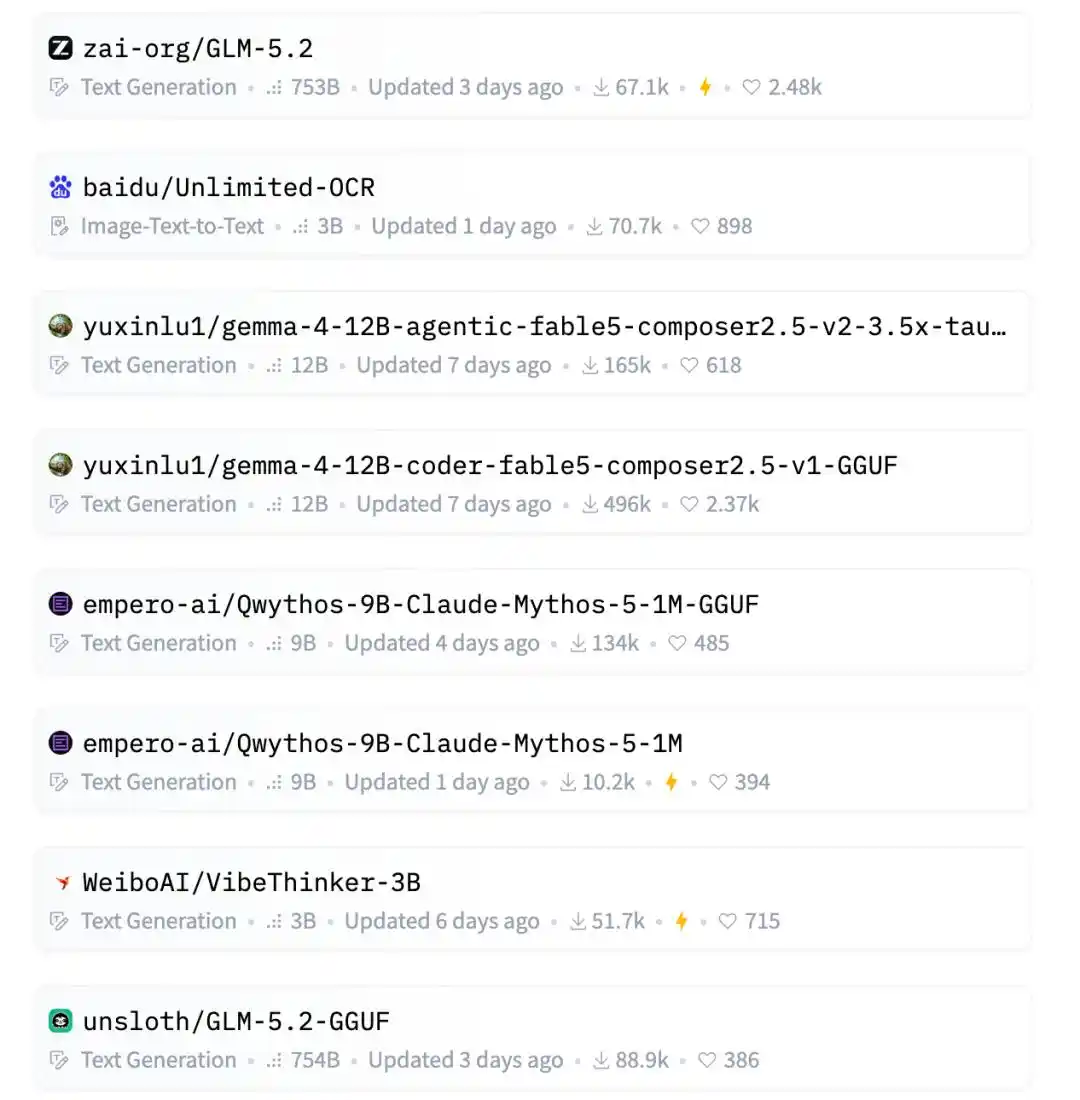
Di bawahnya masih ada AgentWorld dari Qwen, LocateAnything dari NVIDIA, FastContext dari Microsoft.
Wajah-wajah familiar model besar open source China juga ada di daftar: MiniMax M3, Kimi-K2.7-Code, DeepSeek-V4-Pro.
Arah generasi gambar juga ada Krea, model baru Krea-2-Turbo dan Krea-2-Raw juga ada di daftar.
Ternyata di tengahnya masih terselip dua model GGUF 12B dari luyuxin.
