Автор: Vaidik Mandloi
Компиляция: Luffy, Foresight News
ChatGPT, запущенный в конце 2022 года, к настоящему времени породил целую экосистему ИИ-агентов. В настоящее время совокупный сетевой трафик, генерируемый такими программами, уже превышает трафик всех пользователей-людей в мире. Поведение ИИ в интернете коренным образом отличается от человеческого: они не просматривают рекламу, не кликают по ссылкам и не совершают покупки в интернете, а лишь собирают веб-данные для выполнения задач, покидая сайт сразу после завершения задачи.
Изначальная архитектура и бизнес-логика интернета были построены вокруг поведения и привычек человека. Однако сегодня подавляющее большинство сетевых запросов исходит не от реальных людей, что вызывает серьезные проблемы для веб-сайтов. В настоящее время около 2,5 миллионов сайтов начали блокировать программы-краулеры ИИ, и такие платформы, как Perplexity, также оказались вовлечены в соответствующие судебные разбирательства. Провайдер облачных услуг Cloudflare даже создал "лабиринт-ловушку", используя бессмысленные тексты, сгенерированные ИИ, для создания бесконечных циклических страниц, чтобы ловить различных сборщиков данных.
Но часть продвинутых ИИ-агентов уже обладают способностью обходить подобные средства защиты. Перед лицом усиливающегося противостояния человека и машины, вся отрасль начала активно разрабатывать более надежный механизм проверки личности реального человека. Эта система должна точно идентифицировать, является ли оператор по ту сторону экрана человеком: при действиях реального человека наблюдаются колебания, ошибки ввода текста, а перемещение курсора сопровождается характерными для человеческой нервной системы микроскопическими колебаниями. В этой статье анализируются причины, стоящие за этими изменениями, две основные технологические схемы, а также выбор, с которым столкнутся люди: принять централизованный биометрический мониторинг или использовать технологию криптографического доказательства с нулевым разглашением (zero-knowledge proof) для анонимной проверки личности человека.
ИИ подрывает бизнес-модель интернета
Причина, по которой сайты начали блокировать ИИ-программы, заключается в том, что ИИ одновременно с двух сторон пробивает коммерческую основу, на которой держится интернет. Прибыль традиционного интернета строится на внимании пользователей: пользователь заходит на страницу, просматривает рекламу, и издатель контента получает доход. Если поручить покупки ИИ, он за один раз просканирует пять тысяч сайтов, в то время как обычный человек обычно просматривает лишь четыре-пять страниц.
Скорость чтения ИИ намного превышает человеческую: за несколько минут он может провести сравнение цен по всему интернету и даже сразу сделать заказ, причем весь процесс не генерирует ни одного просмотра рекламы. Это означает, что сайты несут операционные затраты на серверы, не получая никакого дохода.
В то же время, поиск с помощью ИИ продолжает перехватывать трафик сайтов. После того как Google добавил блок "ИИ-сводки" (AI overviews) в верхней части результатов поиска, только 8% пользователей переходили на исходные веб-страницы, а реферальный трафик, получаемый крупными контент-сайтами от Google, снизился на 33%. Всего через год после запуска этой функции её ежемесячная аудитория превысила 1 миллиард пользователей, а объем поисковых запросов на платформе удваивался каждый квартал с момента запуска.
Наверняка многие помнят образовательную платформу Chegg. Она изначально специализировалась на вопросах и ответах по учебным программам, пользуясь преимуществами поискового ранжирования, но теперь официально закрыла этот раздел, объяснив это влиянием ChatGPT. Создатели контента оказались в тисках: с одной стороны, краулеры бесконтрольно собирают контент с их сайтов, а с другой — ИИ-сводки перехватывают трафик еще до того, как пользователь попадет на сайт.
Разрыв в данных еще более поразителен: на каждый переходный трафик, который краулер OpenAI приносит партнерскому сайту, он предварительно сканирует данные с 400 страниц; у Anthropic это соотношение составляет 38000:1. Эти компании используют общедоступные данные со всего интернета для обучения своих ИИ-моделей, а затем используют готовые продукты для перехвата трафика, который изначально принадлежал сайтам.
В любой другой отрасли подобное хищническое поведение по сбору данных давно вызвало бы бесчисленные иски, но в сфере ИИ такие компании получают триллионные оценки.
Ваше тело — новый пароль
За последние 25 лет интернет в основном полагался на CAPTCHA для различения человека и машины. Людям нужно было распознавать дорожные знаки, вводить искаженные символы — этот механизм работал, потому что в прошлом возможности машин в распознавании изображений значительно уступали человеческим.
