Breaking the traditional paradigm of large model pretraining, Tsinghua '00s alumnus Wang Guan's team has released a new work:
They used a Hierarchical Recurrent Model (HRM) to replace the standard Transformer, proposing HRM-Text, an efficient pretraining method that goes beyond Scaling.

Paper link: https://arxiv.org/abs/2605.20613
While using approximately 100-900x fewer training tokens and 96-432x less estimated compute compared to the standard baseline model, HRM-Text still achieved performance comparable to open-source models with 2B to 7B parameters.
Furthermore, using 1B parameters, 40B non-repeating tokens, and a training cost of about $1500, HRM-Text achieved the following scores on mainstream benchmarks: MMLU 60.7%, ARC-C 81.9%, DROP 82.2%, GSM8K 84.5%, MATH 56.2%.
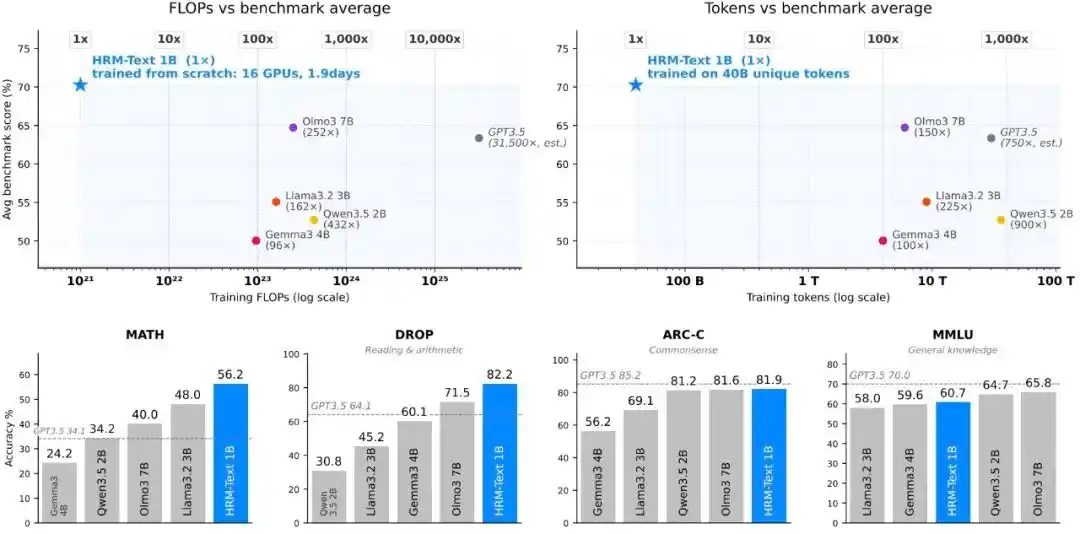
Figure|Pretraining efficiency.
Based on this, they clearly propose: Structural priors and targeted training objectives can significantly lower the barrier to pretraining. This training approach makes training a foundational model from scratch feasible.
How is HRM-Text designed?
Large Language Model (LLM) pretraining is increasingly reliant on a few institutions with ample computing and data resources. Training a competitive foundational model often requires trillions of tokens, thousands of GPUs, and even tens of millions of dollars in compute investment.
However, the current training paradigm is inefficient. A large amount of computation is consumed on irrelevant tokens such as prompts, formatting padding, and web noise, resulting in a significant portion of training compute not directly serving inference.
In this work, the research team redesigned the architecture and training objective, making the pretraining of HRM-Text relatively more efficient.
Architecture: Employs a Hierarchical Recurrent Model with dual timescales, splitting computation into a slow H module and a fast L module. While a standard Transformer performs one forward pass per token, HRM performs multiple rounds of recursive updates on the same token. The H and L modules each account for only half of the recursive core parameters. The overall computational load is roughly equivalent to performing 4 recursive unrolls on the same set of parameters, increasing computational depth without adding more parameters.
Training Objective: Abandons the standard full-text autoregressive pretraining. Instead, training is performed directly on instruction-answer pairs, with loss calculated only on the answer part, combined with PrefixLM masking, allowing bidirectional attention on the instruction part and causal masked generation for the answer part.