Bukan... luyuxin, kau terlalu mencolok ya...
Melihat lebih teliti, dua model baru ini terutama menyuling kemampuan penalaran pemrograman Fable 5, ke dalam sebuah model kecil Gemma4-12B yang bisa dijalankan secara lokal.
Cuma butuh memori grafis 4.5GB untuk menjalankannya, lokal, offline, nol biaya API. Pemain biasa dengan kartu grafis konsumen, bahkan Mac dengan memori terpadu, bisa menjalankannya.
Pembagian kerja kedua model juga berbeda.
V1 adalah versi Coder, fokus menulis kode, memecahkan masalah, menghasilkan kode yang bisa dijalankan.

Menurut kartu model, data pelatihannya adalah penalaran kode yang “dapat diverifikasi”: setiap rantai pemikiran (chain of thought) yang sesuai dengan kode, harus benar-benar telah diuji, lulus tes, baru dipertahankan.
Data guru terutama berasal dari Composer 2.5 Cursor, ditambah Fable 5 — soal yang salah dikerjakan Composer 2.5, akan diserahkan ke Fable 5 untuk dipikir ulang, menghasilkan rantai penalaran baru dan kode yang benar.
Setelah V1 dirilis, pernah bertahan beberapa hari di puncak Daftar Trending Hugging Face.
V2 adalah versi agentic, ditambah kemampuan pemanggilan alat multi-langkah, bisa digunakan sebagai Agent lokal, bisa membaca sendiri, menalar, bertindak, lalu memverifikasi.
Penulis juga menjalankan benchmark — pada subset telecom dari tau2-bench, model dasar gemma-4-12B mendapat skor 15%, model versi V2 mendapat skor 55%, kira-kira 3,5 kali performa dasar.

Tapi penulis juga menyebutkan, ini adalah nilai relatif yang dihasilkan dari pengujian sendiri secara lokal, domain tunggal, 20 tugas, tidak bisa dibandingkan langsung dengan daftar resmi, dia juga mengaku masih ada jarak yang cukup jauh dengan model besar frontier.
Penulis juga menyebut: Fable 5 kemudian diturunkan, hanya datasetnya sendiri yang masih menyimpan proses penalaran “asli” Fable 5 itu.
Sedangkan bagian penalaran yang hilang dari data kontribusi komunitas, dia menggantinya dengan Claude Opus 4.8(xhigh) untuk menghasilkan ulang, melengkapi satu per satu.
Dia juga mengakui, jalur yang dibangun ulang itu “mungkin berbeda dengan versi asli Fable 5”, tapi itu satu-satunya cara yang layak saat itu.
Dia juga mengungkapkan di discussion, data fine-tuning ini sebenarnya hanya sekitar 10 ribu contoh. Dia menekankan, jumlah data tidak sepenting yang dibayangkan orang, yang benar-benar penting adalah kualitas, penyaringan, dan verifikasi.
Alasan lain model ini bisa begitu panas di Hugging Face, ada alasan yang sangat realistis: bisa dijalankan secara lokal.
Kedua model ini adalah versi kuantisasi GGUF.
GGUF adalah format model lokal yang umum di ekosistem llama.cpp, pengguna bisa langsung memuatnya dengan alat seperti llama.cpp, Ollama, LM Studio, Jan, dll.
Ini sangat menarik terutama untuk skenario coding. Bagaimanapun, menulis kode, melihat repositori, menjalankan perintah, debugging, sering melibatkan proyek pribadi dan lingkungan lokal. Bisa dijalankan di mesin sendiri, berarti tidak perlu mengunggah kode ke cloud, juga tidak perlu membayar biaya panggilan API setiap kali.
Yang lebih krusial, ambang batasnya tidak terlalu tinggi.
Di kartu model V1 tertulis, versi terkecil Q2_K sekitar 4.5GB, asalkan memiliki sekitar 4.5GB memori grafis atau memori terpadu, sudah bisa menjalankan asisten pemrograman pribadi dan offline.