Сегодня ситуация кардинально изменилась. Симуляционные баллы программы-агента OpenAI в системе проверки Google "Я не робот" значительно превышают человеческие, она способна точно кликать по интерфейсу, копировать и вставлять контент; фотографии, сгенерированные ИИ, могут обмануть системы проверки личности, а дипфейк-видеозвонки даже использовались мошенниками для совершения банковских переводов. Предпосылка дизайна традиционных методов проверки — превосходство человека над машиной — больше не существует.
Теперь отрасль может сосредоточиться только на том, что ИИ пока не может воспроизвести: на характеристиках физического поведения человека при взаимодействии с электронными устройствами, то есть на поведенческой биометрии. Такие компании, как IBM и BioCatch, разрабатывают соответствующие системы. Эти технологии не только проверяют личность при входе, но и постоянно отслеживают состояние использования, собирая данные о скорости перемещения курсора, способе прокрутки страницы, ритме набора текста, силе нажатия клавиш, привычках правки текста, угле наклона телефона и т.д., гироскоп телефона постоянно записывает эту информацию.
Система также может распознавать доминирующую руку пользователя, траекторию движения пальца и другие детали. IBM требуется собрать данные всего о восьми сессиях использования, чтобы создать поведенческий профиль пользователя, который впоследствии будет в реальном времени сравнивать каждое действие с эталонными данными.
Технология BioCatch может даже распознавать сценарии интернет-мошенничества. Когда жертва под диктовку мошенника по телефону произносит пароль от аккаунта, прерывистый и нервный ритм набора текста будет точно зафиксирован системой. Всего за один год эта система помогла 257 банкам выявить около 2 миллионов счетов, используемых для отмывания денег. Сегодня ЕС также начал пилотные испытания технологии распознавания походки. Всего через три года после начала эры ИИ-агентов пограничники ЕС уже начали собирать данные о походке граждан.
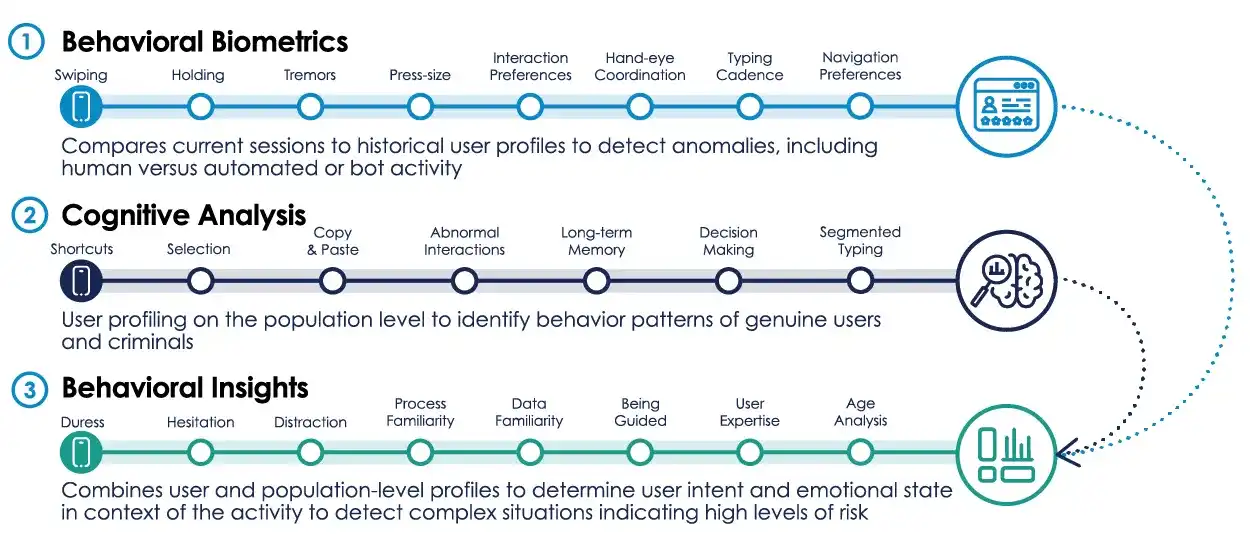
Соответствующие исследования также используют эффект Струпа: когда слово "синий" написано зеленым шрифтом, человеческий мозг испытывает конфликт между значением слова и видимым цветом, что приводит к заметному замедлению реакции, в то время как ИИ не подвержен никакому влиянию. Исследования показывают, что это когнитивное вмешательство напрямую отражается на поведении при наборе текста. Платформе даже не нужно задавать специальные тестовые вопросы — только по ритму нажатия клавиш можно определить, является ли оператор человеком; в привычках набора текста скрыты уникальные характеристики обработки информации человеческим мозгом.