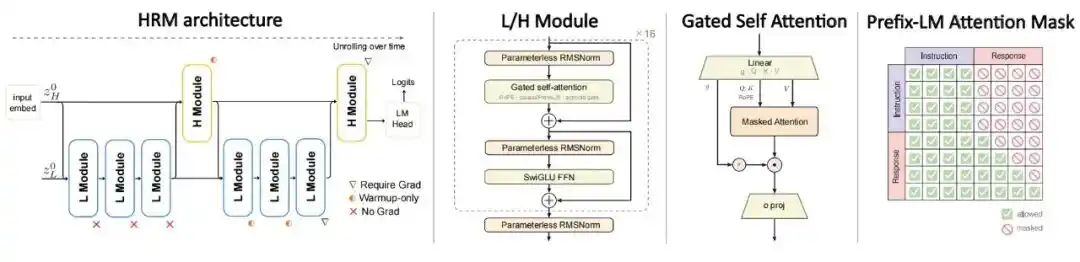
Figure|HRM-Text architecture.
To enhance the stability of recursive training, the research team introduced MagicNorm and Warmup Deep Credit Assignment.
MagicNorm is a hybrid normalization strategy that leverages the asymmetry between forward and backward computation depths under Truncated Backpropagation Through Time (Truncated BPTT). It uses PreNorm internally within modules and adds an extra normalization layer at the module exit, thereby improving the stability of deep recursive training.
Warmup Deep Credit Assignment, on the other hand, only backpropagates gradients from the last 2 recursive steps during the initial training phase, then linearly extends to the last 5 steps. This training mechanism allows the model to converge stably on shorter credit assignment paths before gradually introducing longer dependencies.
How effective is it?
Experimental results show that HRM-Text demonstrates clear advantages in architecture efficiency, training objectives, and overall performance.
1. Under fixed training compute, is the recurrent architecture more effective?
Results show that under FLOPs-aligned conditions, HRM 1B outperforms Transformer 1B, Transformer 3B, Looped Transformer 1B, and RINS 1B on most benchmarks; comparison with TRM also indicates that HRM training is more stable.
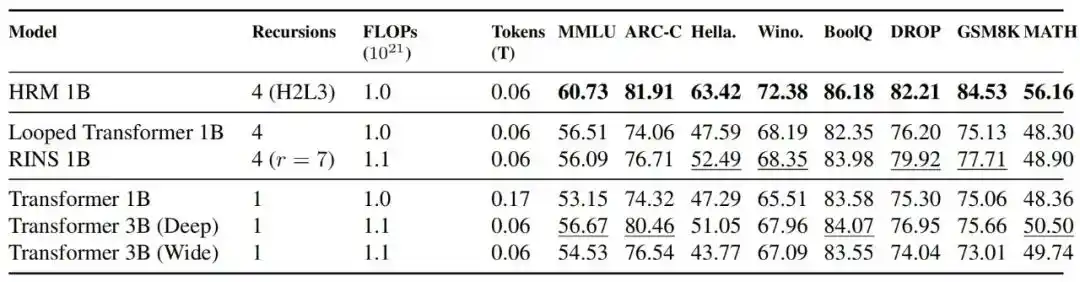
Figure|Comparison of performance and stability with Transformer models. HRM maintained stable training dynamics across all scales, while Transformer models exhibited severe instability at the 1-billion-parameter scale. Furthermore, at the 0.6B scale, HRM achieved competitive performance on most benchmarks using only 2x less computation than Transformer models.
2. Does the task completion objective and PrefixLM help?
Ablation studies show that under FLOPs-aligned conditions, the MMLU score for a 1B Transformer increased from 40.55 with standard autoregressive training, to 47.72 after introducing the task completion objective, to 53.15 after adding PrefixLM, and finally to 60.73 after switching to the HRM architecture.