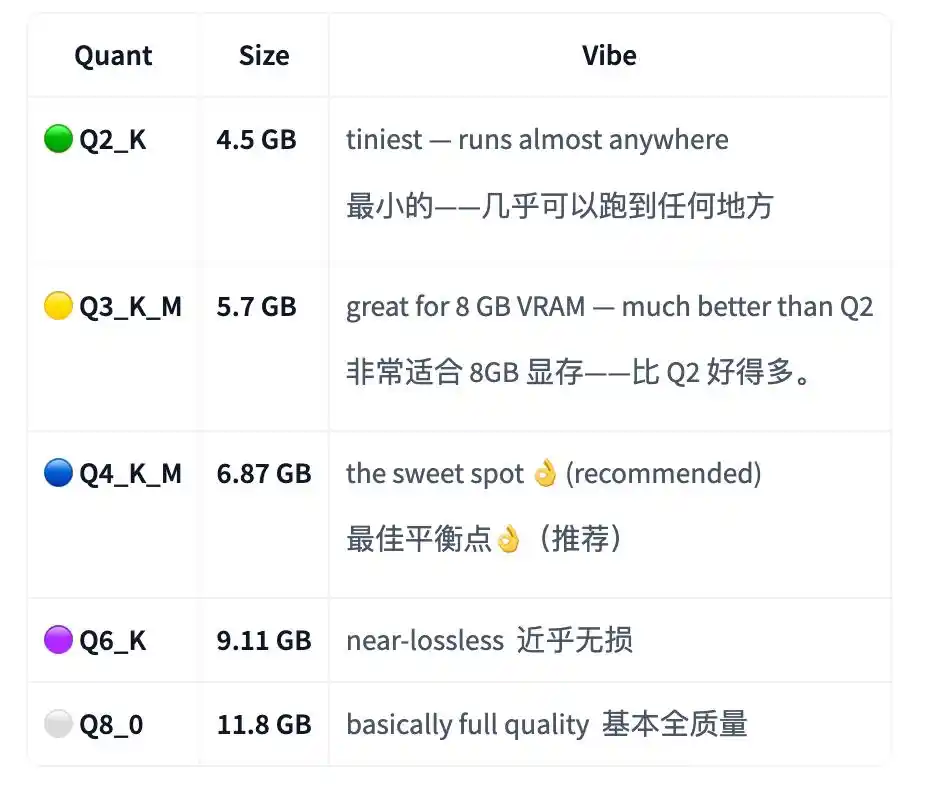
Sweet spot yang direkomendasikan penulis adalah Q4_K_M, ukuran sekitar 6.87GB; Q8_0 yang berkualitas lebih tinggi sekitar 11.8GB.
V2 karena lebih condong ke agentic, penulis tidak menyertakan Q2_K. Alasannya adalah tidak lulus stress test, tidak cukup andal.
Jadi versi terkecil yang andal untuk V2 dimulai dari Q3_K_M, sekitar 5.7GB; Q4_K_M yang direkomendasikan tetap sekitar 6.87GB.
Penulis juga memberikan spoiler untuk rencana selanjutnya — V3 sedang dalam perjalanan.
Dia menyatakan, V3 akan tetap melanjutkan ke arah coding+agentic di jalur 12B ini. Penulis berkata, dia sendiri tidak menyangka peningkatan post-training kali ini begitu besar, jadi selanjutnya akan terus didorong ke depan.
Terutama pada tau2-bench telecom, V2 masih ada masalah “terlalu banyak mencoba, berulang kali retry”, V3 akan terus diperbaiki melalui lebih banyak pelatihan.
Di sisi lain, dia juga sedang mengerjakan versi yang lebih besar: Qwen3.6-27B. Kurang lebih sama dengan menaruh resep coding+agentic yang sama ke dasar yang lebih besar, untuk pengguna dengan memori grafis yang lebih lapang.
Satu Orang, 40 Jam, Menembus ke Tengah-tengah Perusahaan Besar
Bisa sendiri menembus Daftar Trending Hugging Face, unduhan total lebih dari 700 ribu, merebut posisinya di antara perusahaan dan lembaga besar.
Siapa sebenarnya penulis ini?
Setelah menghubungi penulis, QbitAI juga mengetahui kisahnya.
Namanya Lu Yuxin, saat ini adalah mahasiswa pascasarjana di Amerika Serikat yang mengambil arah AI, S1 belajar Data and Business Analysis, di tengahnya juga pernah khusus mengambil satu putaran pengembangan full-stack, belajar frontend, backend, pengembangan perangkat lunak, dan pemrosesan data.
Dua model yang meledak ini, bukanlah pekerjaan utamanya, melainkan proyek pribadi yang sepenuhnya dibiayai sendiri.