style="text-align: start;">Предыдущее отслеживание в интернете в основном записывало действия пользователя: просмотры, клики, покупки; пользователь мог избежать этого, блокируя куки, используя VPN, отключая геолокацию. Но поведенческая биометрия собирает инстинктивные характеристики тела: способ перемещения курсора, ритм набора текста — все это сложно изменить преднамеренно.Поведенческие характеристики каждого человека уникальны, как отпечатки пальцев. В отличие от паролей и ключей, этот биометрический профиль нельзя заменить или сбросить. Как только эта технология получит широкое распространение, все крупные платформы будут вынуждены адаптироваться к ней. Сегодня технологии симуляции голоса уже могут обмануть во время телефонного разговора, за ними следуют и технологии дипфейк-видео. Если это будущее, возникает ключевой вопрос: кто в конечном итоге будет контролировать эти данные о человеческом теле?
Кто будет контролировать систему проверки личности человека
В настоящее время в отрасли сформировались два основных лагеря, исследующих варианты проверки личности человека.
Первый — это World (ранее Worldcoin) Сэма Олтмана. Пользователь должен подойти к сферическому устройству сканирования радужной оболочки глаза, которое собирает информацию о радужке и генерирует зашифрованный сертификат, доказывая, что пользователь является уникальным человеком. В настоящее время 18 миллионов человек из 160 стран уже зарегистрировали свои радужные оболочки. В апреле 2026 года World заключила соглашения о проверке пользователей с приложением для знакомств Tinder, платформой видеоконференций Zoom, сервисом электронной подписи DocuSign; а также совместно с Coinbase выпустила инструмент AgentKit, позволяющий пользователям привязать своих ИИ-агентов к верифицированной личности, чтобы платформы могли подтвердить наличие реального человека за агентом, не раскрывая личную информацию пользователя.
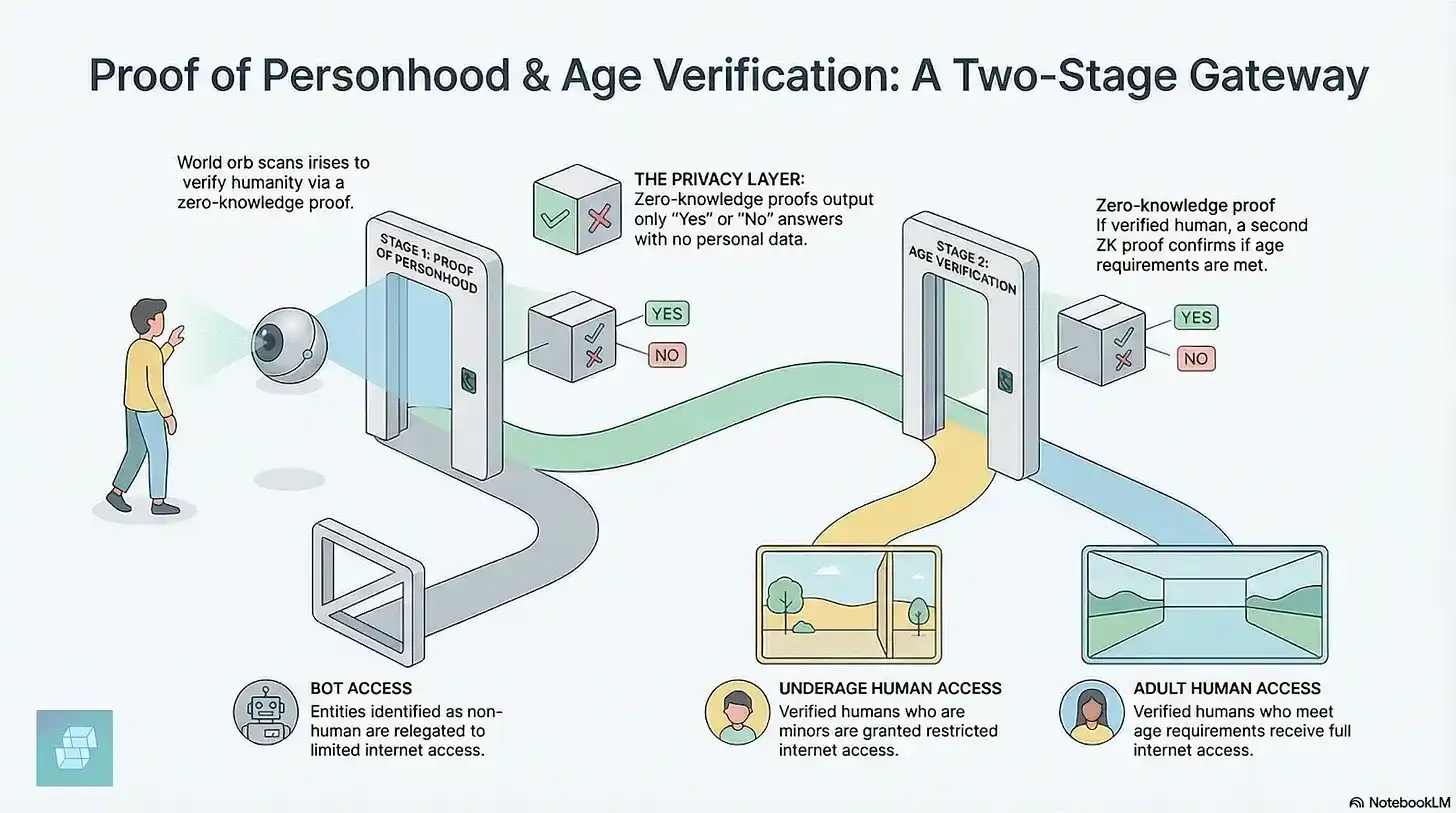
Однако технология сканирования радужной оболочки запрещена в нескольких странах. Основная причина сопротивления — непонимание населением потенциальных рисков, связанных с авторизацией сбора биометрических данных. Исследование MIT Technology Review также выявило, что World без надлежащего разрешения, помимо сбора данных о радужной оболочке, также тайно собирала данные о частоте сердечных сокращений, дыхании и других жизненно важных показателях.
Второй тип — это криптографическое доказательство с нулевым разглашением (zero-knowledge proof), которое позволяет вам доказать, что вы человек, не раскрывая своей реальной личности, местоположения или внешности. Виталик Бутерин выдвинул эту идею еще в 2023 году. Он считает, что если не удастся создать децентрализованную систему идентификации человека, интернет в конечном итоге придет к централизованному контролю над личностью. Как только право проверки личности окажется в руках компаний или правительств, механизмы наблюдения укоренятся в основе сети.
