Примечание редактора: Когда «ИИ пишет код» постепенно становится отраслевым консенсусом, реальное изменение производительности исходит не от самой модели, а от того, как вы устанавливаете правила для модели, организуете процессы и внедряете их в устойчиво работающую систему.
Начиная с простого файла CLAUDE.md, до координации множества агентов и автоматизированного цикла разработки, этот метод превращает процесс разработки из «диалога человека с ИИ» в «управление командой ИИ-инженеров». В этом процессе ошибки устраняются упреждающе, процессы структурируются, а генерация кода, тестирование и проверка постепенно переходят от ручного выполнения к управлению системой.
Что еще более важно, статья также раскрывает упускаемую деталь: в длинном контексте и сложных системах поведение модели не полностью контролируемо. Как скрытое потребление токенов, так и размывание инструкций незаметно влияют на качество вывода. Это делает «управление ИИ», а не просто «использование ИИ», новым ключевым навыком.
Теперь разработчик сосредотачивается не на написании кода, а на проектировании правил, планировании процессов и проверке результатов. Те, кто уже сделал этот шаг, начали переходить от «самостоятельного выполнения задач» к «поручению задач системе».
Далее оригинальный текст:
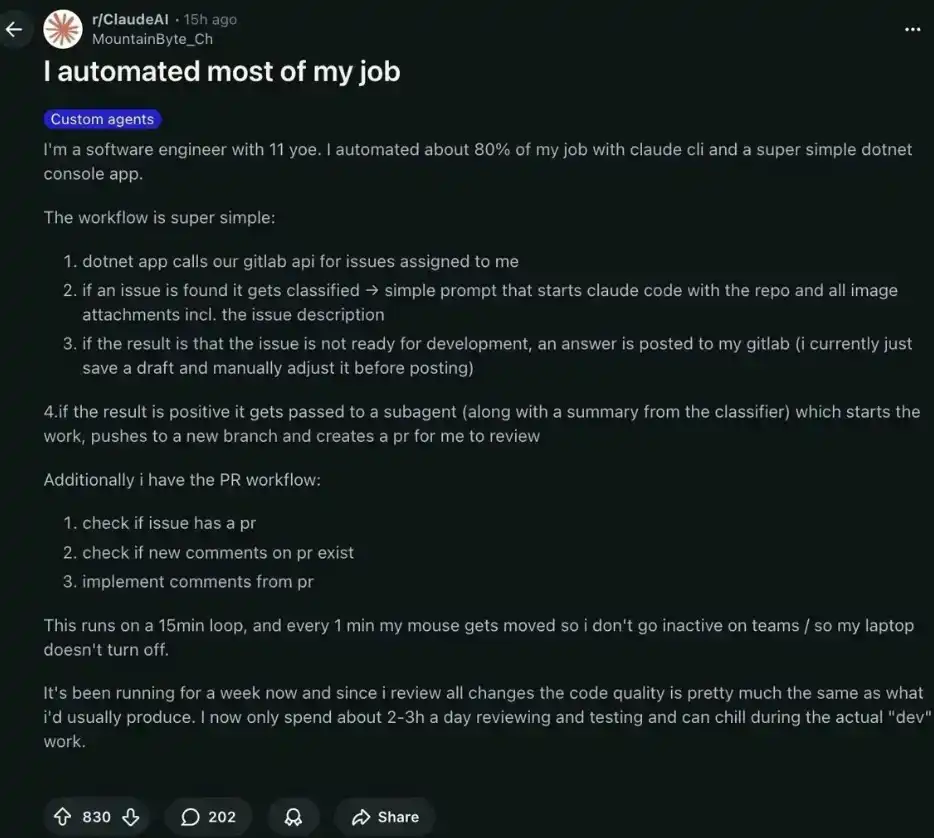
Инженер Google с 11-летним опытом с помощью Claude Code и простого .NET-приложения автоматизировал 80% своей работы.