“Open source ini sebenarnya hanya mengeluarkan uang, tidak akan memberi Anda penghasilan apa pun.” Dia sangat menyadari hal ini, jadi motivasi awalnya membuat V1 justru adalah “peningkatan diri”:
Pengetahuan yang diajarkan sekolah terlalu lambat diperbarui, saat kuliah S2 profesor masih mengajarkan materi dua tiga tahun yang lalu, sedangkan AI berkembang pesat, dia akhirnya menggunakan proyek ini untuk memaksa dirinya mengejar hal-hal terbaru.

Untuk membuat model-model ini, dia menghabiskan satu paket Claude Max 20×, hanya V2 saja menghabiskan lebih dari 40 jam.
Satu per satu menyintesis data, membersihkan secara manual, melatih, mengevaluasi, melatih lagi, hampir semuanya ditanggung sendiri.
Dari sisi perangkat keras, dia menggunakan satu RTX 5090, memori grafis 32GB VRAM; ditambah sekitar 96GB sumber daya SSD lokal yang bisa digunakan bersama. Skala sumber daya yang bisa digerakkan sebenarnya sekitar 128GB.
Untuk developer individu tidak buruk, tapi sama sekali tidak sebanding dengan kumpulan daya komputasi perusahaan besar dan AI Lab.
Dia memberi tahu QbitAI, yang paling memakan waktu dalam keseluruhan proses sebenarnya bukan pelatihan, melainkan pemrosesan data.
Terutama data agentic, percakapan nyata seringkali panjang, satu tugas mungkin memiliki belasan langkah, ribuan bahkan puluhan ribu token. Tapi terbatas oleh memori grafis, saat pelatihan dia hanya bisa memberi makan maksimal 2048 token sekaligus.
Jadi dia melakukan pemrosesan serupa “sliding window”: dalam setiap segmen percakapan multi-ronde, dengan pesan pengguna terbaru sebagai titik jangkar, di sekitar satu kali pemanggilan alat, memotong konteks hingga dalam batas anggaran.
V1 dan V2 keduanya menggunakan Gemma 4-12B sebagai dasar. Memilihnya bukan karena mudah dilakukan, justru sebaliknya, format dan protokol alat Gemma 4 cukup khusus, adaptasinya merepotkan, bahkan dukungan klien yang lengkap tidak banyak.
Lu Yuxin menyatakan, di satu sisi untuk menantang diri sendiri; di sisi lain, karena ukuran 12B ini sangat menarik.
Dia menghitung, jika dikuantisasi ke sekitar 3bit, banyak pengguna Mac dengan memori terpadu 8GB juga bisa menjalankannya, bahkan masih menyisakan jendela konteks tertentu.
Sekarang saya tahu, banyak orang masih menggunakan komputer dengan memori terpadu sekitar 8GB. Jadi saya ingin pada jumlah parameter maksimum yang memungkinkan, membuat lebih banyak orang bisa menggunakannya.
Lu Yuxin merangkum nilai model lokal menjadi dua kata:
Privasi, gratis.
Menurutnya, banyak orang hanya ingin AI membantu mengatur file, memproses data, membuat PPT, atau sekadar mencoba agent, belum tentu bersedia membayar Claude, GPT setiap bulan.
Orang mungkin hanya ingin coba-coba, mengapa harus berbayar?
Setelah V1 dirilis, awalnya dia tidak terlalu memperhatikan daftar peringkat, hanya seperti biasa berkata di kartu model: jika kalian suka, unduhan dan likes banyak, dia akan melanjutkan membuat V2.
Tak disangka dua tiga hari kemudian, model tiba-tiba melompat dari peringkat berapa entah ke peringkat delapan; tidur satu malam, sudah melesat ke peringkat pertama.
Setelah itu, komentar dan issue membanjir masuk.
Hampir setiap dia baca. Paling banyak, setiap hari menghabiskan tiga empat jam membaca komentar Hugging Face, menjawab pertanyaan, menguji umpan balik pengguna, lalu memberi tahu hasilnya.
Dia menyatakan: “Komunitas punya kebutuhan, saya benar-benar melakukannya, inilah yang paling penting.”
Ternyata Suka Baca Fiksi Web Juga...
Di HF, Lu Yuxin total merilis 9 model publik, selain dua model yang meledak, dia juga pernah membuat model “menyuling Claude langsung”.
Misalnya gemma-4-12B-it-Claude-4.6-4.8-Opus-GGUF, bisa dipahami sebagai model distilasi versi umum Gemma4-12B.
Tidak hanya terbatas pada pemrograman, lebih mirip memeras gaya jawaban, kebiasaan penalaran, kemampuan thinking Claude Opus, ke dalam model lokal 12B ini.