Попытки крупномасштабного внедрения децентрализованной системы идентификации человека предпринимались и ранее, но в конечном итоге потерпели неудачу. Idena была одним из первых проектов публичного блокчейна, ориентированных на принцип "один человек — одна личность". Всего через два года после запуска 40% аккаунтов и 48% вознаграждений в сети контролировались 23 организациями. Команды по управлению аккаунтами в Индии, России и других странах нанимали обычных людей за плату менее одного доллара в час для "аренды" их личностей, зарабатывая при этом прибыль до 55 раз больше. Исследователи также обнаружили, что даже дети использовались в качестве подставных аккаунтов.
Виталик ранее предвидел подобные риски. Он заявил, что самой дешевой атакой на систему проверки личности человека будет не дипфейк или хакерские технологии, а наем людей из регионов с низким уровнем дохода для сдачи в аренду своей личности. Любая система проверки личности человека требует финансовой поддержки: устройства для сканирования радужной оболочки, узлы проверки в блокчейне требуют постоянных затрат.
Но как только удостоверение личности приобретает экономическую ценность, возникает черный рынок аренды личностей. В реальном мире с огромным разрывом между богатыми и бедными капитал всегда будет контролировать такие рынки.
"Попытка навязать правило 'один человек — один голос' в системе с реальными экономическими стимулами в конечном итоге повторит неудачные социальные эксперименты двадцатого века."
Объективно говоря, оба пути развития имеют очевидные недостатки. Централизованное решение может быть реализовано в больших масштабах, но биометрические данные пользователей будут храниться компаниями, которые и так собирают избыточную информацию, и которые сами извлекают выгоду из ситуации с распространением ботов. Криптографический путь теоретически может защитить конфиденциальность, но ему трудно избежать проблемы экономического дисбаланса в реальном мире, в конечном итоге становясь уязвимым для серой индустрии.
Если бы мне пришлось делать ставку, я бы все равно поставил на криптографическое решение. Потому что поведенческая биометрия и централизованное сканирование радужной оболочки навсегда записывают информацию о вашем теле, и право собственности на эту информацию принадлежит тем, кто развернул эту систему. Как только они получат ваши данные, вы не сможете их удалить или перенести; эти данные будут заблокированы в компании, которая их собрала.
Даже зная, что доказательство с нулевым разглашением может быть использовано в обход, оно все равно стоит разработки, потому что такое доказательство может подтвердить, что вы человек, не раскрывая дополнительной информации. И наоборот, если отказаться от этого пути, в будущем при посещении любого сайта наши данные о поведении и движениях будут сохраняться. Сегодня эта централизованная схема с элементами наблюдения реализуется гораздо быстрее, чем криптографический путь.