Теперь он работает всего 2–3 часа в день вместо прежних 8 часов, остальное время基本上处于「расслабленном」状态, пока система работает сама, принося ему пассивный доход в размере 28 000 долларов в месяц.
То, чем он овладел, — это именно тот метод, который вам еще неизвестен.
Часть 1—Создание CLAUDE.md по принципу Карпати
Андрей Карпати — один из самых влиятельных исследователей ИИ в мире — систематически summarized самые распространенные ошибки больших языковых моделей при написании кода: излишнее усложнение, игнорирование существующих шаблонов и добавление ненужных зависимостей.
Кто-то обобщил эти наблюдения и свел их в единый файл CLAUDE.md.
В результате проект набрал 15 тысяч звезд на GitHub за неделю, что, в некотором смысле, означает, что 15 тысяч человек изменили благодаря этому свой способ работы.
Основная идея довольно проста: если ошибки предсказуемы, то их можно избежать с помощью четких инструкций заранее. Достаточно разместить markdown-файл в репозитории, чтобы предоставить Claude Code целый набор структурированных правил поведения, унифицируя thus принятие решений и выполнение во всем проекте.
Внутри этот файл в основном содержит четыре ключевых принципа:
· Сначала подумай, потом программируй → Избегай ошибочных предположений и упущенных компромиссов
· Простота прежде всего → Избегай over-engineering и раздутых абстракций
· Хирургические изменения → Избегай изменений в коде, которые никто не просил менять
· Целеориентированное выполнение → Сначала тестируй, затем проверяй по четким критериям успеха
Без зависимостей от фреймворков или сложных инструментов — всего один файл может изменить поведение Claude на уровне проекта.
Реальная разница заключается в следующем:
· Без CLAUDE.md: Claude нарушает правила примерно в 40% случаев
· С CLAUDE.md от Карпати: уровень нарушений снижается до примерно 3%
· Время настройки: всего 5 минут
Команда для автоматического создания вашего собственного файла CLAUDE.md:
claude -p "Прочти весь проект и создай CLAUDE.md на основе:
Think Before Coding, Simplicity First, Surgical Changes, Goal-Driven Execution.
Адаптируй под реальную архитектуру, которую ты видишь." --allowedTools Bash,Write,Read
Это заменяет такого Claude, который: сталкиваясь с простой задачей, излишне усложняет, добавляет ненужные зависимости и даже随意 изменяет файлы, которые трогать не следует.
Часть 2 Everything Claude Code: Полная инженерная команда в одном репозитории
Everything Claude Code (более 153 тысяч звезд на GitHub)
Это не просто набор промптов, а скорее полноценная AI-операционная система для создания продуктов.
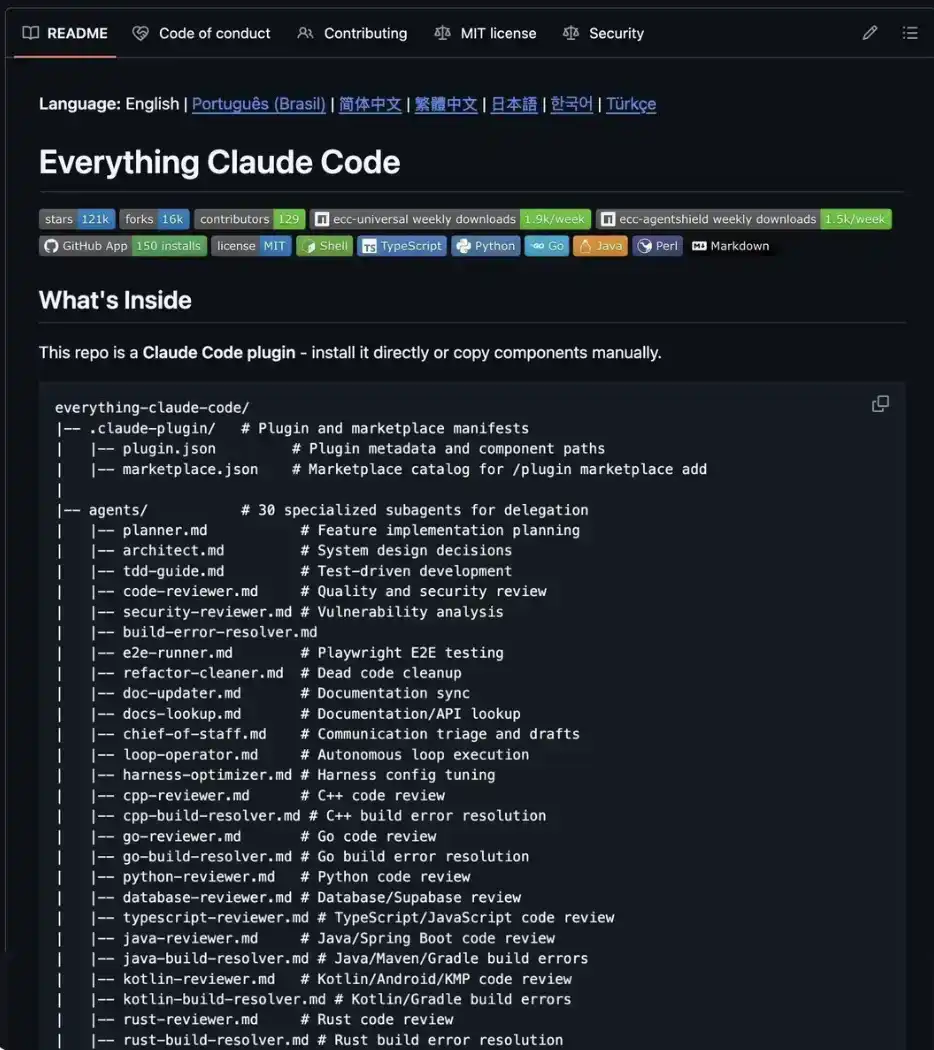

Работает на Claude, Codex, Cursor, OpenCode, Gemini и многих других инструментах — одна система, работает везде.
Способ установки:
/plugin marketplace add affaan-m/everything-claude-code
Или ручная установка — просто скопируйте нужные компоненты в директорию .claude/ вашего проекта. Не загружайте все сразу — одновременная загрузка 27 агентов и 64 навыков, скорее всего, исчерпает лимит контекста еще до того, как вы введете первый промпт. Оставляйте только то, что действительно нужно.
Реальная разница заключается в следующем:
· До: Вы общались с ИИ
· После: Вы управляете самостоятельно работающей командой ИИ-инженеров
Это заменяет: необходимость тратить недели на搭建 своей собственной системы агентов, отдельную настройку различных инструментов для планирования/ревью/безопасности, а также ежемесячные затраты в 200–500 долларов на различные AI-сервисы.
Часть 3 Скрытый «скандал»: Claude Code v2.1.100 тихо потребляет ваши токены
Кто-то, настроив HTTP-прокси, перехватил и проанализировал полные API-запросы 4 разных версий Claude Code.
Они обнаружили:
v2.1.98: 169 514 байт запроса → 49 726 токенов к оплате
v2.1.100: 168 536 байт запроса → 69 922 токена к оплате
разница: -978 байт, но +20 196 токенов
v2.1.100 отправляет меньше байт данных, но списывает на 20 тысяч токенов больше. Эта «инфляция» происходит полностью на стороне сервера — вы не можете ни увидеть ее, ни проверить через интерфейс /context.