Model lain bahkan mengganti dasar dengan model pemrograman Mellum2 dari JetBrains, khusus melakukan distilasi penalaran.
Melihat terus ke bawah...
Tunggu, kok ada juga model fine-tuning fiksi web?

Wah, dibagi lagi menjadi empat genre, semuanya LoRA fiksi web bahasa Mandarin, dan semuanya berbasis Qwen3.6.
Lu Yuxin memberi tahu QbitAI, ini sebenarnya pintu masuk awalnya dia mulai membuat model Hugging Face.
Karena dia sendiri memang suka membaca novel. Saat mengejar novel yang belum tamat, pembaca cemas; penulis yang mengetik harian juga sangat lelah.
Karena itu, dia ingin membuat satu set pipeline pembuatan novel gratis, menggunakan LoRA novel bahasa Mandarin dengan gaya berbeda, agar penulis bisa mempercepat dengan AI, pembaca juga bisa lebih cepat melihat konten.
Tapi LoRA novel bahasa Mandarin di HF tidak begitu populer, belakangan dia menemukan pengguna lebih memperhatikan coding dan agentic, jadi arahnya perlahan beralih ke jalur sekarang ini.
Saat ditanya saran untuk developer individu lainnya, Lu Yuxin berkata: Kejujuran dan ketekunan paling penting.
Kejujuran, adalah tidak membesar-besarkan kemampuan model. Di mana kuat, di mana lemah, jelaskan dengan jelas.
Harus jujur memberi tahu semua orang. Saya menipu Anda mengatakan model saya sekuat ini, tapi saat digunakan nyata muncul banyak masalah, lain kali saya mengunggah sesuatu, Anda tidak percaya lagi pada saya.
Ketekunan, adalah penulis open source harus menerima hal ini: Anda pasti akan menemukan suara-suara yang tidak baik.
Setelah modelnya terkenal, Lu Yuxin juga pernah menemukan keraguan, tapi dia tetap memutuskan bertahan.
Menurutnya, jalur open source ini memang sulit.
Bahkan menduduki puncak Daftar Trending Hugging Face, tidak akan langsung menghasilkan pendapatan. Lebih sering, adalah mengeluarkan uang sendiri untuk membeli daya komputasi, menghabiskan waktu memproses data, menjawab komentar, memperbaiki bug, lalu masih harus menghadapi sedikit suara negatif.
Dan yang menopangnya terus melakukan ini, juga ada ritme kerja yang sangat pribadi.
Lu Yuxin menyebutkan, dia menderita ADHD.
Dulu ini mungkin berarti sulit untuk lama-lama melakukan sesuatu secara teratur, tapi di bidang AI yang berkembang sangat cepat ini, berganti minat dengan cepat, cepat masuk ke hyperfocus, justru menjadi semacam keunggulan.
Dia bahkan berpikir: “Era AI adalah dunia ADHD.” Karena setelah satu arah meredup, jika masih terus mendalaminya, saat beralih belajar hal baru, mungkin sudah terlambat.
Di akhir pembicaraan, kami juga melontarkan pertanyaan awal itu:
Sebagai developer individu, atas dasar apa bisa menyelip ke barisan depan di antara perusahaan besar?
Jawaban Lu Yuxin sangat masuk akal.
Menurutnya perusahaan besar tentu bisa melakukan lebih baik, punya lebih banyak peneliti, juga daya komputasi lebih kuat.
Tapi perusahaan besar merilis model kecil open source, seringkali masih memikul target seperti promosi merek, mengalirkan ke API; sedangkan developer individu tidak punya beban ini, justru bisa lebih fokus menyelesaikan satu titik nyeri yang spesifik.
Saya senang, tapi bukan berarti saya benar-benar mengalahkan mereka secara menyeluruh, hanya mungkin lebih serius sedikit.
Menurutnya, inilah peluang penulis open source individu: tidak perlu membuat model serba bisa, tapi membuat satu masalah yang cukup spesifik menjadi mudah digunakan.
Jika Anda juga ingin mencoba model lokal ini, tautan sudah ditempatkan di bawah.
Peringatan ramah: Platform yang paling cocok saat ini adalah llama.cpp, direkomendasikan untuk digunakan lebih dulu~
Alamat HF: https://huggingface.co/yuxinlu1
Artikel ini berasal dari akun publik WeChat "Quantum Bit" (ID: QbitAI), penulis: Fokus pada teknologi terdepan