在数字金融的新浪潮中,稳定币并非对旧体系的颠覆者,而更像是“布雷顿森林体系的数字中继站”——承载美元信用、锚定美债资产、重塑全球结算秩序。
一、历史回望:美元霸权的三次结构性跃迁
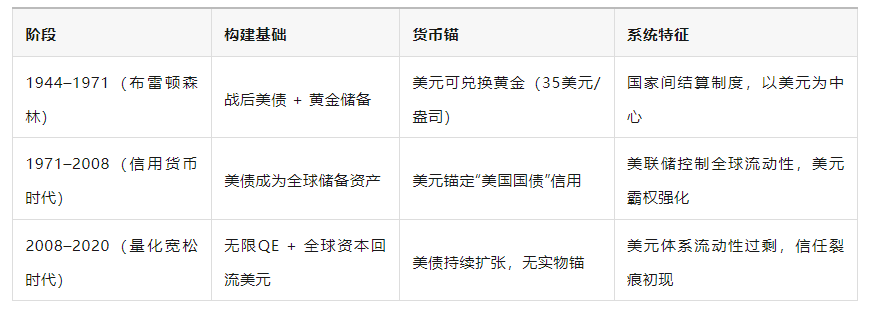
2020年后的新阶段,是美元信用基础数字化、可编程化、碎片化的重构过程,稳定币是这场重构的关键连接体。
二、稳定币的本质:链上的“美元-美债”锚定机制
稳定币(Stablecoin)特别是锚定美元的USDC、FDUSD、PYUSD,其发行机制是“链上美元凭证 + 美债或现金储备”,形成一个简化版的“布雷顿机制”:
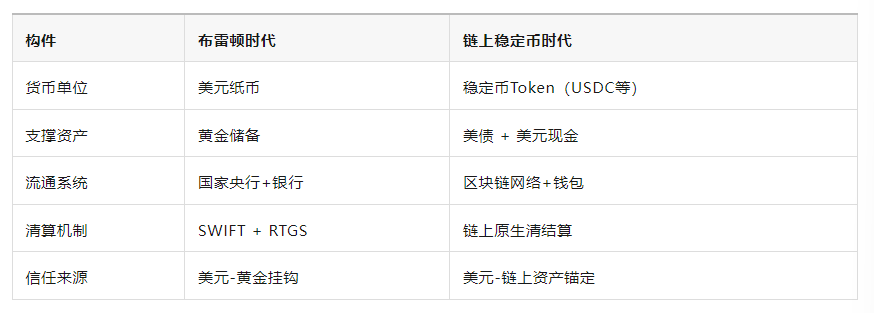
这说明:稳定币体系实际上重建了一个“数字版布雷顿森林框架”,只是锚从黄金变成了美债,从国家清算变成了链上共识。
三、美债的角色:稳定币背后的“新型储备黄金”
目前主流稳定币的储备结构中,美债尤其是短期T-Bills(1-3个月国库券)占比最高:
-
USDC:90%以上储备配置短期美债+现金;
-
FDUSD:100%为现金+T-Bills;
-
Tether亦逐步增加美债权重,减少商业票据。
▶ 为什么美债成为链上金融的“硬通货”?
-
流动性极强,适合应对链上大额赎回;
-
收益稳定,可为发行商提供利差收益;
-
美元主权信用背书,增强市场信心;
-
合规友好,可作为监管合规储备资产。
从这个角度看,稳定币就是“以T-Bills作为黄金的新布雷顿代币”,背后嵌入了美国财政的信用体系。
四、稳定币=美元主权的延伸,而非削弱
虽然表面看,稳定币由私营机构发行,似乎削弱了中央银行对美元的控制。但从实质看:
-
每一枚USDC的发行,都必须对应1美元美债/现金;
-
每一笔链上交易,都以“美元单位”计价;
-
每一笔稳定币全球流通,都是对美元使用半径的扩大。
这使得美国不再需要SWIFT或军事投射就能把美元“空投”到全球钱包,是货币主权外包的新范式。
因此我们说:
稳定币是美国货币霸权的“非官方承包商”
—— 它不是替代美元,而是将美元推向链上、推向全球、推向“无银行区”。
五、布雷顿3.0体系雏形已现:数字美元+链上美债+可编程金融
在这一架构中,全球金融系统将演化为如下模型:

这意味着:未来的布雷顿森林体系不再发生在布雷顿森林会议桌上,而是在智能合约代码、链上资产池、API接口之间协商与共识。
六、风险与不确定性:这套体系还能走多远?
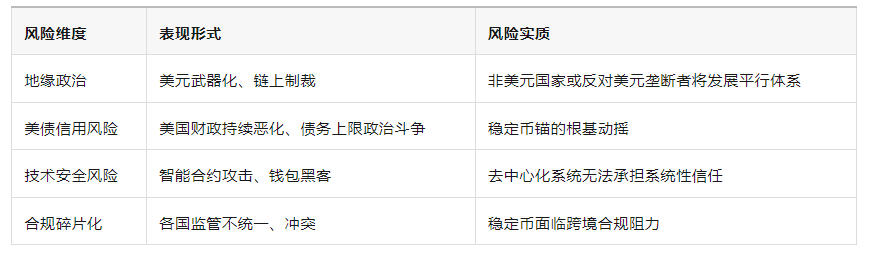
七、结语:稳定币不是终点,是美元全球治理的“中场补给站”
稳定币看似是私营创新,实则正在成为美国政府数字货币战略的“变相桥梁”:
-
它连接了旧金融(美债)与新金融(DeFi);
-
它将美国金融主权延伸至智能合约层;
-
它让美元在数字化转型中不失主导地位。
正如布雷顿森林体系通过黄金锚定建立美元信用,今天的稳定币正尝试以“链上T-Bills + 美元清算共识”重新书写货币治理结构。
稳定币不是革命,而是美债的重构、美元的重塑、主权的延伸。