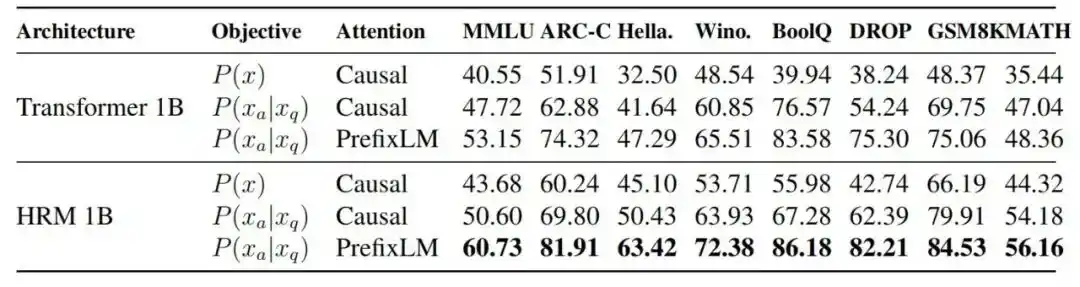
Figure|Performance comparison between different model architectures and training objectives
3. How does HRM-Text's efficiency compare to contemporary open models?
HRM-Text 1B achieved scores of 60.7, 81.9, 82.2, 84.5, and 56.2 on MMLU, ARC-C, DROP, GSM8K, and MATH respectively. Compared to open models that generally have larger training budgets, it entered the performance range of 2B to 7B open-source models using only 40B unique tokens and 1B parameters; training required up to 900x fewer tokens and up to 432x less compute.
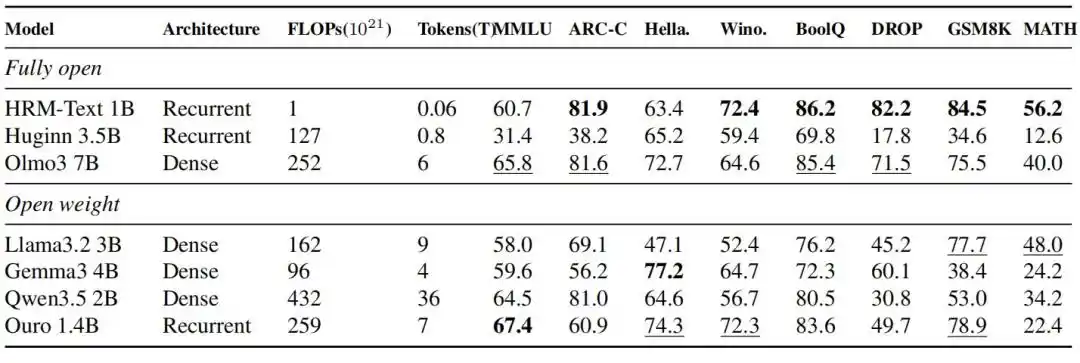
Figure|Evaluation results of HRM-Text 1B compared with contemporary fully open-source models and open-weight models
4. Does the recurrent structure bring greater effective depth?
Results show that the standard Transformer and Looped Transformer stabilize at shallower depths, while HRM maintains more pronounced inter-block representation changes, lower cosine similarity, and higher logit lens KL values even at deeper layers.
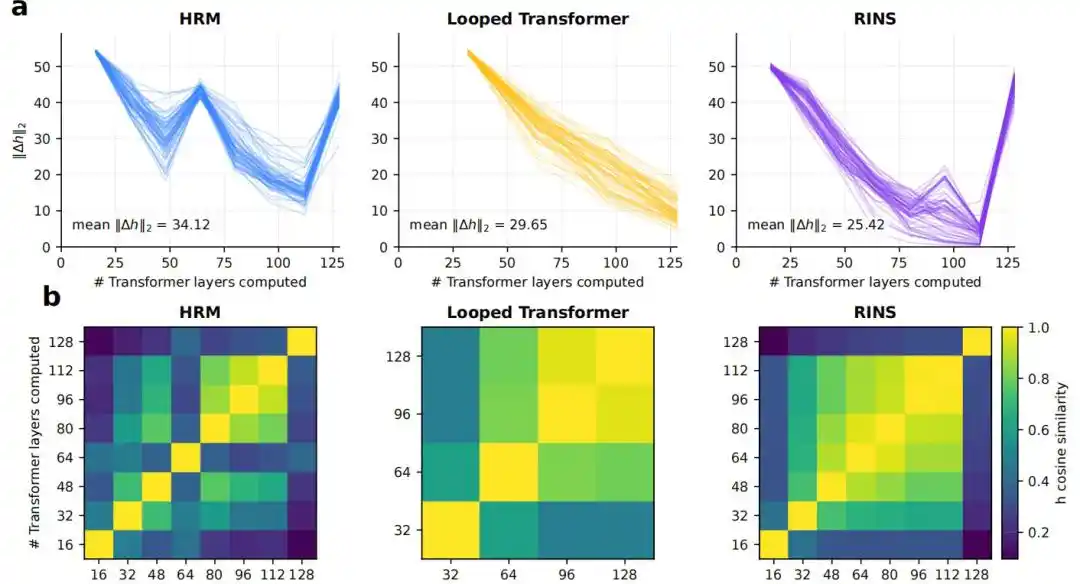
Figure|Effective depth analysis.