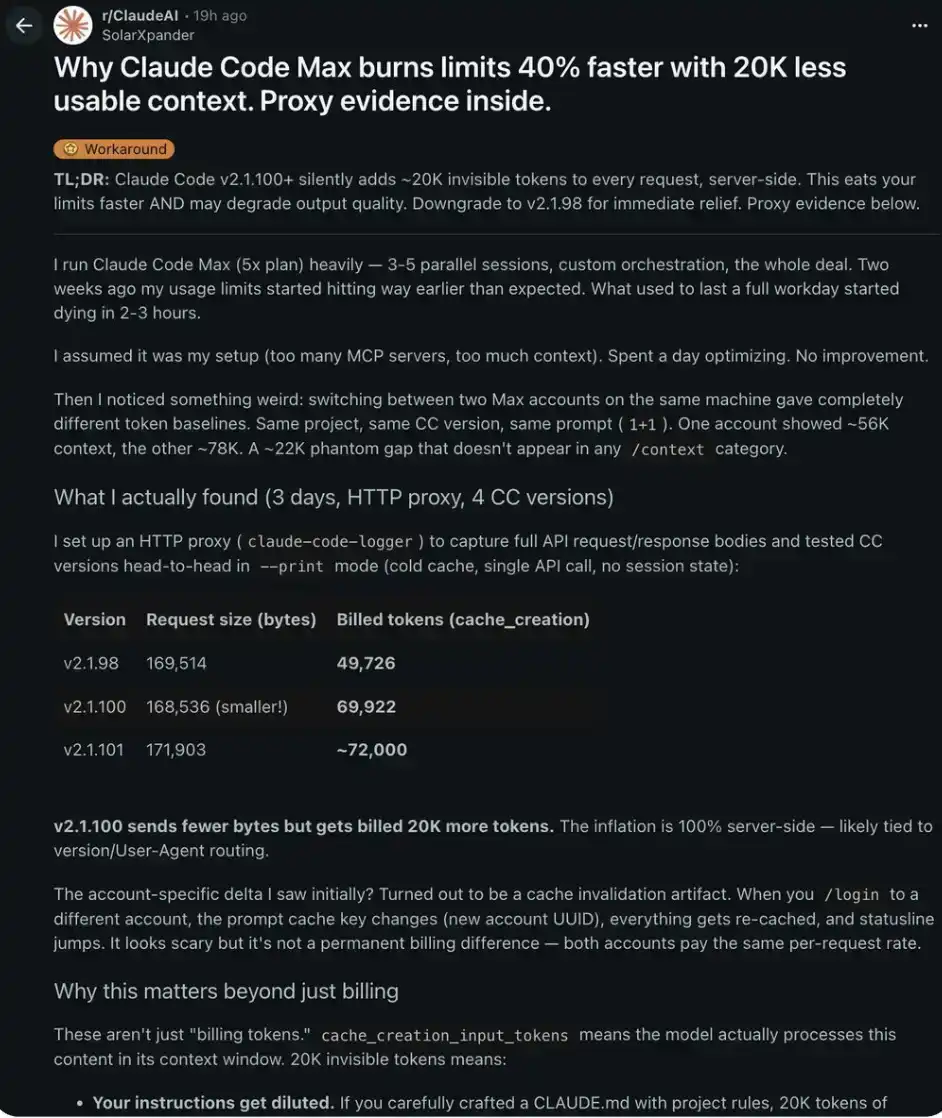
Почему это важно не только для биллинга: эти дополнительные 20 тысяч токенов помещаются в фактическое контекстное окно Claude.
Это означает:
→ Ваши инструкции из CLAUDE.md будут разбавлены этими 20 тысячами «скрытого контента»
→ В длинных диалогах качество вывода будет падать быстрее
→ Когда Claude игнорирует ваши правила, вам сложно找出原因
→ Лимиты использования Claude Max будут исчерпываться примерно на 40% быстрее
Исправление занимает 30 секунд: npx [email protected]
Это временное решение до официального исправления от Anthropic, но на практике вы几乎可以立刻 ощутить изменение эффективности сессий.
Это заменяет: необходимость гадать, почему Claude вдруг перестал следовать вашим инструкциям.