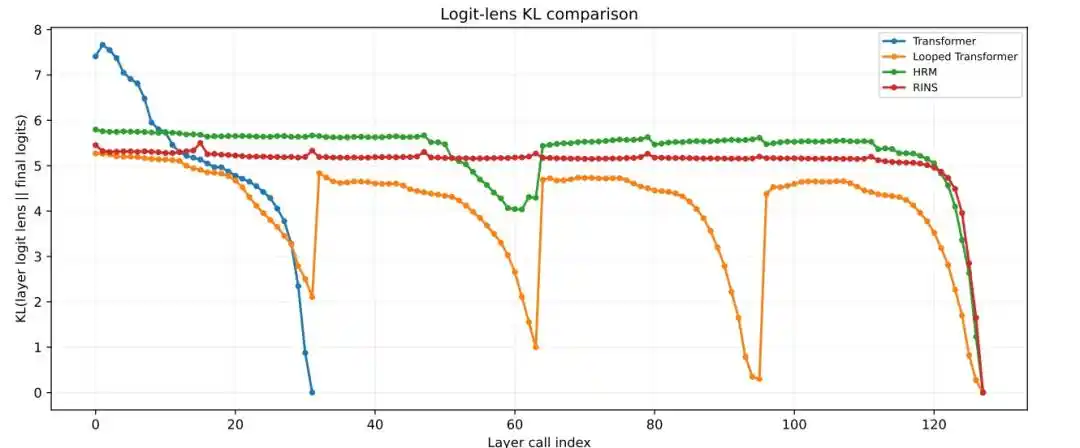
Figure|Layer-wise Logit Lens KL analysis.
Limitations and Future Directions
Although HRM-Text demonstrates strong performance on inference-intensive tasks, this method still has limitations, and future research directions are proposed.
1. Towards Decoupling "Knowledge" and "Reasoning"
Currently, broader factual knowledge coverage still depends more on model scale and data breadth. HRM-Text was only trained on 40B unique tokens, and explicit knowledge sources constitute only part of the task-formatted mixed data. In the future, researchers need to design a compact reasoning core separately from external fact storage, delegating knowledge breadth to curated corpora, retrieval-augmented modules, or learnable memory.
2. Adaptive Computation Time
The recurrent scheduling of HRM-Text brings greater effective serial depth, but this also means the model must execute a fixed number of recursive steps during inference. A promising future direction is to introduce an adaptive computation time mechanism, allowing simple samples to stop computation earlier and reserving the full recursive budget for difficult samples, thereby reducing inference cost.
3. Current Scaling Validation Scope Remains Limited
The current scaling experiments only cover up to the 3B parameter Transformer control group and the 1B parameter HRM-Text. The research team states that it remains to be verified by subsequent work whether similar efficiency advantages can be maintained at larger model scales.
4. PrefixLM and Inference Frameworks
Currently, PrefixLM still faces certain engineering implementation constraints in practical deployment. Although it can run on standard text generation inference frameworks like vLLM, this requires the framework to support custom attention masks during the prefill stage. Extending it to multi-turn dialogue scenarios further requires designing a KV-cache mechanism that ensures bidirectional visibility within user segments while maintaining causal constraints for the assistant's generation process.
For more technical details, please refer to the original paper.
This article comes from the WeChat public account "Academic Headlines" (ID: SciTouTiao), author: Xia Qiansi