Кейс: Как выглядит полная автоматизированная система
Инженер с 11-летним опытом построил систему, состоящую из трех частей:
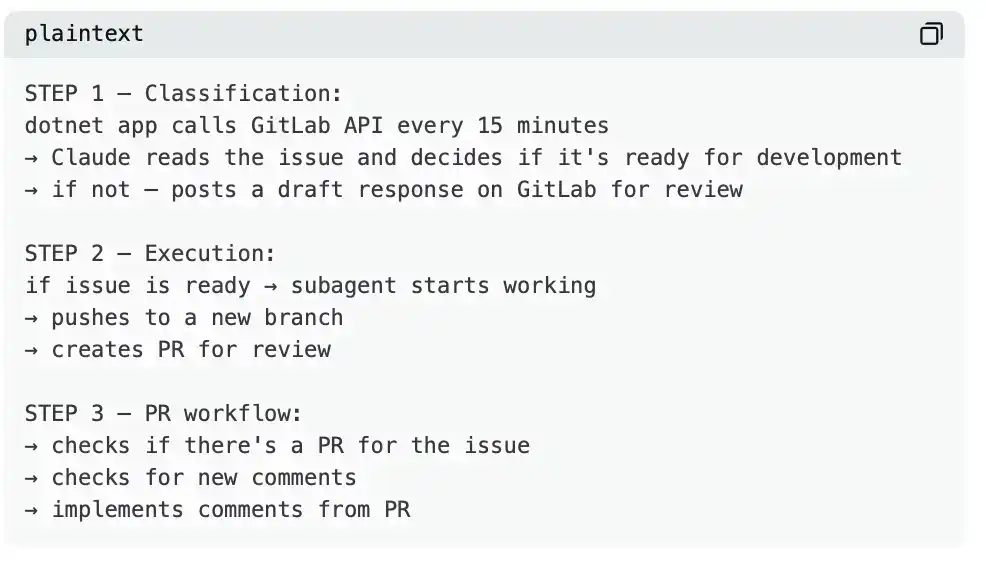
Результат через неделю:
· До: 8 часов в день на написание кода
· После: Всего 2–3 часа в день на ревью кода и тестирование
· Качество кода: практически не изменилось — потому что он проверял каждый changeset
· Статус в Teams: Всегда в сети — курсор мыши двигался автоматически каждую минуту
· Оставшееся время: Свободно в течение дня
Это не какое-то «волшебство», а результат совместной работы CLAUDE.md + подходящих агентов + циклического механизма, запускаемого каждые 15 минут.
Полный список:

Что вы получите после прочтения:
· До: Claude нарушал established правила в 40% случаев
· После: С CLAUDE.md от Карпати уровень нарушений упал до 3%
· До: Вам требовались недели на настройку агентов
· После: 27 агентов готовы к использованию out-of-the-box
· До: Лимиты Claude Max исчерпывались за 2–3 часа
· После: Понижение версии до v2.1.98 восстанавливает около 40% лимита использования
· До: 8 часов в день на написание кода
· После: Всего 2–3 часа на ревью, остальное система делает автоматически
· Время настройки: 15–20 минут
· Ежедневная экономия: 5–6 часов
· Ежемесячная экономия: 100–120 часов
Если стоимость вашего времени составляет 30 долларов в час — то вы «невидимо теряете» 3000–3600 долларов в месяц.
Если 100 долларов в час — то это 10000–12000 долларов в месяц, утекающих впустую, только потому, что вы все еще вручную пишете код, который Claude мог бы сделать сам.
Большинство разработчиков никогда не достигнут этого уровня — не потому, что они не могут, а потому, что они думают, что это сложно. На самом деле, между вами и «полной автоматизацией» всего три команды и один файл.
Тот инженер, о котором я говорил вначале, не гением, и он не senior engineer из Google. Он просто потратил один вечер на то, чтобы настроить систему — с тех пор работу выполняет система, а он занимается жизнью.
Вы можете сделать то же самое сегодня вечером. Пока другие спорят, заменит ли ИИ разработчиков, те, кто уже настроил систему, просто получают деньги и расслабляются.
Выбор довольно ясен. Вы строите свою собственную жизнь — так что выбирайте правильный путь.





